







 本文深入探讨了神经网络的基础概念,包括感知机、人工神经网络的结构与工作原理,以及卷积神经网络的特性。详细讲解了反向传播算法、交叉熵损失函数和优化策略在神经网络训练中的应用。并通过一个MNIST手写数字识别的例子,演示了如何使用TensorFlow实现神经网络。
本文深入探讨了神经网络的基础概念,包括感知机、人工神经网络的结构与工作原理,以及卷积神经网络的特性。详细讲解了反向传播算法、交叉熵损失函数和优化策略在神经网络训练中的应用。并通过一个MNIST手写数字识别的例子,演示了如何使用TensorFlow实现神经网络。
| 算法 | 策略 | 优化 |
|---|---|---|
| 神经网络 | 交叉熵损失 | 反向传播算法(梯度下降) |
1.感知机 2.人工神经网络
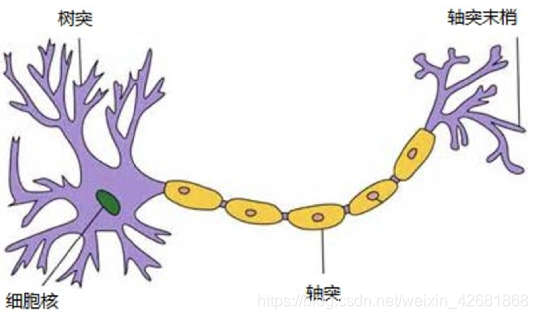
感知机:
有n个输入数据,通过权重与各数据之间的计算和,比较激活函数结果(和一个给定阀值比较),得出输出
应用:很容易解决与、或、非问题(分类问题)
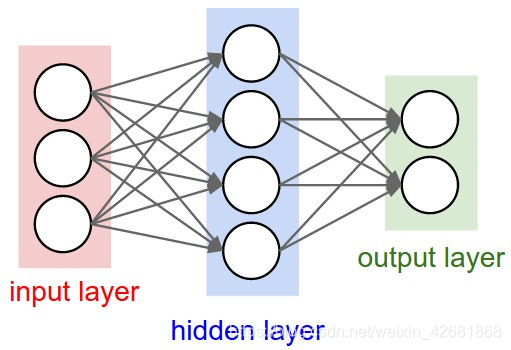
神经网络其实就是按照一定规则连接起来的多个神经元:
输入向量的维度和输入层神经元个数相同
第N层的神经元与第N-1层的所有神经元连接,也叫 全连接
上图网络中最左边的层叫做输入层,负责接收输入数据;最右边的层叫输出层,可以有多个输出层。我们可以从这层获取神经网络输出数据。输入层和输出层之间的层叫做隐藏层,因为它们对于外部来说是不可见的。
而且同一层的神经元之间没有连接,并且每个连接都有一个权值,
神经网络的种类:
基础神经网络:单层感知器,线性神经网络,BP神经网络,Hopfield神经网络等
进阶神经网络:玻尔兹曼机,受限玻尔兹曼机,递归神经网络等
深度神经网络:深度置信网络,卷积神经网络,循环神经网络,LSTM网络等
神经网络的组成:
结构(Architecture)例如,神经网络中的变量可以是神经元连接的权重
激励函数(Activity Rule)大部分神经网络模型具有一个短时间尺度的动力学规则,来定义神经元如何根据其他神经元的活动来改变自己的激励值。
学习规则(Learning Rule)学习规则指定了网络中的权重如何随着时间推进而调整。(反向传播算法)
神经网络的API模块:
(1)tf.nn :提供神经网络相关操作的支持,包括卷积操作(conv),池化操作(pooling),归一化,loss,分类操作,embedding,RNN,Evaluation
(2)tf.layers : 主要提供的高层的神经网络,主要和卷积相关得到,对tf.nn进一步封装。
(3)tf.contrib : tf.contrib.layers 提供将计算图中的网络层,正则化,摘要操作,是构建计算图的高级操作,但是 tf.contrib包不稳定及一些实验代码。
全连接层的神经元个数跟输出的类别数量相同
softmax 回归: 输出判定机制
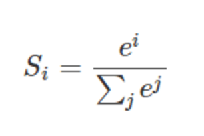
