









发现一篇多模态大模型+Mamba效果很好的论文,上周刚刚发表,论文提出了Multimodal Mamba多模态解码器模型,通过将Transformer模型的知识蒸馏到线性复杂度的Mamba架构中,实现了20.6倍的速度提升和75.8%的GPU内存节省。
这效果在MLLM+Mamba一众成果中也算非常突出。近些年MLLM发展迅猛,再加上Mamba高效的分布式计算和强大的上下文理解能力,MLLM+Mamba这一结合已是当前极具潜力的研究方向,不仅有很高的创新性(比如高效架构、动态建模),在实际应用中前景也非常广阔(比如机器人、边缘计算)。
如果有论文需求,且对这方向感兴趣,推荐从混合架构设计、跨模态对齐、轻量化部署等方向切入,现在有不少具体的实验设计和技术细节值得参考(比如Robomamba、LongLLaVA)。我挑选了12篇MLLM+Mamba新成果(包括开源代码),需要参考的同学可无偿获取~
全部论文+开源代码需要的同学看文末
Multimodal Mamba: Decoder-only Multimodal State Space Model via Quadratic to Linear Distillation
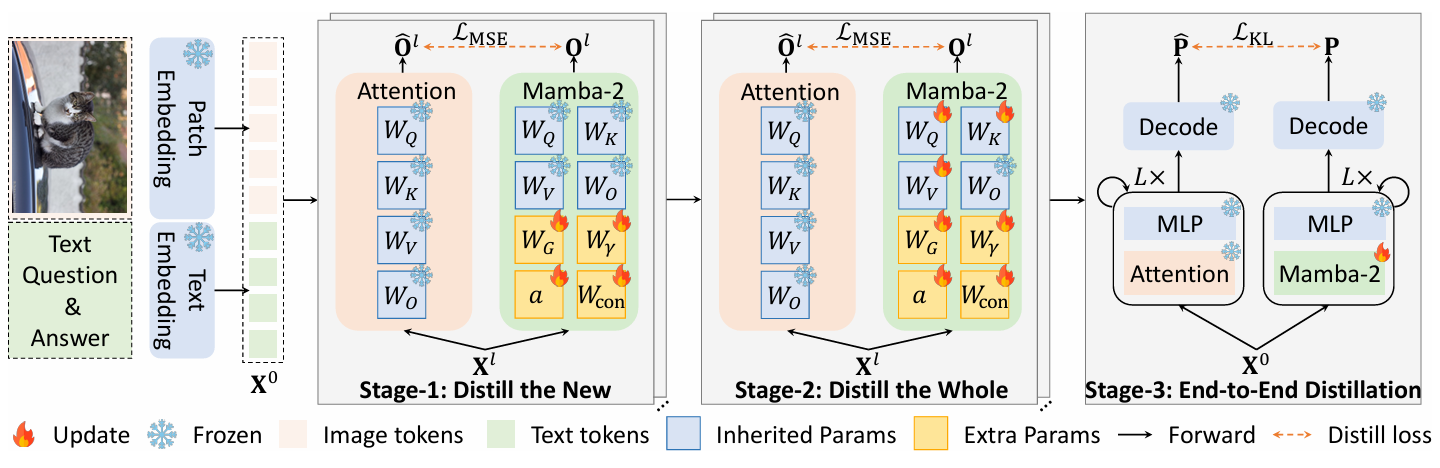
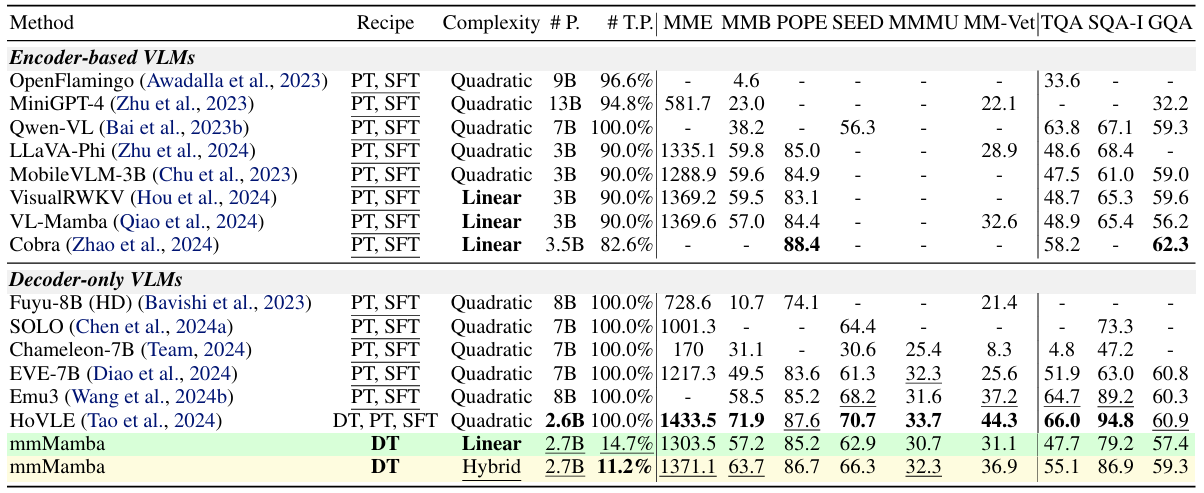
方法:论文介绍了一个名为 mmMamba 的多模态大模型,它通过将现有的基于 Transformer 的多模态大语言模型(MLLMs)通过知识蒸馏转换为线性复杂度的解码器-only(decoder-only)状态空间模型,具体使用了 Mamba-2 作为核心架构。
创新点:
-
提出了一种新的基于蒸馏的方法来构建线性复杂度的解码器仅视觉语言模型(VLM),无需依赖预训练的线性复杂度语言模型(LLM)和视觉编码器。
-
开发了一种三阶段的渐进式蒸馏策略,用于从二次复杂度架构向线性复杂度架构的有效知识转移。
-
提出的mmMamba混合架构结合了Transformer层和Mamba-2层,能够在性能和计算效率之间达到灵活的平衡。
Vl-mamba: Exploring state space models for multimodal learning
