






一、环境:
(一)使用云服务器
如AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDL
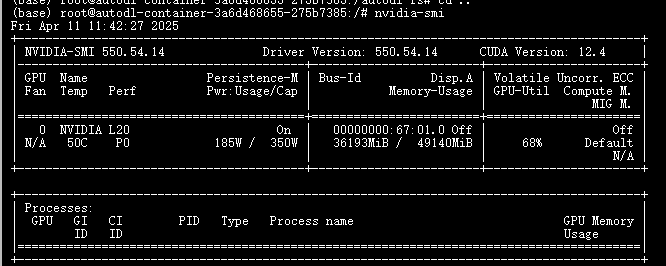
1、选择服务器:本人使用L20(48G显存)服务器,训练两三千数据量时,显卡使用情况如下图,V100我也用,但算力好的服务器,跑起来速度相对也快,仅供参考。
2、创建及初始化conda:
conda init base
3、创建conda虚拟环境,安装ultralytics:
conda create -n myYolo python=3.11
conda activate myYolo
pip install ultralytics
(二)Windows环境
使用conda,先安装conda,可参考之前的Conda/Miniconda/Anaconda 安装及命令整理_condamini-优快云博客,不使用conda的话,跳过此步骤,使用的话,创建虚拟环境,并激活
conda create -n myYolo python=3.11
conda activate myYolo
方案1、CPU安装:
最简单的,不使用CUDA,一条命令(yolo的训练使用,就主要就安装ultralytics这个), 但不太推荐此方法,不使用CUDA会很慢
pip install ultralytics
方案2、安装CUDA:需要先确认机子是否有独显,
1)下载安装CUDA CUDA Toolkit Archive | NVIDIA Developer
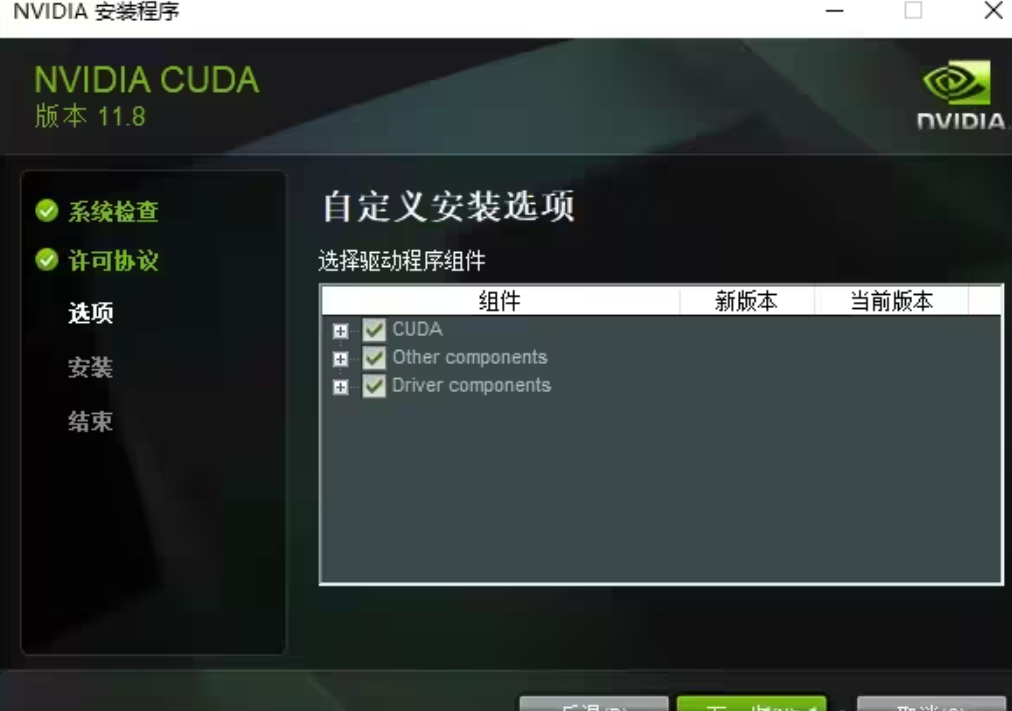
全选
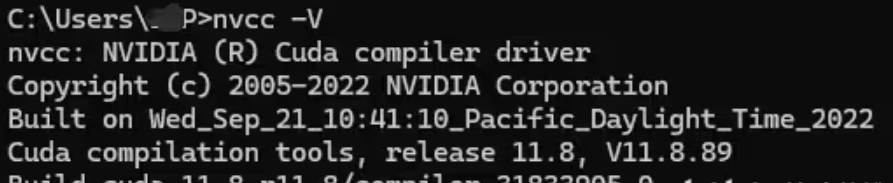
安装完成后可以再次在cmd里输入命令:nvcc -V 查看,如下显示即安装成功
2)cudnn安装
进入cudnn官网,选择合适版本的文件。
https://developer.nvidia.com/rdp/cudnn-archivehttps://developer.nvidia.com/rdp/cudnn-archive
进入后在文件列表中选择cudnn版本与上面cuda安装相匹配的版本,然后下载Windows版本的压缩包文件。
将得到的压缩文件进行解压,解压后得到下图三个文件夹,全选复制进cuda的文件夹中进行覆盖替换,替换完成后即cudnn安装完成。按照本文教程安装的cuda的文件夹默认在 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8 目录下。
3) 创建环境,安装:
conda create -n myYolo python=3.11
conda activate myYolo
pip install ultralytics
本文安装参考:YOLOv11(Ultralytics)环境配置,适合0基础纯小白,手把手教 - 哔哩哔哩
二、YOLO:
1、YOLO测试图片识别:
创建一个文件夹myYoLo,进入到myYOLO ,创建一个python文件,test.py:
from ultralytics import YOLO
# 加载模型
model = YOLO("yolov8n.pt")
# 训练模型
#train_results = model.train(
# data="coco8.yaml", # 数据集 YAML 路径
# epochs=100, # 训练轮次
# imgsz=640, # 训练图像尺寸
# device="cpu", # 运行设备,例如 device=0 或 device=0,1,2,3 或 device=cpu
#)
# 评估模型在验证集上的性能
#metrics = model.val()
# 在图像上执行对象检测
# show = True 显示检测结果
# save = True 保存检测结果
model("you_ceshi_url.jpg", show=True, save = True )
