







本篇笔记百分之90以上是该课程ppt的内容,我只是通过查询在不理解的地方进行标注。
目录
文件上传
问题
1
:如何限定请求方式是
POST?
@PostMapping
问题
2
:怎么在
controller
中接收
json
格式的请求参数?
@RequestBody
//
把前端传递的
json
数据填充到实体类中
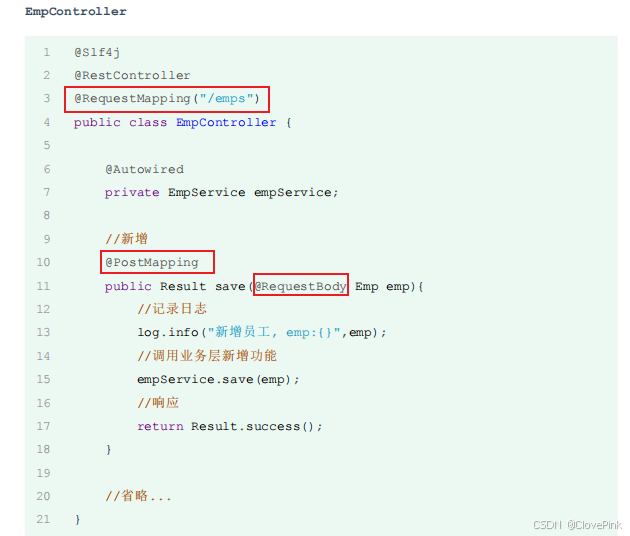
上传文件的原始
form
表单,要求表单必须具备以下三点(上传文件页面三要素):
表单必须有file
域,用于选择要上传的文件
<input
type
=
"file"
name
=
"image"
/>
表单提交方式必须为POST
通常上传的文件会比较大,所以需要使用 POST
提交方式
表单的编码类型enctype
必须要设置为:
multipart/form-data
普通默认的编码格式是不适合传输大型的二进制数据的,所以在文件上传时,表单的编码格
式必须设置为
multipart/form-data
Spring
中提供了一个
