







 本文介绍了如何使用Python的lxml库和XPath语法从网页中抓取数据,包括爬取指定HTML结构的内容并下载图片,同时处理了并发请求和文件管理。
本文介绍了如何使用Python的lxml库和XPath语法从网页中抓取数据,包括爬取指定HTML结构的内容并下载图片,同时处理了并发请求和文件管理。
实战4 xpath解析数据
代码思路
- 爬取网页数据str
- 将str实例化为extree对象:extree.HTML
- 通过extree.xpath和xpath语句实现提取指定文本。
- 保存文件
注意:xpath可以通过鼠标右键检查目标文本,而后右键复制xpath路径
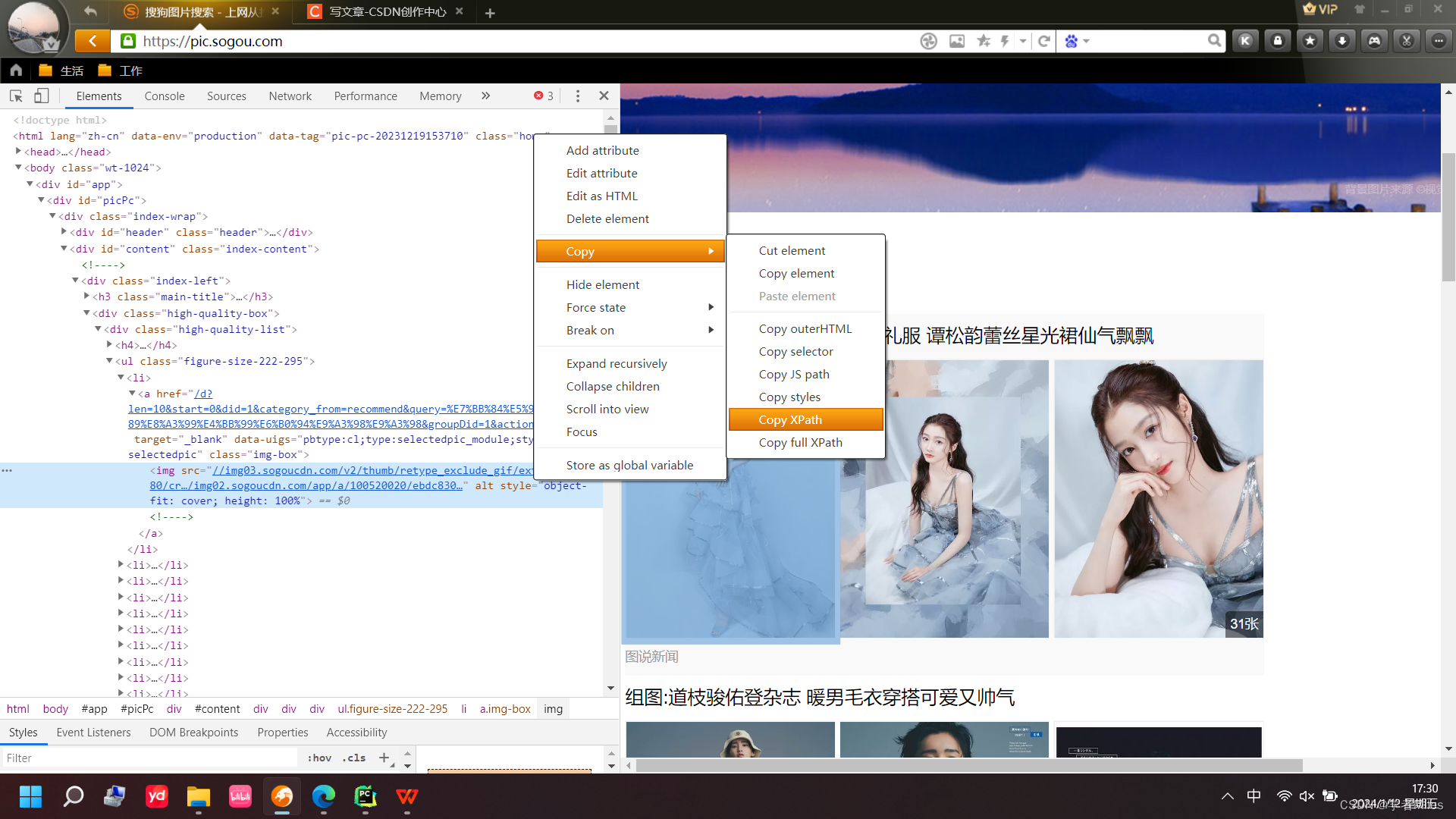
前置环境
安装pip install xlml
完整代码
# 爬虫实战5,xpath解析数据
pass # 这是分隔符
# 1、导入库
import os
import requests
import time
from lxml import etree
t1 = time.thread_time() # 测试开始时间
# 2、爬取数据
url = "https://pic.sogou.com/"
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36"
}
if os.path.exists("./img"):
os.system(f'attrib -r "./img"')
os.remove('./img')
os.mkdir("./img",mode=1) # 创建图片存储路径
# 1.网页爬取
# page_Text = requests.get(url,headers=headers)
# with open('123.html','wb') as f:
# f.write(page_Text.content) # 保存html log
# tree = etree.HTML(page_Text.content) # 导入HTML数据
# 2.本地读取再转换
with open('123.html',mode='r',encoding='utf-8') as f:
str1 = f.read()
tree = etree.HTML(str1) # 导入本地HTML文档
# 3.本地直接读取
# tree = etree.parse('123.html')
# 3、提取数据
# str = tree.xpath('/html/body/div')
# str = tree.xpath('//div[@class="index-left"]') # 使用xpath表达式定位标签,返回为对象;'//'表示多个层级,可以从任意层级开始查找; '@class=""'为属性定位
# str = tree.xpath('//*[@id="content"]//a//text()') # xpath索引是从1开始的;//text()是读取标签的text属性
str = tree.xpath('//*[@id="content"]/div[1]/div/div[1]/ul//img/@src') # @src为读取标签的src的属性
print(str)
print(f"找到了{len(str)}个数据") # @src为查找所有属性为src的标签
for i in str:
i = 'https:' + i
print(i)
img_data = requests.get(url=i,headers=headers).content # 在取得完整的image url后,获取图片数据
# 4、保存数据
img_name = i.split('/')[-1] # 获取image名称
imgPath = 'img\\'+img_name+".png" # image存储路径
with open(imgPath,'wb') as f:
f.write(img_data)
time.sleep(0.05) # 不要太频繁提取数据,否则会被认为是在攻击网站
print(f"use time : {0}",time.thread_time() - t1) # 打印测试耗时
pass # 这是分隔符

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









