






kettle笔记
一、关于kettle
1.kettle来源
Kettle是一款国外开源(免费:受欢迎)的ETL工具,纯Java编写(Java开发很好的集成),可以在windows、Linux、Unix 上运行(Linux服务器流行时代下,Kettle 更加受欢迎),数据抽取高效稳定(更更加受欢迎)。
Kettle 中文名俗称“水壶”,开发目的是将各种数据放到一个水壶中,然后经过各种处理加工,以特定的格式流出。
学会使用此工具进行数据转换、同步,能够解决实际工作中遇到的迁移和业务各种实际工作内容。
2.部分术语和定义
(1)资源库
资源库是用来保存转换任务的,用户通过图形界面创建的的转换任务可以保存在资源库中。资源库可以是各种常见的数据库,用户通过用户名/密码来访问资源库中的资源,默认的用户名/密码是admin/admin,资源库并不是必须的,如果没有资源库,用户还可以把转换任务保存在xml 文件中。资源库可以使多用户共享转换任务,转换任务在资源库中是以文件夹形式分组管理的,用户可以自定义文件夹名称
(2)Transformation
转换步骤,可以理解为将一个或者多个不同的数据源组装成一条数据流水线。然后最终输出到某一个地方,文件或者数据库等
(3)Job
作业可以调度设计好的转换,也可以执行一些文件处理(比较,删除等),还可以ftp上传,下载文件,发送邮件,执行shell命令等。
(4)Hop
连接转换步骤或者连接Job(实际上就是执行顺序)的连线
(5)Transformation hop
主要表示数据的流向。从输入,过滤等转换操作,到输出
(6)Job hop
可设置执行条件:1)无条件执行2)当上一个Job执行结果为true时执行3)当上一个Job执行结果为false时执行
(7)kettle家族
1)Chef
它是一个图形用户界面,使用SWT开发,用来设计一个作业,转换,SQL,FTP,邮件,检查表存在,检查文件存在,执行SHELL脚本
2)Kitchen
作业执行引擎,用来进行转换,校验,FTP上传。可以执行xml格式定义的任务以及保存在数据库上的
3)Spoon
Spoon是Kettle的另一个图形用户界面,用来设计数据转换过程
3)Pan
Pan是一个数据转换引擎,负责从不同的数据源读写和转换数据。pan.sh -file="/PRD/Customer Dimension.ktr" -level=Minimal
(8)目标表
数据将要插入的表。
(9)用来查询的关键字段
这一部分用来设置查询的关键字段。表字段指示的是目标表的中的字段,流里的字段指示的是的转换的上一步操作传入的字段。比较符指定匹配方法。
(10)更新字段
指定字段对应规则。
(11)转换
(12)作业
多个转换融合再一起形成作业,不仅包含转换还可能包含作业
二、ETL概念
1.背景
随着企业的发展,目前的业务线越来越复杂,各个业务系统独立运营。例如:CRM系统只会生产CRM的数据;Billing只会生产Billing的数据。各业务系统之间只关心自己的数据,导致各业务系统之间数据相互独立,互不相通。一旦业务系统之间进行数据交互,只能通过传统的webservice接口之间进行数据通信。该种方式对人力成本、时间成本要求比较高。也就是说:需要成熟的开发人员才能编写响应的webservice接口进行数据通信。而ETL的诞生就解决了此类问题,企业不需要技术很好、很成熟的开发人员一样可以完成该任务。而且可以比优秀的开发人员完成的更好,致使人力成本更低。这些都是企业所迫切需要的,有此诞生了ETL。
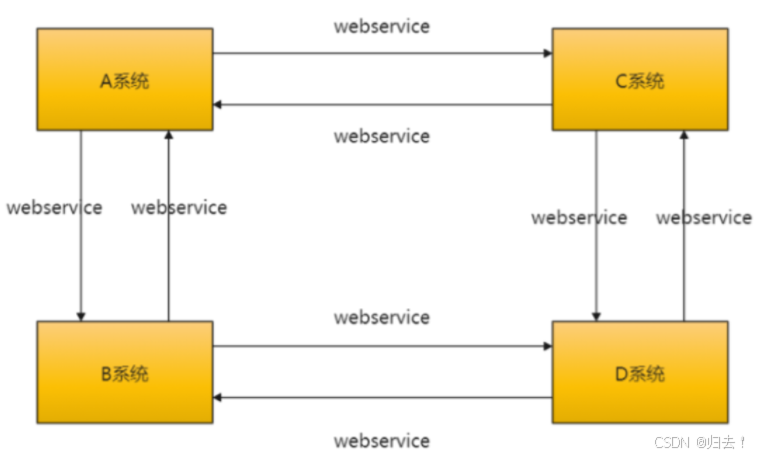
 ETL工作流程:先抽取、然后加载到目标数据库中、在目标数据库中完成转换操作。在ELT架构中,ELT只负责提供图形化的界面来设计业务规则,数据的整个加工过程都在目标和源的数据库之间流动,ELT协调相关的数据库系统来执行相关的应用,数据加工过程既可以在源数据库端执行,也可以在目标数据仓库端执行(主要取决于系统的架构设计和数据属性)。
ETL工作流程:先抽取、然后加载到目标数据库中、在目标数据库中完成转换操作。在ELT架构中,ELT只负责提供图形化的界面来设计业务规则,数据的整个加工过程都在目标和源的数据库之间流动,ELT协调相关的数据库系统来执行相关的应用,数据加工过程既可以在源数据库端执行,也可以在目标数据仓库端执行(主要取决于系统的架构设计和数据属性)。
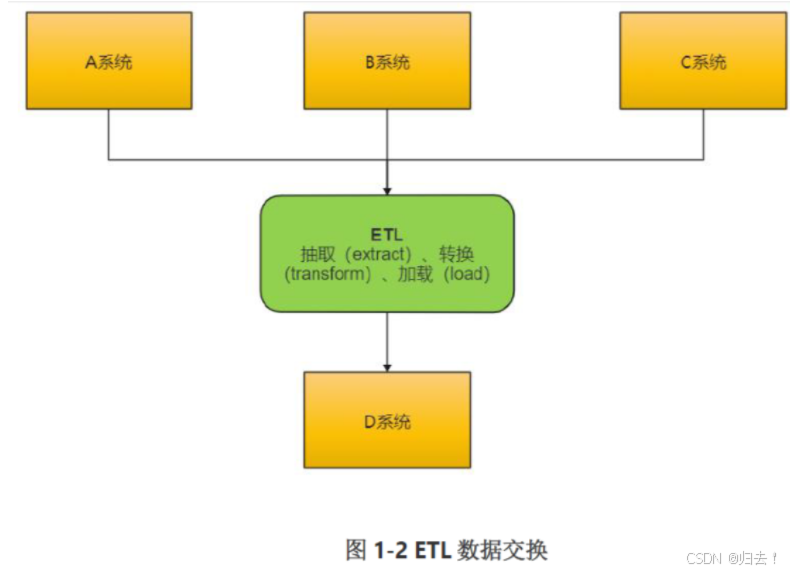
2.工作流程
ETL是将业务系统的数据经过抽取(Extract)、清洗转换(Transform)之后加载(Load)到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。
ETL工作流程:先抽取、然后加载到目标数据库中、在目标数据库中完成转换操作。在ELT架构中,ELT只负责提供图形化的界面来设计业务规则,数据的整个加工过程都在目标和源的数据库之间流动,ELT协调相关的数据库系统来执行相关的应用,数据加工过程既可以在源数据库端执行,也可以在目标数据仓库端执行(主要取决于系统的架构设计和数据属性)。
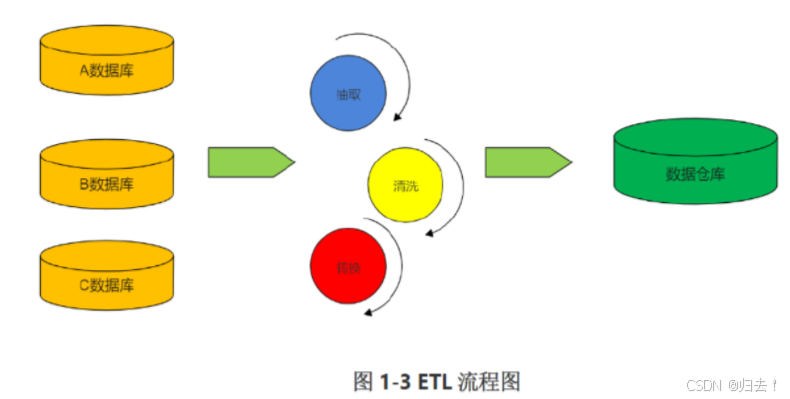
3.操作步骤
ETL处理分为五大模块,分别是:数据抽取、数据清洗、库内转换、规则检查、数据加载。各模块可灵活进行组合,形成ETL处理流程。简单介绍一下各个模块之间的主要功能。
(1)数据抽取
确定数据源,需要确定从哪些源系统进行数据抽取定义数据接口,对每个源文件及系统的每个字段进行详细说明确定数据抽取的方法:是主动抽取还是由源系统推送?是增量抽取还是全量抽取?是按照每日抽取还是按照每月抽取?
(2)数据清洗与转换
数据清洗主要将不完整数据、错误数据、重复数据进行清洗
(3)数据转换
1)空值处理:可捕获字段空值,进行加载或替换为其他含义数据,或数据分流问题库2)数据标准:统一元数据、统一标准字段、统一字段类型定义3)数据拆分:依据业务需求做数据拆分,如身份证号,拆分区划、出生日期、性别等4)数据验证:时间规则、业务规则、自定义规则5)数据替换:对于因业务因素,可实现无效数据、缺失数据的替换6)数据关联:关联其他数据或数学,保障数据完整性数据加载将数据缓冲区的数据直接加载到数据库对应表中,如果是全量方式则采用LOAD方式,如果是增量则根据业务规则MERGE进数据库