公式:第i种类的指数除以所有种类的指数的和 就表示数于 i 种类的概率
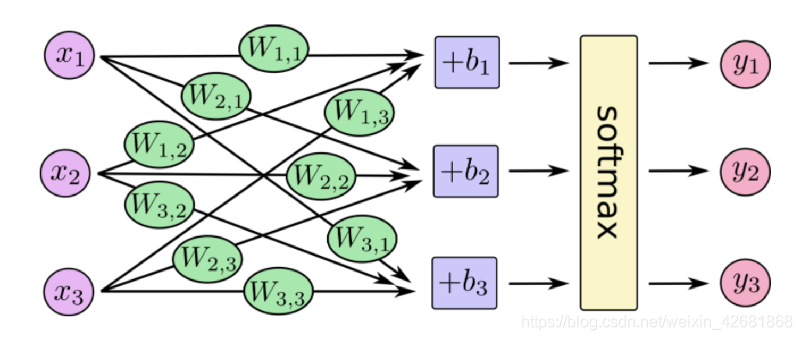
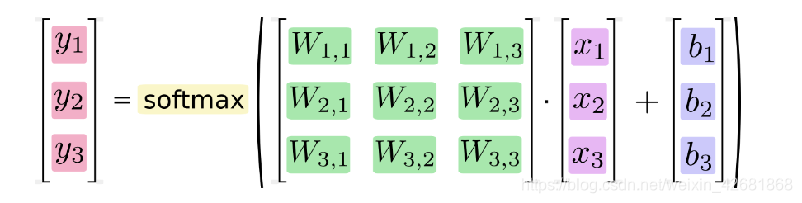
权重和偏置会被softmax转化为该样本所属每个类别的概率。所有类别的概率相加等于1 。softmax的核心就是其公式
得到样本所属类别的概率之后用one-hot编码输出预测的样本所属类别
损失计算:交叉熵损失
交叉熵损失公式:
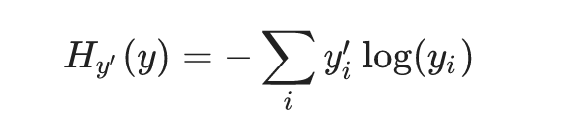
注:yi ’ 为神经网络结果, yi 为真实结果。每个类别都有一个损失结果,最后需要求平均损失
优化:反向传播算法(即梯度下降)
例:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
def minist(sess):
#引入数据
mnist = input_data.read_data_sets('./data', one_hot=True)
#建立输入数据占位符
x = tf.placeholder(tf.float32,[None,784])
#初始化权重与偏置
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
#输出结果y
y = tf.matmul(x,W) + b #这是预测值
#建立类别占位符
y_label = tf.placeholder(tf.float32,[None,10]) #这是真实值
#计算交叉熵损失值
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_label,logits=y)) #输入预测值和真实值,求出交叉熵,再求平均值
#生成优化损失操作
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(cross_entropy)
#比较结果
correcte_prediction = tf.equal(tf.arg_max(y,1),tf.arg_max(y_label,1))
#计算正确率平均值
accurency = tf.reduce_mean(tf.cast(correcte_prediction,tf.float32))
#
tf.summary.scalar("loss",cross_entropy)
tf.summary.scalar("accurency",accurency)
tf.summary.histogram("W",W)
#初始化变量
tf.global_variables_initializer().run()
#合并所有摘要:
mergy = tf.summary.merge_all()
summary_write = tf.summary.FileWriter('./book',session=sess)
#训练