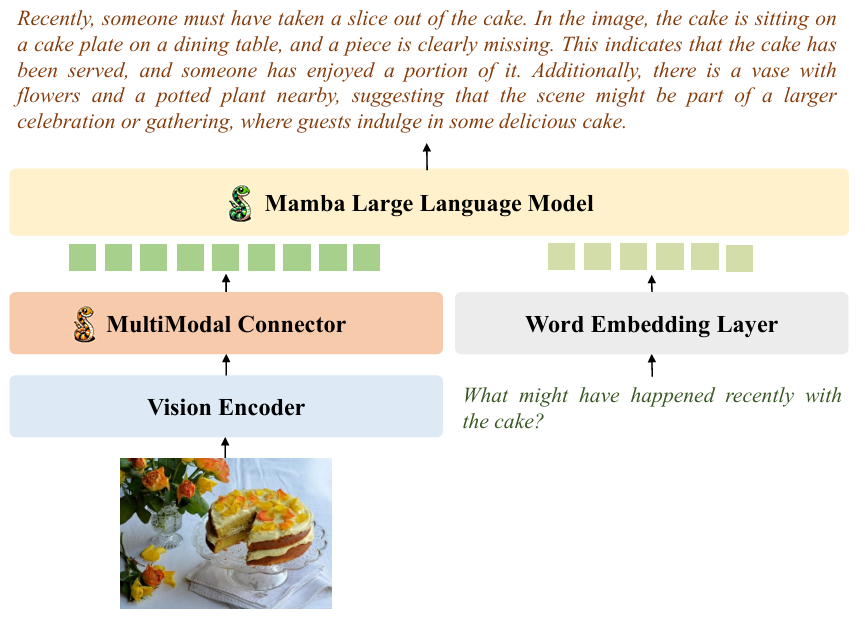
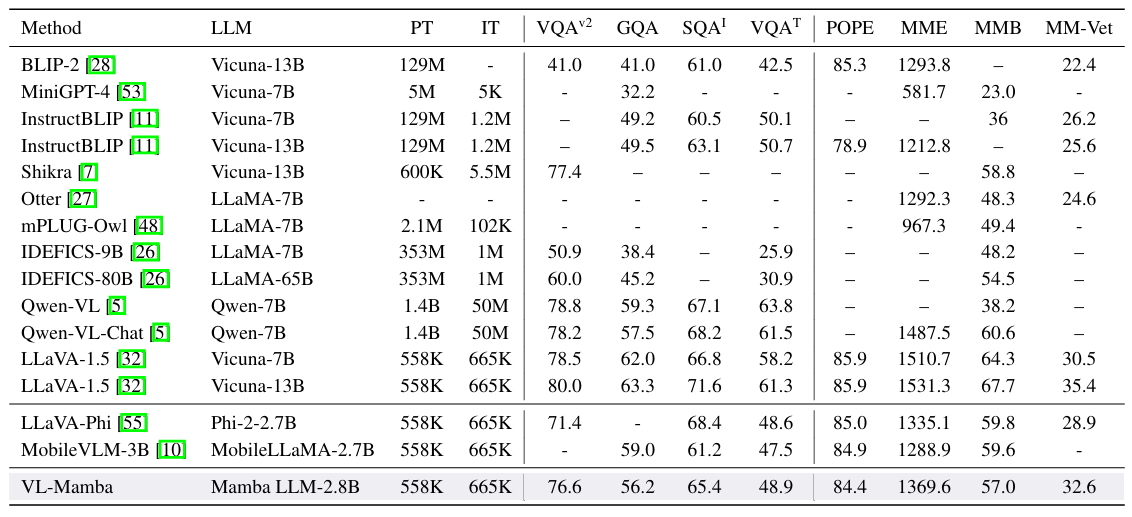
方法:论文介绍了一个名为 VL-Mamba 的多模态大模型,这是首个利用状态空间模型Mamba解决多模态学习任务的工作,通过研究多模态连接器的三种架构并引入视觉选择扫描(VSS)模块来弥合2D非因果图像信息与状态空间模型(SSMs)固有因果建模能力之间的差距。
创新点:
-
VL-Mamba是首个利用状态空间模型来解决多模态学习任务的工作。
-
在多模态连接器中引入视觉选择扫描机制(VSS),包括双向扫描机制(BSM)和交叉扫描机制(CSM),以增强对视觉序列的二维因果建模能力。
-
探索了不同视觉编码器、Mamba语言模型变体以及多模态连接器的组合。
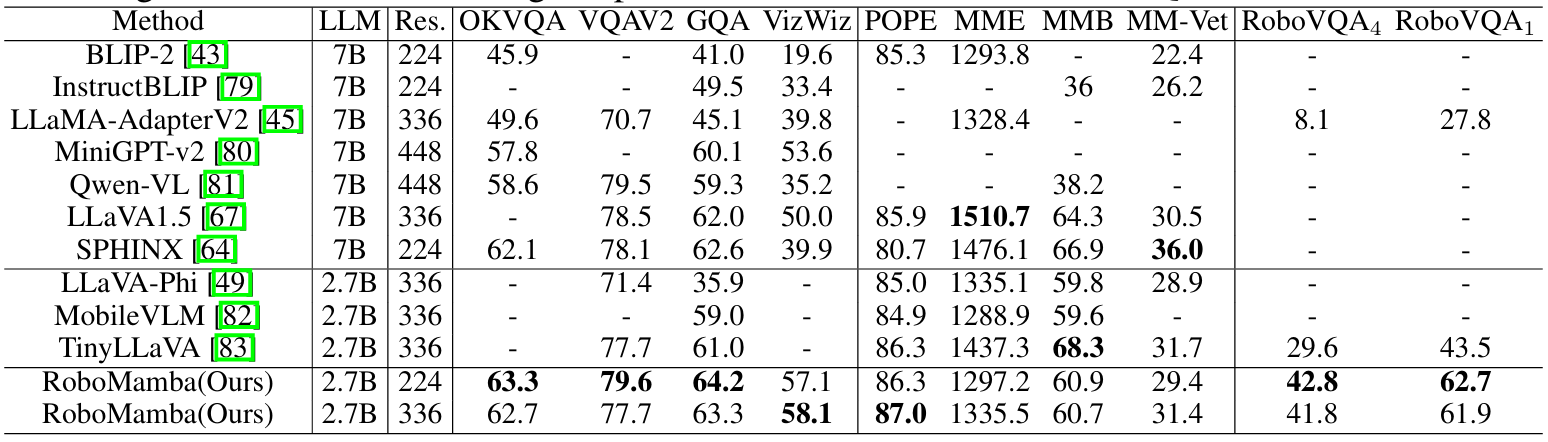
Robomamba: Multimodal state space model for efficient robot reasoning and manipulation