三、kettle概念
1.什么是kettle
kettle最早是一个开源的ETL工具,全称为KDE Extraction, Transportation,Transformation and Loading Environment。在2006年,Pentaho公司收购了Kettle项目,原 Kettle 项目发起人Matt Casters加入了Pentaho 团队,成为Pentaho套件数据集成架构师﹔从此,Kettle成为企业级数据集成商业智能套件Pentaho 的主要组成部分,Kettle亦重命名为Pentaho Data Integration。
Pentaho Data lntegration 以Java开发,支持跨平台运行,其特性包括:支持100%无编码、拖拽方式开发ETL数据管道;可对接包括传统数据库、文件、大数据平台、接口、流数据等数据源;支持ETL数据管道加入机器学习算法。
Pentaho Data Integration分为商业版与开源版﹐开源版的截止2021年1月的累计下载量达836万,其中19%来自中国。在中国,一般人仍习惯把Pentaho Data Integration的开源版称为Kettle。
2.主要功能
Pentaho Data Integration作为一个端对端的数据集成平台,可以对多种数据源进行抽取(Extraction)、加载(Loading)、数据落湖(Data Lake lnjection)、对数据进行各种清洗(Cleasing)、转换(Transformation)、混合(Blending) ,并支持多维联机分析处理OLAP和数据挖掘(Data mining) 。
3.kettle的整体结构图
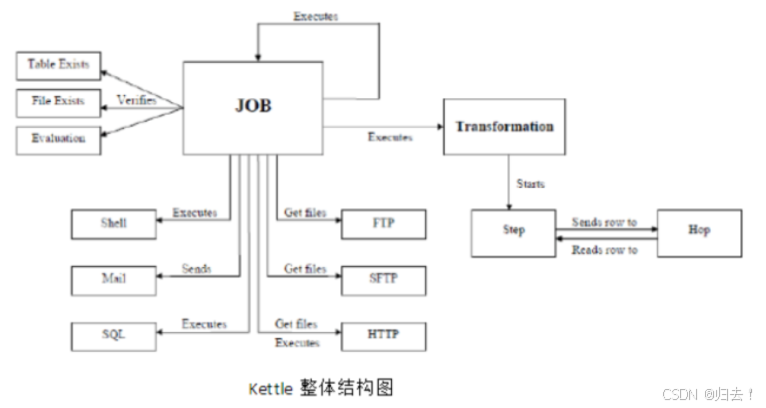
4.运行环境
Windows / linux、Jdk1.6以上
5.支持的数据库种类
DB2、Oracle、SQL Server . Sybase、Informix、MySQL,mangoDB,国产达梦等
6支持的操作系统
Windows、Linux、Solaris、Apple OSX、HP-UX、AIX
7支持的文件类型
txt、csv、xls、zip
8 安装说明
(1)Window下安装
1)下载地址: Home - Hitachi Vantara/2)解压zip 文件至指定的文件目录3)将需要同步数据的数据库的驱动包放入….[data-integration\lib 文件中
(2) Linux下安装
1)下载地址: Home - Hitachi Vantara/2)解压zip 文件至指定的文件目录下3)赋予*.sh文件的执行权限4) Linux系统需要支持图形化服务5)修改根目录下没有.kettle文件中的 ShowWelcomePageOnStartup=N6) Linux版本的下载地址:https://sourceforge.net/projects/pentaho/files/Data%20Integration/7.1/pdi-ce-7.1.0.0-12.zip/download
9.注意事项
由于此工具采用异步方式同步数据,故待同步的表必须有时间戳同步的任务正常成功与否需要记录日志
四、产品功能及使用
1.资源库
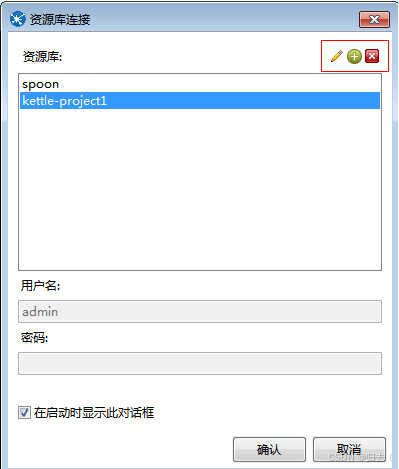
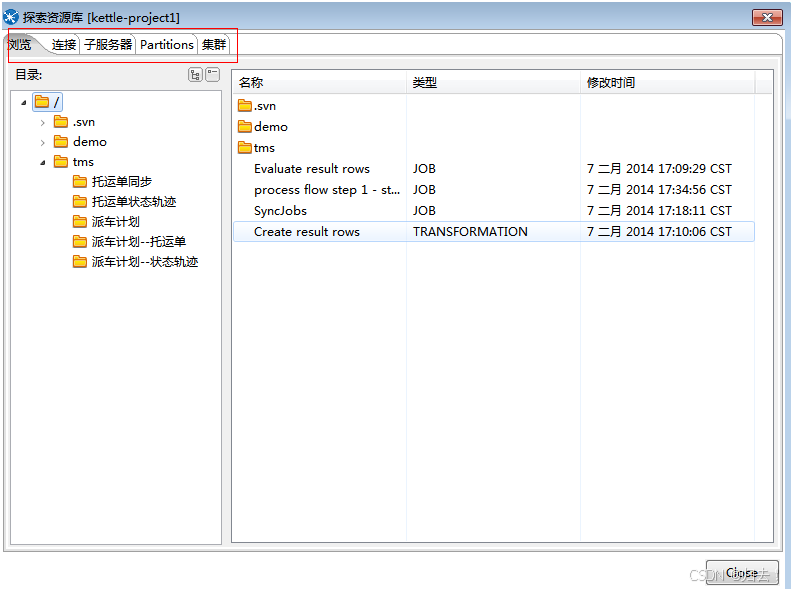
功能描述:目录管理、数据源管理、子服务器管理、集群管理
2.数据源
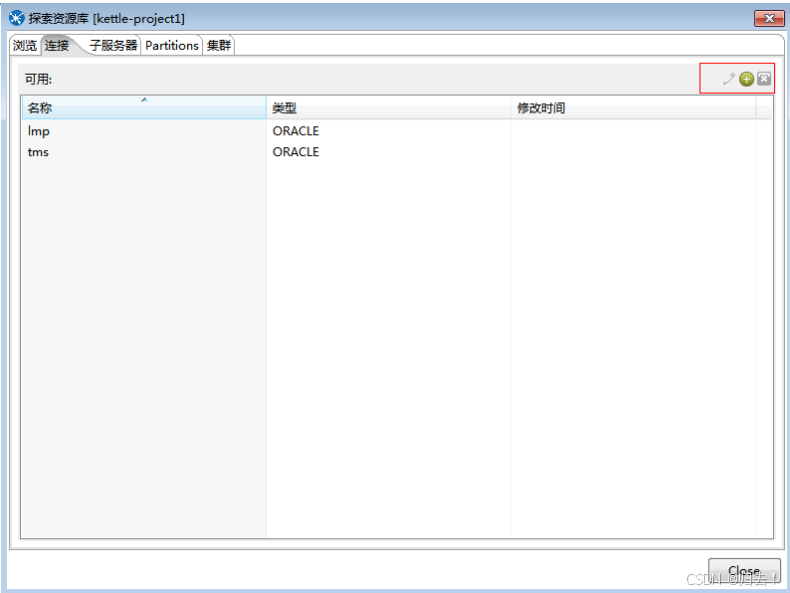
功能描述:提供数据库连接
注意事项:
1.不同的数据库在界面选择不同的类型
2. 添加该数据库的驱动包至lib目录
3.不要频繁变更数据源名称(名称所对应的数据库ip、用户、密码、端口、service_name信息可以更改)
4.调整数据库连接池初始、最大值大小
3.转换
(1)输入
1)生成记录
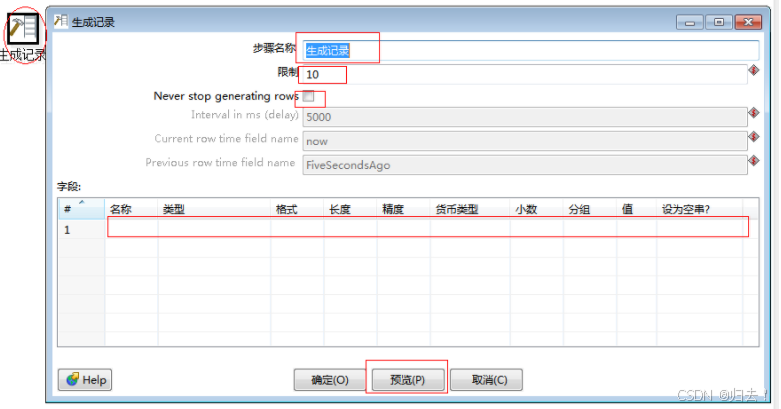
功能描述:生成一些固定字段的记录,主要用来模拟一些数据进行测试
注意事项:注意生成行数
2)自定义常量数据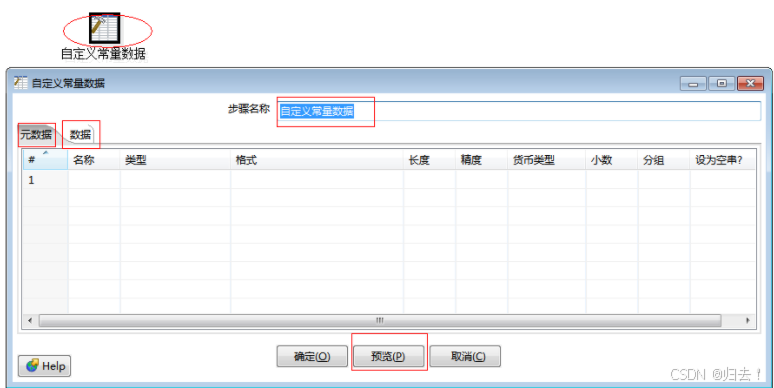
功能描述:用来给查询增加常量列 “元数据”页是定义字段相关信息 “数据”页则是赋予各字段相应的值
注意事项:注意字段相关的约束条件
3)获取表名
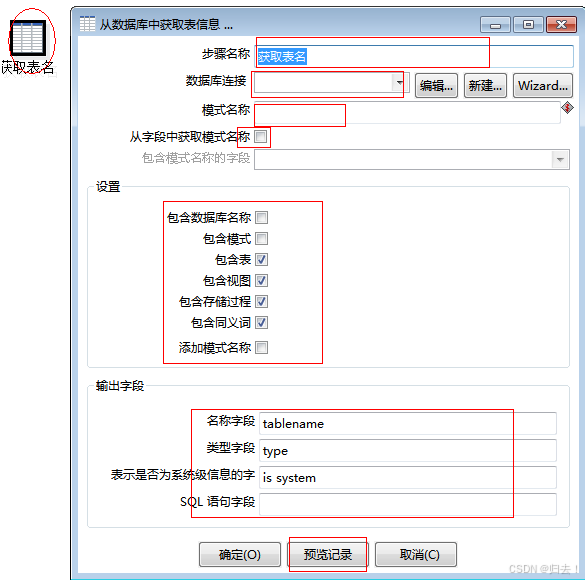
功能描述:
获取某个数据库的表信息获取视图信息获取存储过程信息获取同义词信息获取模式名获取数据库名可以在表名、视图名、过程名前添加上模式名
注意事项:”数据库连接“一定得正确
4)获取系统信息
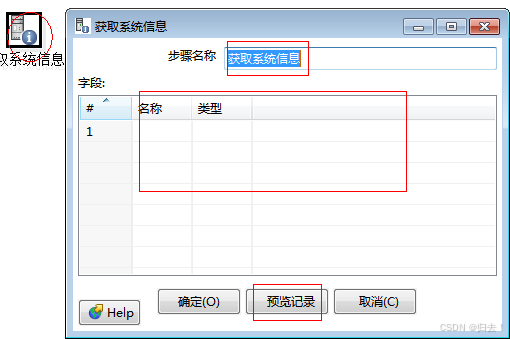
功能描述:包括命令行输入的参数,操作系统时间,ip 地址, 一些特殊属性, kettle 版本等
5)表输入
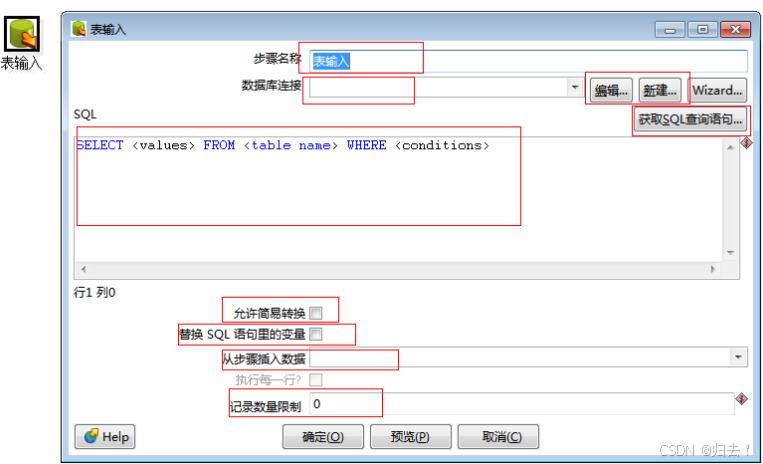
功能描述:从某个数据库中按条件查找某个表的数据
注意事项:
1、可以使用变量替换的方式进行查询,请将"替换sql语句里的变量”勾选上
2、可以使用上一步结果中赋予值,请将“从步骤插入数据”选择上一步的名称
3、当sybase数据库同步含有中文字符的数据至其它库时,请将"允许简易转换"勾选上
4、在预览时,会出现双精度的值显示不正常的问题,不影响实际输出值
5、测试过程中发现如果上一个步骤设置的变量,在table input 里面获取不到,变量设置必须作为一个单独的转换先执行一-次, 然后才能获取到这个变量
6)文本文件输入
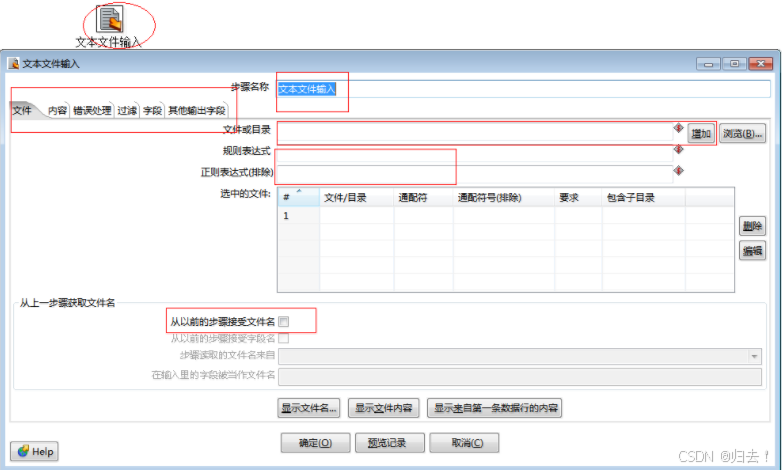
7)XML文件输入
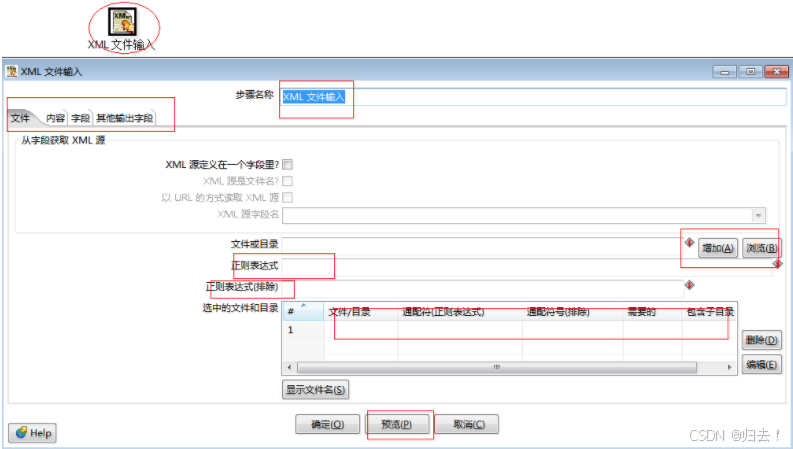
8)EXCEL输入
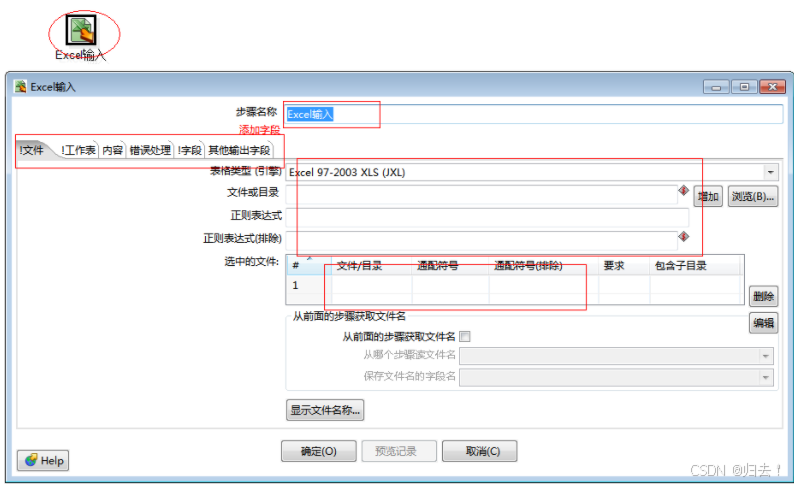
功能描述:读取excel文件,和csv文件读取类似,增加了表单,表头,出错(是否忽略错误,严格的类型判断等)的处理
9)CSV输入
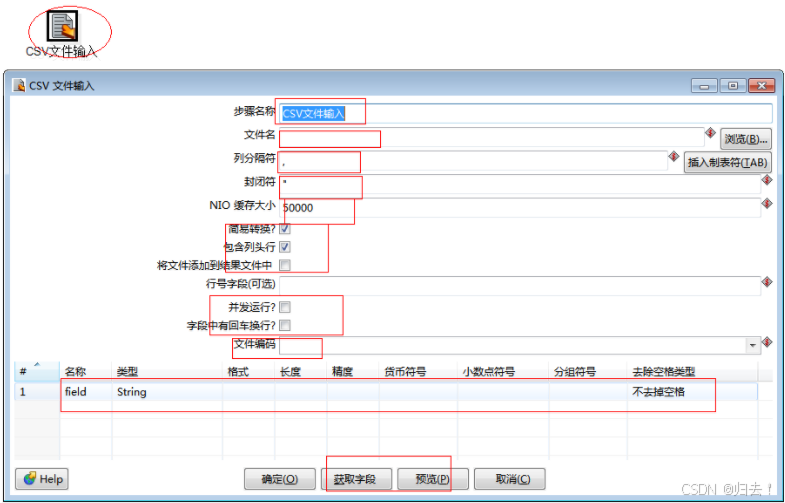
功能描述:读取csv文件,设置CsV文件路径,可以设置csv文件的相对路径或者绝对路径,字段分隔符,文件读取的缓存大小等