API
:
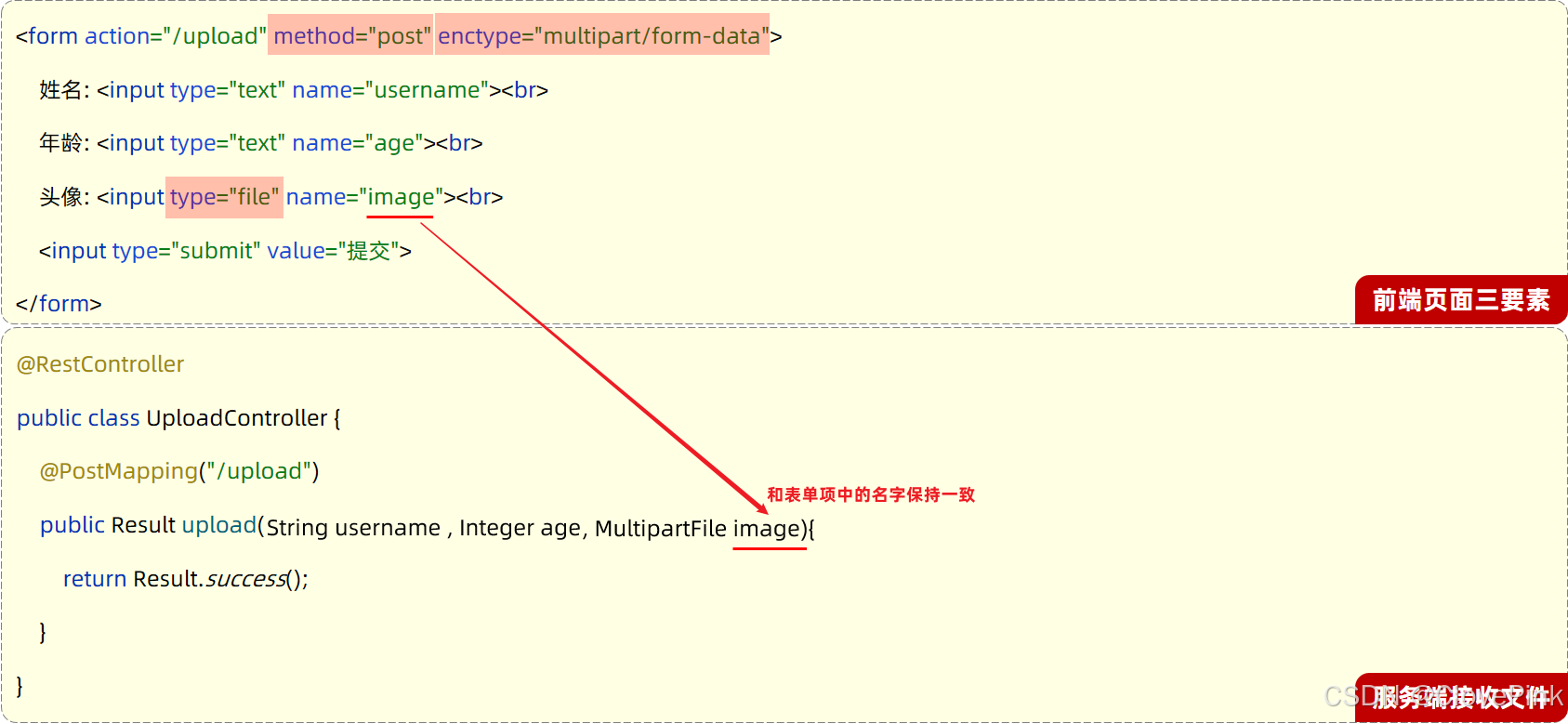
MultipartFile
,使用这个
API
就可以来接收到上传的文件
本地存储

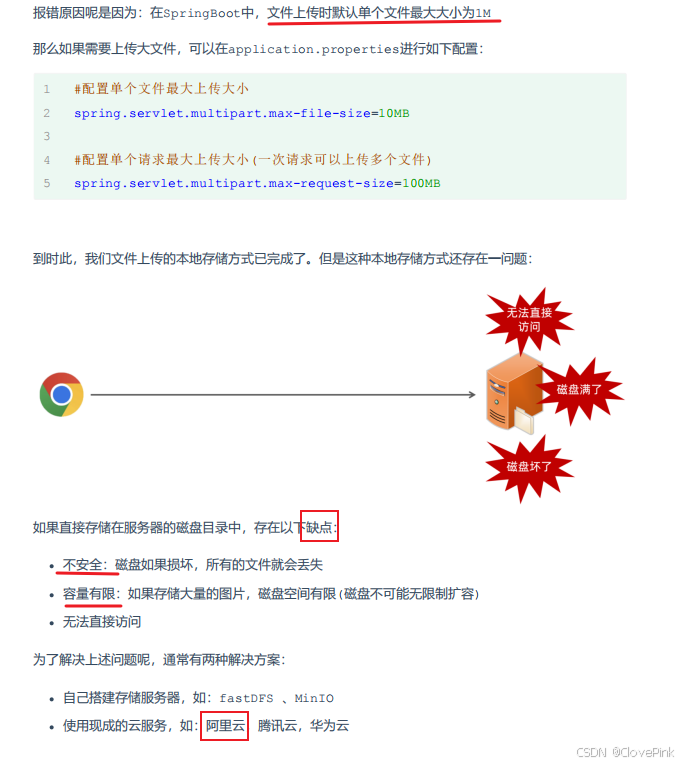
阿里云OSS

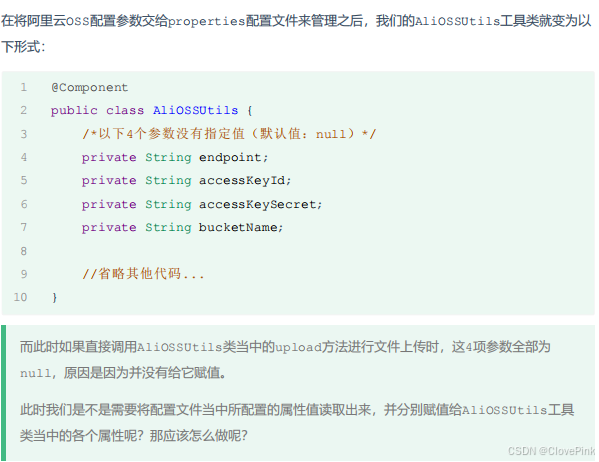

yml配置文件

我们可以看到配置同样的数据信息,
yml
格式的数据有以下特点:
容易阅读
容易与脚本语言交互
以数据为核心,重数据轻格式
了解下
yml
配置文件的基本语法:
大小写敏感
使用缩进表示层级关系,缩进时,不允许使用Tab
键,只能用空格(
idea
中会自动将
Tab
转换为空格)
缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
#
表示注释,从这个字符一直到行尾,都会被解析器忽略

了解完
yml
格式配置文件的基本语法之后,接下来我们再来看下
yml
文件中常见的数据格式。在这里我们主要介绍最为常见的两类:
1.
