




简介
在Pytorch 2.x中,引入了torch.compile特性,主要包含如下4个部分:
TorchDynamo:基于Python Frame Evaluation Hook技术,实现安全的Pytorch的计算图捕获。
AOTAutograd: AOT生成计算图的反向图。
PrimTorch:规范化2000+ PyTorch Operators为250+ Primitive Operators, 极大降低了开发Pytorch后端的难度。
TorchInductor:一个Deep Learning Compiler,为多种加速器生成高性能代码。对NVIDIA和AMD GPUs, 使用OpenAI Triton编译器作为Backend。
torch.compile编译过程如下:
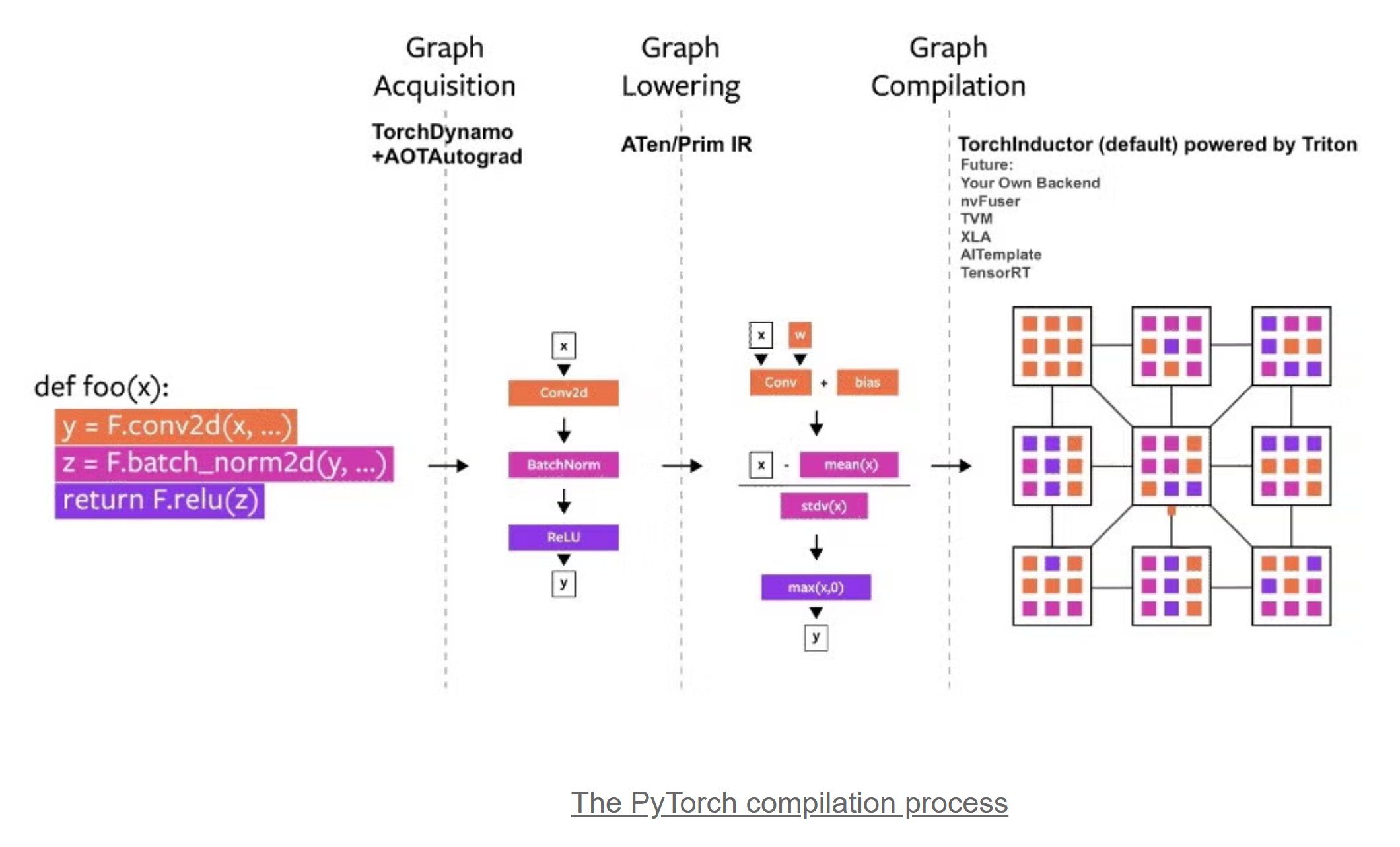
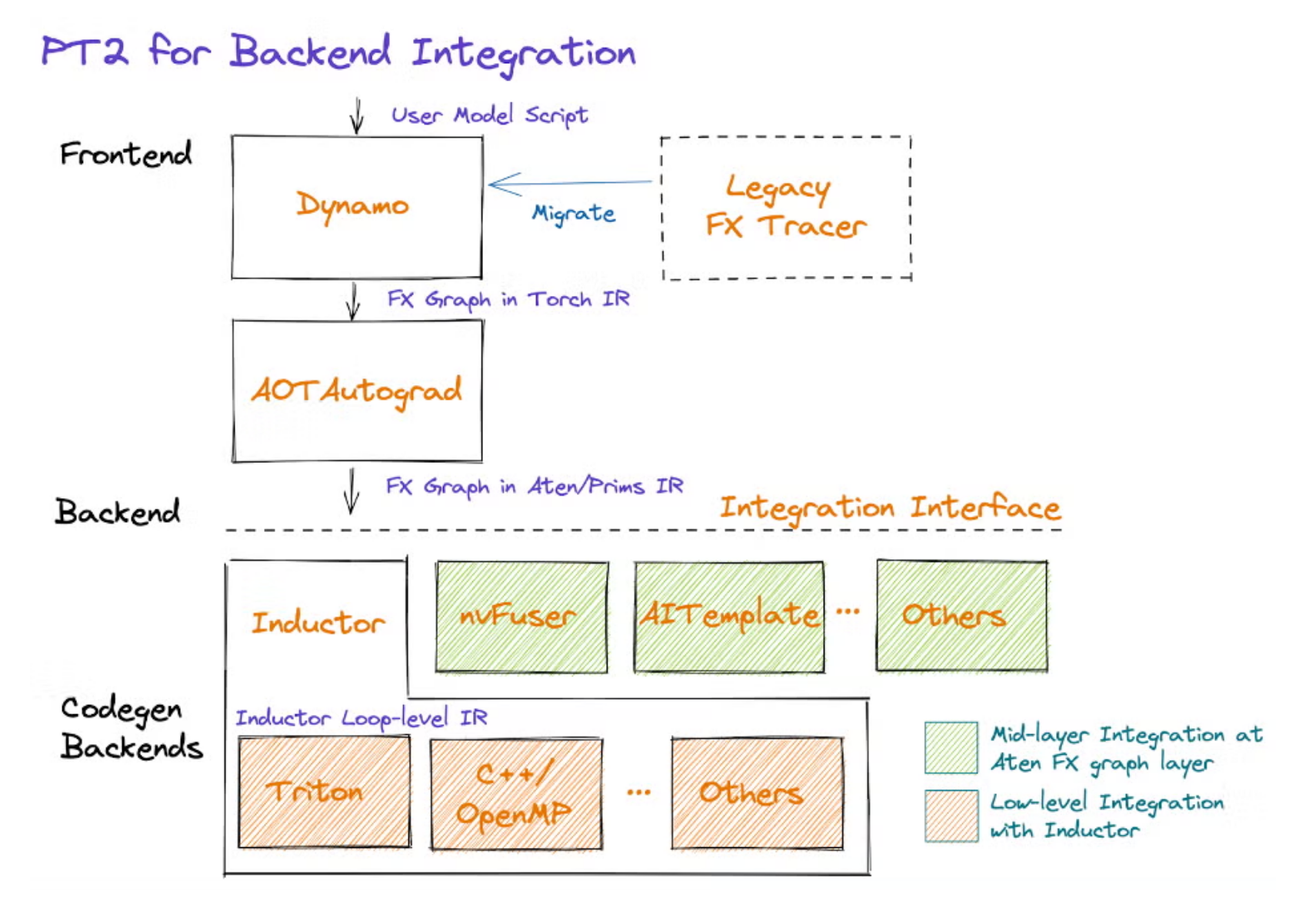
在图编译视角下,Pytorch的软件栈如下,Triton是Inductor的一个Codegen Backend:
 示例
示例
以如下pytorch代码为例:
import torch
def mul(x1, x2):
return x1 * x2
x1 = torch.randn(4096, 390, device='cuda', requires_grad=True)
x2 = torch.randn(4096, 390, device='cuda', requires_grad=True)
fn = torch.compile(mul, backend='inductor')
out = fn(x1, x2)
out.sum().backward()编译过程
在pytorch/torch/_inductor/codecache.py中的write函数打印调用栈,观察torch.compile的实际编译过程:
def write(
content: Union[str, bytes],
extension: str,
extra: str = "",
hash_type: str = "code",
specified_dir: str = "",
) -> Tuple[str, str]:
# use striped content to compute hash so we don't end up with different
# hashes just because the content begins/ends with different number of
# spaces.
print('#######################################################')
import traceback
traceback.print_stack()
...前向图编译
通过分析调用栈,可以看到:
- JIT编译:前向图的编译在调用编译的模型时触发:out = fn(x1, x2),并不是在fn = torch.compile(mul, backend='inductor')时触发。
- TorchDynamo:从out = fn(x1, x2)到return compile_fx(model_, inputs_, config_patches=self.config)完成了Python Bytecode捕获,并转换为FX Graph。
- AOT Autograd:从return compile_fx(model_, inputs_, config_patches=self.config)到return self.compiler_fn(gm, example_inputs),完成了反向图FX Graph的生成和Autograd注册,为后续反向图编译打下了基础。
- Inductor:从return inner_compile到return self._compile_to_module实现了FX Graph到Triton Kernel的编译。
File "/home/vincent/mul.py", line 10, in <module>
out = fn(x1, x2)
File "/home/vincent/pytorch/torch/_dynamo/eval_frame.py", line 574, in _fn
return fn(*args, **kwargs)
File "/home/vincent/pytorch/torch/_dynamo/convert_frame.py", line 1380, in __call__
return self._torchdynamo_orig_callable(
File "/home/vincent/pytorch/torch/_dynamo/convert_frame.py", line 1164, in __call__
result = self._inner_convert(
File "/home/vincent/pytorch/torch/_dynamo/convert_frame.py", line 547, in __call__
return _compile(
File "/home/vincent/pytorch/torch/_dynamo/convert_frame.py", line 986, in _compile
guarded_code = compile_inner(code, one_graph, hooks, transform)
File "/home/vincent/pytorch/torch/_dynamo/convert_frame.py", line 715, in compile_inner
return _compile_inner(code, one_graph, hooks, transform)
File "/home/vincent/pytorch/torch/_utils_internal.py", line 95, in wrapper_function
return function(*args, **kwargs)
File "/home/vincent/pytorch/torch/_dynamo/convert_frame.py", line 750, in _compile_inner
out_code = transform_code_object(code, transform)
File "/home/vincent/pytorch/torch/_dynamo/bytecode_transformation.py", line 1361, in transform_code_object
transformations(instructions, code_options)
File "/home/vincent/pytorch/torch/_dynamo/convert_frame.py", line 231, in _fn
return fn(*args, **kwargs)
File "/home/vincent/pytorch/torch/_dynamo/convert_frame.py", line 662, in transform
tracer.run()
File "/home/vincent/pytorch/torch/_dynamo/symbolic_convert.py", line 2868, in run
super().run()
File "/home/vincent/pytorch/torch/_dynamo/symbolic_convert.py", line 1052, in run
while self.step():
File "/home/vincent/pytorch/torch/_dynamo/symbolic_convert.py", line 962, in step
self.dispatch_table[inst.opcode](self, inst)
File "/home/vincent/pytorch/torch/_dynamo/symbolic_convert.py", line 3048, in RETURN_VALUE
self._return(inst)
File "/home/vincent/pytorch/torch/_dynamo/symbolic_convert.py", line 3033, in _return
self.output.compile_subgraph(
File "/home/vincent/pytorch/torch/_dynamo/output_graph.py", line 1101, in compile_subgraph
self.compile_and_call_fx_graph(
File "/home/vincent/pytorch/torch/_dynamo/output_graph.py", line 1382, in compile_and_call_fx_graph
compiled_fn = self.call_user_compiler(gm)
File "/home/vincent/pytorch/torch/_dynamo/output_graph.py", line 1432, in call_user_compiler
return self._call_user_compiler(gm)
File "/home/vincent/pytorch/torch/_dynamo/output_graph.py", line 1462, in _call_user_compiler
compiled_fn = compiler_fn(gm, self.example_inputs())
File "/home/vincent/pytorch/torch/_dynamo/repro/after_dynamo.py", line 130, in __call__
compiled_gm = compiler_fn(gm, example_inputs)
File "/home/vincent/pytorch/torch/__init__.py", line 2340, in __call__
return compile_fx(model_, inputs_, config_patches=self.config)
File "/home/vincent/pytorch/torch/_inductor/compile_fx.py", line 1863, in compile_fx
return aot_autograd(
File "/home/vincent/pytorch/torch/_dynamo/backends/common.py", line 83, in __call__
cg = aot_module_simplified(gm, example_inputs, **s 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 783
783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









