







 该博客围绕大数据展开,涵盖Linux集群搭建、HDFS、MapReduce、Hive等知识,介绍Flume、Azkaban、Sqoop使用,阐述离线项目流程,包括数据采集、清洗、仓库设计、ETL、统计分析等,最后给出面试相关的集群配置和框架运行建议。
该博客围绕大数据展开,涵盖Linux集群搭建、HDFS、MapReduce、Hive等知识,介绍Flume、Azkaban、Sqoop使用,阐述离线项目流程,包括数据采集、清洗、仓库设计、ETL、统计分析等,最后给出面试相关的集群配置和框架运行建议。
day01-day02 初始大数据
0.linux集群情况
1. window 宿主192.168.137.188
node01.hadoop.com node01 192.168.137.100 00:50:56:3D:7D:CC root 123456
node02.hadoop.com node02 192.168.137.110 00:50:56:3D:2F:CC root 123456
node03.hadoop.com node03 192.168.137.100 00:50:56:28:C3:E8 root 123456
2. 软件安装情况
node01
zookeeper hadoop jdk8 /export/servers
flume(数据采集框架) /export/servers
hive
impala
kafka node01:9092 keadmin, 移除topic
es user:es passwd:es
nodejs
kibana
node02
zookeeper hadoop jdk8 /export/servers
flume(数据采集框架) /export/servers
hive
impala
kafka
node03
zookeeper-3.4.5-cdh5.14.0.tar hadoop-2.6.0-cdh5.14.0-src.tar jdk8 /export/servers
hive(数据仓库) /export/servers 端口:jdbc:hive2://node03.hadoop.com:10000
flume(数据采集框架) /export/servers
azkaban-solo(任务调度框架) /export/servers 端口:http://node03:8081 azkaban azkaban
mysql root 123456 azkaban azkaban
azkaban-server/exec 两个执行任务的,一个web 端口:https://node03:8443 azkaban azkaban
sqoop
hive
impala
hue(图形界面,可以操作其他组件) node03:8888 root 123456
oozie(天生分布式) node03:11000
kafka-eagle-bin-1.2.2.aaa.tar node03:8408/ke admin 123456
kafka_2.11-1.0.0
1. 集群情况
| node01 | node02 | node03 | |
|---|---|---|---|
| hdfs | namenode 主节点 存储元数据信息,接收读写请求 | ||
| secondarynamenode 辅助节点, | |||
| datanode从节点 存储数据(文件,文件夹) | datanode从节点 | datanode 从节点 | |
| yarn | resoucemanager 接收计算任务,负责分配资源 | ||
| nodemanager 执行分配的任务 | nodemanager | nodemanager |
2. 软件安装
2.1 安装jdk
- rpm -qa | grep java 查找自带的java
- rpm -e xxx -nodeps 不考虑依赖删除java包
- rpm -ivh 客户端程序 --nodeps --force 安装rpm包
- vim /etc/profile
export JAVA_HOME=/exoprt/servers/jdk1.8.0_141
exoprt PATH=$JAVA_HOME/bin:$PATH
- source /etc/profile 重新编译
- java -version java javac
2.2 安装zookeeper
- cd /export/servers/zookeeper-3.4.5-cdh5.14.0/conf mv zoo_xxx.xxx zoo.cfg
- mkdir -p /export/servers/zookeeper-3.4.5-cdh5.14.0/zkdatas
- vim zoo.cfg
- 修改dataDir=创建的目录
- 放开3 1
- 配置集群关系 server.1=node01.hadoop.com node01 server.2=node02.hadoop.com node02 server.3=node03.hadoop.com node03
- zkdatas 目录下 echo 1 > /export/servers/zookeeper-3.4.9/zkdatas/myid
- 发送到另外两台 修改myid
- 启动集群
- bin 目录下 sh zkServer.sh start | status | stop
- sh zkCli.sh 退出是quit
2.3 安装hadoop伪分布式集群
-
hadoop目录结构
- bin sbin 存放执行的脚本
- etc/hadoop 配置文件
- lib/native hadoop本地库, 存放了以下c程序
- bin/hadoop checknative 检查hadoop本地库支持什么的
- hadoop: 支持c程序访问hadoop集群
- snappy: appach公司的hadoop软件包天使不支持snappy压缩库, cloudera CDH5需要编译
- bin/hadoop checknative 检查hadoop本地库支持什么的
-
修改6个配置文件
-
core-site.xml 核心配置文件 绝对是分布式还是单节点 决定namenode在哪台服务器上
<property> <name>fs.default.name</name> <value>hdfs://192.168.52.100:8020</value> </property> -
hdfs-site.xml hdfs配置文件, 指定元数据存放位置(2个位置), datanode节点数据存放位置(1个位置)
并指定外界浏览器访问的端口号50070
<!-- 一部分元数据存放的位置 --> <property> <name>dfs.namenode.name.dir</name> <value>file:///export/servers/hadoop-2.6.0- cdh5.14.0/hadoopDatas/namenodeDatas</value> </property> <!-- 定义dataNode数据存储的节点位置,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 --> <property> <name>dfs.datanode.data.dir</name> <value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/datanodeDatas</value> </property> <!-- 另外一部分元数据存放的位置 --> <property> <name>dfs.namenode.edits.dir</name> <value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/edits</value> </property> -
hadoop-evn.sh 环境变量
-
marped-site.xml mapreduce 配置文件 指定了jobhistoryserver节点在哪台机器上&外界访问端口
<property> <name>mapreduce.jobhistory.webapp.address</name> <value>node01:19888</value> </property> -
yarn-site.xml 指定主节点在哪台服务器上, 外键默认访问端口号80888
-
slaves 指定从节点在哪台服务器上
-
-
增加文件夹, 因为刚才配置数据存放位置都是需要创建文件夹的,
- 先dh -lh 看看磁盘空间
- 然后创建
mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/tempDatas mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/namenodeDatas mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/datanodeDatas mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/edits mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/snn/name mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/snn/edits -
配置环境变量
-
分发到其他台服务器上
-
启动集群
-
首次启动一定要格式化hdfs hdfs -namenode format 很重要, 只执行这一次
-
单个节点启动
hadoop-daemon.sh start namenode yarn-daemon.sh start resourcemanager sbin/mr-jobhistory-daemon.sh start historyserver #----------------------------------- hadoop-daemon.sh start datanode yarn-daemon.sh start nodemanager -
脚本一次启动
cd /export/servers/hadoop-2.6.0-cdh5.14.0/ sbin/start-dfs.sh sbin/start-yarn.sh sbin/mr-jobhistory-daemon.sh start historyserver
-
-
外键访问界面
- node01:50070 hdfs界面 可以看到存储的数据
- node01:80888 yarn界面
- node01:19888 mapreduce jobhistory历史任务界面
-
为什么要重新编译hadoop
- 为了支持c程序
- 为了支持snappy压缩,天生不支持snappy压缩
3. shell 编程
-
#!/bin/bash 使用哪种解析器解析脚本
-
sh xxx.sh 执行脚本
-
变量 除了变量不空格,其他都空格