10)JSON输入
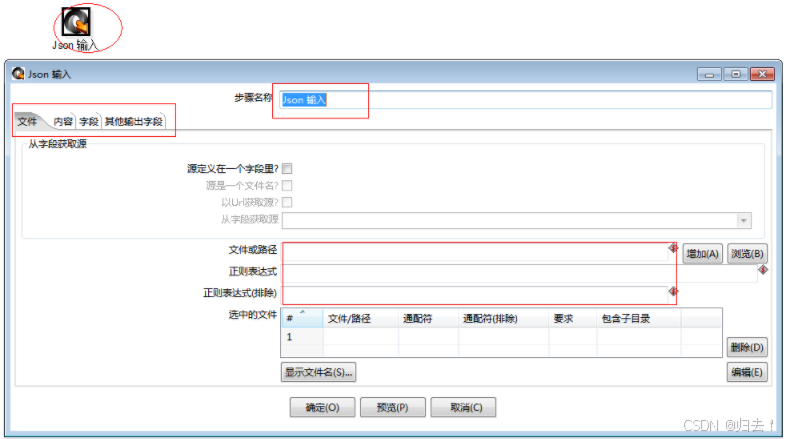
(2)输出
1)表输出
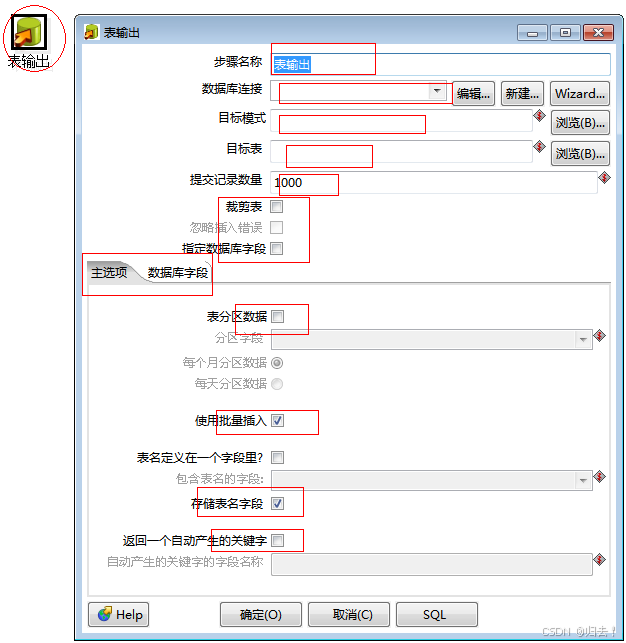
功能描述:将数据写入到数据库,可以指定是否truncate表,编辑前一步转换字段与现在表结构的字段映射关系。以及每次commit的记录数大小等
注意事项:
1.同步的id值不要选择更新,其它字段根据要求进行插入或更新操作,若需要修改id,则使用"序列”功能来实现2.当源表跟目标表的字段名不同时,要将"指定数据库字段”勾选上3.杜绝使用"裁剪表" (防止锁表),若需要此功能,则可以使用"delete" 功能进行变相操作4.表的错误输出处理
2)插入\更新
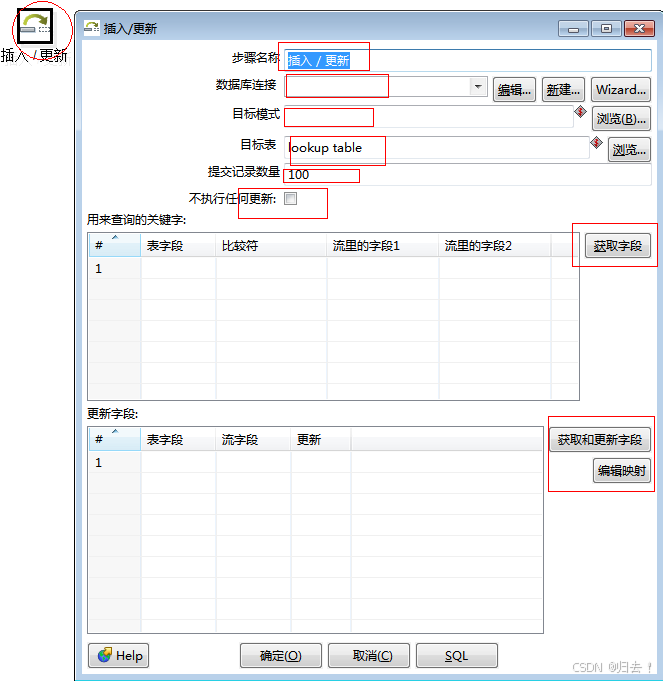
功能描述:将源表流转过来的数据,根据设置进行插入、更新操作
注意事项:
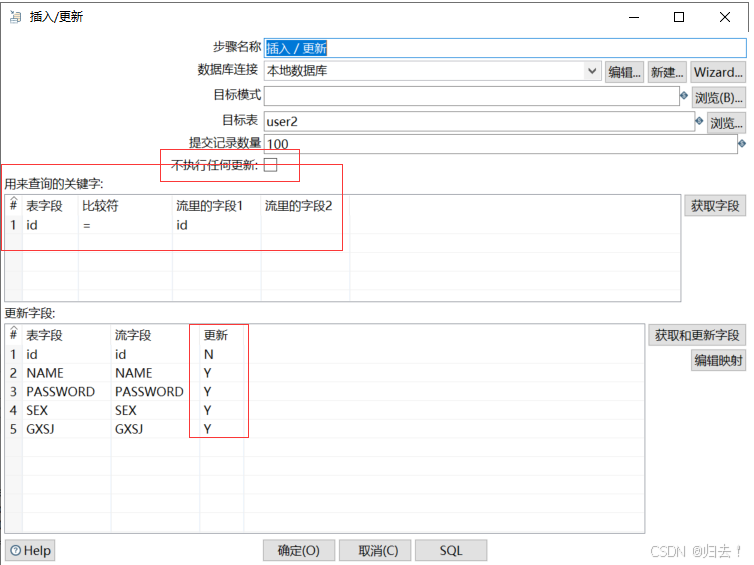
1.若只需要插入操作,则勾选上"不执行任何更新”2.提交数量不要设置过大,尽量使用小数量3.一定要有能唯一 识别某行数据的主键4.表的错误输出处理
3)更新
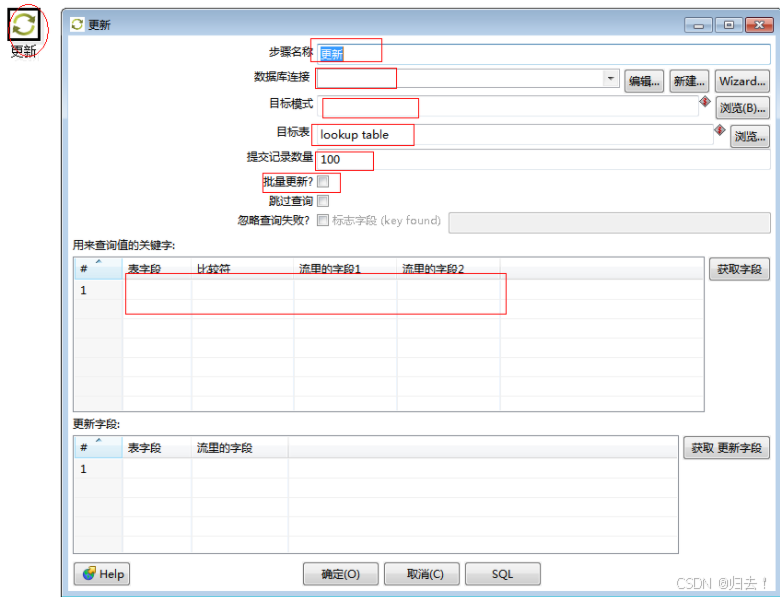
功能描述:将源表同步过来的数据进行目标表数据更新操作
注意事项
1.一定要有能唯一识别某行数据的主键
2.需要更新的字段在"更新字段"中选择(当字段名不同时需要进行映射)
3.表的错误输出处理
4)删除
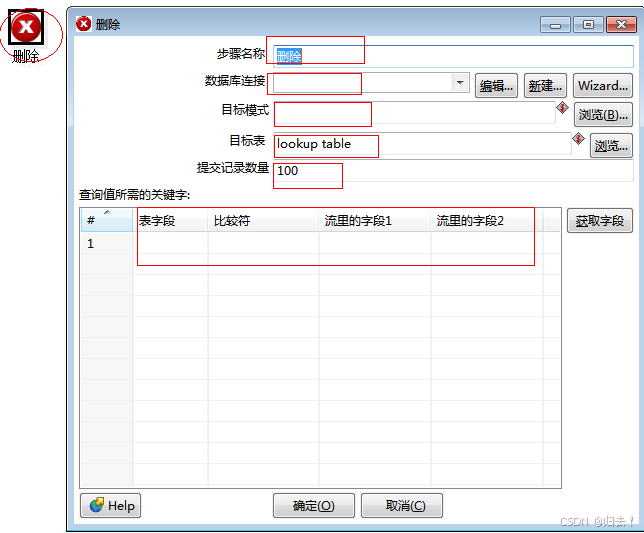
功能描述:根据给定的条件进行删除目标表数据
注意事项:
1.数据库能正常连接
2.目标表名正确
3.提交记录数量不宜过大
4.查询的字段最好是主键
5.表的错误输出处理
5)文本文件输出
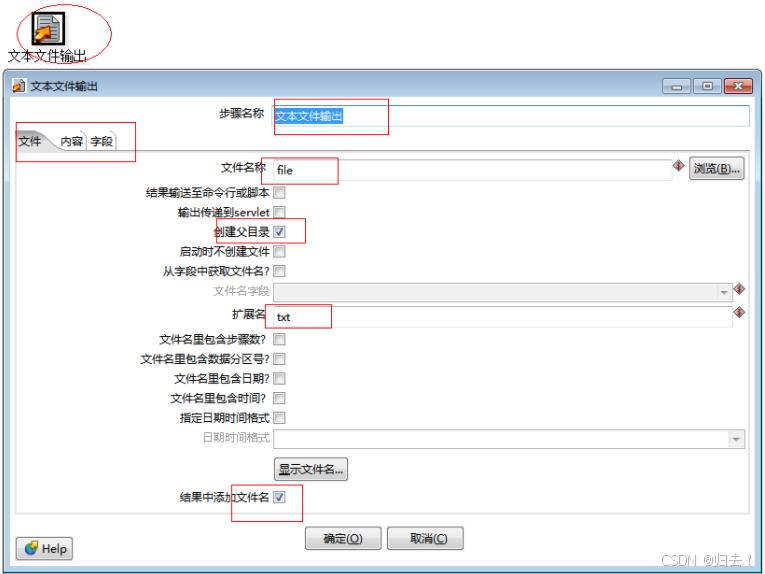
功能描述:将数据写入到文本文件,通常是CSV文件
注意事项:注意输出路径、注意文件名、注意分隔符
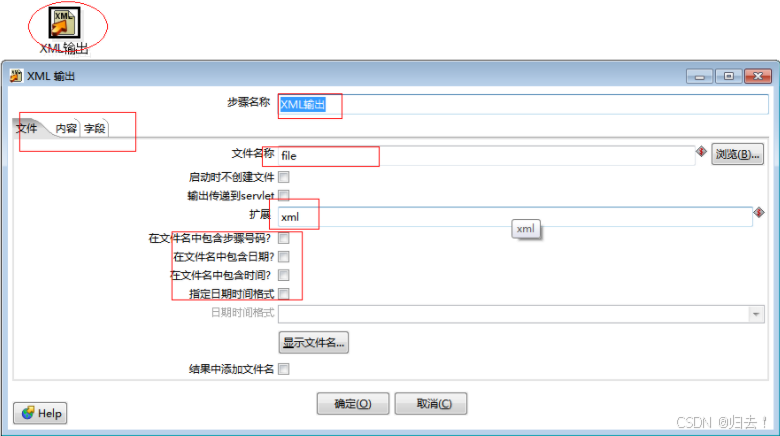
6)XML文件输出
7)EXCEL文件输出
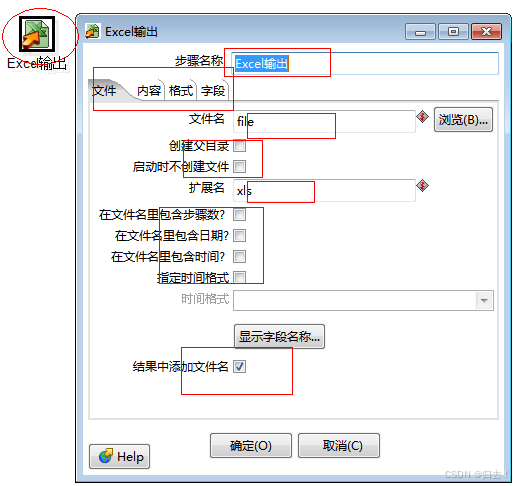
功能描述:输出到EXCEL,格式可以采用excel模板
8)JSON输出
9)SQL文件输出
功能描述:将输出的SQL Insert语句保存到文件中
(3)转换
1)值映射
2)剪切字符串
注意事项:1.能操作的字段一定是字符类型
2.起始、结束位置与java相同
3.可以更改输出流字段名
3)去除重复记录
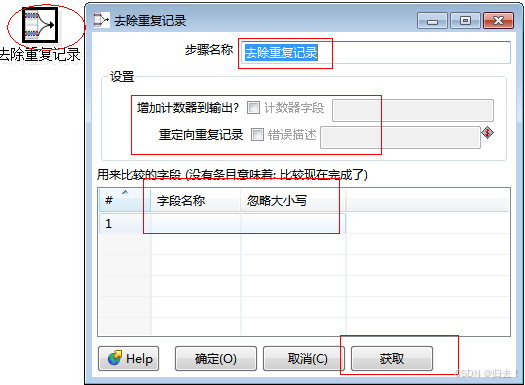
功能描述:
1.根据指定的字段进行排除重复记录
2.可以统计出重复的数量
3.可以将重复的记录重定向注意事项:使用前必须排序
4)唯一行
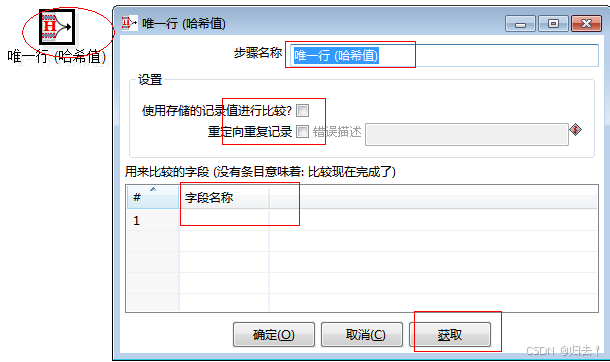
功能描述:去掉输入流中的重复行,在使用该节点前要先排序,否则只能删除连续的重复行
5)增加常量
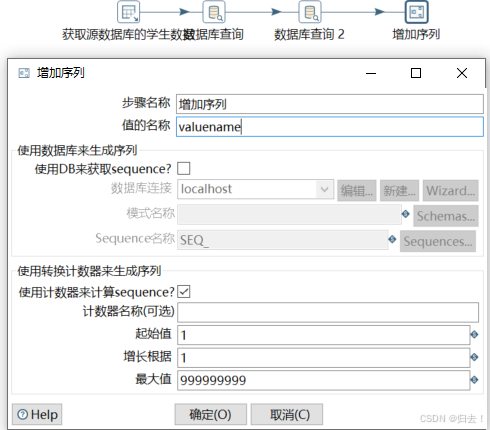
6)增加序列
7)字段选择
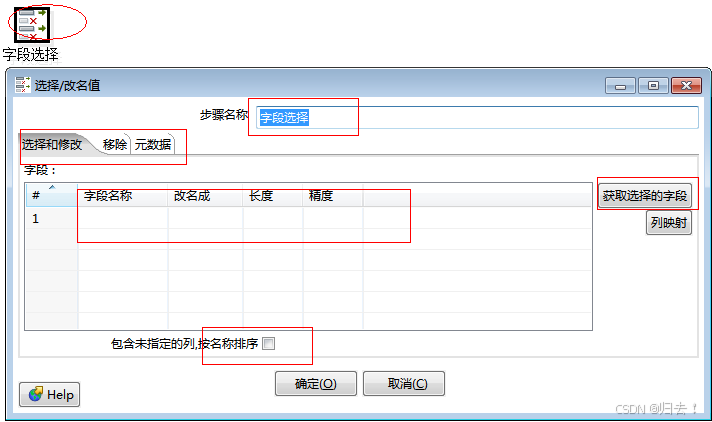
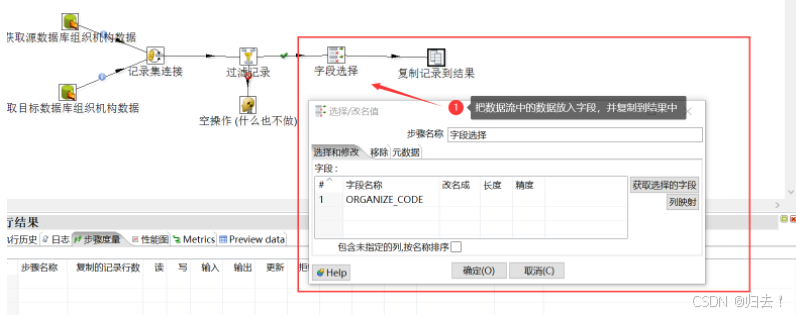
功能描述:用于选择列,重命名列,指定列长度或精度
注意事项:1.可以移除不需要的字段2.可以更改字段值类型、样式3.可以手动增加需要的字段
8)字符串操作
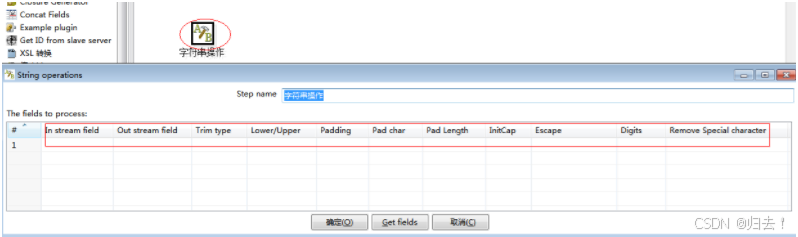
功能描述:与JAVA中的字符串操作相同
9)字符串替换
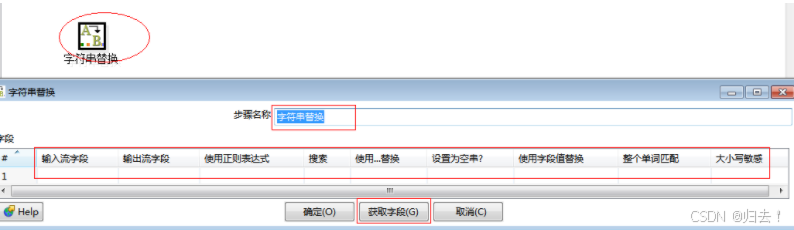
功能描述:与JAVA中的字符串替换类同
10)排序记录
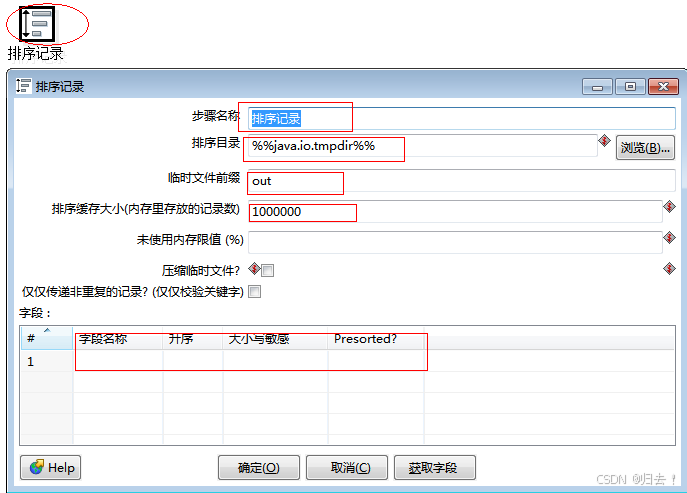
功能描述:对指定的列以升序或降序排序,当排序的行数超过5000时需要临时表
注意事项:排序的数据尽量不要太多
11)设置字段值
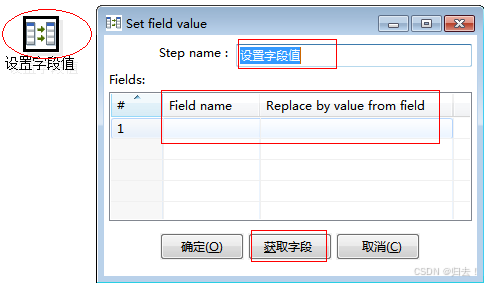
功能描述:使用某个字段流更改另一个字段流值
注意事项:字段类型要对应
12)计算器
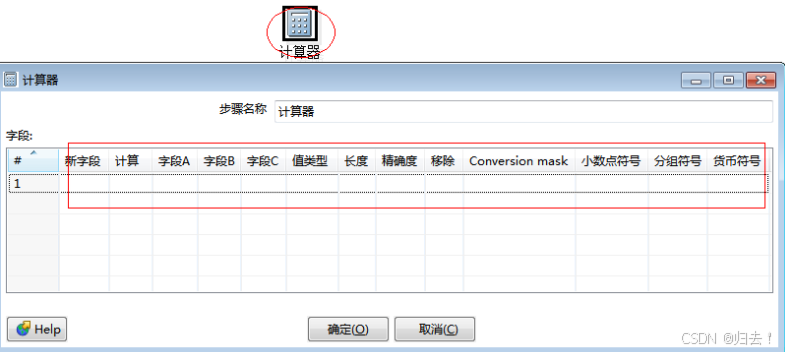
功能描述:提供了一组函数对列值进行计算,使用该方式比用户自定义JAVA SCRIPT脚本速度更快
(4)应用
(5)流程
1)Switch\Case
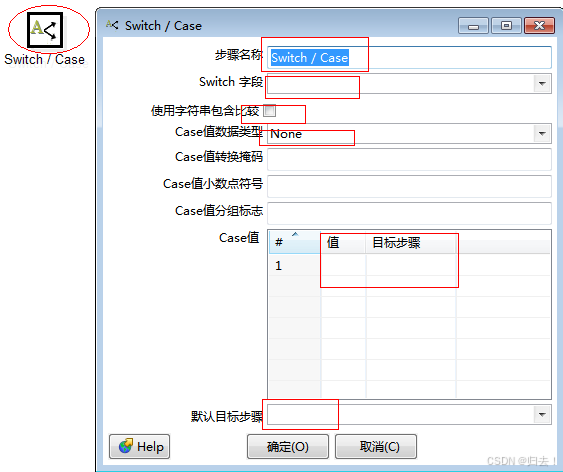
功能描述:对于多种类型的值进行不同的选择路径注意事项:
1.一定得有个默认的路径
2.先产生目标步骤,再进行路径连接
3.注意命名规范,最好见名知意
2)中止
3)执行作业
4)检测空流
5)空操作
功能描述:不做任何处理,一般作为流程的终点
6)识别流的最后一行
7)过滤记录
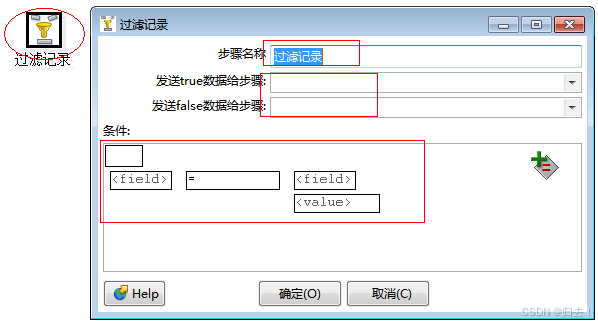
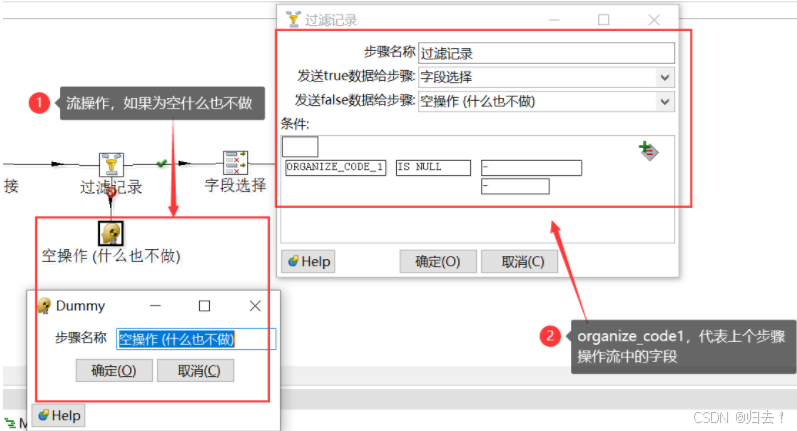
功能描述:通过使用一个表达式从输入行中过滤数据,将结果是TURE或FALSE的行输出到不同的节点。表达式是”"OPERATOR”“的形式,其中OPERATOR可以是=,<>,<,>, <=, >=, REGEXP,IS NULL,IS NOT NULL, IN LIST, CONTAINS,STARTS WITH, ENDS WITH。用户可以增加多个表达式,并用AND或OR连接
注意事项:正确选择对应的步骤
(6)脚本
1)JAVA代码
2)Java Script代码
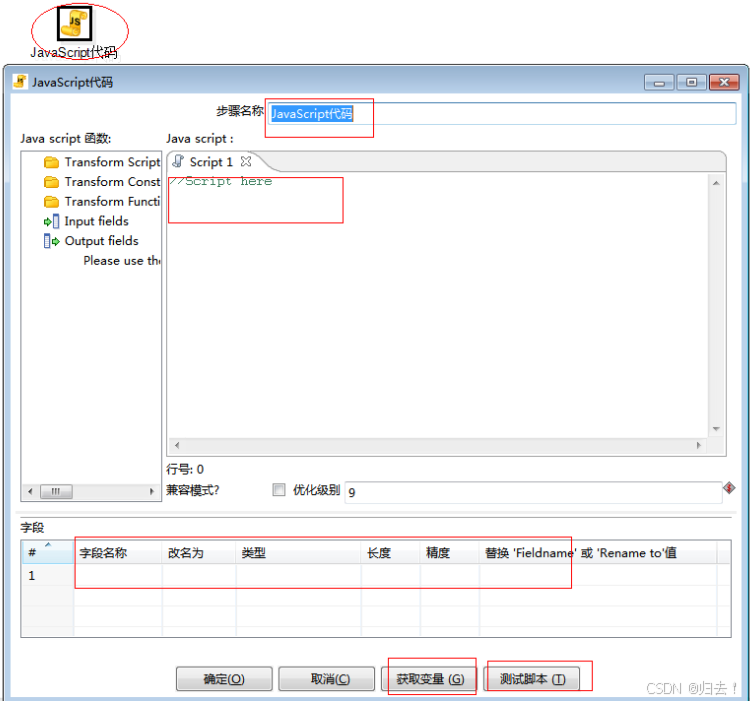
功能描述:使用mozilla的rhino作为脚本语言,并提供了很多函数,用户可以在脚本中使用这些函数。
例如
var prev_ row;
if (prev_row == null) prev_row = row;
...
StringpreviousName = prev_row.getString( "Name","-" );
...