方法:论文介绍了一个名为 RoboMamba 的多模态大模型,它结合了 Mamba 语言模型,用于机器人视觉、语言和动作(VLA)任务。具体来说,RoboMamba 旨在解决机器人操作中的两个关键挑战:推理能力不足和计算成本高。
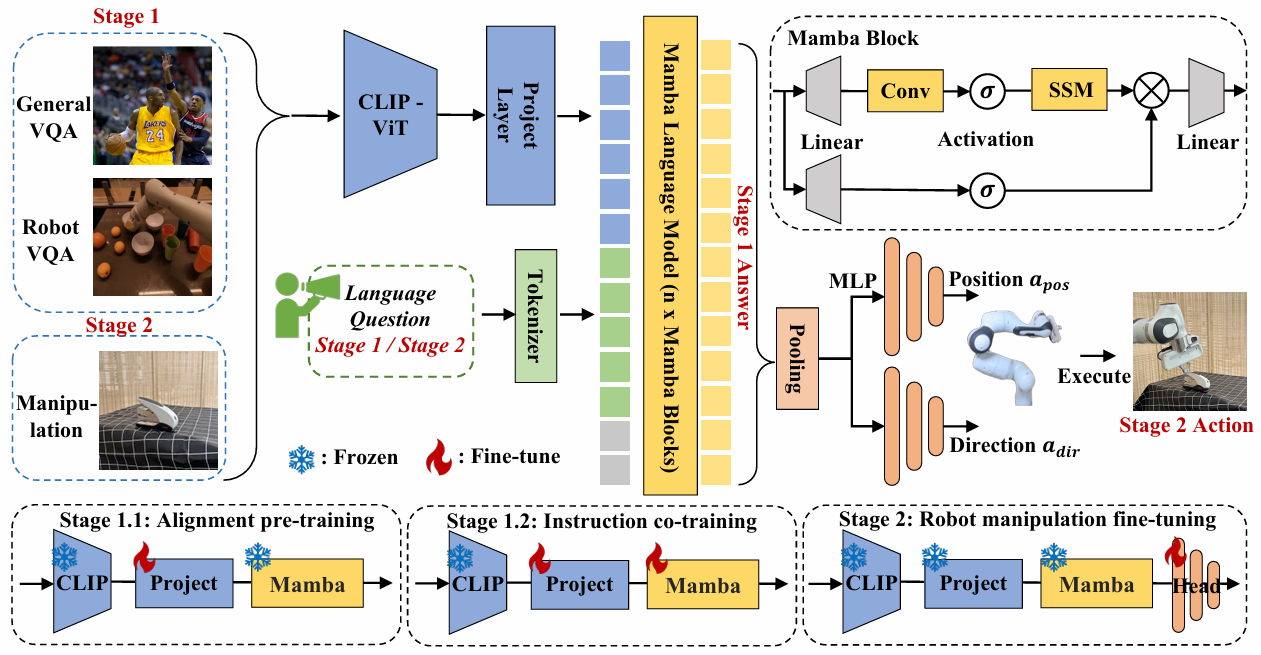
创新点:
-
通过冻结RoboMamba的大部分参数,仅引入简化的策略头(policy head)进行微调,显著降低训练资源消耗。
-
设计了一个不依赖于复杂视觉编码器集成的简单模型架构,通过CLIP视觉编码器提取视觉特征并连接至LLM,利用多层感知机(MLP)实现视觉信息到语言嵌入空间的转换。
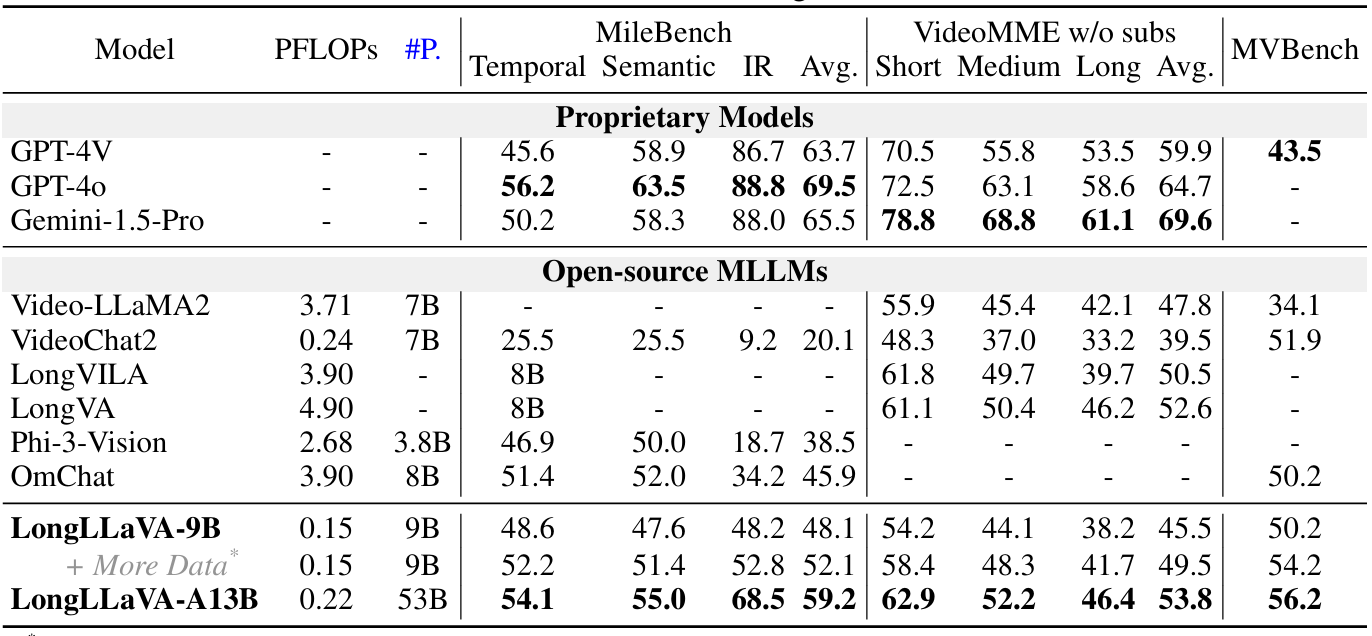
LOOONGLLAVA: SCALING MULTI-MODAL LLMS TO 1000 IMAGES EFFICIENTLY VIA A HYBRID ARCHITECTURE
