







1.解决问题:基于I3D模型,使用图模型,以构造视频中物体间的关系,提升识别精度。
本文是将video看做是 a graph of objects,然后再该graph上进行行为识别的推理。
2.实验效果:在somethingV1数据集上,test:45% 相对于I3D 提高1.7% ,相对于TRN网络提高12%
3.图卷积层的定义:Z=GXW
其中x是图卷积输入节点是特征(Nxd),G各个节点之间的关系矩阵(NxN),W是权重矩阵(dxd),因此图卷积层的输出依然是Nxd维的。图卷积可以叠加。因此图卷积模型的构建在于怎么构造图G。文章介绍了相似图和时空图的构造。
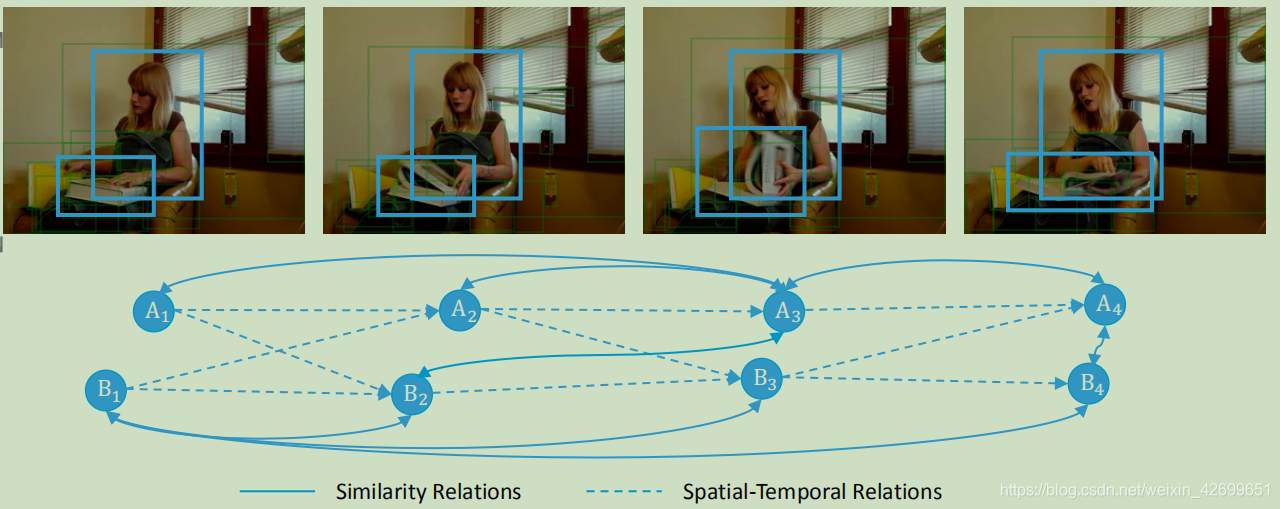
相似图Similarity Graph

时空图Spatial-Temporal Graph

4.网络结构
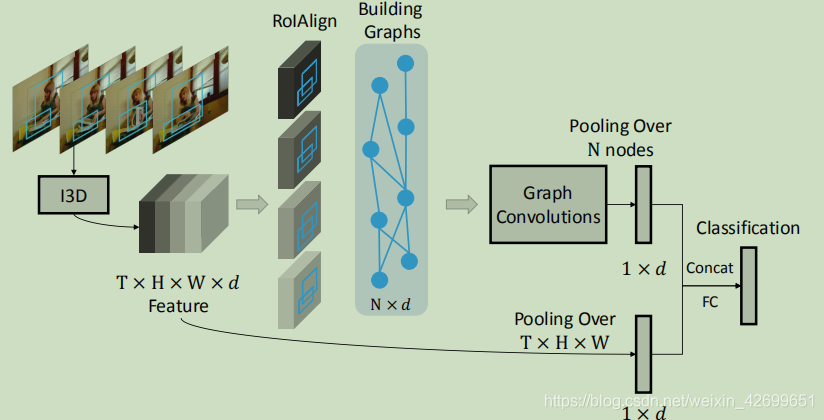
- 对均匀下采样后的T 帧作为输入,经过I3D,得到 TxHxWxd 的 feature,该feature经过2个分支
- 第一个branch进行RPN来提取N个候选区域,然后进行ROIAlign来得到 Nxd 特征;接着构造相似度图和双向时空图,然后对两种图各进行图卷积操作,再叠加得到N*d特征;最后对N个物体特征进行均值池化,得到 1xd 特征
- 第二个branch直接对时空deep feature进行均值池化, 得到 1xd 特征
- 最后将2组branch的特征进行concat,再送到fc进行分类
5.思考
文章中,构造图节点时,每个图节点都是一个具体的值,不论是计算时空图还是相似图,这样就导致每个节点只涵盖了一种信息,如果每个节点可以由多个值构成(如:特征信息,位置IOU信息,相似性信息等),再进行学习,这样这些信息之间可以相互辅助,效果应该会更好。
6.代码实现

















 735
735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