prev_ row = row可以获得字段Name的前一条记录的值
3)执行SQL脚本
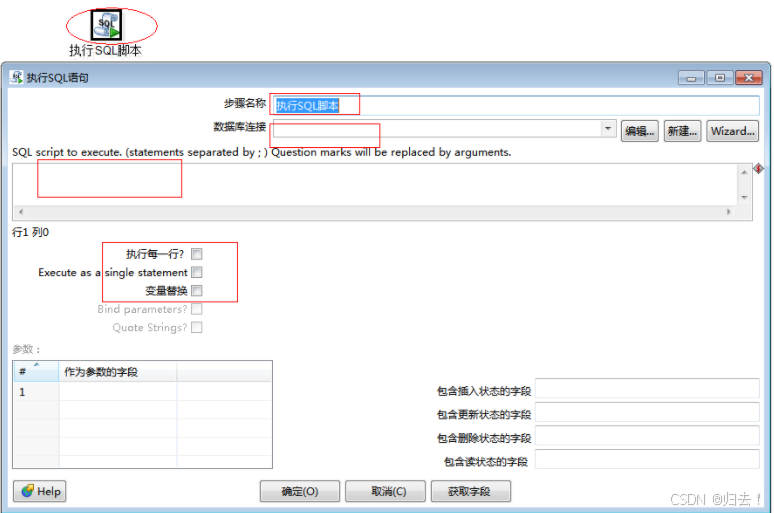
功能描述:执行SQL脚本,应该避免使用这一步骤, 尽可能的使用"table input(select)","table output(insert)" , "update" ," delete" 等步骤来替代。譬如动态创建表(表名是可变的,table1,table2,table3) :CREATE TABLE ? ( ID INTEGER);
4)正则表达式
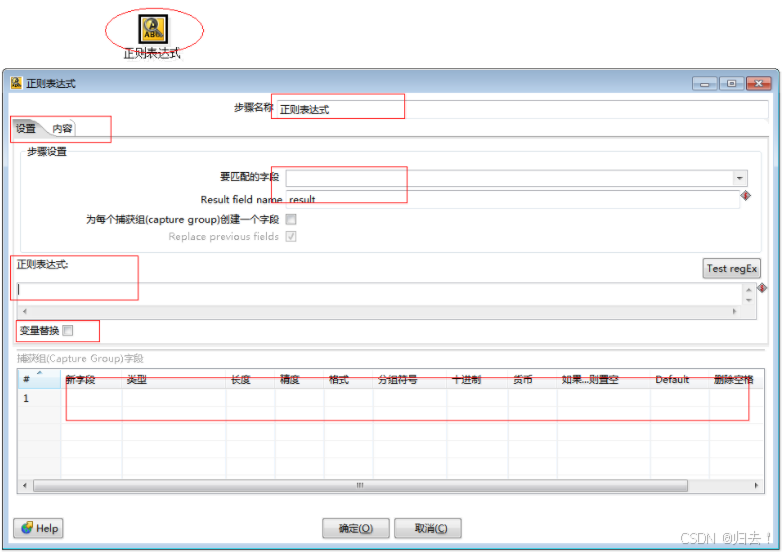
功能描述:通过正则表达式验证输入字段
(7)查询
1)调用数据库存储过程
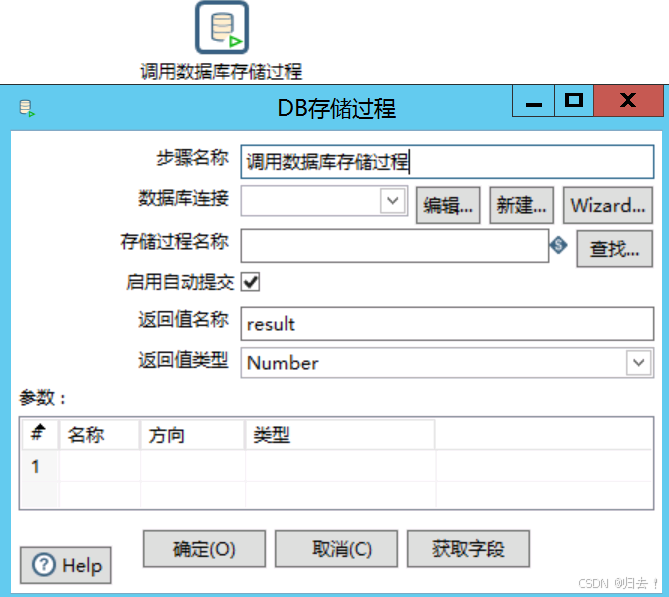
功能描述:执行存储过程并获得返回值,返回值只有一个,参数可以多个
注意事项:1.返回值只有一个,并且只针对函数
2.当调用的过程时,要返回值名称删除
2)流查询
3)数据库查询
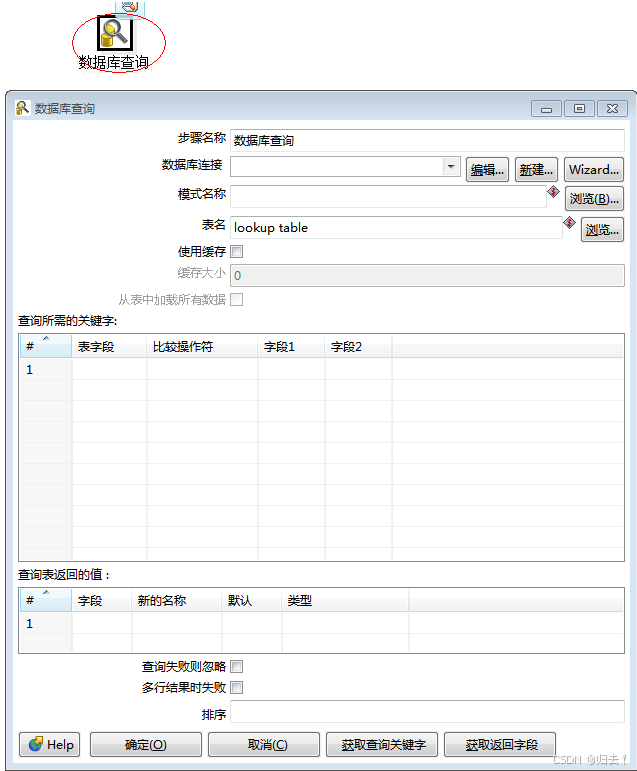
功能描述:从数据库查询数值,作为新的字段添加到数据流中。可将前面的输出流的值作为查询比较参数
(8)连接
1)合并记录
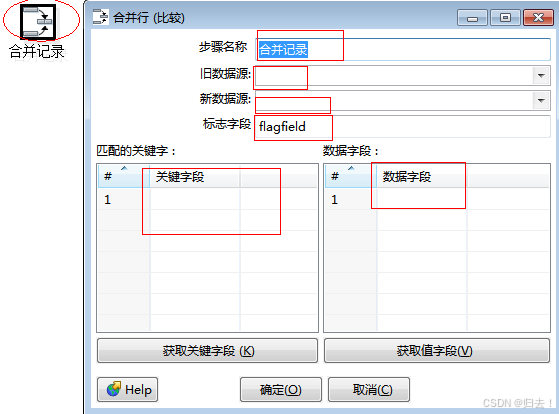
功能描述:用于比较两组输入数据,一般用于更新后的数据重新导入到数据仓库中。两组数据中一组是引用流,一组是比较流,每次比较后只有最新版本的行数据被输出到下一步。
比较结果包括:1.idectical 一致:两组流的主键一致,值一致2.changed有变化:两组流的主键一致,值有一个或多个不同3.new新行:引用流中有而比较流中没有某一主键4.deleted被删除的行:比较流中有而引用流中没有某一主键。 比较流里面的数据除了被标记为deleted都会进入下一一个步骤里面
2)排序合并
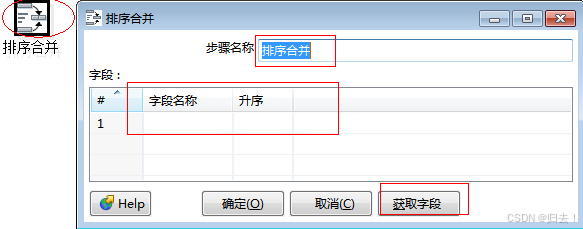
功能描述:对记录按某个关键字进行排序
3)记录关联(笛卡尔输出)
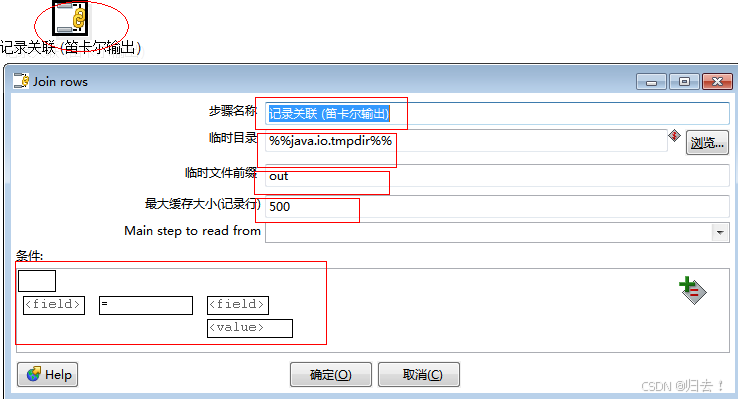
功能描述:对所有输出流做笛卡尔积
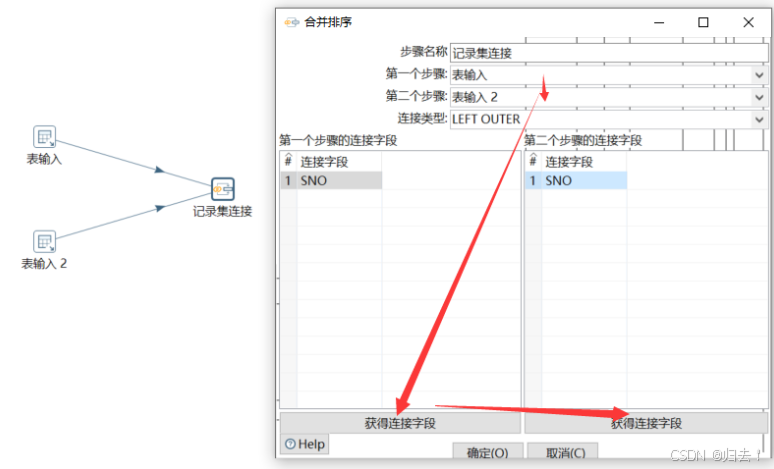
4)记录集连接
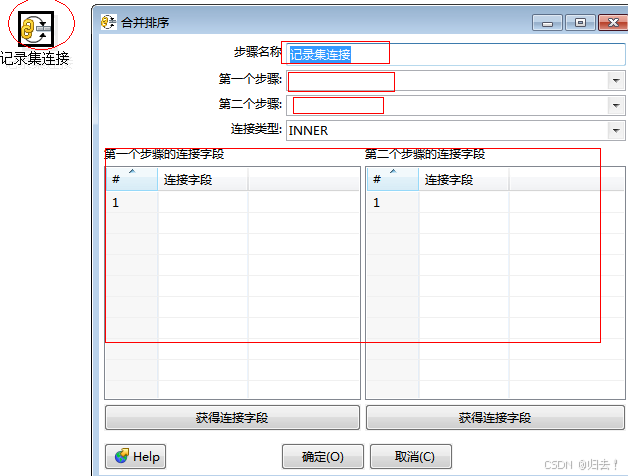
功能描述:合并两种不同输入流,连接方式有内连,左外连接等。注意事项:记录需要先按关键字进行排序
(9)数据仓库
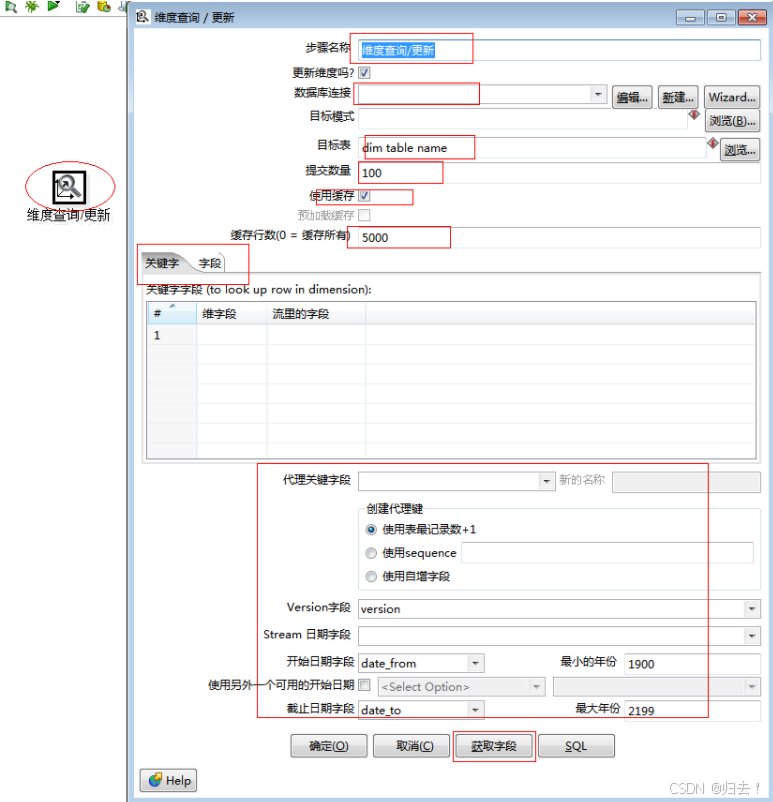
1)维度查询、更新
2)联合查询、更新
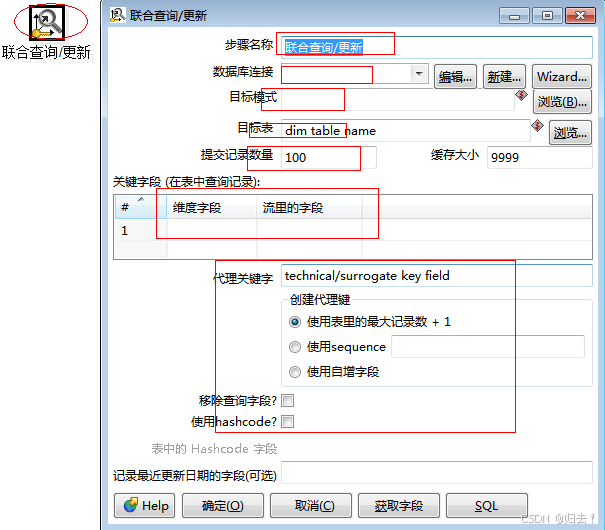
(10)作业
1)设置变量
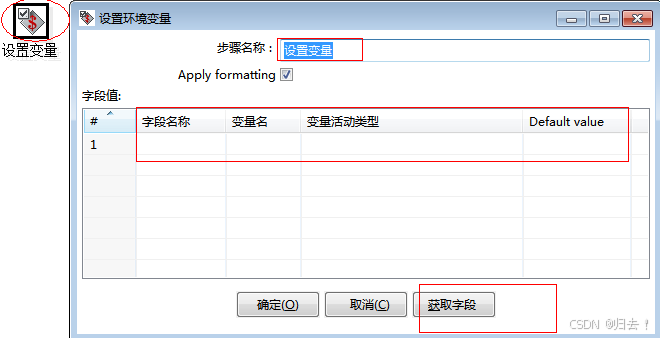
功能描述:1.将字段流值设置为变量2.可以添加默认值注意事项:字段流只能是一-行数据
2)获取变量
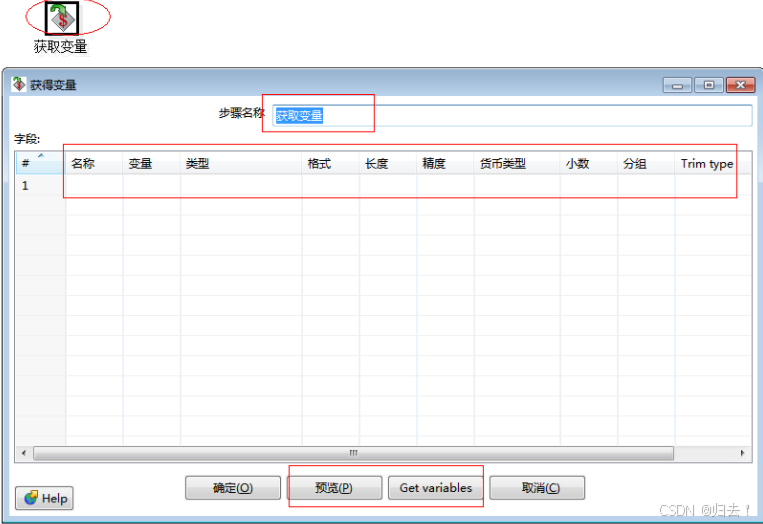
功能描述:更加变量名获取对应的值,并做相应的格式输出。
3)复制记录到结果
功能描述:复制记录到内存
4)从结果中获取记录
功能描述:从内存中获得记录
(11)批量加载
1)ORACLE批量加载
功能描述:批量加载表中的数据
4.作业
(1)通用
1)START
功能描述:1.指定job执行规则,是否循环,循环规则等
2.重复执行,可以设置重复执行的间隔时间
2)DUMMY

功能描述:空操作,主要用来多数据源汇总
3)作业
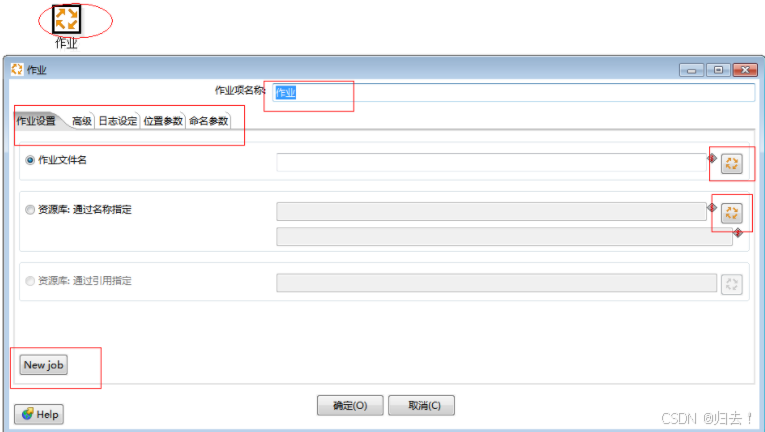
功能描述:执行已经定义好的job,job可以嵌套job
4)成功
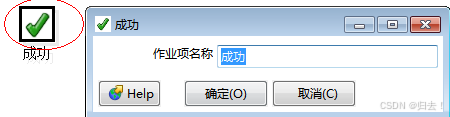
功能描述:将出错后可以强制将该job置成功
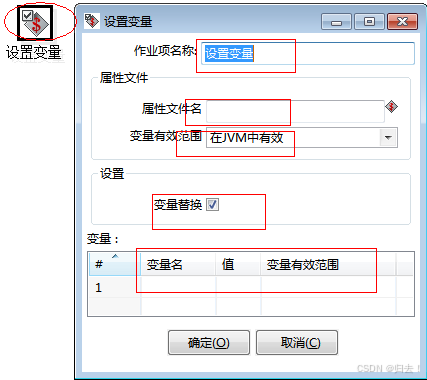
5)设置变量
6)转换
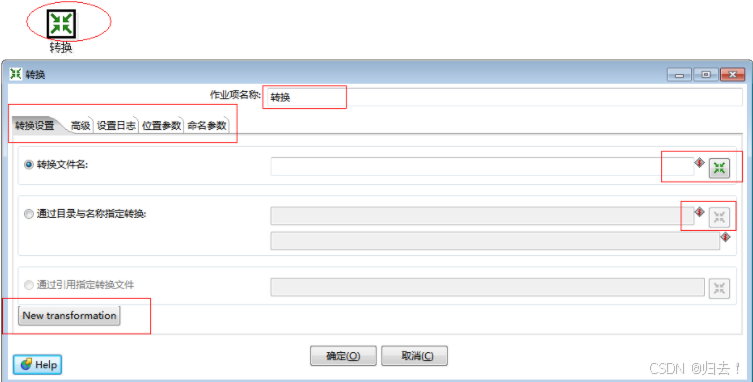
功能描述:
1.执行定义好的转换
2.将转换任务提交给job进行定期执行
3.记录日志
(2)邮件
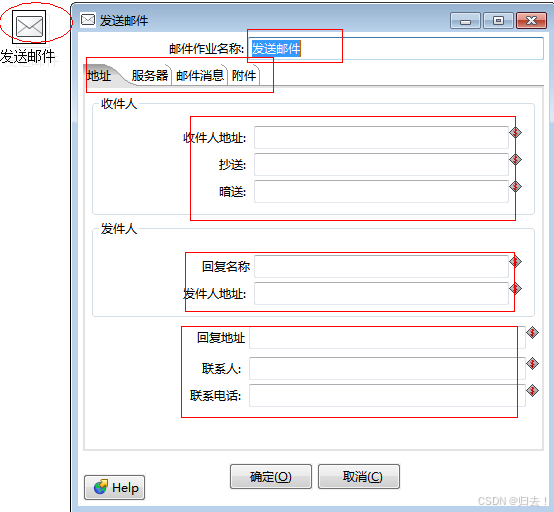
1)发送邮件
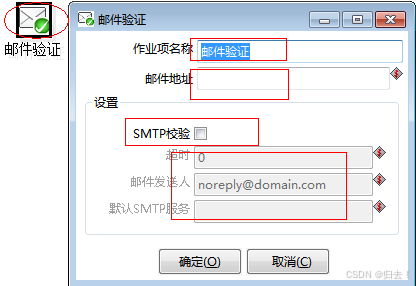
2)邮件验证
(3)文件管理
1)创建目录
2)创建文件
3)删除目录
4)删除一个文件
5)删除多个文件
(4)条件
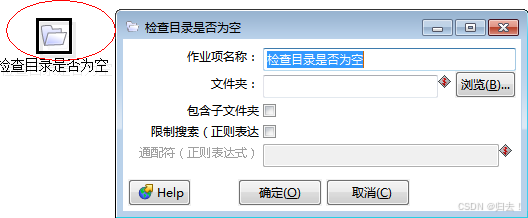
1)检查目录是否为空
2)检查一个文件是否存在
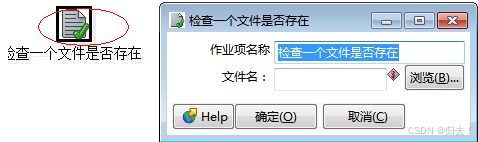
功能描述:检查文件是否存在
注意事项:文件名由上一步传来
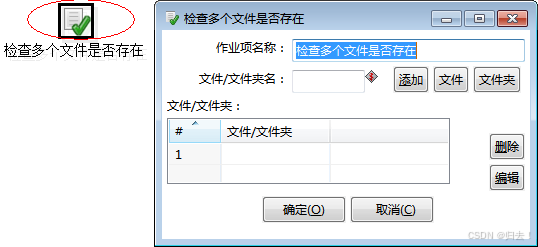
3)检查多个文件是否存在
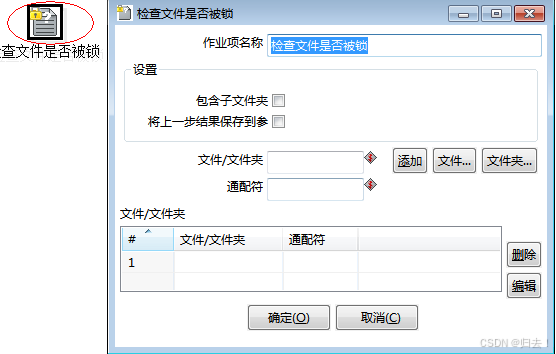
4)检查文件是否被锁
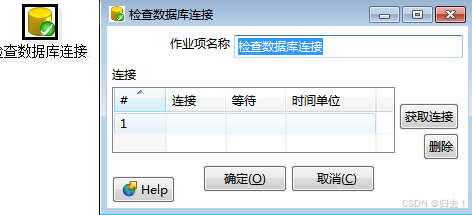
5)检查数据库连接
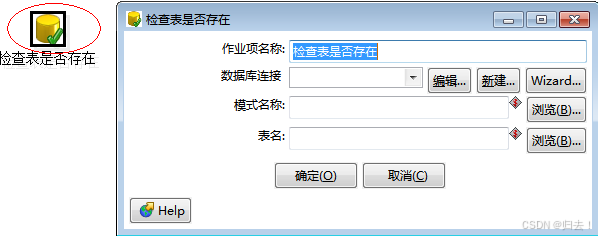
6)检查表是否存在
7)检查列是否存在
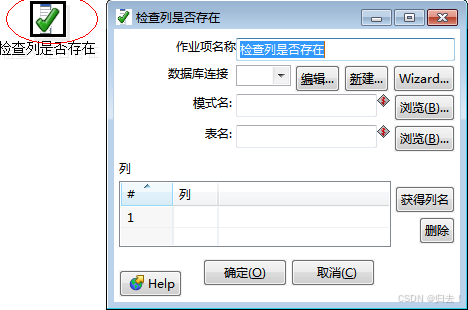
功能描述:检查数据库表是否存在某列
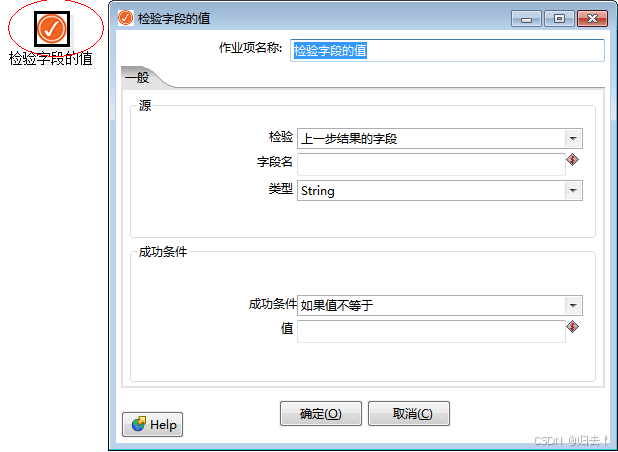
8)检验字段的值
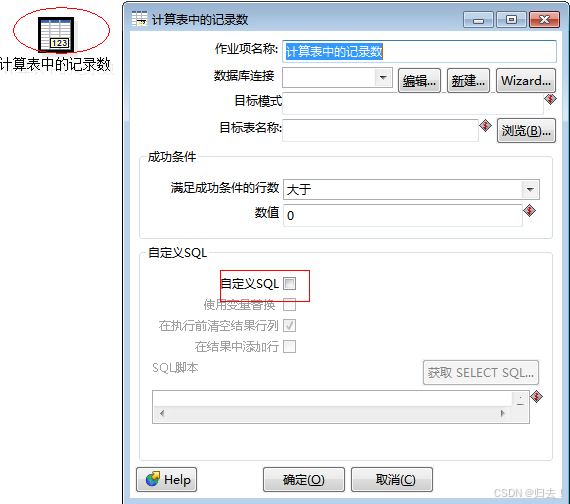
9)计算表中的记录数
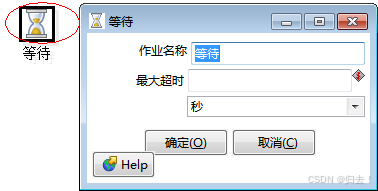
10)等待
11)计算文件的大小和个数
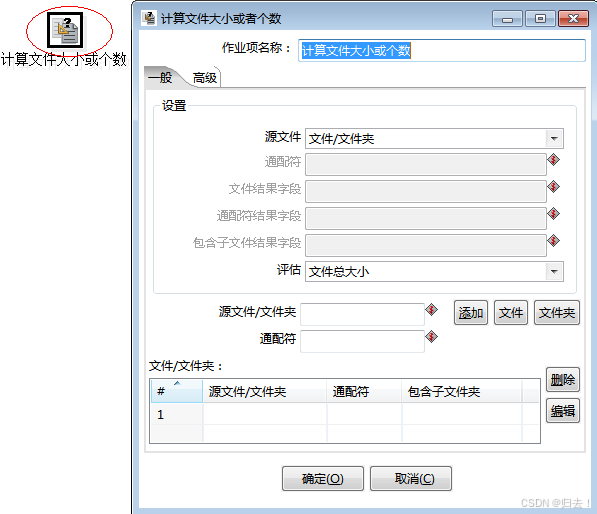
(5)脚本
1)shell
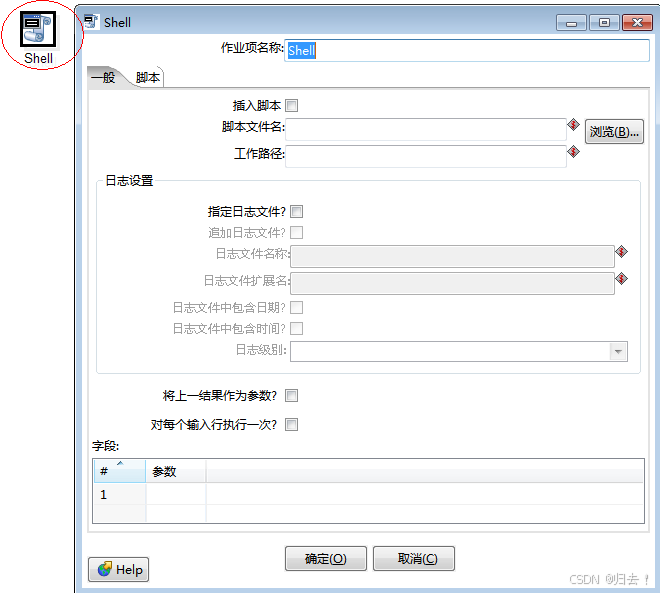
功能描述:执行SHELL脚本,可以执行已经写好的shell脚本指定shell脚本路径即可,也可以自己插入,编辑shell脚本可以把前一个步骤的执行结果当作参数传入
2)SQL
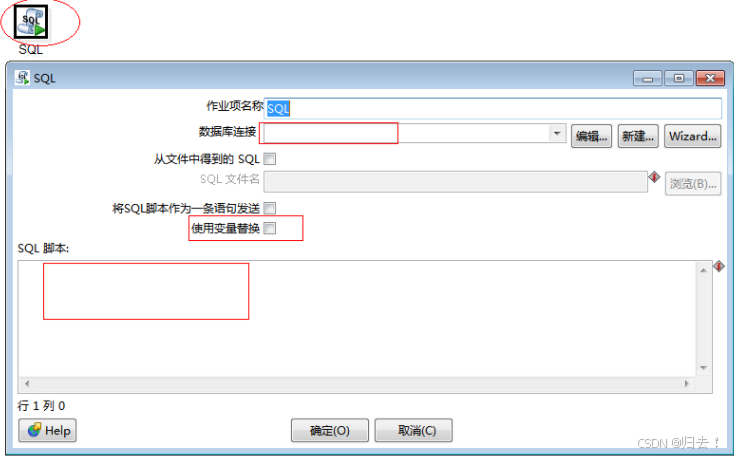
功能描述:执行SQL脚本可以执行写好的SQL脚本,指定SQL路径即可。也可以插入编辑SQL脚本
3)使用JAVA SCRIPT脚本验证

5.资源导出
6.资源导入
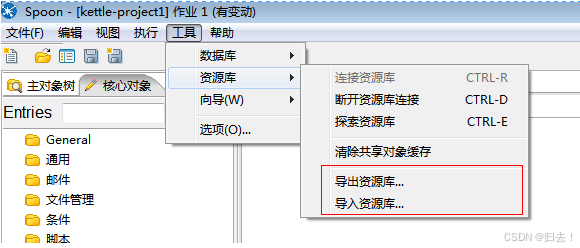
7.分区
8.集群
五(一)、数据定时自动(自动抽取)同步作业
1.表数据自动同步
(1)首先在数据库创建四张表,表结构如下:
t_ student_ _kettle 学生数据源表;t_ student_ kettle_ target学生目标数据表;t_ class 班级数据源表;t_ class_ _target 班级班级目标数据表;t_ tbrz同步日志表
--1、学生数据源表
-- Create table
create table T_STUDENT_KETTLE
( id INTEGER,
name VARCHAR(2000),
sex VARCHAR(2000),
age INTEGER,
cjsj DATE,
zhgxsj DATETIME default sysdate)
tablespace MYSPACE
pctfree 10
initrans 1
maxtrans 255
storage
(
initial 64K
next 1M
minextents 1
maxextents unlimited
);
--学生目标数据表
-- Create table