- $1 $2 ${10} xxx.sh 脚本中获取命令窗口传递过来的参数
- a= 1 b = 1 b= 1b=var $var 脚本中调用变量(调用的变量需要初始化,也就是要有初始值)
-
参数的传递
- $n 接收传递的第n个参数
- $@ 接收全部参数 数组格式
- $* 接收全部参数 拼接为字符串
- $# 几个参数
-
计算
expr $a + $b- c=$(( $a + $b )) 或者 count=1 (( count++ ))
- d=$[ $a + $b ]
-
比较运算符
- [ $a -eq $b ] [ $a -gt $b ] [ $a -lt $b]
-
选择
#!/bin/bash a=$1 b=$2 if[ $a -eq $b] then echo $a 等于 $b elif[ $a -gt $b ] then echo $a 大于 $b else echo $a 小于 $b fi # --------------命令窗口执行 sh hello.sh 20 30 -
循环
#!/bin/bash for n in $@ do echo $n done # --------------命令窗口执行 sh hello.sh 20 30 40 50 -
函数
#!/bin/bash funshow(){ # 使用$@ 接收调用本参数时传递的参数 for n in $@ do echo $n done } # 脚本中调用自定义的函数, 使用$@接收命令行传递的所有参数 funshow $@ # ---------------命令行执行 sh hello.sh 20 30 40
4. zookeeper集群介绍
-
可以理解为交通路况的红绿灯, 负责协调指挥, 功能:
- 统一命名服务 dubbo
- 分布式配置管理 solr cloud
- 分布式的消息队列 pub/sub 类似于activeMQ
- 分布式锁
- 分布式协调
pdsh,Puppet也可以管理集群
-
zookeeper特性
全局数据一致性:所有的机器看到的数据都是一样的
可靠性:如果消息被一台服务器接收,那么终将被所有的服务器接收
顺序性:如果A消息在B消息之前发布,那么所有的机器都是先处理A消息,再处理B消息
数据更新的原子性:我们所有的操作都是事务性的操作,要么全部成功,要么全部失败,没有中间状态
实时性:消息最终会被同步到所有的机器上面去
-
主从+准备
- 主节点 负责处理事务&非事务请求, 用户就算增删改请求发送到从节点上,也要把请求转发到主节点,主节点执行后,会把数据同步给其他从节点
- 从节点 负责处理非事务请求,用户就算把读请求发送到主节点上, 主节点也会把请求转发到从节点上去(空闲着的), 从节点将数据读取出来发送给客户端
- 观察者, 增大并发请求, 不参与投票,也就是增加机器是为了增加并发而不是高可用
-
数据结构 二叉树, 每一个节点叫做znode
-
zookeeper节点
- 有一个同意的根路径 /
- 两个类 四小类
- persistent 服务器关闭,永久节点才会xiao
- persistent normal 创建时不可以重名
- persistent sequential创建时可以重名, 有序的,向上的
- ephemeral 临时节点只有客户端已关闭, 就会消失
- ephemeral normal
- ephemeral sequential
- persistent 服务器关闭,永久节点才会xiao
- 创建序列化节点可以重名, 非序列化节点不可以重名,命令窗口create节点写数据无法写入空格
- cretae [-e] [-s] /aaa hello
- ls /hello
- ls2 /hello
- get /hello
- set /hello world
- rmr /hello
- 节点兼具文件和文件夹的特性最多1M
- 只有永久节点才可以创建子节点,临时节点无法创建子节点
- 临时节点+watch监听器
- get /zhangsan 再开一个窗口连接客户端就修改数据 第一个窗口就能监听到了 NodeDataChange
- ls /zhangsan 窗口2给/zhangsan节点下面新增一个节点 窗口1 NodeChildChange
- 特点
- 一次有效
- 异步
- 先注册有触发
-
javaAPI 节点操作套路
- 获取连接
- 执行
- create(), set(), get(), delete()
- 关闭连接(注意,临时节点&监听器关闭连接就会失效)
- 监听器,有一个treeCacheEvent
- treeCacheEvent.getType() type 是事件
- NODE_ADDED
- NODE_REMOVED
- NODE_UPDATED
- NODE_INITALIZED
- treeCacheEvent.getData() data 是datanode上面的数据
- treeCacheEvent.getType() type 是事件
5. hadoop 2.x 高可用集群介绍
-
hdfs分布式文件存储系统(赋值文件的存储+查询),
主从模式,无主备—就是主节点死了,从节点不会成为主节点,需要我们手动搭建备份节点 hdfs ha
- namenode 主节点,存储&管理元数据信息, 接收客户端的请求
- 元数据:描述数据的数据 大小 类型 位置 权限等等 , 和数据本身无关, 根据元数据可以知道存储的数据在哪里
- secondarynamenode 辅主主节点管理元数据
- datanode 从节点 存储数据(文件 文件夹都叫做数据)
- journalnode 同步数据的节点(namenode active–namenode standby),让两个namenode元数据相同,防止脑裂
- ZKFC hdfs的守护进程, 时不时的摸一摸namenode的心跳, 当节点死去,让standby成为active
- namenode 主节点,存储&管理元数据信息, 接收客户端的请求
-
yarn 资源调度系统
- resourcemanager 接收用户的计算任务, 分配资源(cpu 内存), 不分配任务
- nodemanager 执行分配的任务
6. hdfs命令
hdfs文件都是以/开头的, 和zookeeper中节点类似
6.1 普通命令
- hdfs dfs -ls /
6.2 限额
- 限制文件个数 hdfs dfadmin -setQuota
- 限制大小 hdfs dfadmin -setSpaceQuota
- 取消 hdfs dfadmin -clrQuota/SpaceQuota url
- 查看 hdfs dfs -count -q -h url
6.3 安全模式
- hadoop开启后,默认进入安全模式(只能读取数据), 30s后退出安全模式
- 手动开启安全模式hdfs dfsadmin -safemode enter|leave , 手动进入安全模式,必须手动退出才可以
6.4 使用mapreduce程序测试
- 写入数据 20-30M/s
- 读取数据 50-100M/s
7. HDFS入门
分布式文件存储系统, 可以理解为一块磁盘, 每个服务器磁盘之和
- 主从架构,没有主备,要想实现主备需要配置高可用
- 分块存储 hdfs-site.xml配置 每块默认128M
- 名字空间 core-site.xml 第一行配置 绝对是分布式还是单机版本
- namenode元数据管理 目录j结构&文件分块信息叫做元数据
- datanode数据存储
- 副本机制, 几个从节点就几个副本
- 一次写入,多次读出 读多写少
day03 HDFS增强
1. hdfs注意事项
- 一个block 默认128M, 3个副本 hdfs-site.xml进行设置
- 小文件会占用元数据内存,但不会占用磁盘空间
- hdfs写入数据时, packet 64KB 会有acs检查机制 使用UDP协议
- 假设数据1G, 需要准备13倍的内存(至少准备13倍)
- flume数据先采集过来 3倍
- 清洗非结构化数据–>结构化数据 6倍
- ods 构建外部表, 会将flume数据采集的位置剪切到对应的hive文件夹下面–> 不重新占内存
- dw --> 会映射过来(3份), 9倍
- app --> 会映射过来(3份), 12倍
- mr程序,会产生中间数据(1份), 13倍
2. hdfs写入流程
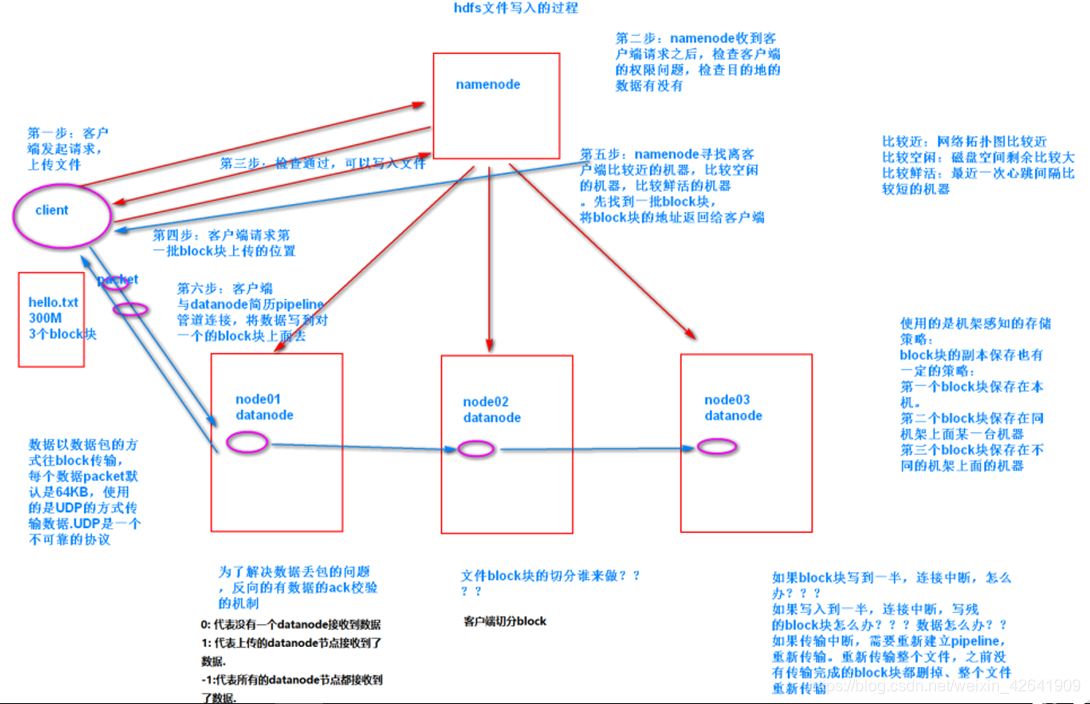
3. hdfs 读取流程

4. hdfs元数据合并
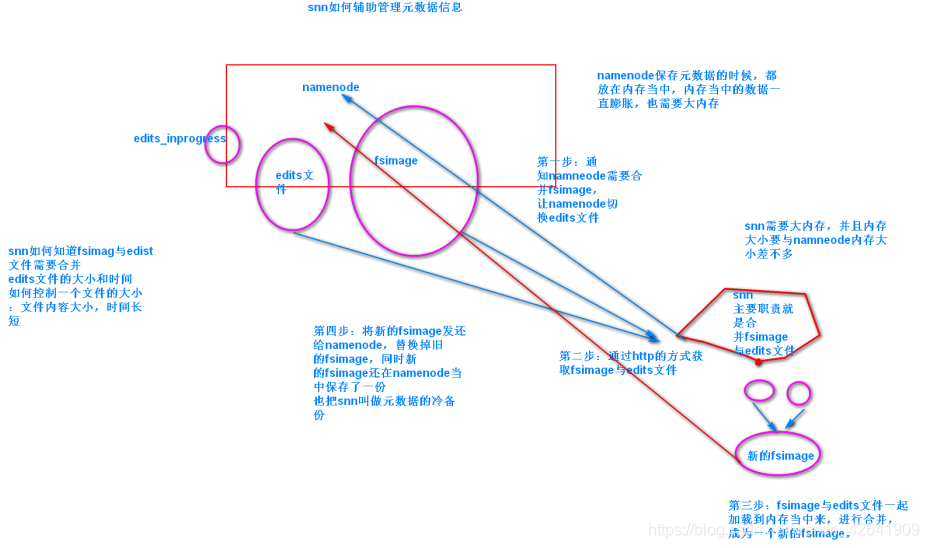
5. 小文件合并(上传到hdfs前合并)
- java代码就是一个中介, 符合copy输入流到输出流中
- 通过分布式文件系统对象,获取输出到hdfs的输出流
- 获取本地文件系统对象, 遍历本地path对象, 通过本地文件系统对象打开输入流(读取小文件)
- 读取的同时, copy(输入流, 输出流), 每次copy完后,关闭本地输入流
- for循环结束后,关闭分布式文件系统的输出流对象
6. mr入门
- 读取文件, k1(行偏移量) , v1(一行内容)
- TextInputFormat
- 自定义map逻辑, 输出k2(切割后的每个单词), v2(1)
- 分区(相同给的k2发送到同一个reduce中)
- 默认使用hashPartitioner
- 排序(局部排序)
- WritableComparable
- 规约
- mapreduce当中调优的手段。combiner就是一个reducer的程序、combiner是运行在map端的一个reduce程序,reducer是真正运行在reduce端的一个程序
- 分组(k2合并,v2形成集合), 分组内的排序是全局排序
- WritableComparator
- 自定义reduce逻辑, k2,v2–>k3 v3
- 输出k3, v3
- TextOutputFormat
7. 手写wordCount
day04 Mapreduce增强
1. block
hdfs上面一个block只能存储同一个文件的数据,
一个空文件夹不会产生block, 但会产生元数据
2. 删除非空目录和文件才可以使用 -rmr
如果是空目录,直接mv剪切走
3. 排序

- 想按照什么排序, 什么就放到k2位置
- 想按照什么求和,什么就放到k2位置
4. mapreduce 整个过程注意事项
- map中有shuffle阶段的3个步骤, 环形缓存区 默认100M, 80%会触发溢写程序, 从环形缓存区(内存)–>内存或磁盘或内存+磁盘
- maptask的个数取决于TextInputFormat的个数, 取决于inputSplit的个数,
- inputSplit的大小取决于 mapred.min.split.size & mapred.max.split.size 的配置,如果不配置, inputSplit的大小默认为128M, 也就是一个block的大小
- 所以,默认情况下 有多少个block,就要多少个maptask
- reduceTask 的个数 取决于job.setReduceNumTasks()