for i in range(1000):
print("第%d次训练"%(i))
batch_xs, batch_ys = mnist.train.next_batch(100) #取出真实的特征值和目标值
sess.run(train_step,feed_dict={x:batch_xs,y_label:batch_ys})
print("准确率为:",sess.run(accurency, feed_dict={x: batch_xs, y_label: batch_ys}))
summary = sess.run(mergy,feed_dict={x: batch_xs, y_label: batch_ys})
summary_write.add_summary(summary,i)
return None
if __name__ == '__main__':
with tf.Session() as sess:
minist(sess)
卷积神经网络的特点:
1.局部连接: 这个是最容易想到的,每个神经元不再和上一层的所有神经元相连,而只和一小部分神经元相连。这样就减少了很多参数。
2.权值共享: 一组连接可以共享同一个权重,而不是每个连接有一个不同的权重,这样又减少了很多参数。
3.下采样: 可以使用Pooling来减少每层的样本数,进一步减少参数数量,同时还可以提升模型的鲁棒性。对于图像识别任务来说,卷积神经网络通过尽可能保留重要的参数,去掉大量不重要的参数,来达到更好的学习效果
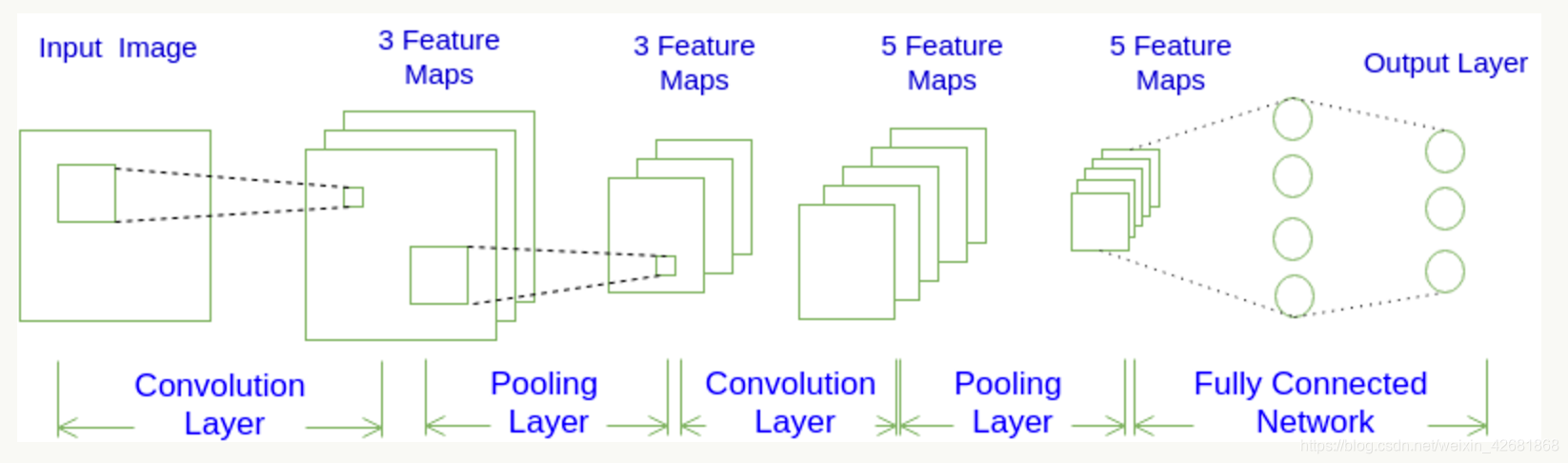
神经网络(neural networks)的基本组成包括输入层、隐藏层、输出层。而卷积神经网络的特点在于隐藏层分为卷积层和池化层(pooling layer,又叫下采样层)。
卷积层:通过在原始图像上平移来提取特征,每一个特征就是一个特征映射
池化层:通过特征后稀疏参数来减少学习的参数,降低网络的复杂度,(最大池化和平均池化)

卷积核在提取特征映射时的动作称之为padding(零填充),由于移动步长不一定能整出整张图的像素宽度。其中有两种方式,SAME和VALID :
SAME:越过边缘取样,取样的面积和输入图像的像素宽度一致。(在tf中如果指定了SAME,输入和输出大小就会一样)
VALID:不越过边缘取样,取样的面积小于输入人的图像的像素宽度
如果需要卷积之后输出大小一样:零填的大小为2
卷积网络API


Pooling层主要的作用是特征提取,通过去掉Feature Map中不重要的样本,进一步减少参数数量。Pooling的方法很多,最常用的是Max Pooling。
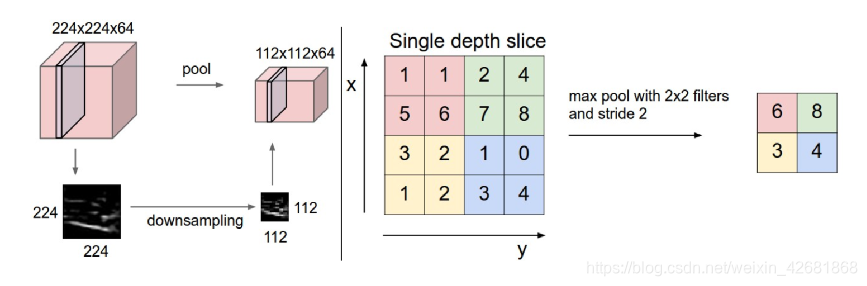

前面的卷积和池化相当于做特征工程,后面的全连接相当于做特征加权。最后的全连接层在整个卷积神经网络中起到“分类器”的作用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