create table T_STUDENT_KETTLE_TARGET
(
id INTEGER,
name VARCHAR(2000),
sex VARCHAR(2000),
age INTEGER,
cjsj DATE,
zhgxsj DATE default sysdate ) ;
tablespace MYSPACE
pctfree 10
initrans 1
maxtrans 255
storage
(
initial 64K
next 1M
minextents 1
maxextents unlimited
);
--班级数据源表
-- Create table
create table T_CLASS
(
id NUMBER,
class VARCHAR(100),
cjsj DATE,
zhgxsj DATE )
tablespace MYSPACE
pctfree 10
initrans 1
maxtrans 255
storage
(
initial 64K
next 1M
minextents 1
maxextents unlimited
);
--班级目标数据表
-- Create table
create table T_CLASS_TARGET
(
id NUMBER,
class VARCHAR(100),
cjsj DATE,
zhgxsj DATE
)
tablespace MYSPACE
pctfree 10
initrans 1
maxtrans 255
storage
(
initial 64K
next 1M
minextents 1
maxextents unlimited
);
-- 同步日志表
-- Create table
create table T_TBRZ (
id NUMBER, --id
tbcgsj DATE, --同步成功时间(结束时间)
tbkssj DATE, --同步开始时间
bm VARCHAR(100), --同步表名
tbjg CHAR(1) --同步结果:1-成功;2-未成功
)
tablespace MYSPACE
pctfree 10
initrans 1
maxtrans 255
storage
(
initial 64K
next 1M
minextents 1
maxextents unlimited
);
--创建同步日志表的序列
create sequence SEQ_T_TBRZ
minvalue 1
maxvalue 999999999
start with 81
increment by 1
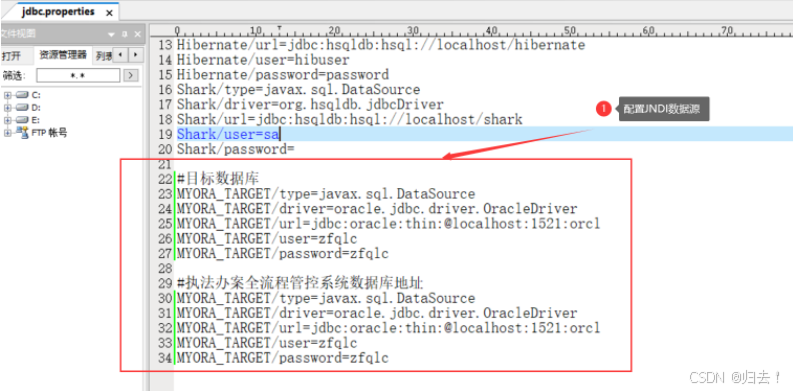
cache 20;2.配置数据库连接地址
一般项目上会通过配置jndi数据源直接连接数据库,不在配置jdbc数据源了,有点类似于java的配置
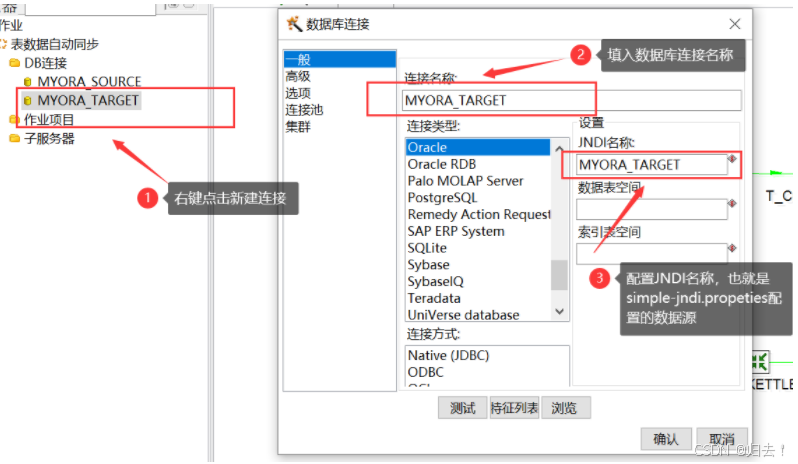
3.设置数据库连接,通过JNDI方式
4.作业整体流程

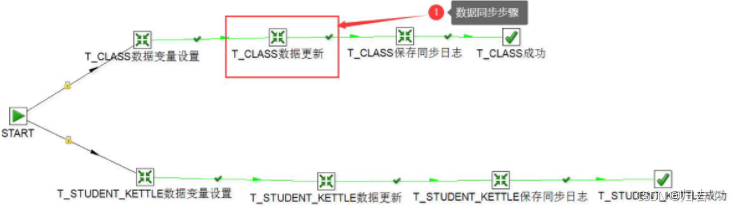
需要用到1个作业和6个转换来操作2张表,-一个表是3个转换来完成,几张表总共的转换就是N*3个转换。下图为整个作业的流程:
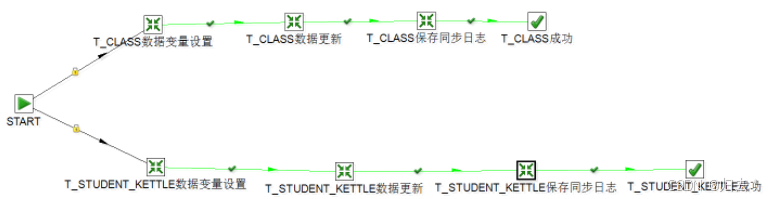
由上面流程图可以看到,start 分了两个分支,一个是class表,一个是student表,下面我们来一一点开每个转换看下。
(1)T_CLASS数据变量设置
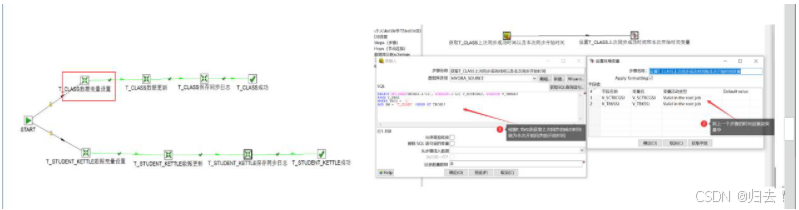
如上图,T_ _CLASS 数据变量设置,该步骤是获取.上次同步的成功时间,做为下次同步的开始时间,并设置到环境变量中,供后续的数据流调用
(2) T_ CLASS数据变量设置
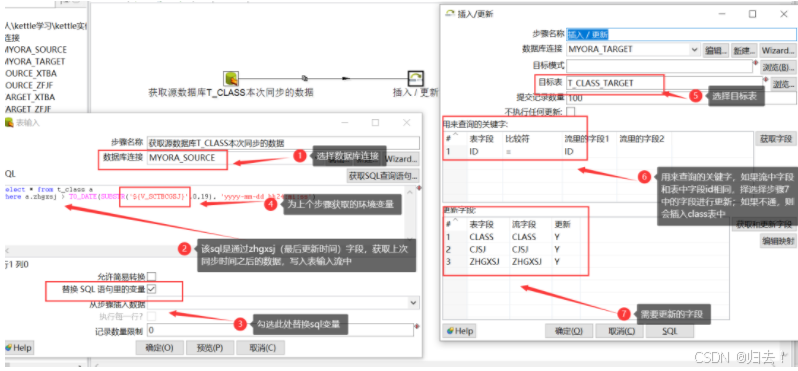
如上图,T_ _CL ASS数据更新步骤,该步骤是获取.上次同步的成功时间之后的数据,插入更新到表中。
(3) T_CL ASS保存同步日志
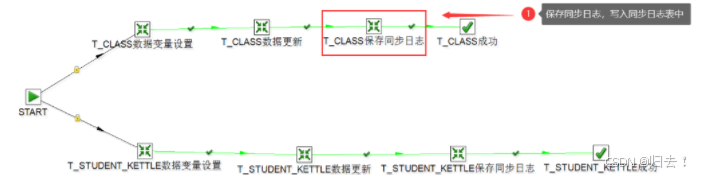
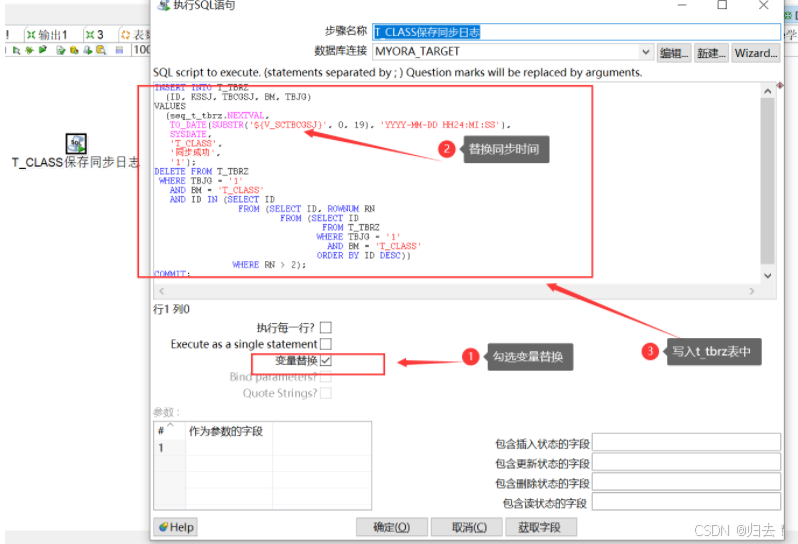
如上图,T_ _CLASS保存同步日志,该步骤是保存本次同步的同步成功时间,插入到同步日志表中,为下次同步的开始时间做准备,具体sql如下
(4) T_ CLASS同步成功
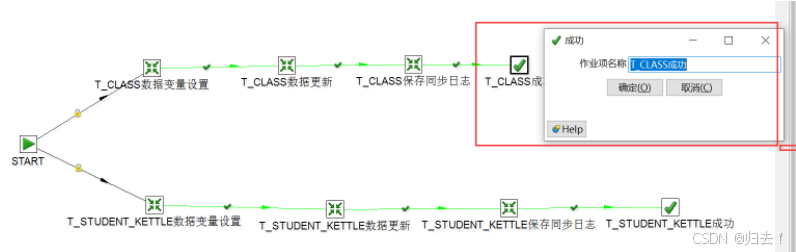
如上图,T_ _CL ASS同步步骤成功后,写入该成功步骤,提示成功。
(5)T_ STUDENT_ KETTLE 表的数据同步工作
如同T _CLASS表- -样,存在3个转换步骤
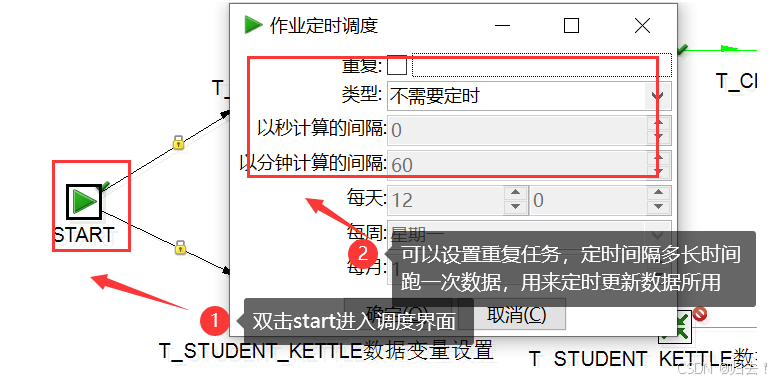
(6)运行转换
双击start,设置作业定时调度,设置完成后,运行转换
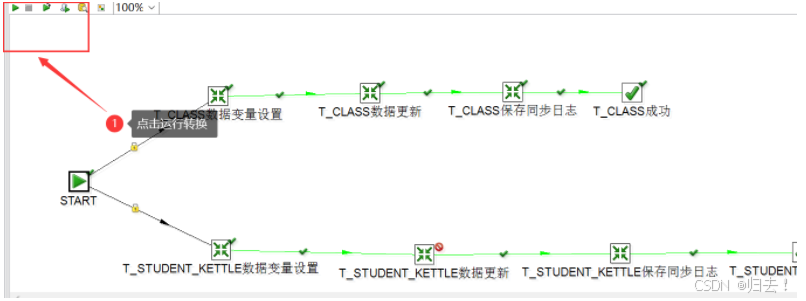
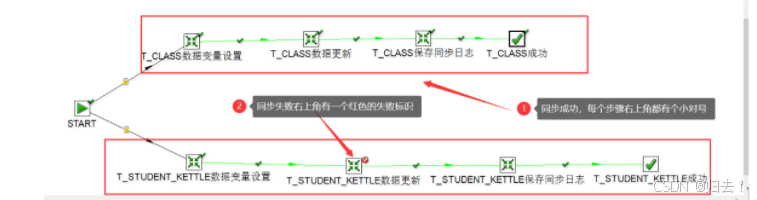
(7)运行结果
运行成功和运行失败有不同的结果展示,可以根据此结果进行错误排除
五(二)两表数据比较,比较后自动同步(部门、单位数据同步)
目标:比较t_bm表的数据和t_bm_target表的数据,以t_bm表为准,往t_bm_target 中进行数据的自动同步;
1.创建表,表结构如下
t_ bm部门单位表;t_ bm_target 部门单位目标表;
-- Create table
create table T_BM
(
organize_code VARCHAR(200), --单位代码
organize_name VARCHAR(200), --单位名称
cjsj DATE --创建时间
)
tablespace ZFQLC
pctfree 10
initrans 1
maxtrans 255
storage
(
initial 64K
next 1M
minextents 1
maxextents unlimited
);
-- Create table
create table T_BM_TARGET
(
organize_code VARCHAR(200), --单位代码
organize_name VARCHAR(200), --单位名称
cjsj DATE --创建时间
)
tablespace ZFQLC
pctfree 10
initrans 1
maxtrans 255
storage
(
initial 64K
next 1M
minextents 1
maxextents unlimited
);其中t_bm(单位表)的数据如下图:

t_bm_ target (单位目标表)的数据如下图:

2.作业整体流程

需要用到1个作业和4个转换来操作2张表
下图为整个作业的流程:
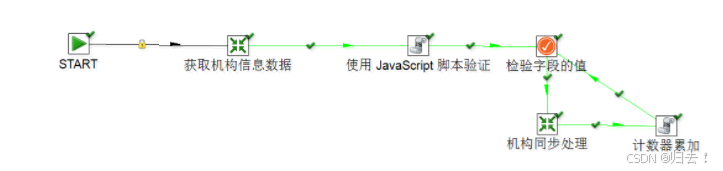
上面流程图就是整个作业的流程,用到了3个转换和2个JS脚本,来实现该需求
3.获取机构信息数据

(1)获取源数据如下图,sql 语句必须要按照机构代码进行排序
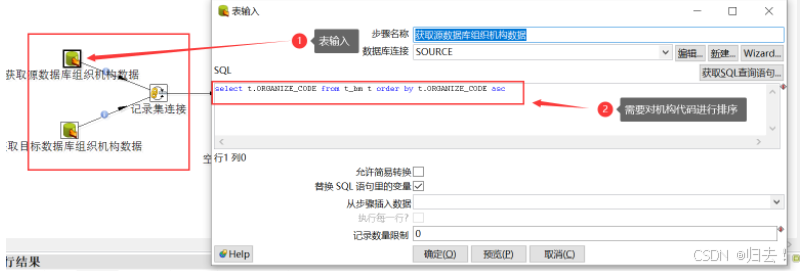
(2)获取源数据如下图,sql 语句必须要按照机构代码进行排序
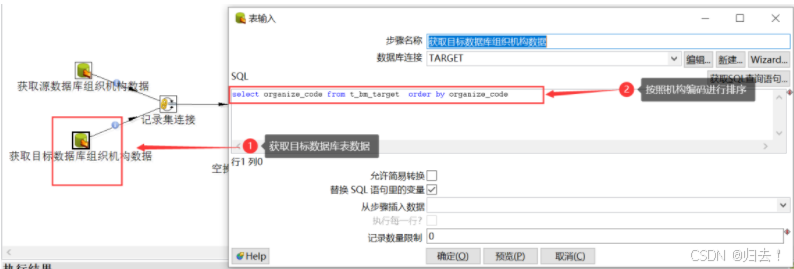
(3)将3.1和3.2的步骤通过hops连线,连接记录集连接控件
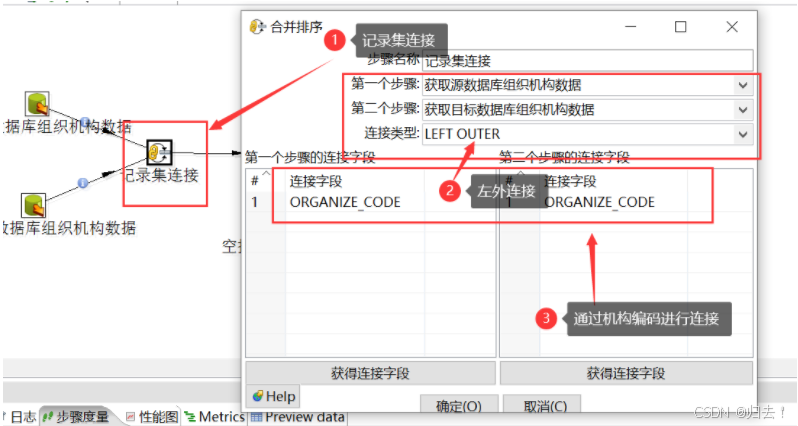
选择步骤1和步骤2,连接类型leftouter,,以步骤1的源表数据为基础创建连接,连接字段选择organize_ code 字段。
(4)设置条件过滤
如果organize_code为空的话,则什么都不做,不为空的话,放入数据流中
(5)字段选择
将不为空的数据放到字段选择中,并复制记录到结果,供下一个转换步骤使用.