定义对象或
Map
集合
2.
定义数组、
list
或
set集合
@ConfigurationProperties
讲解完了
yml
配置文件之后,最后再来介绍一个注解
@ConfigurationProperties
。在介绍注解之
前,我们先来看一个场景,分析下代码当中可能存在的问题:
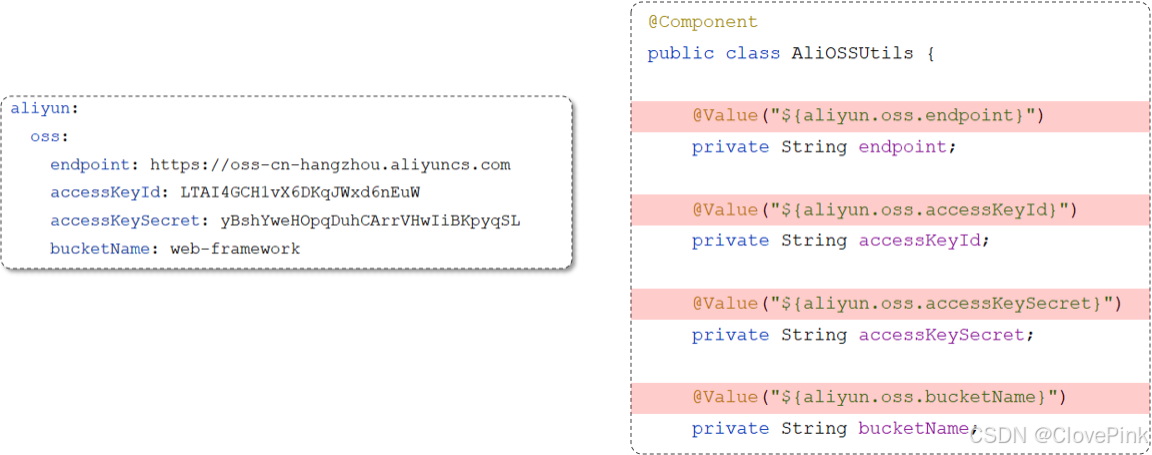
我们在
application.properties
或者
application.yml
中配置了阿里云
OSS
的四项参数之后,如果java
程序中需要这四项参数数据,我们直接通过
@Value
注解来进行注入。这种方式本身没有什么问题问题,但是如果说需要注入的属性较多(
例:需要
20
多个参数数据
)
,我们写起来就会比较繁琐。
那么有没有一种方式可以简化这些配置参数的注入呢?答案是肯定有,在
Spring
中给我们提供了一种简化方式,可以直接将配置文件中配置项的值自动的注入到对象的属性中。
Spring
提供的简化方式套路:
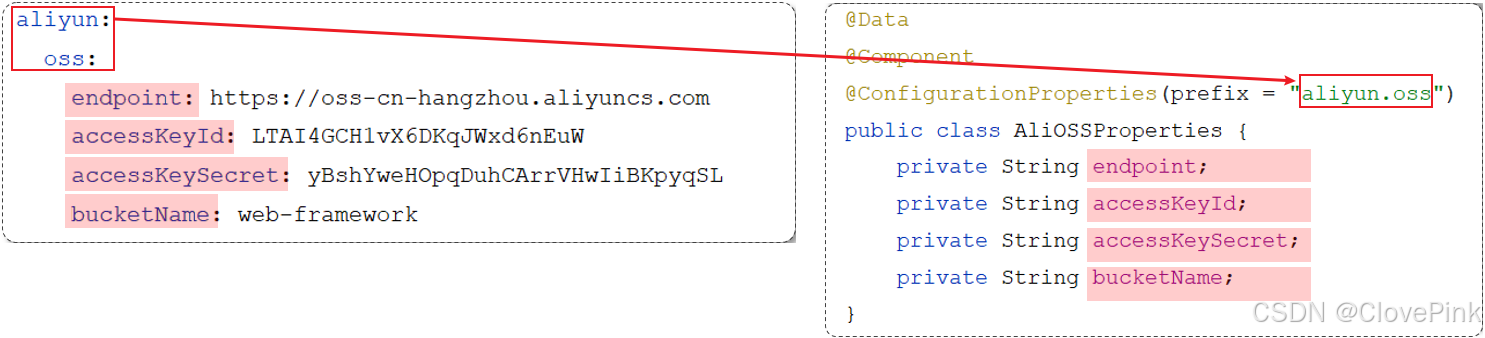
1.
需要创建一个实现类,且实体类中的属性名和配置文件当中
key
的名字必须要一致
比如:配置文件当中叫endpoints
,实体类当中的属性也得叫
endpoints
,另外实体类当
中的属性还需要提供 getter / setter
方法
2.
需要将实体类交给
Spring
的
