




 博客介绍了机器学习的一般过程,包括数据预处理、特征值提取、模型训练和模型评估。还提到在话题推荐前,通过用户行为获取话题偏好值,按运营逻辑划分权重,采用基于spark_mlib的ALS协同过滤推荐算法,且模型评估召回效果尚可。
博客介绍了机器学习的一般过程,包括数据预处理、特征值提取、模型训练和模型评估。还提到在话题推荐前,通过用户行为获取话题偏好值,按运营逻辑划分权重,采用基于spark_mlib的ALS协同过滤推荐算法,且模型评估召回效果尚可。
机器学习的一般过程分为以下四步:
①数据预处理
②特征值提取
③模型训练
④模型评估
1,在进行话题推荐之前,我们要获取用户对于话题的偏好值,根据用户的行为例如:点赞、评论、收藏、分享等等。按照运营的逻辑进行权重的划分得出用户对于话题的偏好值,数据格式如下:
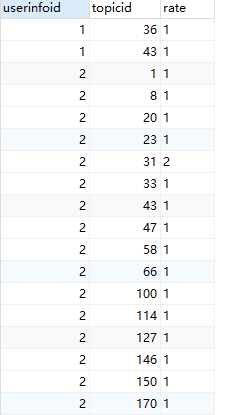
最高值为5分,采用的是基于spark_mlib的ALS协同过滤推荐算法。代码如下:
private val ratingRdd: RDD[UserRating] = spark.sparkContext.textFile(SOURCE_URL).map {
line =>
val fields = line.split("\\[")
val strings = fields(1).split("\\]")
val strings1 = strings(0).split(",")
UserRating(strings1(0).toInt, strings1(1).toInt, strings1(2).toDouble)
}
//用户数据集
val userRdd: RDD[Int] = ratingRdd.map(_.userinfoid).distinct()
//话题数据集
val topicRdd = ratingRdd.map(_.topicid).distinct()
//训练模型传参
val (rank, iterations, lambda) = (60, 15, 0.003)
//训练数据集
val trainData = ratingRdd.map(x => Rating(x.userinfoid, x.topicid, x.rate))
val model = ALS.train(trainData, rank, iterations, lambda)
//构建用户推荐矩阵
val userTopic: RDD[(Int, Int)] = userRdd.cartesian(topicRdd)
val praRatings = model.predict(userTopic)
val userRec: RDD[UserRecs] = praRatings.map(rating => (rating.user, (rating.product, rating.rating)))
.groupByKey()
.map {
case (uid, recs) => UserRecs(uid, recs.toList.sortWith(_._2 > _._2).take(USER_MAX_RECOMMENDATION).map(x => Recommendation(x._1, x._2)))
}
userRec.saveAsTextFile(OUTPUT_URL)
spark.close()
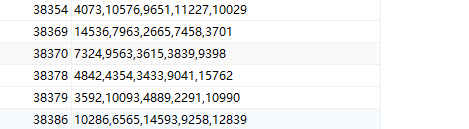
部分结果如图,对于模型评估,召回也是可以的

















 505
505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