方法:论文介绍了一种结合了多模态大模型和 Mamba 架构的混合模型,名为 LongLLaVA。通过引入混合架构、数据处理协议和训练策略等创新方法来提升LongLLaVA在长上下文、多图像场景中的表现,解决性能下降和高计算成本问题。
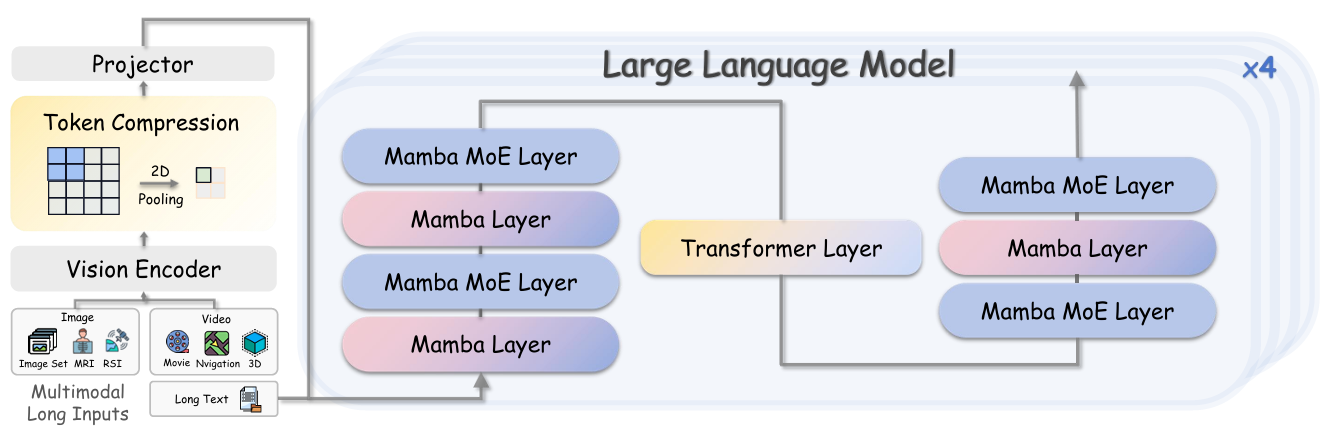
创新点:
-
LongLLaVA通过整合Mamba和Transformer模块,首次在多模态长上下文理解中引入混合架构。
-
在高分辨率图像处理和需要详细图像理解的场景中,LongLLaVA通过将图像分解为子图像,强调对这些子图像之间空间依赖关系的把握。
-
LongLLaVA在理解多模态长上下文方面表现出色,特别是在VNBench的检索、计数和排序任务中表现领先。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“多模态曼巴”获取全部方案+开源代码
码字不易,欢迎大家点赞评论收藏

















 1552
1552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