- 默认reduceNum为1, 使用的是HasPartitioner 实现了Partitioner
- reduceNumTask的个数不会小于分区的个数
- 如果是手动实现Partitioner, 需要手动设置reduceNumTask的个数
- 如果reduceNumTask个数小于分区个数 报错 10块砖 只有5个人搬
- 如果reduceNumTask个数大于分区个数 产生空文件 10块砖 只有15个人搬
- 如果reduceNumTask个数等于分区个数 正好 10块砖 只有10个人搬
- 默认reduceNum为1, 使用的是HasPartitioner 实现了Partitioner
- 压缩机制
- map输出数据压缩
- reduce输出数据压缩 snappy appach天生不支持这种编译, 需要手动编译
- 计数器 TaskCounter
- 规约 基础reducer map阶段就合并相同k2的数据, 减少k2数据量的传输
5. join(数据倾斜)
- map join
- block缓存, 需要把要缓存的数据上传到hdfs系统,然后缓存到block中
- map逻辑中setup()从缓存中读取出来
- 字符缓存流
- 字节流–>字节转换流(字节流+编码集)–>字符缓存流
- map逻辑map 再合并数据
- reduce join
- reduce逻辑中拼接数据
6. 读取本地文件
- 读取本地文件,也会有block, 但是不会有副本
- 只能从hdfs上放到block缓存中
7. 案例
- 分区 按照手机号分区
- 排序 定义一个SortBean implements WritableComparable<SortBean>
- 重写compareTo(SortBean o)方法,
- 0:相等
- 正数:前者比后者大(默认排到后面)
- 负数:前者比后者小
- 重写compareTo(SortBean o)方法,
- 规约 combiner 就是一个map端的reduce
- 每个mapTask输出的数据先进行一次合并, 合并后再发送到reduce端
- 减少k2的传输量, 提高网络IO的性能
day05 maprduce高阶训练
1. io流
- 字节流 --> 转为字符缓存流

- 字节流–> 字节数组
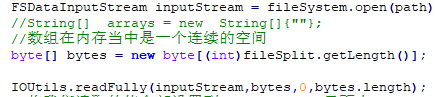
2. 案例
- 查询共同好友
- hdfs小文件合并,自定义fileInputFormat
- 上传文件后, 分文件夹, 自定义fileOutputFormat
- 分组求topN, 自定义compator,
- 按照pid 分区, 分组(同一组的数据,调用一次reduceTask), 如果不分组, 就每一条数据调用一次reduceTask
- 按照money排序
3. mapreduce任务调度流程
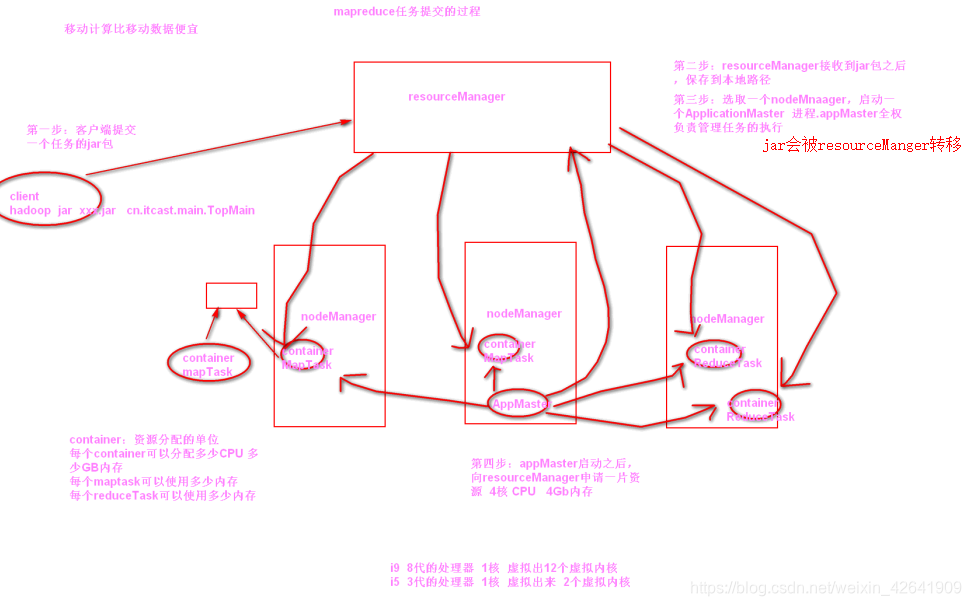
3.1 yarn的基本介绍
yarn的主要作用:管理任务,调度资源
resourceManager:主节点,主要用于接收客户端的请求,分配资源
nodeManager:从节点,主要是用于执行我们的任务,说白了就是提供cpu和内存的
ApplicationMaster:主要用于申请资源,分配资源,分配任务,任务生命周期的管理
container:资源分配的单位,所有的任务执行,都在container里面,主要用于分配资源,以及回收资源
JobHistory:查看历史完成的任务的日志
TimeLineServer:2.4以后引入的新特性 查看正在执行的任务的情况
3.2 yarn当中的调度器
调度器:主要是用于研究一个任务提交之后,下一个任务又来了该怎么执行。决定我们任务如何进行执行
yarn当中的调度器主要用三种
-
第一种:队列调度器 FIFO。第一个任务提交,先执行,然后第二个任务提交,等着第一个任务执行完毕之后再执行第二个任务
第一个任务:大任务,需要运行4个小时
第二个任务:小任务,需要运行3分钟
这种调度器没人用,不管是apache软件的版本,还是CDH软件的版本 hadoop1.x使用的就是这种版本
-
第二种调度器:capacity Scheduler 容量调度器 apache的版本默认使用的调度器
-
将整个资源,划分成好多块。
根据我们提交的任务需要资源的大小,将我们的任务,划分到不同的资源队列里面去,可以允许多个任务并行的快速的执行
-
缺点:将资源给划散了
-
-
第三种调度器:Fair scheduler 公平调度器 CDH的软件默认使用的调度器
第一个任务提交,将所有的资源 全部分配给第一个任务,保证第一个任务最快的完成
第二个任务提交:从第一个任务当中划分一部分资源出来,给第二个任务进行执行
- 缺点:造成资源的频繁的分配
- 优点:可以快速的执行我们的一些大任务
-
交换区空间大小:如果内存不够用了,找一块磁盘,当做内存来用
磁盘大小定义 2.1 * 内存大小
day06 hive(数据仓库)
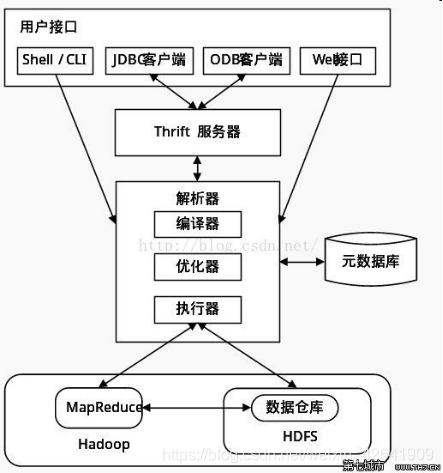
0. hive概述
-
三种交互方式
-
依赖hdfs&yarn, 底层mr查询数据
-
解析(hql)–编译(hql)–优化(hql)生成查询计划保存在hdfs中–执行mr
1. 数据仓库
- 面向主题的(非关系型), 集成的,非易失的(数据不可以变),时变的(分析手段)
- 只支持数据的添加和查询,不可以删除数据或修改数据
- 分层
- 数据源层: ODS 从外界(hadoop就是从hdfs)抽取数据EXTRA
- 数据仓库层:DW 使用hql语句转换 transform
- 应用层:APP 结果分析, 展示
2. hive小结
-
交互方式
-
bin/hive --service hiveserver2 ---->后台 nohup bin/hive --service hiveserver2 &
nohup bin/hive --service metastore &(impala需要)
-
bin/beeline
beeline> !connect jdbc:hive2://node03.hadoop.com:10000
-
-
ruduce设置方式
set hive.enforce.bucketing=true;
set mapreduce.job.reduces=3; -
分区表要手动映射关系 msck repair table score4;
-
创建表
create [external] table score_third(sid string, c_id string, s_score int) partitioned by(month string) clustered by(sid) into 3 buckets row format delimited fields terminated by ‘\t’;
可以指定表存在的位置, 这个目录可以存在也可以不存在
- 如果目录不存在, 会创建这个目录,在这个目录下面创建一个表名文件夹
- 如果目录存在, 直接将数据导入到该目录下
-
加载数据
-
通过load方式加载数据
(无法加载数据到分桶表中) ; 如果是从hdfs上面被load的数据会被剪切到score表文件夹下面
load data [local] inpath ‘/export/servers/hivedatas/score.csv’ overwrite into table score partition(month=‘201801’);
-
通过查询方式加载数据
-
create table score4 like score; 复制表结构
-
可以加载数据到任何类型的表中
insert overwrite[关键字overwrite 必须要有] table score_third partition(month=‘201801’) select s_id,c_id,s_score from score [where month=‘201805’] [cluster by(s_id)];
-
-
查出来的数据直接下载到本地 (不能指定到/)
insert overwrite local ‘/export/servers/hivedatas/随便起名字’ select myfunc(jsonstr) from temp_table;
-
-
开启本地模式
set hive.exec.mode.local.auto=true;
set hive.exec.mode.local.auto.inputbytes.max=51234560;
set hive.exec.mode.local.auto.input.files.max=10; -
小技巧
-
清屏 ctrl + l
-
查看表结构: desc fromatted 表名
-
查看内置函数如何使用: desc function extended upper;
hive客户端添加jar包
add jar /export/servers/hive-1.1.0-cdh5.14.0/lib/json.jar;
create temporary function strToJson as ‘cn.itcast.udf.StrToJson’;
-
3. 小结2
- 内部表,
- 外部表(删库不删数),
- 分区表, 通过insert方法加载分区表中的数据要注意, 不能select * , 要select具体字段, 查出来的字段比要添加的多, 因为添加的表已经指定字段了
- 分通表, 分文件的, cluster by(c_id)
4. 排序
- order by
- sort by
- distrubute by
5. 杂记
设计分布式数据仓库hive的数据表时,为取样更高效,一般可以对表中的连续字段分桶
6. hive当中数据存储格式&压缩格式选择
6.1 hive当中的存储格式
-
数据的存储格式主要分为两大类,一类是行式存储,一类是列式存储
-
行式存储:TextFile,SequenceFile。
- textFile 行式存储
- sequenceFile 二进制的行式存储
-
列式存储:Parquet ,Orc。
-
orc,一个orc文件,由多个stripe组成。一个stripe由三部分构成
indexData:存储了row data里面的索引的数据
row data:数据都存在row data里面
stripe footer:stripe的元数据信息,第多少个stripe,上一个stripe是哪一个,下一个stripe是哪一个
-
parquet twitter + cloudera公司 合作开发 列式存储
-
-
-
主流文件存储格式的对比
原始文件18.1M
- textFile存储格式 18.1M
- orc存储格式 2.8M 两方面的原因 第一方面数据格式更加紧凑,占用磁盘空间比较少。第二方面:orc自带了一种压缩算法
- parquet 存储格式:13.1M
存储文件的压缩比总结:
ORC > Parquet > textFile
-
文件的查询速度
log_text 9.756 seconds
log_orc 9.513 seconds