IOC
容器管理,成为
IOC
容器当中的
bean
对象
3.
在实体类上添加
@ConfigurationProperties
注解,并通过
perfect
属性来指定配置参数项的
前缀



登录校验
什么是登录校验?
所谓登录校验,指的是我们在服务器端接收到浏览器发送过来的请求之后,首先我们要对请求进行
校验。先要校验一下用户登录了没有,如果用户已经登录了,就直接执行对应的业务操作就可以
了;如果用户没有登录,此时就不允许他执行相关的业务操作,直接给前端响应一个错误的结果,
最终跳转到登录页面,要求他登录成功之后,再来访问对应的数据。
首先我们在宏观上先有一个认知:
前面在讲解
HTTP
协议的时候,我们提到
HTTP
协议是无状态协议。什么又是无状态的协议?
所谓无状态,指的是每一次请求都是独立的,下一次请求并不会携带上一次请求的数据。而浏览器与服务器之间进行交互,基于HTTP
协议也就意味着现在我们通过浏览器来访问了登陆这个接口,实现了登陆 的操作,接下来我们在执行其他业务操作时,服务器也并不知道这个员工到底登陆了没有。因为HTTP
协 议是无状态的,两次请求之间是独立的,所以是无法判断这个员工到底登陆了没有。
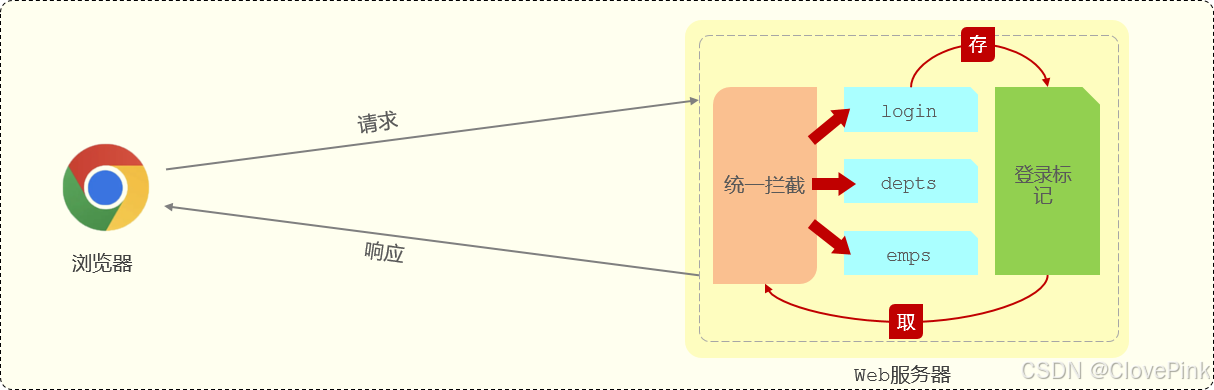
那应该怎么来实现登录校验的操作呢?具体的实现思路可以分为两部分:
-
在员工登录成功后,需要将用户登录成功的信息存起来,记录用户已经登录成功的标记。
-