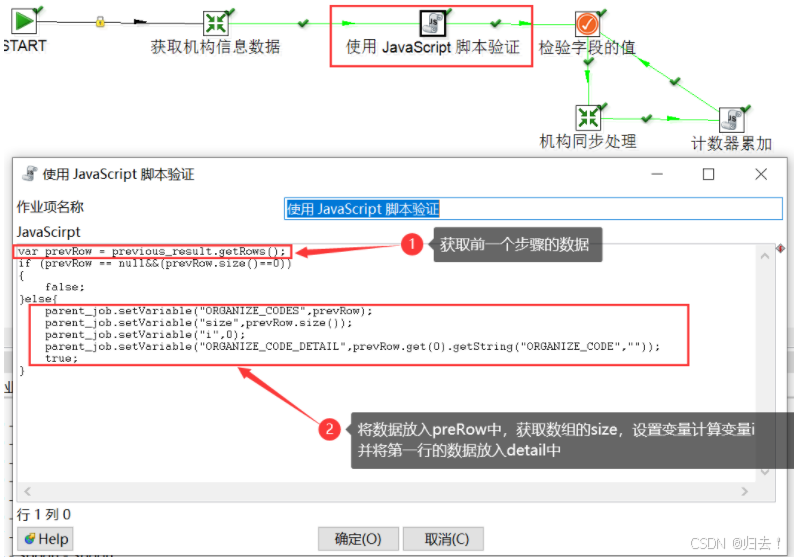
(6)JavaScript脚本验证,获取数据并设置到变量中
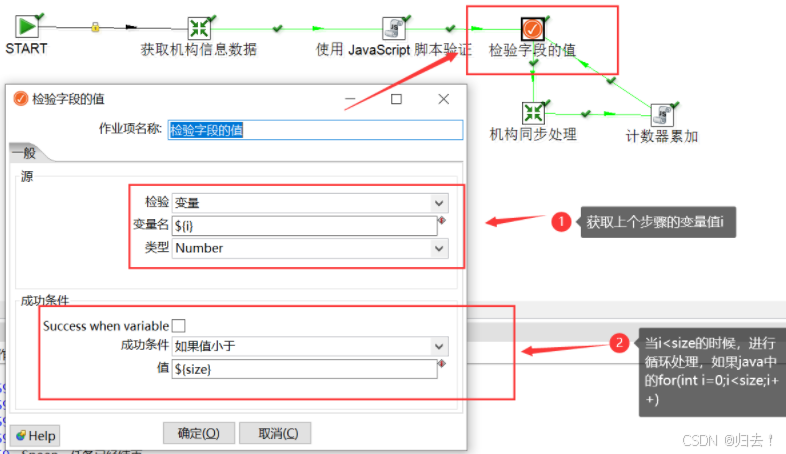
(7)检验字段的值,获取数据并设置到变量中
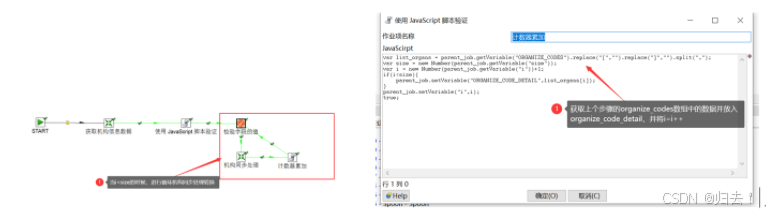
(8)计数器累加,获取i中的变量,并将结果放入detail明细中
(9)机构同步处理流程
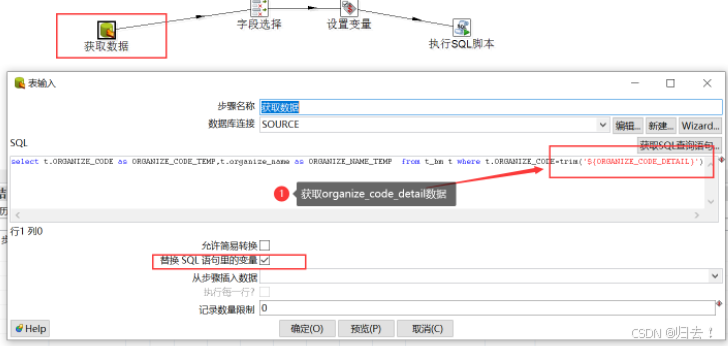
1)机构同步处理-获取数据,将上个步骤的detail数据放入变量中
2)sql脚本执行插入t_bm_target 表
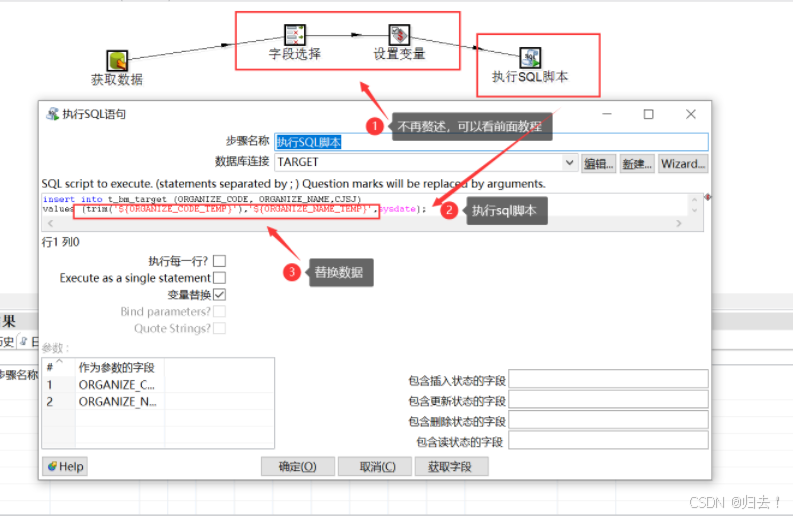
五(三)操作
1、文本/excel的导入导出和入表(视频Day1)
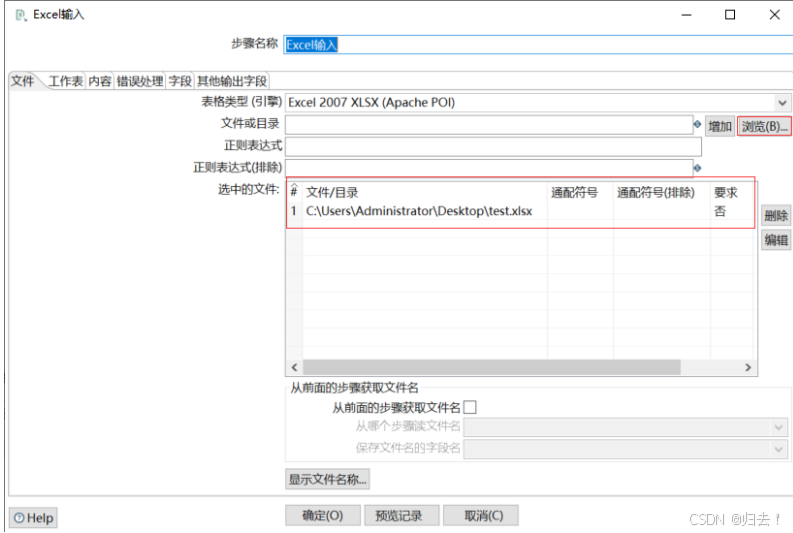
(1)excel写入txt

1)excel输入
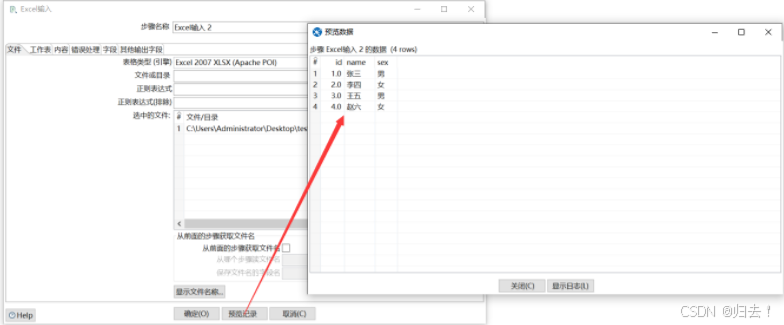
2)txt输出
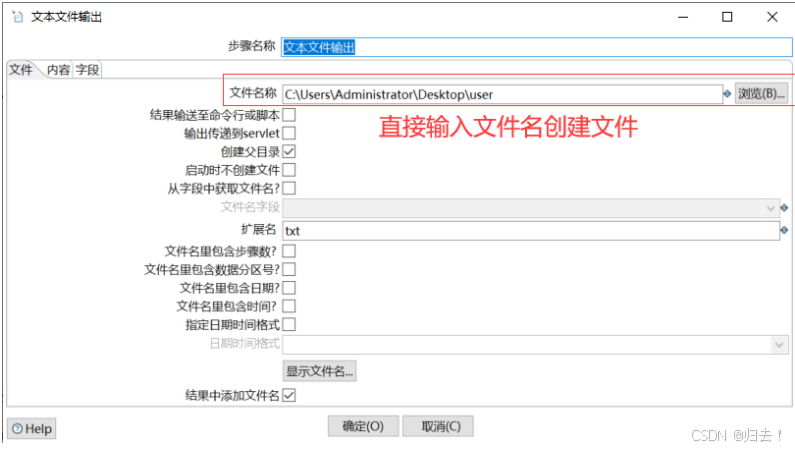
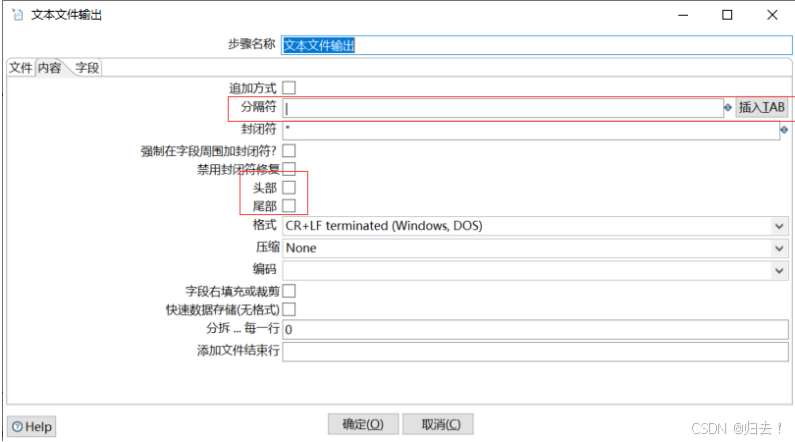
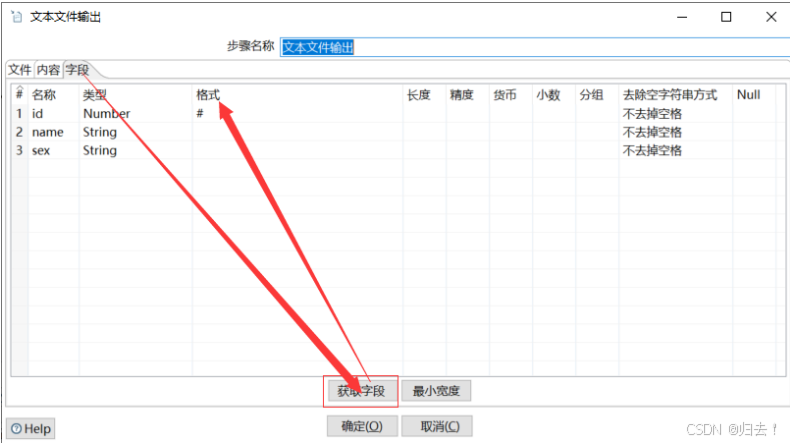
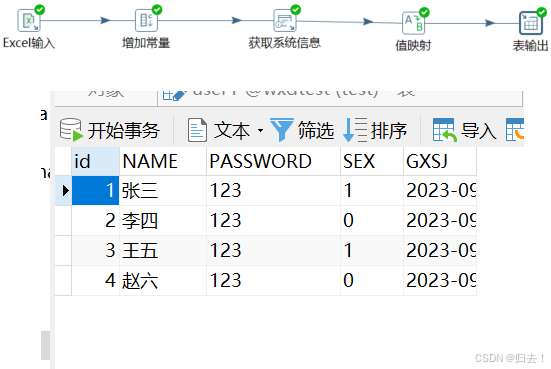
(2)excel写入数据库的table
1)excel写入同上
2)增加常量
给密码一个初始值
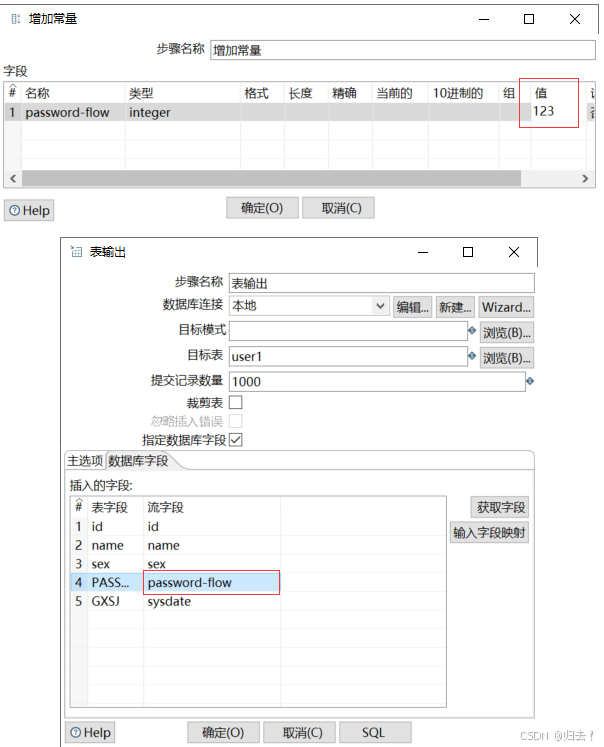
3)获取系统信息
给更新时间字段一个时间
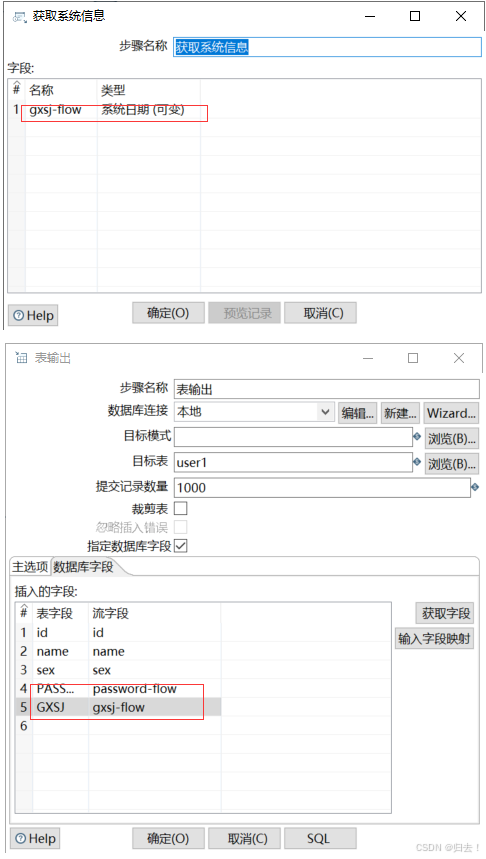
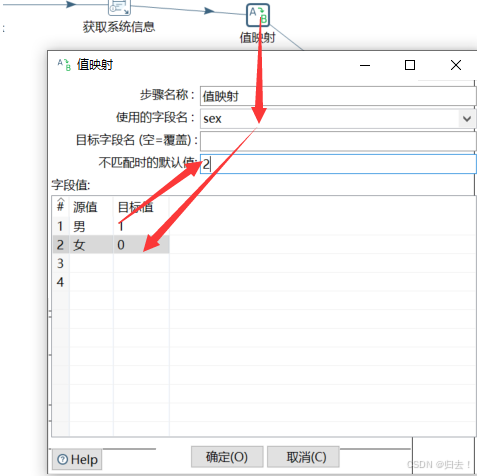
4)值映射
性别男和女分别对应1和0,不匹配时为2
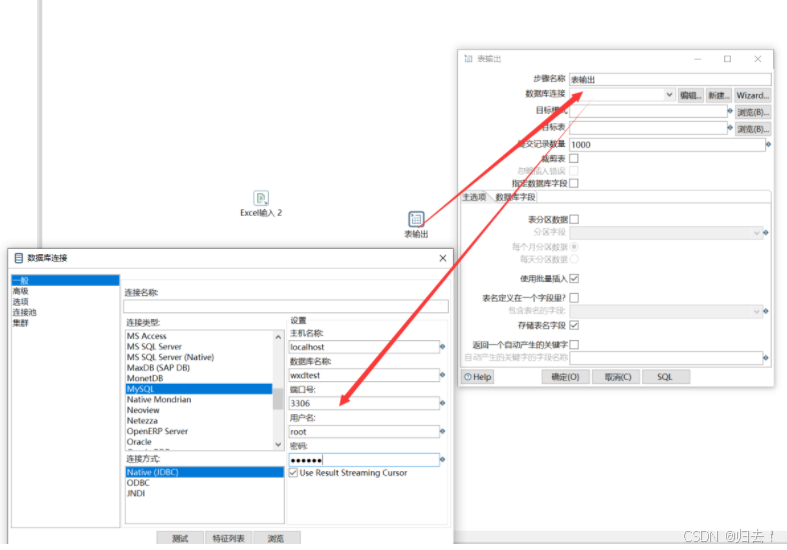
5)表输出
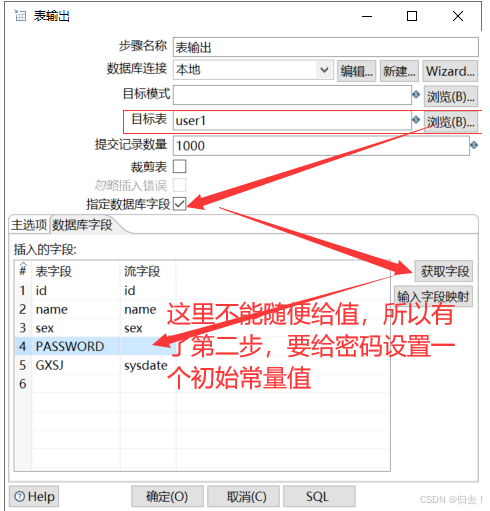
(3)table怎么导出txt或者excel
1)表输入
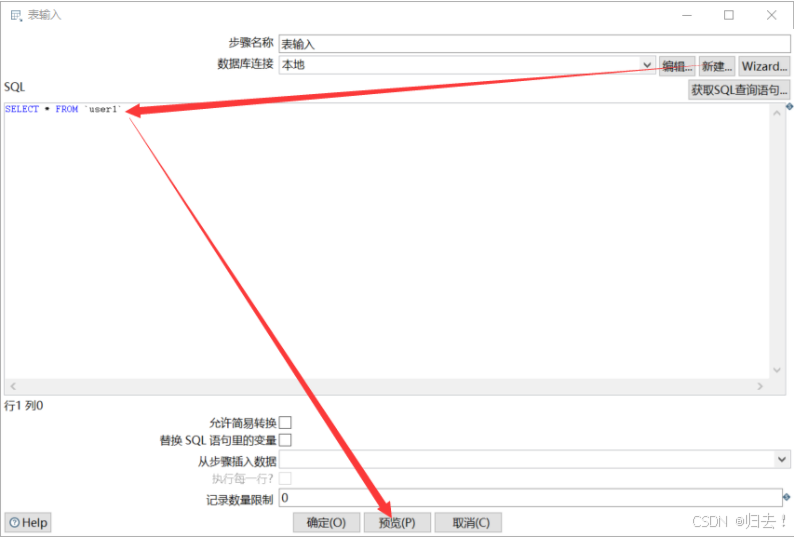
2)txt输出同上
去除两端空格
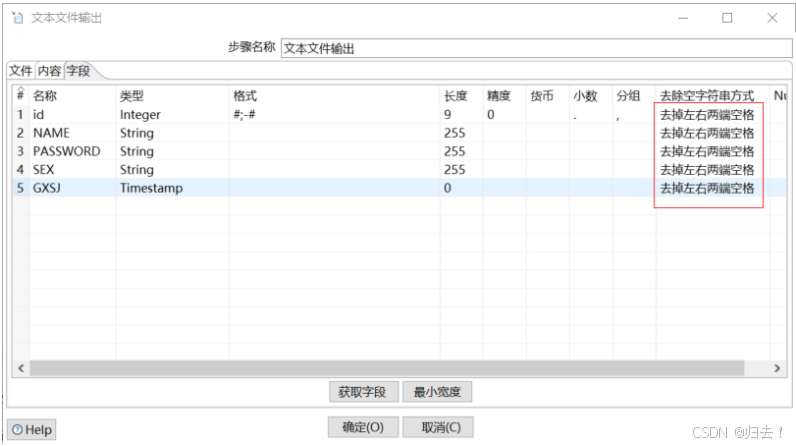
去除毫秒
3)字段选择
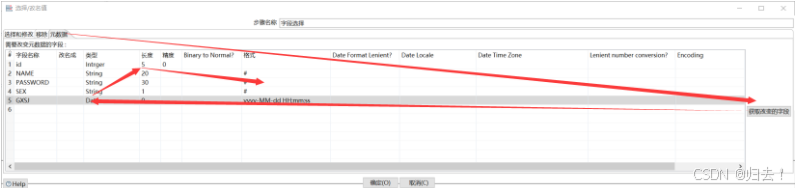
2、单表的导入导出、单表的全量同步和增量同步
需求描述:数据库的迁移或者是几张重要表的迁移A数据库要迁移数据到B数据库exp imp dmpKETTLE可以从A数据库迁移表到B数据
(1)全量迁移(视频Day2)
不常更新的表代码表,机构表,单表同步就可以实现
1)表输入同上
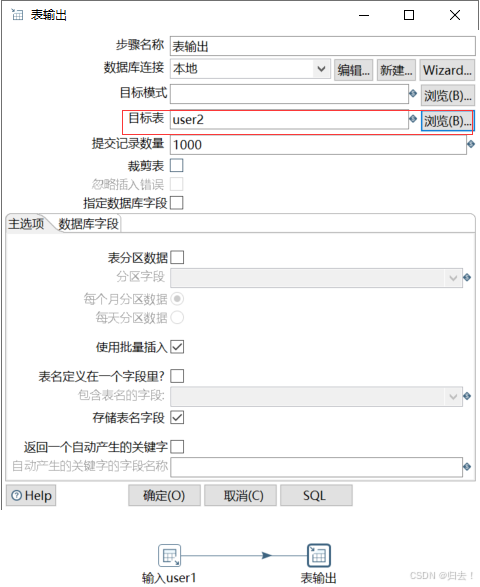
2)①表输出(第一种方式直接输出)(单表的导入导出)
2) ②插入\更新(第二种方式)
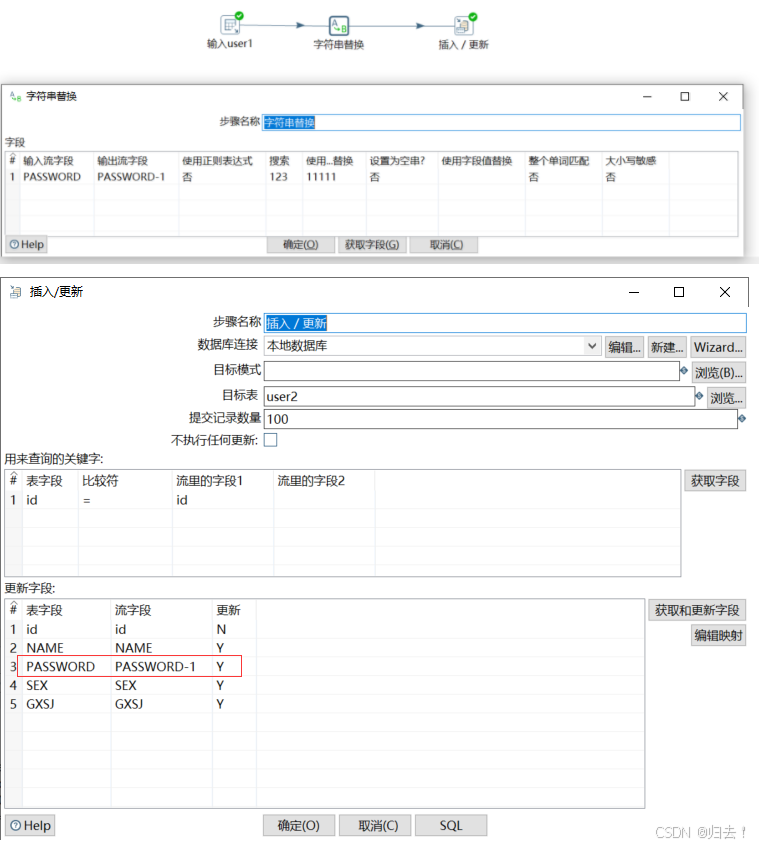
3)字符串替换
(2)增量迁移(视频Day3)
常更新的表:业务表、用户表,单表的增量同步可以实现
需求描述:单表的增量同步-时间戳1、 A数据库迁移到B数据库 A数据库不会停机2、 业务会根据B数据库的表来调整你的业务代码数据实时变化的
1)START
2)加入转换
①获取上一次同步时间

②同步本次增量数据
SQL:SELECT * FROM `user2‘ where gxsj>str_to_date('${TBSJ}','%Y-%m-%d %T')
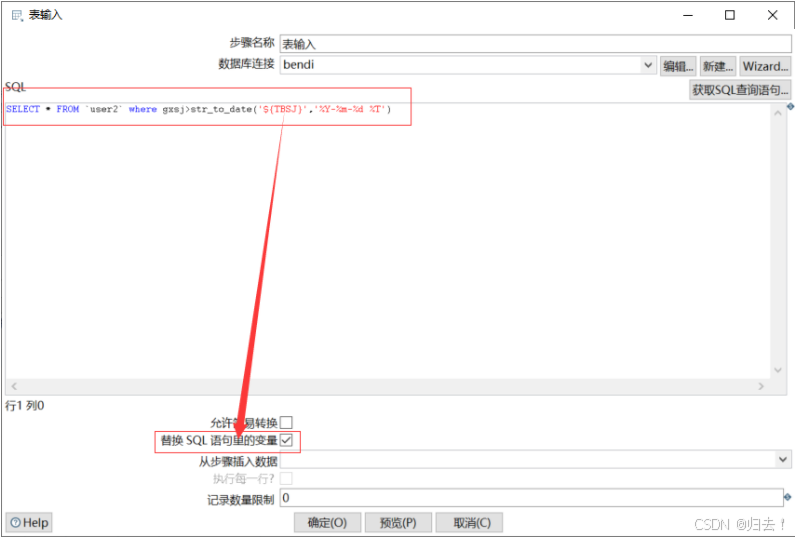
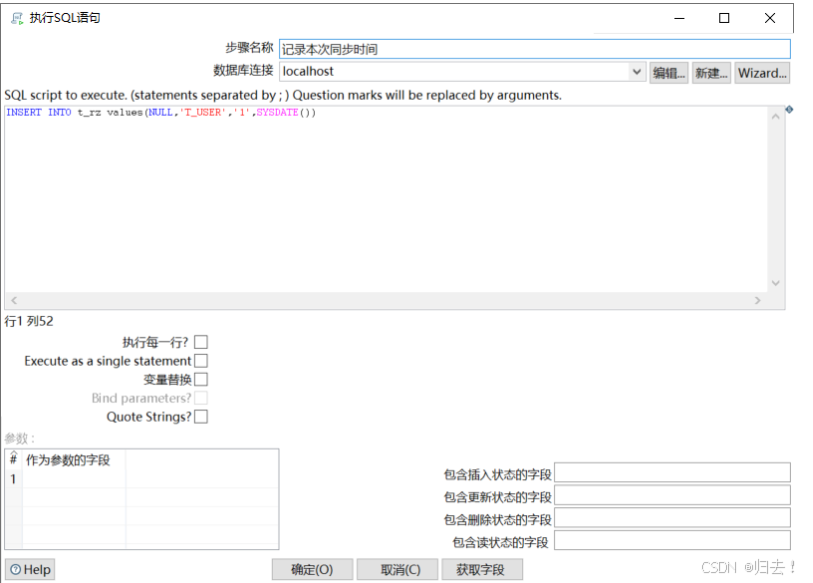
③记录本次同步时间
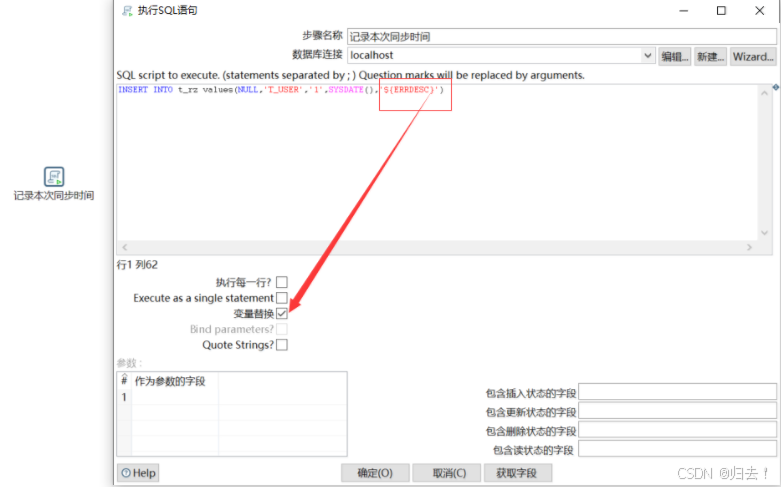
SQL:INSERT INTO t_rz values(NULL,'T_USER','1',SYSDATE())
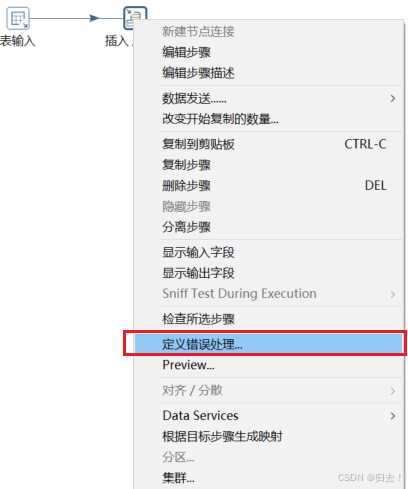
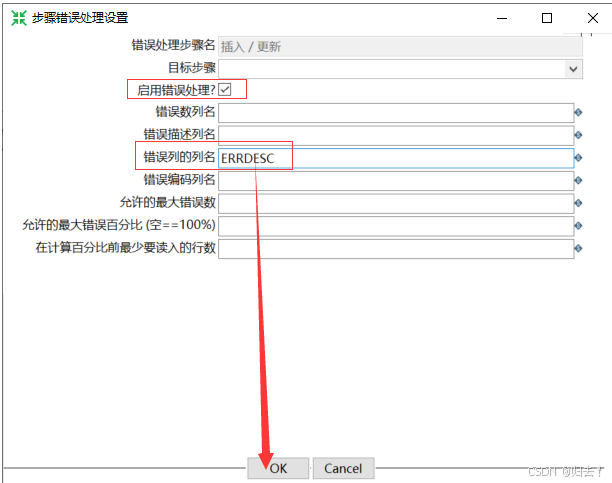
3、同步错误原因记录到日志表(视频Day4)
(1)定义错误处理
(2)添加样本行
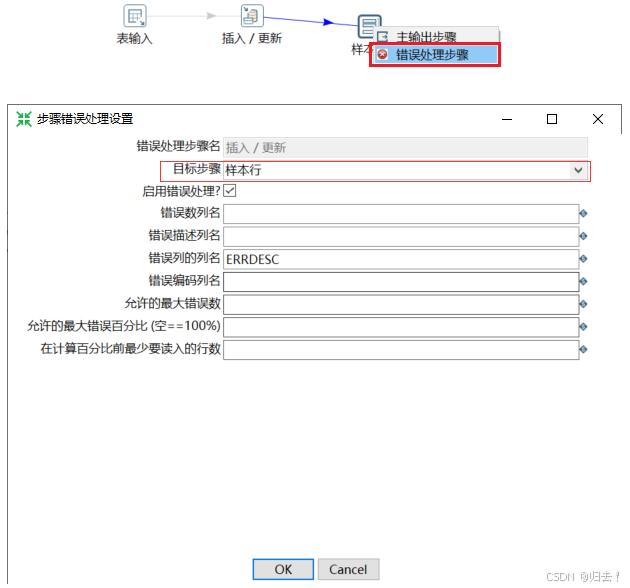
(3)添加字段选择
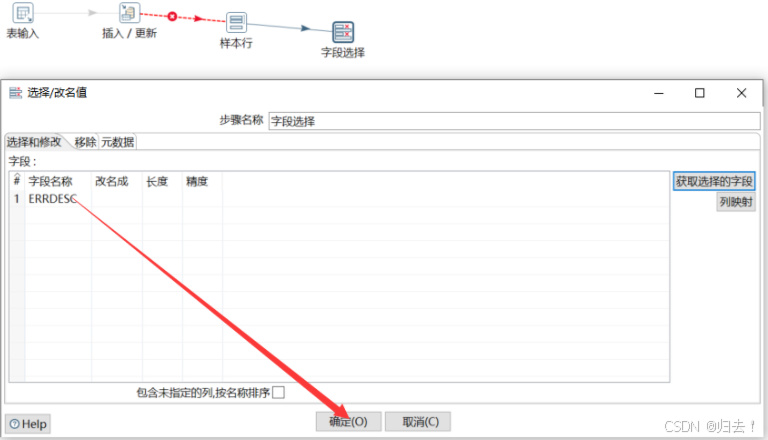
(4)设置变量
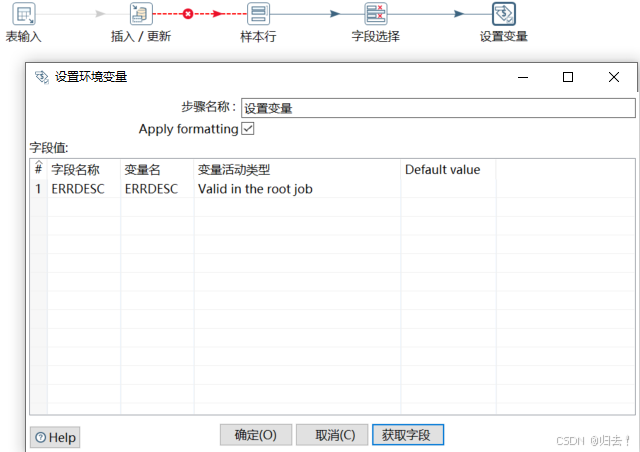
(5)修改第三步记录
(6)检验字段的值
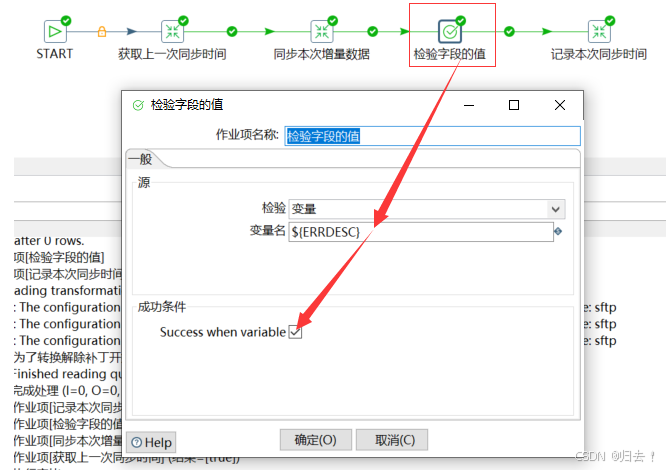
4、多个表融合到一个表(视频Day5)
需求描述:A数据库的A表,B表,C表融合到B数据库的ABC这张表
先建几张表
CREATE TABLE STUDENT
(SNO VARCHAR(3) NOT NULL,
SNAME VARCHAR(4) NOT NULL,
SSEX VARCHAR(2) NOT NULL,
SBIRTHDAY DATETIME,
CLASS VARCHAR(5))
CREATE TABLE COURSE
(CNO VARCHAR(5) NOT NULL,
CNAME VARCHAR(10) NOT NULL,
TNO VARCHAR(10) NOT NULL)
CREATE TABLE SCORE
(SNO VARCHAR(3) NOT NULL,
CNO VARCHAR(5) NOT NULL,
DEGREE NUMERIC(10, 1) NOT NULL)
CREATE TABLE TEACHER
(TNO VARCHAR(3) NOT NULL,
TNAME VARCHAR(4) NOT NULL, TSEX VARCHAR(2) NOT NULL,
TBIRTHDAY DATETIME NOT NULL, PROF VARCHAR(6),
DEPART VARCHAR(10) NOT NULL)
INSERT INTO STUDENT (SNO,SNAME,SSEX,SBIRTHDAY,CLASS) VALUES (108 ,'曾华'
,'男' ,'1977-09-01',95033);
INSERT INTO STUDENT (SNO,SNAME,SSEX,SBIRTHDAY,CLASS) VALUES (105 ,'匡明'
,'男' ,'1975-10-02',95031);
INSERT INTO STUDENT (SNO,SNAME,SSEX,SBIRTHDAY,CLASS) VALUES (107 ,'王丽'
,'女' ,'1976-01-23',95033);
INSERT INTO STUDENT (SNO,SNAME,SSEX,SBIRTHDAY,CLASS) VALUES (101 ,'李军'
,'男' ,'1976-02-20',95033);
INSERT INTO STUDENT (SNO,SNAME,SSEX,SBIRTHDAY,CLASS) VALUES (109 ,'王芳'
,'女' ,'1975-02-10',95031);
INSERT INTO STUDENT (SNO,SNAME,SSEX,SBIRTHDAY,CLASS) VALUES (103 ,'陆君'
,'男' ,'1974-06-03',95031);
INSERT INTO COURSE(CNO,CNAME,TNO)VALUES ('3-105' ,'计算机导论',825);
INSERT INTO COURSE(CNO,CNAME,TNO)VALUES ('3-245' ,'操作系统' ,804);
INSERT INTO COURSE(CNO,CNAME,TNO)VALUES ('6-166' ,'数据电路' ,856);
INSERT INTO COURSE(CNO,CNAME,TNO)VALUES ('9-888' ,'高等数学' ,100);
INSERT INTO SCORE(SNO,CNO,DEGREE)VALUES (103,'3-245',86);
INSERT INTO SCORE(SNO,CNO,DEGREE)VALUES (105,'3-245',75);