print("ok")在此文件夹目录下,执行python文件
python test.py
执行后,会在当前目录下生成一个runs目录,一直点进去就可以看到刚刚生成的图片了
2、YOLO训练
(一)数据标记
(1)图片准备:几十张到几万张,看运用场景,练着玩,几十张,练个两三百遍,也能看到效果,当然数据量越大,训练出来效果越好,我们这次训练三个设备,一个设备一千多张,最好每个种类的数据量差不多,训练六七百遍,目前效果也能符合我们需求。
(2)数据标记:标记工具有很多,这个大家自己网上搜就行,我用过LabelImg ,但貌似没有多边形功能,不知道是不是我没找到还是就是没有,有的话,大家也可以给我留言告诉我下,感谢;还自己部署过cvat,但不知道为什么导出yolo格式后,txt文件好多是空的,没有标注的数据,因项目紧急,我也没时间过多研究,后来用了roboflow,挺方便的,可以免费使用,适合小数据量的用户,且下载时选好自己要用的模型格式,如yolo8,下下来的数据直接就可以使用,很方便。
下走下来的包目录是这样的,主要文件是:train(必须)、valid(必须)、test(貌似可有可无)、和 data.yaml(必须)。
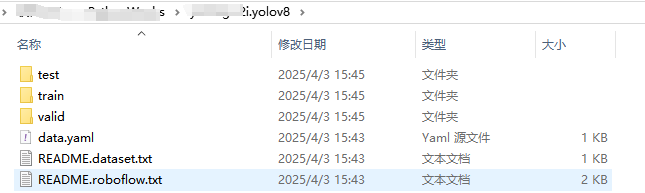
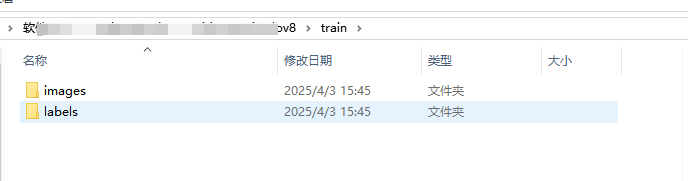
train、test和valid目录下都有个images 和labels。目录images 里放的是图片文件,labels里放的是标注后的文件,具体文本里啥内容我这里就不细说了 ,网上很多博主都有提到:就是类型,坐标什么的。标注文件的名称和图片名称是一一对应的,不能随便更改。
特别说明:貌似这个目录结构不是一定的,还可以是创建images和labels,然后分别在images和labels 里在创建train、test和valid三个文件,images里放的是图片,labels里放的是txt文件。
data.yaml文件:主要是修改图片地址,和添加数据类型,roboflow下载下来的数据文件里,这些都不用动,数据增强,自己看情况使用调整
train: ../train/images
val: ../valid/images
test: ../test/images
#数据类型
nc: 3
names: ['class0', 'class1', 'class2']
# 数据增强设置,不设置就用默认值
augment:
flipud: 0.5 # 50% 概率进行垂直翻转
fliplr: 0.5 # 50% 概率进行水平翻转
mosaic: 0.0 # 启用 Mosaic 数据增强
mixup: 0.5 # 启用 Mixup 数据增强
hsv_h: 0.015 # 色调增强,范围为 ±0.015
hsv_s: 0.7 # 饱和度增强,范围为 ±0.7
hsv_v: 0.4 # 亮度增强,范围为 ±0.4
scale: 0.5 # 随机缩放,范围为 ±50%
shear: 0.0 # 随机剪切,设置为 0 禁用
perspective: 0.0 # 随机透视变换,设置为 0 禁用(二)训练
在目录下创建一个训练脚本: train.py
from ultralytics import YOLO
def train_model():
# 加载模型
model = YOLO("yolov8n.pt") # 第一次会自动下载到当前目录下
# 训练模1 参数自己设置,
model.train(
data='data.yaml', # 修改成自己的数据集 data.yaml 路径
epochs=700, # 训练轮次依据数据量大小调整,三千多条数据 采用早停法,大概训练了六百多次
imgsz=640, # 训练图像尺寸
device=0, # 运行设备,例如 device=0 或 device=0,1,2,3 或 device=cpu #"cpu"