在浏览器发起请求时,需要在服务端进行统一拦截,拦截后进行登录校验。
想要判断员工是否已经登录,我们需要在员工登录成功之后,存储一个登录成功的标记,接下来在
每一个接口方法执行之前,先做一个条件判断,判断一下这个员工到底登录了没有。如果是登录
了,就可以执行正常的业务操作,如果没有登录,会直接给前端返回一个错误的信息,前端拿到这
个错误信息之后会自动的跳转到登录页面。
我们程序中所开发的查询功能、删除功能、添加功能、修改功能,都需要使用以上套路进行登录校
验。此时就会出现:相同代码逻辑,每个功能都需要编写,就会造成代码非常繁琐。
为了简化这块操作,我们可以使用一种技术:统一拦截技术。
通过统一拦截的技术,我们可以来拦截浏览器发送过来的所有的请求,拦截到这个请求之后,就可
以通过请求来获取之前所存入的登录标记,在获取到登录标记且标记为登录成功,就说明员工已经
登录了。如果已经登录,我们就直接放行
(
意思就是可以访问正常的业务接口了
)
。
我们要完成以上操作,会涉及到
web
开发中的两个技术:
1.
会话技术
2.
统一拦截技术
而统一拦截技术现实方案也有两种:
1. Servlet
规范中的
Filter
过滤器
2. Spring
提供的
interceptor
拦截器
下面我们先学习会话技术,然后再学习统一拦截技术。
什么是会话?
指的就是浏览器与服务器之间的一次连接,我们就称为一次会话。
在用户打开浏览器第一次访问服务器的时候,这个会话就建立了,直到有任何一方断开连接,此时会话就结束了。在一次会话当中,是可以包含多次请求和响应的。