INSERT INTO SCORE(SNO,CNO,DEGREE)VALUES (109,'3-245',68);
INSERT INTO SCORE(SNO,CNO,DEGREE)VALUES (103,'3-105',92);
INSERT INTO SCORE(SNO,CNO,DEGREE)VALUES (105,'3-105',88);
INSERT INTO SCORE(SNO,CNO,DEGREE)VALUES (109,'3-105',76);
INSERT INTO SCORE(SNO,CNO,DEGREE)VALUES (101,'3-105',64);
INSERT INTO SCORE(SNO,CNO,DEGREE)VALUES (107,'3-105',91);
INSERT INTO SCORE(SNO,CNO,DEGREE)VALUES (108,'3-105',78);
INSERT INTO SCORE(SNO,CNO,DEGREE)VALUES (101,'6-166',85);
INSERT INTO SCORE(SNO,CNO,DEGREE)VALUES (107,'6-106',79);
INSERT INTO SCORE(SNO,CNO,DEGREE)VALUES (108,'6-166',81);
INSERT INTO TEACHER(TNO,TNAME,TSEX,TBIRTHDAY,PROF,DEPART)
VALUES (804,'李诚','男','1958-12-02','副教授','计算机系');
INSERT INTO TEACHER(TNO,TNAME,TSEX,TBIRTHDAY,PROF,DEPART)
VALUES (856,'张旭','男','1969-03-12','讲师','电子工程系');
INSERT INTO TEACHER(TNO,TNAME,TSEX,TBIRTHDAY,PROF,DEPART)
VALUES (825,'王萍','女','1972-05-05','助教','计算机系');
INSERT INTO TEACHER(TNO,TNAME,TSEX,TBIRTHDAY,PROF,DEPART)
VALUES (831,'刘冰','女','1977-08-14','助教','电子工程系');
select * from student
select * from course
select * from score
select * from teacher(1)表输入(获取源数据库的学生数据)
SQL:
select s.SNO,s.SNAME,s.SSEX,s.SBIRTHDAY,s.CLASS,d.CNO,d.DEGREE from student s,score d where s.SNO=d.SNO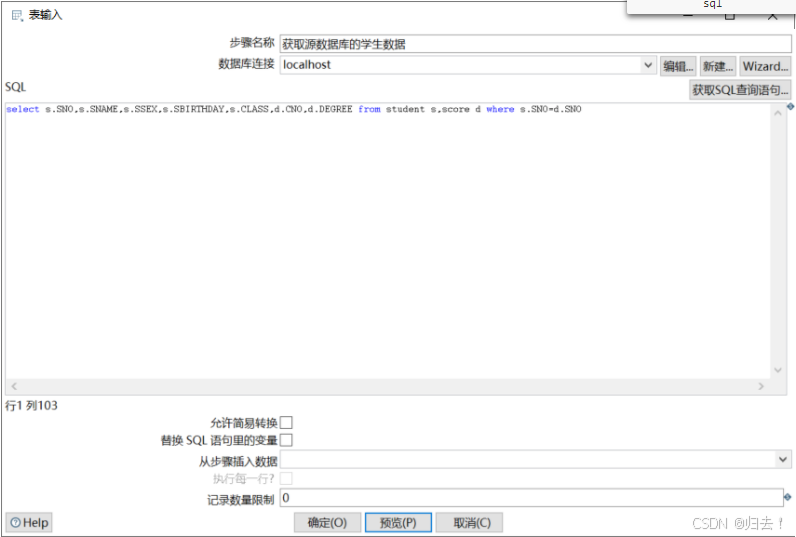
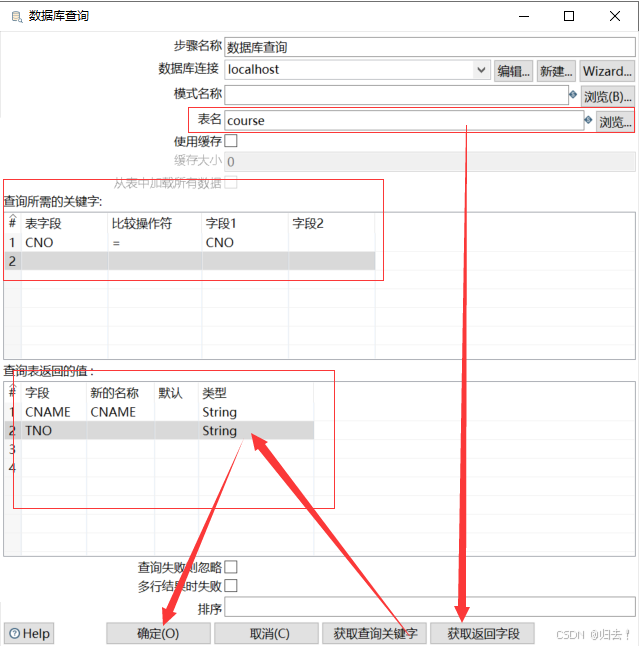
(2)数据库查询(获取课程)
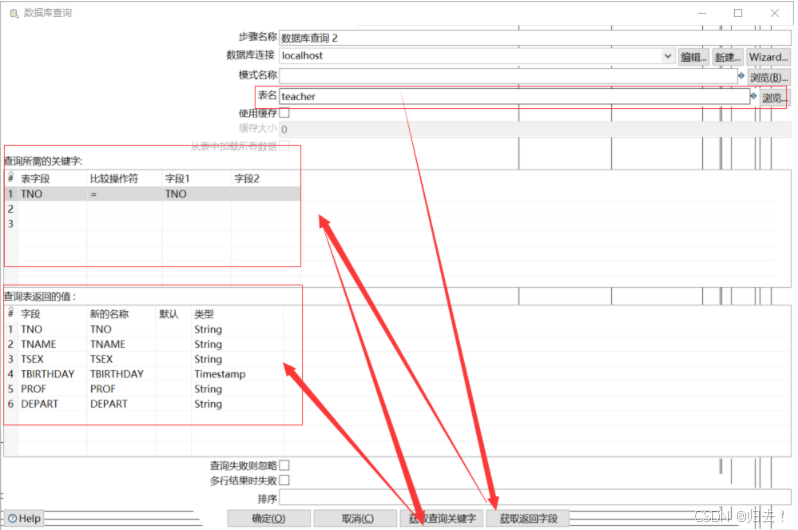
(3)数据库查询2(获取教师)
(4)增加序列
(5)插入更新
插入的表重新创建一个
5、比较不同的数据库-做差异化处理
需求描述:两个数据库去比较某一张表,然后将比对结果更新到目标表中去同数据库:
select * from tb_a
minus
select * from tb_b
insert into不同数据库:比较不同数据库的表A和表B,表B多出的数据存到表A
(1)表输入
两张表都输入
(2)记录集连接
(3)过滤记录
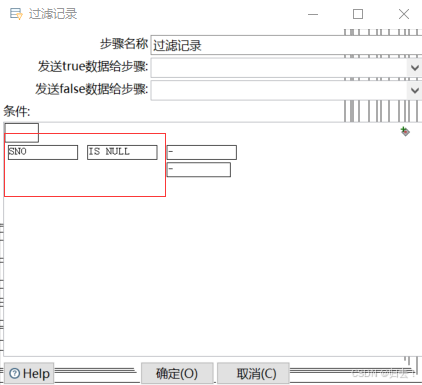
(4)过滤判断
①空操作(如果数据是空,就什么也不做)
②复制记录到结果
(5)表输出
6、整体数据库迁移(表全量和表增量)(第七讲以后听)
需求描述:全数据库做迁移,A数据库的所有表全部迁移到B数据库1、oracle imp和exp --要停应用dmp2、KETTLE全量表迁移 --也要停应用 user表这种不常做改变的表3、增量表迁移--不需要停应用
8、通过配置文件做表的全量同步
9、通过配置文件做表的增量同步
11、windows和linux下的作业调度
六、应用部署及运行方式
使用java web start方式运行的配置方法命令行方式:1) Windows下执行kitchen.bat,多个参数之间以"/"分隔,Key和value以" :"分隔。例如 : kitchen.bat/file:F:\samples\demo-table2table.ktr /level:Basic/log:test123.log (/file: 指定转换文件的路径/level: 执行日志执行级别/log:执行日志文件路径)2) Linux 下执行kitchen.sh,多个参数之间以“-" 分隔,Key 和value以”=”分隔。例如: kitchen.sh -file=/home/updateWarehouse.kjb -level=Minimal3)如果设计的转换, Job是保存在数据库中,则命令如下: Kitchen.bat /rep:资源库名称/user:admin /pass:admin /job:job名
七、常见问题及解答
1.在ETL任务中由于数据问题出现转换错误
在ETL任务中由于数据问题出现转换错误是一件非常正常的事情,你不应该设计一个依赖于临时表或者拥有事务特点的ETL过程,面对数据源质量问题的巨大挑战,错误处理是并不可少的,kettle 同样提供非常方便的错误处理方式,在你可能会出错的步骤点击右键选择Define Error handing,它会要求你指定一个处理 error的步骤,你可以使用文本文件或者数据库的表来储存这些错误信息,这些错误信息会包含一个id和一个出错的字段,当你得到这些错误信息之后就需要你自己分析出错的原因了,比如违反主键约束可能是你生成主键的方式有错误或者本身的数据有重复,而违反外键约束则可能是你依赖的一些表里面的数据还没有转换或者外键表本身过滤掉了这些数据.当你调整了这些错误之后,确定所有依赖的数据都被正确的处理了.kettle user guide里面有更详细的解释,里面还附带了一个使用javascript来处理错误的示例,这种方式可以作为处理简单数据质量的方式。
2.ETL 转换出现不可预知的问题
当ETL 转换出现不可预知的问题时,或是你不清楚某个步骤的功能是什么的情况下,你可能需要创建一个模拟环境来调适程序,下面一些建议可能会有所帮助:尽量使用generate row步骤或者固定的一个文本文件来创建一个模拟的数据源.模拟的数据源一定要有代表性,数据集一定尽量小(为了性能考虑)但是数据本身要足够分散.创建了模拟的数据集后你应该清楚的知道你所要转换之后的数据时什么样的。
3.数据复制或者一个备份数据库以及数据库私有
有的时候可能我们需要的是类似数据复制或者一个备份数据库,这个时候你需要的是一种数据库私有的解决方案, Kettle也许并不是你的第一选择, 比如对于Oracle来说,可能rman , oracle stream , oracle replication等等,mysql 也有mysql rmaster /slave模式的replication等私有的解决方法,如果你确定你的需求不是数据集成这方面的,那么也许kettle并不是一个很好的首选方案,你应该咨询一下专业的DBA人士也会会更好
4.数据库连接、连接参数以及连接池
在你创建一个数据库连接的时候除了可以指定你一次需要初始化的连接池参数之外(在Pooling选项卡下面) ,还包括一个Options选项卡和一个SQL选项卡,Options选项卡里面主要设置一些连接时的参数,比如autocommit是on还是off,defaultFetchSize,useCursorFetch (mysql 默认支持的),oracle 还支持比如defaultExecuteBatchoracle.jdbc.StreamBufferSize,oracle.jdbc.FreeMemoryOnEnterlmplicitCache ,你可以查阅对应数据库所支持的连接参数,另外-一个小提示:在创建数据库连接的时候,选择你的数据库类型,然后选到Options选项卡,下面有一个Show help text on options usage,点击这个按钮会把你带到对应各个数据库的连接参数的官方的一个参数列表页面,通过查询这个列表页面你就可以知道那种数据库可以使用何种参数了.对于SQL选项卡就是在你一连接这个Connection之后, Kettle会立刻执行的sq|语句,个人比较推荐的一个sq|是执行把所有日期格式统一成同一 格式的sql,比如在oracle 里面就是: alter session setnls_ date_ format = xxxxxxXXxx; alter session set nls_ xxXxXXXx = xXXXXXXXXXX这样可以避免你在转换的时候大量使用to date() , to _char函数而仅仅只是为了统一日期格式,对于增量更新的时候尤其适用