batch=16, # 批量处理的数量需要根据自身电脑情况调整
workers=8, # 启用几个子进程并行处理数据 需要根据自身电脑情况调整
optimizer='AdamW', # 小数据集推荐AdmW而非SGD
lrf=0.01, # 最终学习了衰减比例
lr0=1e-3, # 学习率
weight_decay=5e-4, #防止过拟合
cos_lr=True, # 启用余弦退火
augment=True,
close_mosaic=0,
patience=100 #早停法,防止过拟合; 设置0,关闭早停,会直到epochs全部执行完
)
print('模型训练完毕')
# show = True 显示检测结果
# save = True 保存检测结果
#model("F:\\IMG_20250318_114327.jpg", show=True, save = True )
if __name__ == '__main__':
train_model()开始训练,运行:
python train.py
这个里方便截图,我练10,训练后会在runs/detect/train目录里,可以看到训练过程的评估指标变化。模型在weighter下,有个best.pt 和last.pt 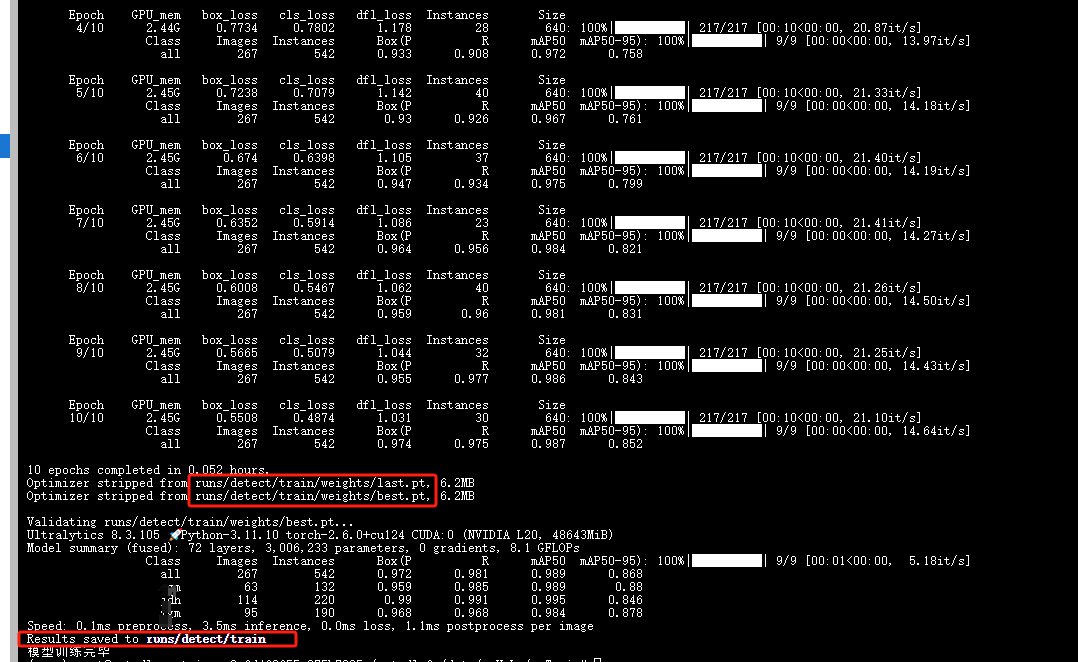
(三)模型验证
简单测试,就用前面的test.py 脚本,把模型路径换成训练好的 .pt 模型路径就行。
批量校验图片:以下是我写的一个简单粗暴的批量测法,目的是判断要检测的图片是否有我校验的类型,并将测试结果保存为result.csv文件。这样可以根据csv文件统计出准确率。
import os
import csv
from datetime import datetime
from ultralytics import YOLO
class YOLOImageProcessor:
def __init__(self, model_path, target_class_id=0):
self.model = YOLO(model_path)
self.target_class_id = target_class_id
self.results_list = []
def process_images(self, input_dir, output_dir):
# 确保输出目录存在
os.makedirs(output_dir, exist_ok=True)
# 遍历输入目录中的所有图片文件
for filename in os.listdir(input_dir):
if filename.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp', '.tiff')):
image_path = os.path.join(input_dir, filename)
result = self._process_single_image(image_path, output_dir)
# 记录结果
self.results_list.append({
"filename": filename,
"result": result,
"timestamp": datetime.now().strftime("%Y-%m-%d %H:%M:%S")
})
# 打印实时结果
print(f"处理文件: {filename} => 结果: {result}")
# 生成CSV报告
self._generate_csv_report()
print("处理完成,结果已保存至results.csv")
def _process_single_image(self, image_path, output_dir):
# 进行预测并保存结果图片
results = self.model.predict(
source=image_path,
project=output_dir,