比如:打开了浏览器来访问
web
服务器上的资源(浏览器不能关闭、服务器不能断开)
第
1
次:访问的是登录的接口,完成登录操作
第
2
次:访问的是部门管理接口,查询所有部门数据
第
3
次:访问的是员工管理接口,查询员工数据
只要浏览器和服务器都没有关闭,以上
3
次请求都属于一次会话当中完成的。
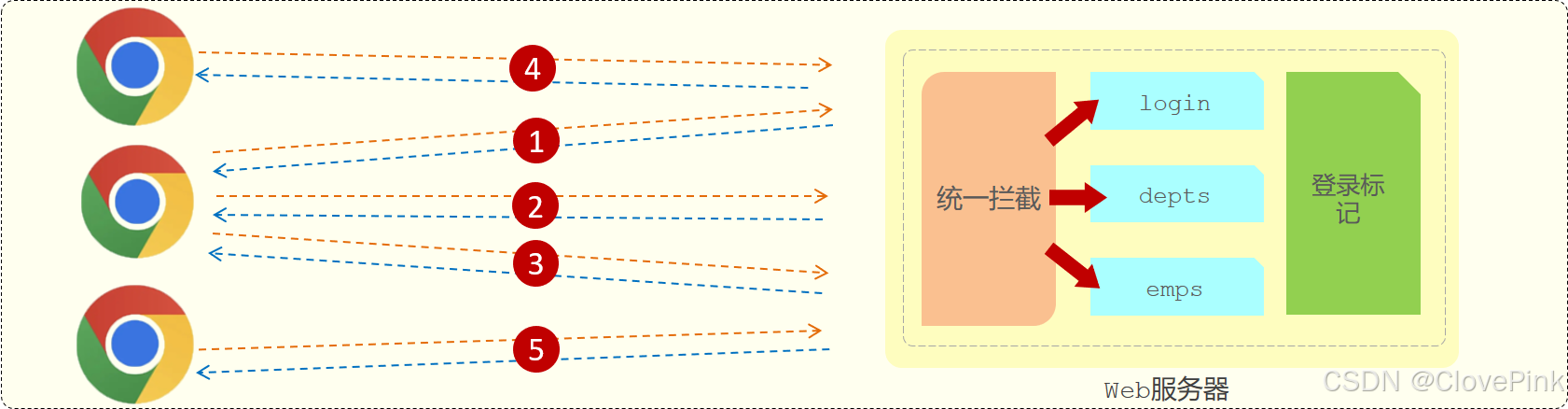
需要注意的是:会话是和浏览器关联的,当有三个浏览器客户端和服务器建立了连接时,就会有三个会话。同一个浏览器在未关闭之前请求了多次服务器,这多次请求是属于同一个会话。比如:1
、
2
、
3
这三个请求都是属于同一个会话。当我们关闭浏览器之后,这次会话就结束了。而如果我们是直接把web 服务器关了,那么所有的会话就都结束了。
会话跟踪:一种维护浏览器状态的方法,服务器需要识别多次请求是否来自于同一浏览器,以便在同一次会话的多次请求间共享数据。
为什么要共享数据呢?
由于
HTTP
是无状态协议,在后面请求中怎么拿到前一次请求生成的数据呢?此时就需要在一次会
话的多次请求之间进行数据共享
会话跟踪技术有两种:
1. Cookie
(客户端会话跟踪技术)
数据存储在客户端浏览器当中
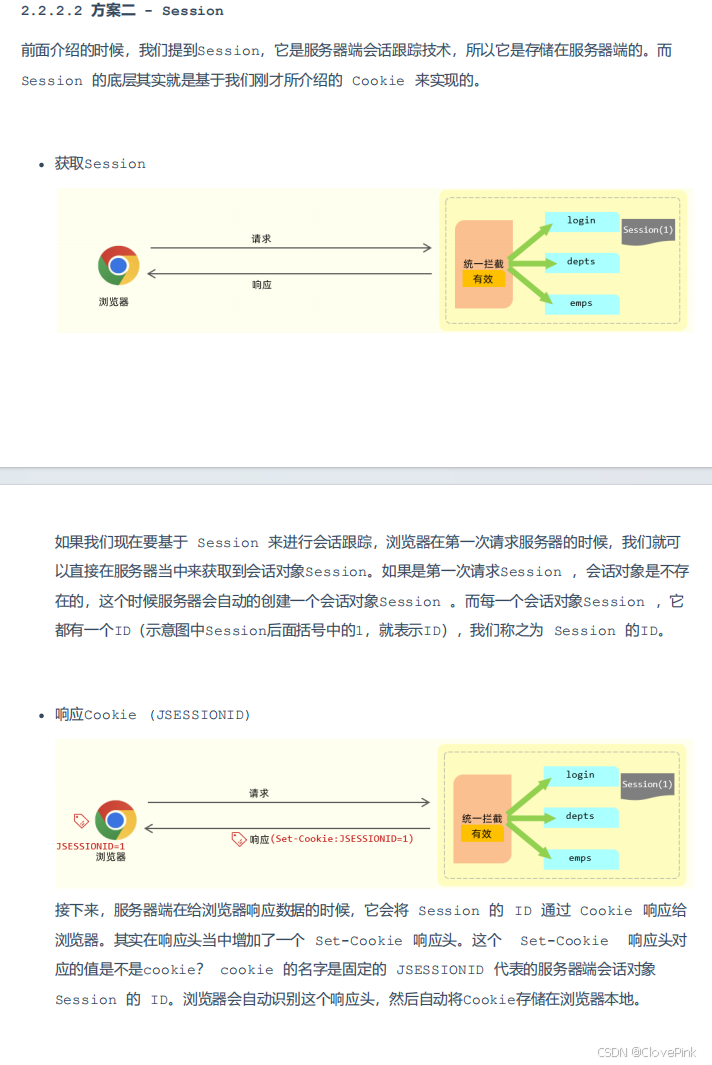
2. Session
(服务端会话跟踪技术)
数据存储在储在服务端
3.