5.字符集问题
Kettle使用Java通常使用的UTF8来传输字符集,所以无论你使用何种数据库,任何数据库种类的字符集,kettle 都是支持的,如果你遇到了字符集问题,也许下面这些提示可以帮助你:
1.单数据库到单数据库是绝对不会出现乱码问题的,不管原数据库和目标数据库是何种种类,何种字符集 2.多种不同字符集的原数据库到一 个目标数据库,你首先需要确定多种源数据库的字符集的最大兼容字符集是什么,如果你不清楚,最好的办法就是使用UTF8来创建数据库. 3.不要以你工作的环境来判断字符集 :现在某一个测试人 员手上有-个oracle 的基于xxx字符集的已经存在的数据库,并且非常不幸的是xXx字符集不是utf8类型的,于是他把另一个基于yy字符集的oracle数据库要经过某一个 ETL过程转换到oracle,后来他发现无论怎么样设置都会出现乱码,这是因为你的数据库本身的字符集不支持,无论你怎么设置都是没用的.测试的数据库不代表最后产品运行的数据库,尤其是有时候为了省事把多个不同的项目的不相关的数据库装在同一台机器上,测试的时候又没有分析清楚这种环境,所以也再次强调描述物理环境的重要性. 4.你所看到的不一 定代表实际储存的: mysq|处理字符集的时候是要在jdbc连接的参数里面加上字符集参数的,而oracle则是需要服务器端和客户端使用同一种字符集才能正确显示,所以你要明确你所看到的字符集乱码不- -定代表真的就是字符集乱码,这需要你检查在转换之前的字符集是否会出现乱码和转换之后是否出现乱码,你的桌面环境可能需要变动一些参数来适应这种变动 5.不要在一个转换中使用多个字符集做为数据源
6.数据库连接池
Kettle的数据库连接是一个步骤里面控制一一个单数据库连接,所以kettle的连接有数据库连接池,你可以在指定的数据库连接里面指定-开始连接池里面放多少个数据库连接,在创建数据库连接的时候就有Pooling 选项卡,里面可以指定最大连接数和初始连接数,这可以一定程度上提高速度
7.类似事务性问题
在步骤A执行一个操作(更新或者插入) ,然后在经过若干个步骤之后,如果我发现某一个条件成立,我就提交所有的操作,如果失败,我就回滚,kettle 提供这种事务性的操作吗? Kettle 里面是没有所谓事务的概念的,每个步骤都是自己管理自己的连接的,在这个步骤开始的时候打开数据库连接,在结束的时候关闭数据库连接,一个步骤是肯定不会跨session的(数据库里面的session),另外,由于kettle是并行执行的,所以不可能把一个数据库连接打开很长时间不放,这样可能会造成锁出现,虽然不一定是死锁,但是对性能还是影响太大了。ETL中的事务对性能影响也很大,所以不应该设计一种依赖与事务方式的ETL执行顺序,毕竟这不是OLTP,因为你可能一次需要提交的数据量是几百GB都有可能,任何一种数据库维持一个几百 GB的回滚段性能都是会不大幅下降的
8.更新数据问题
执行update table操作是比较慢的,它会一条一条基于compare key对比数据,然后决定是不是要执行updatesql,如果你知道你要怎么更新数据尽可能的使用execute sql script操作,在里面手写update sql (注意源数据库和目标数据库在哪),这种多行执行方式(update sql)肯定比单行执行方式(update table操作)快的多。另一个区别是execute sql script操作是可以接受参数的输入的。它前面可以是一个跟它完全不关的表一个sql: select field1, field2 field3 from tableA后面执行另一个表的更新操作: update tableB set field4 = ? where field5=? And field6=?然后选中execute sql script 的execute for each row .注意参数是一一对应的.(field4 对应field1的值,field5 对应field2的值,field6 对应field3的值)
9.一些注意事项
1.尽量使用数据库连接池2.尽量提高批处理的commit size3.尽量使用缓存,缓存尽量大一些(主要是文本文件和数据流)4.Kettle是Java做的,尽量用大一点的内存参数启动Kettle.5.可以使用sq|来做的一些操作尽量用sql。Group , merge , stream lookup ,split field这些操作都是比较慢的,想办法避免他们6.插入大量数据的时候尽量把索引删掉7.尽量避免使用update,delete 操作,尤其是update,如果可以把update变成先delete,后insert。能使用truncate table的时候,就不要使用delete all row这种类似sql8.合理的分区。如果删除操作是基于某一个分区的, 就不要使用delete row这种方式(不管是delete sql还是delete步骤) ,直接把分区drop掉,再重新创建9.尽量缩小输入的数据集的大小(增量更新也是为了这个目的)尽量使用数据库原生的方式装载文本文件(Oracle的sql loader , mysq|的bulk loader步骤)10.尽量不要用kettle的calculate计算步骤,能用数据库本身的sql就用sql ,不能用sql就尽量想办法用procedure,实在不行才是calculate步骤。要知道你的性能瓶颈在哪,可能有时候你使用了不恰当的方式,导致整个操作都变慢,观察kettle log生成的方式来了解你的ETL操作最慢的地方。11.远程数据库用文件+FTP的方式来传数据,文件要压缩12.源数据库的操作系统,硬件环境,是单数据源还是多数据源,数据库怎么分布的,做ETL的那台机器放在哪,操作系统和硬件环境是什么,目标数据仓库的数据库是什么,操作系统,硬件环境,数据库的字符集怎么选,数据传输方式是什么,开发环境,测试环境和实际的生产环境有什么区别,是不是需要一个中间数据库(staging 数据库) ,源数据库的数据库版本号是多少,测试数据库的版本号是多少,真正的目标数据库的版本号是多少.....这些信息也许很零散,但是都需要一份专门的文档来描述这些信息,无论是你遇到问题需要别人帮助的时候描述问题本身,还是发现测试环境跟目标数据库的版本号不一致,这份专门的文档都能提供一些基本的信息13.触发procedure 和http client 都需要一个 类似与触发器的条件,你可以使用generate row步骤产生一个空的row然后把这条记录连上procedure步骤,这样就会使这条没有记录的空行触发这个procedure (如果你打算使用无条件的单次触发) ,当然procedure也可以象table input里面的步骤那样传参数并且多次执行另外一个建议是不要使用复杂的procedure来完成本该ETL任务完成的任务,比如创建表,填充数据,创建物化视图等等
八、总结
1.Kettle的功能非常强大,数据抽取率也比较高,开源产品,可以进行第三方修改,項中的控件能够实现数据抽取的大部分需求2.所有功能支持控件化,使用简单3.Kettle目前还不是特别稳定,并且发现的bug也比较多4.执行效率和复杂度删除和更新都是一 项比较耗 费时间的操作,它们都需要不断的在数据库中查询记录,执行删除操作或更新操作,而且都是一条- 条的执行,执行效率低下也是可以预见的,尽量可能的缩小原数据集大小。减少传输的数据集大小,降低ETL的复杂程度5.时间戳方法的- -些优点和缺点优点: 实现方式简单, 很容易就跨数据库实现了,运行起来也容易设计缺点:浪 费大量的储存空间,时间戳字段除ETL过程之外都不被使用,如果是定时运行的,某一次运行失败了,就有可能造成数据有部分丢失
九、SPOON操作指南+参考文献
spoon新手入门教程spoon用法wuzhangweiss的博客-优快云博客
微信公众号:JAVA大师 kettle教程系列


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











