







 本文详细介绍了KNN算法的基本原理、可视化实现和在手势识别中的应用,强调了数据预处理、距离度量和K值选择的重要性。同时,探讨了稠密SIFT(DSIFT)的原理,用于提取图像特征,并展示了如何将其应用于手势识别系统,通过实验获得了约74%的分类准确率。
本文详细介绍了KNN算法的基本原理、可视化实现和在手势识别中的应用,强调了数据预处理、距离度量和K值选择的重要性。同时,探讨了稠密SIFT(DSIFT)的原理,用于提取图像特征,并展示了如何将其应用于手势识别系统,通过实验获得了约74%的分类准确率。
一、knn可视化:
1、knn算法简单介绍:
KNN是一种监督学习算法,通过计算新数据与训练数据特征值之间的距离,然后选取K(K>=1)个距离最近的邻居进行分类判(投票法)或者回归。若K=1,新数据被简单分配给其近邻的类。
2、算法描述:
从训练集中找到和新数据最接近的k条记录,然后根据多数类来决定新数据类别。
如下图:
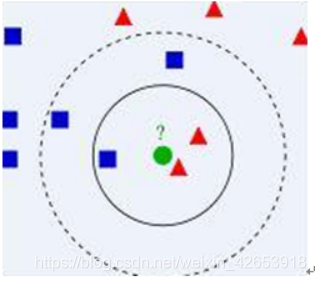
(1) 已知两类“先验”数据,分别是蓝方块和红三角,他们分布在一个二维空间中;
(2) 有一个未知类别的数据(绿点),需要判断它是属于“蓝方块”还是“红三角”类;
(3) 考察离绿点最近的3个(或k个)数据点的类别,占多数的类别即为绿点判定类别。
3、knn算法实现过程:
(1)选择一种距离计算方式, 通过数据所有的特征计算新数据与已知类别数据集中的数据点的距离;
(2)按照距离递增次序进行排序,选取与当前距离最小的k个点;
(3)对于离散分类,返回k个点出现频率最多的类别作预测分类;对于回归则返回k个点的加权值作为预测值;
4、算法的关键:
(1)数据的所有特征都要做可比较的量化
若是数据特征中存在非数值的类型,必须采取手段将其量化为数值。例如样本特征中包含颜色,可通过将颜色转换为灰度值来实现距离计算。
(2)样本特征要做归一化处理
样本有多个参数,每一个参数都有自己的定义域和取值范围,他们对距离计算的影响不一样,如取值较大的影响力会盖过取值较小的参数。所以样本参数必须做一些scale处理,最简单的方式就是所有特征的数值都采取归一化处置。
(3)需要一个距离函数以计算两个样本之间的距离
距离的定义:欧氏距离、余弦距离、汉明距离、曼哈顿距离等,一般选欧氏距离作为距离度量,但是这是只适用于连续变量。在文本分类这种非连续变量情况下,汉明距离可以用来作为度量。通常情况下,如果运用一些特殊的算法来计算度量的话,K近邻分类精度可显著提高,如运用大边缘最近邻法或者近邻成分分析法。
(4)确定K的值
K值选的太大易引起欠拟合,太小容易过拟合。交叉验证确定K值。
5、knn可视化的实现:
在此次实验中运用的度量方式是欧式距离度量法。欧几里得度量是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离),在二维和三维空间中的欧氏距离就是两点之间的实际距离,当然在此次实验中主要度量二维空间的距离,度量方式为:
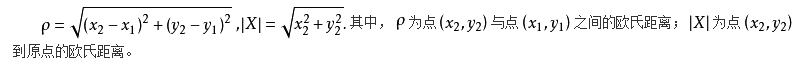
from numpy import *
class KnnClassifier(object):
def __init__(self,labels,samples):
""" 使用训练数据初始化分类器"""
self.labels = labels
self.samples = samples
def classify(self,point,k=3):
""" 在训练数据上采用K邻近分类,并返回标记""
# 计算所有训练数据点的额距离
dist = array([L2dist(point,s) for s in self.samples])
# 对它们进行排序
ndx = dist.argsort()
# 用字典存储K近邻
votes = {}
for i in range(k):
label = self.labels[ndx[i]]
votes.setdefault(label,0)
votes[label] += 1
return max(votes, key=lambda x: votes.get(x))
def L2dist(p1,p2):
return sqrt( sum( (p1-p2)**2) )
def L1dist(v1,v2):
return sum(abs(v1-v2))
我们首先建立一个简单的二维实例数据集来说明并可视化分类器的工作原理,下面的脚本将创建两个不同的二维点集,每个集点有两类,并用pickle模块来保存创建的数据:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2086
2086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