log_parquet 10.628 seconds
查询速度总结:log_orc > log_text > log_parquet
6.2 存储与压缩结合使用
建表的时候既要指定我们的存储格式,也要指定我们的压缩方式
如果建表的时候指定存储格式为orc,不指定任何的压缩算法,18.1M的文件变成了7.7M
如果文件存储格式指定为orc,压缩方式知道个为snappy,18.1M的文件变成了3.8M
实际工作当中,一般自己使用建立的内部表数据,存储格式都是使用orc,压缩方式都是使用的snappy
7. hive内置函数
-
UDF(User-Defined-Function)
一进一出
-
UDAF(User-Defined Aggregation Function)
聚集函数,多进一出
类似于:count/max/min -
UDTF(User-Defined Table-Generating Functions)
一进多出 如lateral view explore()
day07 flume & azkaban & sqoop
0. flume运行
- 设置配置文件
- flume需要依赖JDK, flume.env中要配置JDK的环境变量
- flume家目录中运行
- bin/flume-ng agent -n a1 -c conf -f conf/spooldir.conf -n a1 -Dflume.root.logger=INFO,console;
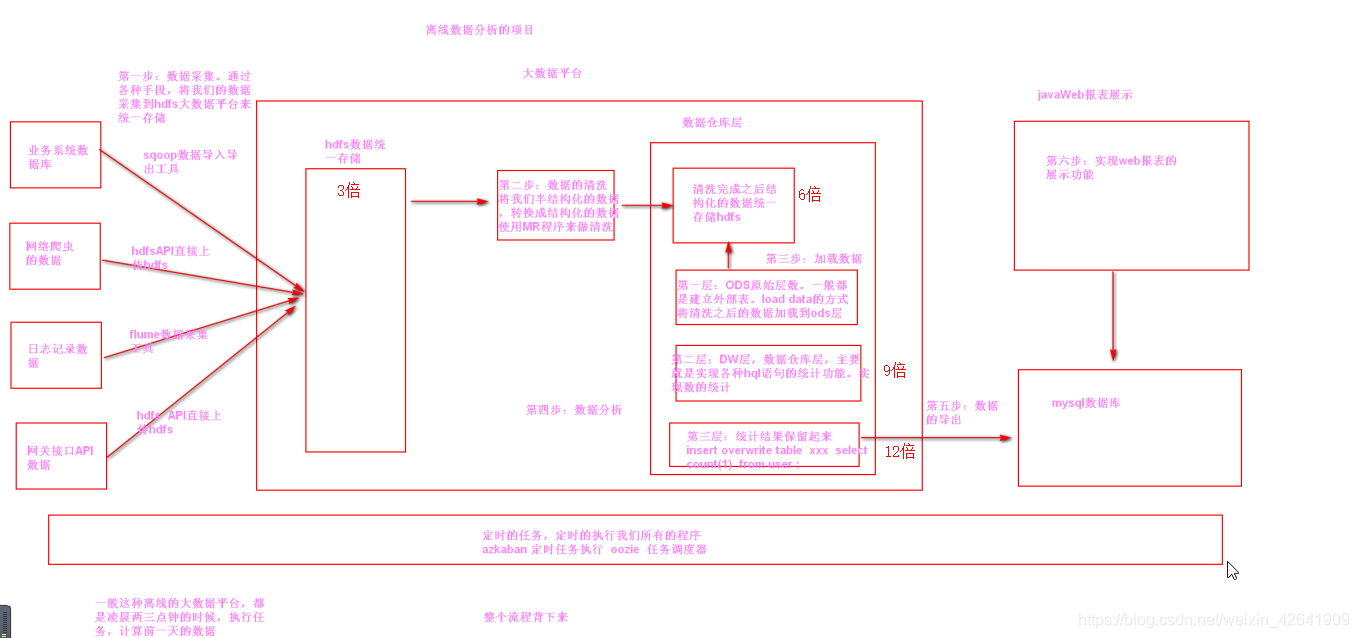
1. 离线数据分析
2. flume是什么
-
一个flume程序运行起来就是一个anget
- source 采集数据
- channel 缓存数据
- sink 下沉数据的, 将数据发送到hdfs上面
- events:我们一条条的数据,一条数据就是一个event
-
数据采集框架, 也就是采集数据的第一步
-
可以采集网络端口, 采集文件夹, 采集文件等
3. flume面试问题
-
flume有没有做监控
第一个:数据源,数据一直在增多,但是没有改变后缀名。说白了就是.complete 的文件没有增多
第二个:数据的目的地,数据的目的地没有增多
依据以上两个现象:就可以判断flume有没有在干活儿。判断flume没有干活儿了???杀掉flume的进程,然后将文件夹下面的文件全部移走,然后重新启动flume即可
可以通过shell脚本来实现
需要自己通过shell脚本,或者java程序,定时的检测flume是否正常工作
-
flume多长时间滚动异常
- size 文件大小
- count events(数据的条数)
- internal 滚动的频率
-
mysql -->hdfs
-
没有对应的source, 从mysql上采集数据
-
自定义source,sink, mysql驱动包, flume-sql连接jar包
-
canal(阿里巴巴的项目), streamSet
4. 几种source channel sink
-
采集网路端口
- source: network
- channel: memory channel
- sink: logger(打印到控制台)
-
采集hdfs某一文件夹中的数据
-
source: spooldir
1、监视一个目录,只要目录中出现新文件,就会采集文件中的内容
2、采集完成的文件,会被agent自动添加一个后缀:COMPLETED
3、所监视的目录中不允许重复出现相同文件名的文件
-
channel: memory channel
-
sink: hdfs
-
-
采集具体文件
- exec
- channel: memory channel
- sink: hdfs
-
agent串连
-
exec, avro
-
memeory
-
avro, hdfs
-
需要注意的是,第一个agent中配置sink时,hostname=第一个agnetURL,
第二个agent中配置source时, bind=自己的url
-
-
failover&负载均衡
- 一个source, 两个sink
- 分配比例& 随机分配
-
案例一, 多node采集, 采集后各自文件数据不可以混乱
- source配置静态拦截器,采集的时候拦截下来, 分配标签
- 多个sources, 一个sinks
- sink收集的时候, 根据标签分类
-
自定义拦截器, 敏感信息
- source配置自定义拦截器
java代码
- source配置自定义拦截器
5. azkanban运行
-
赋值调度采集6步骤(任务), 凌晨2-3点执行任务
-
单机启动
cd /export/servers/azkaban-solo-server-0.1.0-SNAPSHOT
bin/start-solo.sh
-
两台启动
6. sqoop数据迁移
- 底层跑maptask任务, 不跑reducetask任务
6.1 sqoop简介
-
sqoop是一款数据导入导出的工具,从关系型数据库到大数据平台,从大数据平台到关系型数据库
-
sqoop的版本分为两大类:
sqoop1:主要就是通过命令行来进行操作,比较方便
sqoop2:添加了一个服务端的模式,需要启动一个服务端。我们可以通过代码操作,可以通过脚本操作,可以远程连接操作数据的导入导出等
一般我们都是使用sqoop1这种版本,我们只需要写命令就可以将数据导入导出即可。以后就可以把命令,保存到脚本里面去,定时的执行脚本即可
6.2 数据查看
- 都是启动了一个job任务,这个job任务只有maptask,没有reduceTask
- 使用sqoop列举出数据库当中所有的数据库
bin/sqoop list-databases --connect jdbc:mysql://192.168.16.30:3306 --username root --password admin
- 列举出win7某个数据库下面的所有的数据库表
bin/sqoop list-tables --connect jdbc:mysql://192.168.16.30:3306/userdb --username root --password admin
6.3 mysql --> hdfs
- 将关系型数据库里面的数据导入到hdfs上面去
bin/sqoop import --connect jdbc:mysql://192.168.16.30:3306/userdb --username root --password admin --table emp -m 1
- 将mysql数据导入到hdfs里面去,并且指定导入的路径
bin/sqoop import --connect jdbc:mysql://192.168.16.30:3306/userdb --username root --password admin --table emp -m 1 --delete-target-dir --target-dir /sqoop/emp
- 将mysql数据导入到hdfs里面去,并且指定导入的路径,并且指定字段之间的分隔符(一定要掌握)
bin/sqoop import --connect jdbc:mysql://192.168.16.30:3306/userdb --username root --password admin --table emp -m 1 --delete-target-dir --target-dir /sqoop/emp2 --fields-terminated-by '\t'
6.4 导入mysql数据---->hive里面去(底层也是先导入到hdfs上)
-
记得一定要拷贝hive-exec.jar到sqoop的lib目录下去
不然的话,数据也不能够导入到hdfs里面去
-
将mysql数据导入到hive的表里面去(需要提前建立hive的表)
bin/sqoop import --connect jdbc:mysql://192.168.16.30:3306/userdb --username root --password admin --table emp --fields-terminated-by '\001' --hive-import --hive-table sqooptohive.emp_hive --hive-overwrite --delete-target-dir --m 1
- 导入数据到hive数据库并且自动建立hive的表
bin/sqoop import --connect jdbc:mysql://192.168.16.30:3306/userdb --username root --password admin --table emp_conn --hive-import -m 1 --hive-database sqooptohive
- 导入数据子集:我们可以通过自定义sql语句,决定我们需要导入哪些数据
bin/sqoop import --connect jdbc:mysql://192.168.16.30:3306/userdb --username root --password admin --delete-target-dir -m 1 --query 'select phno from emp_conn where 1=1 and $CONDITIONS' --target-dir /sqoop/emp_conn
6.5 增量导入
-
实际工作的当中,一般都是每天导出一次数据库里面的数据出来,一般都是凌晨导入前一天的数据,可以通过sqoop的增量的导入,将我们的数据,每天导入一次到hdfs里面去,这种方式就叫做增量的导入
只需要导入前一天的数据,以前的数据都导入过,就不用再导入了
-
如果我们指定 --check-column id 指定 --last-value 1205 就会把id值大于1205的数据全部导入过来
- 伪增量导入
bin/sqoop import --connect jdbc:mysql://192.168.16.30:3306/userdb --username root --password admin --table emp --incremental append --check-column id --last-value 1205 -m1 --target-dir /sqoop/incremen- 通过–where来实现我们数据的增量的导入
bin/sqoop import --connect jdbc:mysql://192.168.16.30:3306/userdb --username root --password admin --table emp --incremental append --where "create_time > '2018-06-17 00:00:00' and create_time < '2018-06-17 23:59:59'" --target-dir /sqoop/incement2 --check-column id -m 1
-
面试题:如何解决减量的数据?????