name='predictions', # 固定子目录名称
exist_ok=True, # 允许目录已存在
save=True,
save_txt=False,
save_conf=True
)
# 检查是否包含目标类别
for result in results:
if self.target_class_id in result.boxes.cls.tolist():
return 1
return 2
def _generate_csv_report(self):
csv_path = "results.csv"
fieldnames = ["文件名", "检测结果", "时间戳"]
with open(csv_path, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for record in self.results_list:
writer.writerow({
"文件名": record["filename"],
"检测结果": "存在" if record["result"] == 1 else "不存在",
"时间戳": record["timestamp"]
})
if __name__ == "__main__":
# 配置参数(根据实际情况修改)
CONFIG = {
"model_path": "/root/autodl-fs/myYoLo/runs/detect/train/weights/best.pt", # 你的模型路径
"input_dir": "/autodl-fs/myYoLo/cheeckPic", # 输入要校验图片目录
"output_dir": "/root/autodl-fs/resultImg", # 结果图片保存目录
"target_class_id": 0 # 目标类别ID(根据你的模型定义修改) 就是data.yaml里[class0,class1,class2] 数组下角标 :0,1,2
}
processor = YOLOImageProcessor(
model_path=CONFIG["model_path"],
target_class_id=CONFIG["target_class_id"]
)
processor.process_images(
input_dir=CONFIG["input_dir"],
output_dir=CONFIG["output_dir"]
)(四)导出
注意导出onnx模型时候需要设置opset=11,不然导出模型可能会报错,或者会出现警告。此外,最好设置动态导出onnx,这样模型的输入就不会仅限制在640*640,而可以是任意batch_size还有任意尺寸的图片了,并且可以同时预测batch_size张图片。
from ultralytics import YOLO
if __name__=="__main__":
pth_path=r"/root/autodl-fs/myYoLo/runs/detect/jdh_zgm_gm3000/weights/best.pt"
# Load a model
#model = YOLO('yolov8n.pt') # load an official model
model = YOLO(pth_path) # load a custom trained model
# Export the model
model.export(format='onnx',opset=11,dynamic=True)或指令导出方式:
yolo export model=/root/autodl-fs/myYoLo/runs/detect/jdh_zgm_gm3000/weights/best.pt format=onnx opset=11 dynamic=True

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