-
数据库里面被别人删除了一条数据
2018-12-30 应该去导入2018-12-29号的数据 但是别人还把2018-12-25 号的一条数据给删掉了???
一个人去银行办理业务,之前的手机号是13788888888 改成了13766666666
数据的标记,没有什么删除不删除数据只说,所有的删除都是逻辑删除,其实就是更新数据
如果真的要做数据,所有的删除操作都是逻辑删除
-
任何删除的操作都是有一定意义的
-
我们获取数据的时候
–where " update_time > ‘2018-12-27 00:00:00 and update_time < 2018-12-27 23:59:59’"
-
如何解决减量的数据???
没有减量的数据,所有的减量的数据,都是更新操作,一旦更细,更新时间就会变,到时候我们就按照更新时间来进行获取数据即可
hello 2018-12-25 12:25
hello 2018-12-27 12:25
-
6.6 hive/hdfs–>mysql
bin/sqoop export \
--connect jdbc:mysql://192.168.16.30:3306/userdb \
--username root --password admin \
--table emp_out \
--export-dir /sqoop/emp \
--input-fields-terminated-by ","
-
如果数据导出的时候,出现中断怎么办??
一般可以这么做,将我们的数据导出到一张临时表里面去,如果临时表导入成功,我们再去导入数据到真正的目标表里面去,可以提高我们导入成功的概率
day08-day09 离线项目
0. 点击流分析
0.1 表模型

-
page作为点, 根据sessionId就可以将用户在该网站的访问情况绘制成一条线, 就可以分析用户的访问轨迹
-
表模型
-
原始数据 通过flume采集得到的input数据
-
原始访问日志表
- mr数据清洗原始数据. 过滤脏数据,得到weblog_origin
- 通过load方式, 加载到hive的ods层, 源数据
-
pageview表(重视每一次的访问, 一个用户访问一次就记录一次, 并且标记session和每个session中访问了多少个页面)
-
mr处理, input是weblog_origin, k2为ip—> 得到ouput就是pageView
-
load的方式, 加载到hive的ods层
-
-
visit表模型(重视每一次会话的情况, 标记每一个session起始时间)
- mr处理, input是pageView, k2为session–> output就是visit
- load的方式, 加载到hive的ods层
-
0.2 分析手段
-
高收益一定伴随高风险:一般的开公司的回报率大概在 10% - 20%
-
网站分析常见的一些手段:
- 流量的质量分析: 竞价排名 —>魏则西事件 莆田医院
- 网站流量多维度分析:从各个方面可以分析我们的网站的访问情况
- 网站内容及导航分析:分析我们网站的浏览情况,以及我们流量的导流情况—>网络刷手,改评论
- 漏斗转化模型的分析:每一步相对一第一访问人员比例, 每一步相对于上一步访问比例
-
流量分析常见的指标:
-
骨灰级的指标:
IP:网站每日访问不重复的ip的个数。不重复的ip的个数越多,说明我这个网站访问的独立的人越多
Page View:PV值,访问一个页面算作一次PV
Unique Page View: UV值 一天之内访问网站不重复的用户数。不重复的用户越多,说明我这个网址访问的人数越多。使用cookie来进行区分不同的用户
基础级指标:
访问次数:session级别的次数 网站停留时间:可以统计每个人再网站停留多长时间 页面停留时间:页面停留时间,每个页面停留多长时间 -
复合级指标:
人均浏览页数:平均一个人看了几个页面 总的页面浏览次数/去重的人数
跳出率:只访问了一个页面就跑了的人数/总的访问的人数
退出率:只访问了一次(session会话级别)就跑了的人数/总的访问人数
-
基础分析指标:
趋势分析:网站流量的走势
对比分析:同比与环比
当前在线:当前网站有多少个人在线进行访问
访问明细:访问用户的一些详情信息
来源分析:主要就是分析我们网站访问的各种流量都是从哪里来的
受访分析:网站受到访问的一些分析情况
访客分析:分析来我们网站访问的用户,都是哪一类人
* 大数据杀熟 * 滴滴打车 * 转化路径分析
-
-
通过ip地址可以确定我们一个人的大致范围
友盟大数据统计
https://solution.umeng.com/?spm=a211g2.182260.0.0.650d9761zdqr58
-
数据导入导出的工具:canal streamset flume 采集mysql数据 得要下去了解
实际采集mysql数据库的数据
0.3 离线处理框架
-
离线阶段框架梳理:
zookeeper + hadoop + hive + flume + azkaban+ sqoop + impala + oozie + hue
基础框架 zookeeper + hadoop
数据采集: flume
-
离线处理第一套框架:azkaban + hive + sqoop 已经比较陈旧了
-
离线处理第二套框架: oozie + impala + hue + sqoop 来处理我们离线的任务。我们可以通过托拉拽的方式,实现我们离线任务的执行以及离线任务定时执行
基于已有的伪分布式环境,如何转换成HA的环境,并且保证hdfs上面的数据不丢失
为了解决我们所有的大数据软件的安装的烦恼,我们可以使用CM图形化的界面的工具来安装管理我们的集群
以后安装大数据软件,直接在页面上点一点就行了
1.flume集数据
-
source Taildir监控某个目录, TailSource可以同时监控tail多个目录中的文件
a1.sources = r1 a1.sources.r1.type = TAILDIR a1.sources.r1.channels = c1 a1.sources.r1.positionFile = /var/log/flume/taildir_position.json a1.sources.r1.filegroups = f1 f2 a1.sources.r1.filegroups.f1 = /var/log/test1/example.log a1.sources.r1.filegroups.f2 = /var/log/test2/.*log.*
2. 数据清洗, mr过滤不合规的数据(转为结构化数据)
- 视频数据属于非结构化数据
2.1 作用
- 得到结构化的数据
- 方便load到hive的ods层
- 处理最原始的数据,也就是flume采集过来的数据, 得到weblog_origin
- 处理weblog_origin, 到的pageView数据, k2 就是weblog_origin的ip
- 处理pageView数据, 得到visit数据, k2就是pageView中标记的session
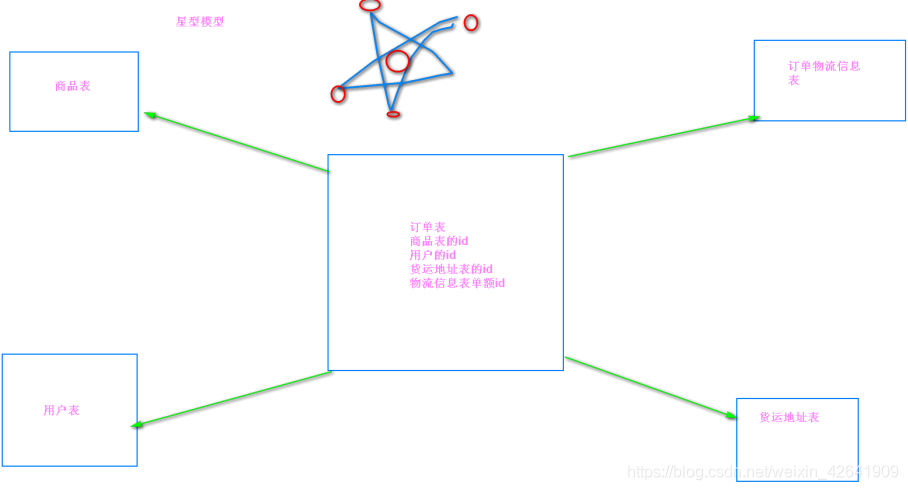
3. 数据仓库设计
3.1 概述: 数据仓库建模
-
维度表: 主键(不同的维度标识),比方说是时间, 地域,部门,产品
-
事实表:有外键约束(维度表的主键), 一件完整的事情.
- 事实表是主表,维度表是从表, 事实表中有的数据,维度表中可以没有,但是事实表没有的数据,维度表一定不可以有.
- 事实表和维度表的关系 是一对多.

-
数仓建模的方式
-
星型模型
- 雪花模型
-
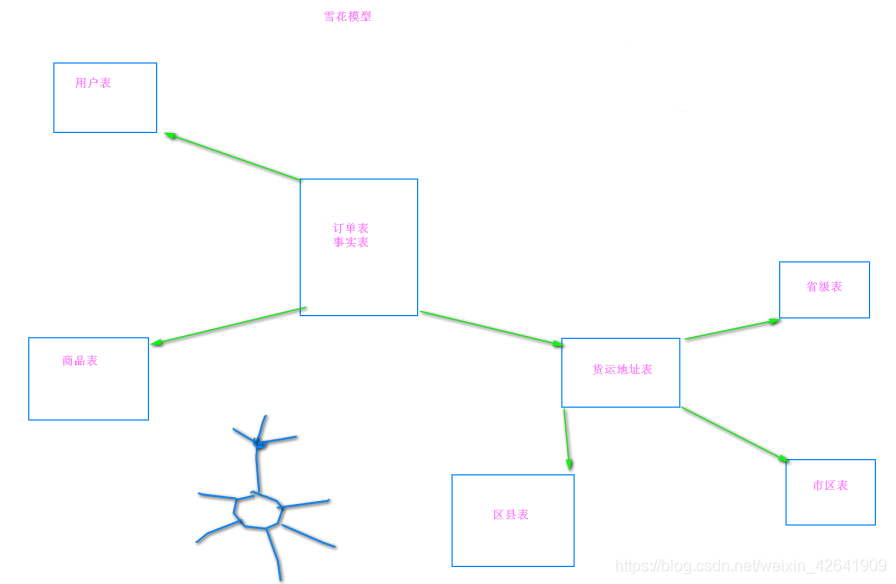
* 星座模型
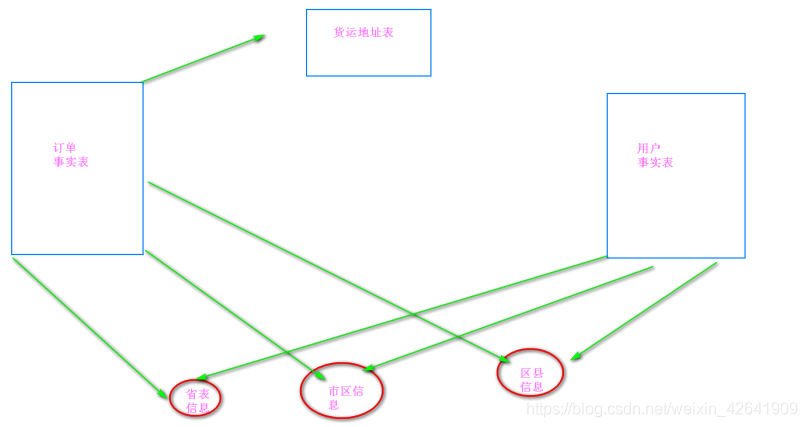
3.2 本项目采用的建模方式
- 星型模型
- 事实表
- 原始数据表: ods_weblog_origin =>对应mr清洗完之后的数据
- 访问日志明细宽表:ods_weblog_detail=>对应ods事实表的精细化拆分
-
将time_local 拆分成 时,日,月
-
将http_referer 拆分成 host,来源的路径, 来源参数,来源参数值,agent
UDTF,parse_url_tuple一行进多行出的高阶行数
-
- 维度表
- 时间维度
- 访客地域维度
- 终端类型维度
- 网站栏目维度
4. ETL(ods层数据导入)
Extrol, Transform, load 抽取,转换,加载: 就是从各个数据源提取数据, 对数据进行转换, 并最终加载填充数据到数据仓库维度建模后的表中.
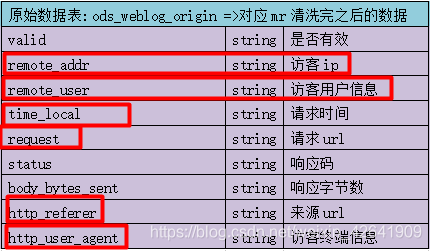
4.1 ods层表结构
- ods_weblog_origin

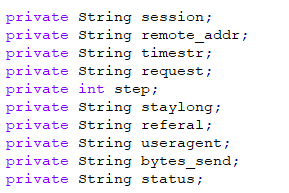
- ods_click_pageviews(重视每一次访问的情况)

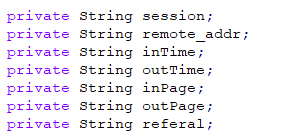
- ods_click_stream_visit(重视每一次session的会话情况,每次seession什么时候来的,什么时候走的)

-
ods_weblog_detail(对weblog_origin的细化)
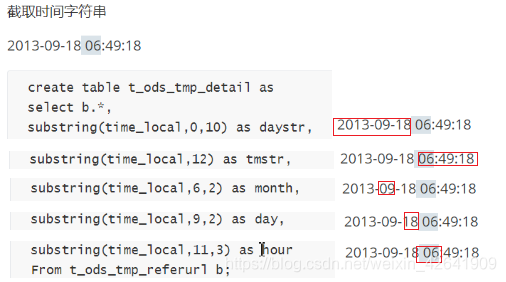
insert into table ods_weblog_detail partition(datestr='20130918') select c.valid, c.remote_addr, c.remote_user, c.time_local, substring(c.time_local,0,10) as daystr, substring(c.time_local,12) as tmstr, substring(c.time_local,6,2) as month, substring(c.time_local,9,2) as day, substring(c.time_local,11,3) as hour, c.request, c.status, c.body_bytes_sent, c.http_referer, c.ref_host, c.ref_path, c.ref_query, c.ref_query_id, c.http_user_agent from (SELECT a.valid, a.remote_addr, a.remote_user, a.time_local, a.request, a.status, a.body_bytes_sent, a.http_referer, a.http_user_agent, b.ref_host, b.ref_path, b.ref_query, b.ref_query_id FROM ods_weblog_origin a LATERAL VIEW parse_url_tuple(regexp_replace(http_referer, "\"", ""), 'HOST','PATH','QUERY', 'QUERY:id') b as ref_host, ref_path, ref_query, ref_query_id) c;
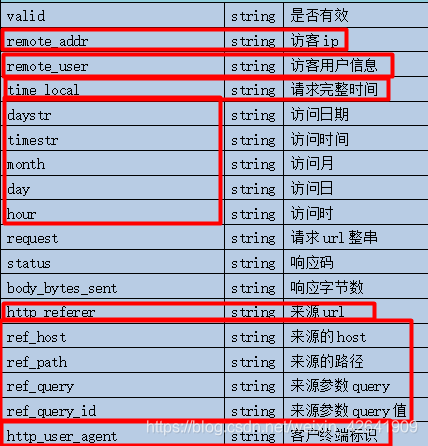
4.2 ods构建明细宽表hive函数
4.2.1 url解析函数 lateral view parse_url_tuple()
- lateral view parse_usr_tuple(fullurl,‘HOST’,‘PATH’,‘QUERY’,‘QUERY:id’) b as host,path,query,query_id. UDTF一行进多行出的函数, 解析url
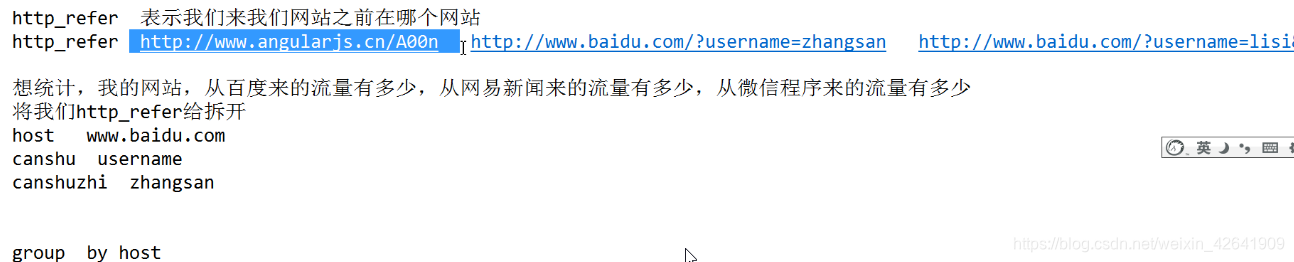
-
案例
select b.* from src lateral view parse_usr_tuple(fullurl,'HOST','PATH','QUERY','QUERY:id') b as host,path,query,query_id.-
b就是多行出的一个临时表, 每一行的字段asxxx, 然后再b.*查出来
-
解析后的结果如下
http://www.baidu.com/hello/world?username=zhangsan
- HOST:www.baidu.com
- PATH:/hello/world
- QUERY:username
- QUERY?zhangsan
-
4.2.2 替换函数 regexp_replace()
-
regexp_replace(xxx, “被替换的字符”,“要替换为的字符”)
UDF 一行进,一行出. 用来替换字符串中的某个字符
-
案例 desc function extended regexp_replace 可以查看案例
lateral view parse_url_tuple(regexp_replace(http_referer,"\"", ""))- 第一个参数是被替换的, 引号
- 第二个参数是要替换为的字符,是一个空值
4.2.3 截取函数 substring()
-
substring(从第几个开始截取,截几个)截取函数–>注意和java中的函数区分, java中的(内部指的是索引)
- (截取字符串的某一部分,作为一个新字段) 是UDF一行进一行出的函数
- substring(xxx,n) 从头开始截取,截取n个字符
- substring(xxx,m,n) 从第m个字符开始截取,截取n个字符
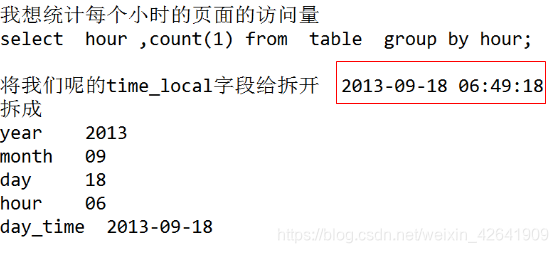
- 案例 把ods_weblog_detail中的time_local拆分成5个字段 访问日期,访问时间,访问月,访问日,访问时
5. 模块开发–统计分析
5.1 流量分析
5.1.1 时间/referer/host维度
-
时间维度: 计算每小时/每天的pvs, 访问一次就计算一次pv
drop table if exists dw_pvs_everyhour_oneday; create table if not exists dw_pvs_everyhour_oneday(month string,day string,hour string,pvs bigint) partitioned by(datestr string); insert into table dw_pvs_everyhour_oneday partition(datestr='20130918') select a.month as month,a.day as day,a.hour as hour,count(*) as pvs from ods_weblog_detail a where a.datestr='20130918' group by a.month,a.day,a.hour; create table if not exists dw_pvs_everyday(pvs bigint,month string,day string); insert into table dw_pvs_everyday select count(*) as pvs,a.month as month,a.day as day from ods_weblog_detail a group by a.month,a.day; -
按照referer维度: 统计每小时各来访url产生的pv量,查询结果存入
drop table if exists dw_pvs_referer_everyhour; create table if not exists dw_pvs_referer_everyhour (referer_url string,referer_host string,month string,day string, hour string,pv_referer_cnt bigint) partitioned by(datestr string); insert into table dw_pvs_referer_everyhour partition(datestr='20130918') select http_referer, ref_host, month, day, hour, count(1) as pv_referer_cnt from ods_weblog_detail group by http_referer,ref_host,month,day,hour having ref_host is not null order by hour asc,day asc,month asc,pv_referer_cnt desc; -
按referer维度: 统计每小时各来访host的产生的pv数并排序
drop table dw_pvs_refererhost_everyhour; create table dw_pvs_refererhost_everyhour(ref_host string,month string,day string,hour string,ref_host_cnts bigint) partitioned by(datestr string); insert into table dw_pvs_refererhost_everyhour partition(datestr='20130918') select ref_host, month, day, hour, count(1) as ref_host_cnts from ods_weblog_detail group by ref_host,month,day,hour having ref_host is not null order by hour asc,day asc,month asc,ref_host_cnts desc;
5.1.2 字符串拼接函数concat()
- contact(xx,yy,zz) as cts UDAF 多行进一行出, 字符串拼接
- 案例 concat(month,day, hour)
5.1.3 dw层hive函数: 分组求topN
-
案例:
id name sal 1 a 10 2 a 12 3 b 13 4 b 12 5 a 14 6 a 15 7 a 13 8 b 11 9 a 16 10 b 17 11 a 14 -- 需求, 按照各部门对薪水进行排序并求TopN -- 1.1 按照name分区,sal排序,并且每个分区中都为排好序的数据打上标号 select id, name, sal, rank() over(partition by name order by sal desc ) rp, dense_rank() over(partition by name order by sal desc ) drp, row_number()over(partition by name order by sal desc) rmp from f_test -- 1.2 打好标号的结果 id name rp drp rmp a 16 1 1 1 a 15 2 2 2 a 14 3 3 3 a 14 3 3 4 a 13 5 4 5 a 12 6 5 6 a 10 7 6 7 b 17 1 1 1 b 13 2 2 2 b 12 3 3 3 b 11 4 4 4 -- 1.3 三种开窗函数的区别 rank() over(partition by name order by sql desc) as rp 1,1,3顺序排 dense_rank over(partition by name order by sal desc) as drp 1,1,2 并列排序,总序号会减少 row_number() over(partition by name order by sql desc) as rmp 1,2,3 并列排序,总序号不变 -- 2. 按照name分组,求每个组中前3名 select * from (select id, name, sal, rank() over(partition by name order by sal desc ) rp, dense_rank() over(partition by name order by sal desc ) drp, row_number() over(partition by name order by sal desc) rmp from f_test) temp where temp.rmp <= 3; -
需求描述:按照时间维度,统计一天内各小时产生最多pvs的来访的topN
(查询dw_pvs_refererhost_everyhour表)
select ref_host, ref_host_cnts, concat(month,day,hour), row_number() over (partition by concat(month,day,hour) order by ref_host_cnts desc) as od from dw_pvs_refererhost_everyhour; --综上可以得出 drop table dw_pvs_refhost_topn_everyhour; create table dw_pvs_refhost_topn_everyhour( hour string, toporder string, ref_host string, ref_host_cnts string )partitioned by(datestr string); -- 每一个子查询语句,都是可以独立运行的 insert into table dw_pvs_refhost_topn_everyhour partition(datestr='20130918') select t.hour, t.od, t.ref_host, t.ref_host_cnts from (select ref_host, ref_host_cnts, concat(month,day,hour) as hour, row_number() over (partition by concat(month,day,hour) order by ref_host_cnts desc) as od from dw_pvs_refererhost_everyhour) t where od<=3;
5.1.4 人均浏览页数
-
需求描述:统计今日所有来访者平均请求的页面数。
总页面请求数/去重总人数
drop table dw_avgpv_user_everyday; create table dw_avgpv_user_everyday( day string, avgpv string); -- 添加数据 insert into table dw_avgpv_user_everyday select '20130918', sum(b.pvs) / count(b.remote_addr) from (select remote_addr, count(1) as pvs from osd_weblog_detail where datestr='20130918' group by remote_addr) b;
5.2 受访分析
页面受到的访问, ods_weblog_detail中的request字段(要访问的页面,这个页面就是受到访问的页面)
5.2.1 各页面访问统计
select
request as request,
count(1) as cts
from
ods_weblog_detail
group by request
having request is not null
order by cts
limit 20;
5.2.2 热门页面统计
-
统计20130918这个分区里面的受访页面的top10
drop table dw_hotpages_everyday; create table dw_hotpages_everyday(day string,url string,pvs string); -- ETL从ods层查询数据抽取到dw层 insert into table dw_hotpages_ervery select '20130918', request, count(1) as cts from ods_weblog_detail where request is not null group by request order by cts desc limit 10; -
统计每日最热门页面的top10(分组求topN)
select temp.* from (select concat(month,day) as day, request, count(1) as cts, row_number() over(partition by day order by cts desc) as rmp from ods_weblog_detail where request is not null) temp where temp.rmp >= 10;
5.3 访客分析
5.3.1 独立访客
-
需求: 每小时独立访客及其产生的pv(也就是一个用户访问了多少个页面)
安装小时,remote_addr进行分组,然后再count(1)
drop table dw_user_dstc_ip_h; create table dw_user_dstc_ip_h( remote_addr string, pvs bigint, hour string); -- 插入数据 select remote_addr, count(1) as pvs, concat(month,day,hour) as hour from ods_weblog_detail where datestr = '20130918' group by hour,remote_addr;
5.3.2 每日新访客
-
历史表
-
每日访客表 就是ods_weblog_detail
-
nrewIp left join hist on newIp.remote_addr = hist.ip where hist.ip is null ==>就是每日新访客表
-
得到的新访客需要追加到历史表中
--历史去重访客累积表 drop table dw_user_dsct_history; create table dw_user_dsct_history( day string, ip string) partitioned by(datestr string); --每日新访客表 drop table dw_user_new_d; create table dw_user_new_d ( day string, ip string) partitioned by(datestr string); --每日新用户插入新访客表 insert into table dw_user_new_d partition(datestr='20130918') select tmp.day as day, tmp.remote_addr as new_ip from (select a.day, a.remote_addr, from (select remote_addr, '20130918' as day from ods_weblog_detail newIp where datestr ='20130918' group by remote_addr ) a left join dw_user_dsct_history hist on a.remote_addr = hist.ip where hist.ip is null) temp; --每日新用户追加到历史累计表 insert into table dw_user_dsct_history partition(datestr='20130918') select day,ip from dw_user_new_d where datestr='20130918';
5.4 访客Visit分析(点击流模型)
-
回头访客及其访问的次数
drop table dw_user_returning; create table dw_user_returning( day string, remote_addr string, acc_cnt string) partitioned by (datestr string); -- 插入数据 insert overwrite table dw_user_returning partition(datestr='20130918') select '20130918' as day, remote_addr, count(1) as acc_cnt from ods_click_stream_visit group by remote_addr having acc_cnt > 1; -
人均访问的频次,频次表示我们来了多少个session
次数都是使用session来进行区分,一个session就是表示一次select sum(groupuser) / count(1) from (select count(1) as groupuser from ods_click_stream_visit where datestr = '20130918' group by remote_addr); -
人均页面浏览量 总的pagevisits / 总的去重人数
select sum(pagevisits)/count(distinct remote_addr) from ods_click_stream_visit where datestr='20130918';
5.5 关键路径转化率分析(漏斗模型)
5.5.1 hive当做级联求和(inner join自关联)
-- t_salary_detail
username month salary
A,2015-01,5
A,2015-01,15
B,2015-01,5
A,2015-01,8
B,2015-01,25
A,2015-01,5
A,2015-02,4
A,2015-02,6
B,2015-02,10
B,2015-02,5
A,2015-03,7
A,2015-03,9
B,2015-03,11
B,2015-03,6
-- 需求1. 求每个用户每个月总共获得多少消费
select
t.month,
t.username,
sum(salary) as salSum
from t_salary_detail
group by t.username,t.month;
+----------+-------------+---------+--+
| t.month | t.username | salsum |
+----------+-------------+---------+--+
| 2015-01 | A | 33 |
| 2015-02 | A | 10 |
| 2015-03 | A | 16 |
| 2015-01 | B | 30 |
| 2015-02 | B | 15 |
| 2015-03 | B | 17 |
+----------+-------------+---------+--+
-- 需求2. 求每个用户每个月累计小费
-- 第一步: 求每个用户每个月的消费总和
select
t.month,
t.username,
sum(salary) as salSum
from t_salary_detail
group by t.username,t.month;
-- 第二步: 使用inner join 实现自己连接自己(inner join并不以谁为基准, 而是两张表的交集)
select
a.*,
b.*
from
(select
t.month,
t.username,
sum(salSum) as salSum
from
t_salary_detail t
group by t.username,t.month) a
inner join
(select
t.month,
t.username,
sum(salSum) as salSum
from
t_salary_detail t
group by t.username,t.month) b
on a.username = b.username;
+----------+-------------+-----------+----------+-------------+-----------+--+
| a.month | a.username | a.salsum | b.month | b.username | b.salsum |
+----------+-------------+-----------+----------+-------------+-----------+--+
取这一个作为一组
| 2015-01 | A | 33 | 2015-01 | A | 33 |
| 2015-01 | A | 33 | 2015-02 | A | 10 |
| 2015-01 | A | 33 | 2015-03 | A | 16 |
取这两个作为一组
| 2015-02 | A | 10 | 2015-01 | A | 33 |
| 2015-02 | A | 10 | 2015-02 | A | 10 |
| 2015-02 | A | 10 | 2015-03 | A | 16 |
取这三个作为一组
| 2015-03 | A | 16 | 2015-01 | A | 33 |
| 2015-03 | A | 16 | 2015-02 | A | 10 |
| 2015-03 | A | 16 | 2015-03 | A | 16 |
| 2015-01 | B | 30 | 2015-01 | B | 30 |
| 2015-01 | B | 30 | 2015-02 | B | 15 |
| 2015-01 | B | 30 | 2015-03 | B | 17 |
| 2015-02 | B | 15 | 2015-01 | B | 30 |
| 2015-02 | B | 15 | 2015-02 | B | 15 |
| 2015-02 | B | 15 | 2015-03 | B | 17 |
| 2015-03 | B | 17 | 2015-01 | B | 30 |
| 2015-03 | B | 17 | 2015-02 | B | 15 |
| 2015-03 | B | 17 | 2015-03 | B | 17 |
+----------+-------------+-----------+----------+-------------+-----------+--+
-- 加参数继续变形 条件就是b.month <= a.month
select
a.*,
b.*
from
(select
t.month,
t.username,
sum(salSum) as salSum
from
t_salary_detail t
group by t.username,t.month) a
inner join
(select
t.month,
t.username,
sum(salSum) as salSum
from
t_salary_detail t
group by t.username,t.month) b
on a.username = b.username
where b.month <= a.month;
+----------+-------------+-----------+----------+-------------+-----------+--+
| a.month | a.username | a.salsum | b.month | b.username | b.salsum |
+----------+-------------+-----------+----------+-------------+-----------+--+
| 2015-01 | A | 33 | 2015-01 | A | 33 | 33
| 2015-02 | A | 10 | 2015-01 | A | 33 | 43
| 2015-02 | A | 10 | 2015-02 | A | 10 |
| 2015-03 | A | 16 | 2015-01 | A | 33 | 59
| 2015-03 | A | 16 | 2015-02 | A | 10 |
| 2015-03 | A | 16 | 2015-03 | A | 16 |
| 2015-01 | B | 30 | 2015-01 | B | 30 | 30
| 2015-02 | B | 15 | 2015-01 | B | 30 | 45
| 2015-02 | B | 15 | 2015-02 | B | 15 |
| 2015-03 | B | 17 | 2015-01 | B | 30 | 62
| 2015-03 | B | 17 | 2015-02 | B | 15 |
| 2015-03 | B | 17 | 2015-03 | B | 17 |
+----------+-------------+-----------+----------+-------------+-----------+--+
-- 第三步: 从第二步的结果中继续对a.month,a.username进行分组,并对分组后的b.salSum进行sum
select
temp.username,
temp.month,
max(asalSum),
sum(bsalSum)
from
(select
a.username as ausername,
a.month as amonth,
a.salSum as asalSum,
b.salSum as bsalSum
from
(select
t.month,
t.username,
sum(salSum) as salSum
from
t_salary_detail t
group by t.username,t.month) a
inner join
(select
t.month,
t.username,
sum(salSum) as salSum
from
t_salary_detail t) b
on a.username = b.username
where b.month <= a.month;
) temp
order by temp.username,a.month;
5.5.2 漏斗模型
第一个指标: 每一步现对于第一步的转化率
第二个指标: 每一步相对于上一步的转化率
5.5.2.1 查询每一步骤的总访问人数
create table dw_oute_numbs as
select
'step1' as step,
count(distinct remote_addr) as numbs
from
ods_click_pageviews
where datestr = '20130918'
and request like '/item%'
union all
select
'step2' as step,
count(distinct remote_addr) as numbs
from
ods_click_pageviews
where datestr = '20130918'
and request like '/category%'
select
'step3' as step,
count(distinct remote_addr) as numbs
from
ods_click_pageviews
where datestr = '20130918'
and request like '/order%'
select
'step4' as step,
count(distinct remote_addr) as numbs
from
ods_click_pageviews
where datestr = '20130918'
and request like '/index%'
+---------------------+----------------------+--+
| dw_oute_numbs.step | dw_oute_numbs.numbs |
+---------------------+----------------------+--+
| step1 | 1029 |
| step2 | 1029 |
| step3 | 1028 |
| step4 | 1018 |
+---------------------+----------------------+--+
5.5.2.2 查询每一步骤相对于路径起点人数的比例(级联查询,自己跟自己join)
-- 1. 先自关联得到总表, 这时候自关联就没有on条件了,
select
a.step as astep,
a.numbs as anumbs,
b.step as bstep,
b.numbs as bnumbs
from
dw_oute_numbs a
inner join
dw_oute_numbs b;
+---------+----------+---------+----------+--+
| a.step | a.numbs | b.step | b.numbs |
+---------+----------+---------+----------+--+
| step1 | 1029 | step1 | 1029 |
| step2 | 1029 | step1 | 1029 |
| step3 | 1028 | step1 | 1029 |
| step4 | 1018 | step1 | 1029 |
| step1 | 1029 | step2 | 1029 |
| step2 | 1029 | step2 | 1029 |
| step3 | 1028 | step2 | 1029 |
| step4 | 1018 | step2 | 1029 |
| step1 | 1029 | step3 | 1028 |
| step2 | 1029 | step3 | 1028 |
| step3 | 1028 | step3 | 1028 |
| step4 | 1018 | step3 | 1028 |
| step1 | 1029 | step4 | 1018 |
| step2 | 1029 | step4 | 1018 |
| step3 | 1028 | step4 | 1018 |
| step4 | 1018 | step4 | 1018 |
+---------+----------+---------+----------+--+
-- 2. 加条件 只取 a表的step1
select
a.step as astep,
a.numbs as anumbs,
b.step as bstep,
b.numbs as bnumbs
from
dw_oute_numbs a
inner join
dw_oute_numbs b
where a.step = 'step1';
+---------+----------+---------+----------+--+
| a.step | a.numbs | b.step | b.numbs |
+---------+----------+---------+----------+--+
| step1 | 1029 | step1 | 1029 |
| step1 | 1029 | step2 | 1029 |
| step1 | 1029 | step3 | 1028 |
| step1 | 1029 | step4 | 1018 |
+---------+----------+---------+----------+--+
-- 3. 求比率
select
temp.bnumbs/temp.anumbs as otherToFirstRation
from
(select
a.step as astep,
a.numbs as anumbs,
b.step as bstep,
b.numbs as bnumbs
from
dw_oute_numbs a
inner join
dw_oute_numbs b
where a.step = 'step1';
) temp;
+---------+
| otherToFirstRation |
+---------+
| 1.0 |
| 1.0 |
| 0.9990 |
| 0.9893 |
+---------+
5.5.2.3 每一步相对于上衣布的转化率 secondToFirstRation==>cast(被转换的数据, 要转换的类型)
- hive中的函数 cast(),转换函数
- UDF 将string类型转为int类型
- cast(substr(xxx,5,1) as int) 将截取后的字符串转为int类型
- casr(‘2013-09-18’, date) 转换为日期类型
- 需求: 每一步相对于上一步的转化率
-- 先过滤出条件
select
a.step as astep,
a.numbs as anumbs,
b.step as bstep,
b.numbs as bnumbs
from
dw_oute_numbs a
inner join
dw_oute_numbs b
where cast(substr(a.step, 5, 1), int) = cast(substr(b.step, 5, 1), int) - 1;
+---------+----------+---------+----------+--+
| a.step | a.numbs | b.step | b.numbs |
+---------+----------+---------+----------+--+
| step1 | 1029 | step2 | 1029 |
| step2 | 1029 | step3 | 1028 |
| step3 | 1028 | step4 | 1018 |
+---------+----------+---------+----------+--+
-- 再求比率
select
temp.bnumbs/temp.anumbs as secondToFirstRation
from
(select
a.step as astep,
a.numbs as anumbs,
b.step as bstep,
b.numbs as bnumbs
from
dw_oute_numbs a
inner join
dw_oute_numbs b
where cast(substr(a.step, 5, 1), int) = cast(substr(b.step, 5, 1), int) - 1
) temp;
+---------+
| secondToFirstRation |
+---------+
| 1.0 |
| 0.9990 |
| 0.9983 |
+---------+
6. hive到出到mysql中
-
先在mysql中创建库,创建表
-
sqoop找到hive在hdfs存储位置,默认user/root/warehouse/weblog/表文件夹
/export/servers/sqoop-xxx/bin/sqoop export \ --connect jdbc:mysql://192.168.137.188:3306/weblog \ --username root --passwrod root \ --m 1 \ --export-dir /user/root/warehouse/weblog/xxx \ --table mysql中的表名 \ --input-fields-terminated-by '\001'
7. azkaban调度
7.1 大体的轮廓
flume一直在运行, 唯一要做的就是要监控十分正常运行
- 数据的清洗 三个mr程序需要运行
- hive当中表数据的加载
- ETL开发
- 将结果数据到出
7.2 小记忆
- date -d ‘-1 day’ + %Y%m%d
8. echarts数据可视化
9. 面试总结
-
一天数据 50G-100G 2-3个人维护
-
集群数量30台左右 每台硬盘配置12T-24T 内存最少64GB CM搭建运行环境
-
首先要确定你要运行哪些框架?
zookeeper hadoop hive flume sqoop
zookeeper:奇数台,7-9台都行
hadoop HA: namenode 2 个 datanode 26个 journalenode 7-9个
zkfc 与namenode同在
resourceManager 2 个 nodeManager 26个
hive:随便找一个datanode装上就行了
sqoop:随便找一个datanode装上就行了集群的服务的规划:主节点彻底分开,不要与其他的节点混淆

















 1032
1032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