令牌技术


优缺点
优点:
HTTP
协议中支持的技术(像
Set-Cookie
响应头的解析以及
Cookie
请求头数据的携带,都是浏览器自动进行的,是无需我们手动操作的)
缺点:
移动端APP(Android
、
IOS)
中无法使用
Cookie
不安全,用户可以自己禁用Cookie
Cookie不能跨域
区分跨域的维度:
协议
IP/协议
端口

优缺点
优点:
Session
是存储在服务端的,安全
缺点:
服务器集群环境下无法直接使用Session
移动端APP(Android
、
IOS)
中无法使用
Cookie
用户可以自己禁用Cookie
Cookie不能跨域
PS
:
Session 底层是基于Cookie实现的会话跟踪,如果Cookie不可用,则该方案,也就失效
了。
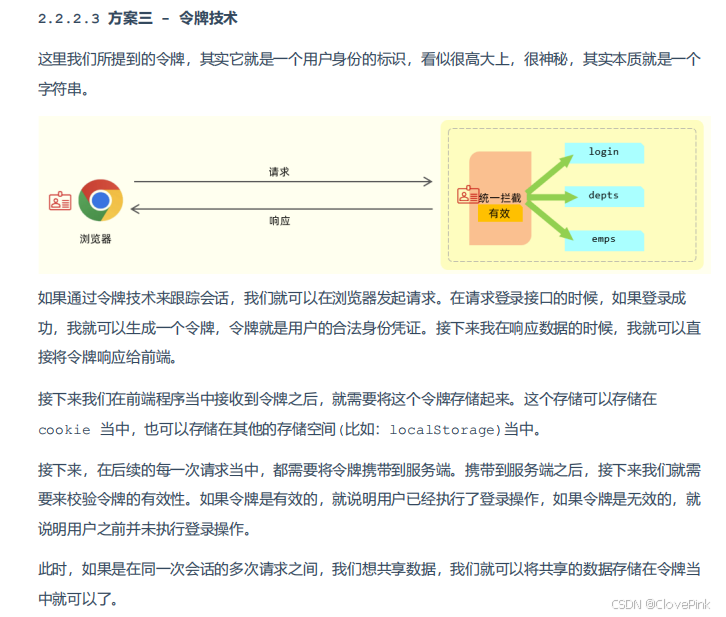
优缺点
优点:
支持PC
端、移动端
解决集群环境下的认证问题
减轻服务器的存储压力(无需在服务器端存储)
缺点:需要自己实现(包括令牌的生成、令牌的传递、令牌的校验)
JWT令牌
JWT
全称:
JSON Web Token
定义了一种简洁的、自包含的格式,用于在通信双方以
json
数据格式安全的传输信息。由于数字
签名的存在,这些信息是可靠的。
简洁:是指
jwt
就是一个简单的字符串。可以在请求参数或者是请求头当中直接传递。
自包含:指的是
jwt
令牌,看似是一个随机的字符串,但是我们是可以根据自身的需求在
jwt
令牌中存储自定义的数据内容。如:可以直接在
jwt
令牌中存储用户的相关信息。
简单来讲,
jwt
就是将原始的
json
数据格式进行了安全的封装,这样就可以直接基于
jwt
在
通信双方安全的进行信息传输了。
JWT
的组成: (
JWT
令牌由三个部分组成,三个部分之间使用英文的点来分割)
第一部分:
Header(
头), 记录令牌类型、签名算法等。 例如:
{"alg":"HS256","type":"JWT"}
第二部分:
Payload(
有效载荷),携带一些自定义信息、默认信息等。 例如:
{"id":"1","username":"Tom"}
第三部分:
Signature(
签名),防止
Token
被篡改、确保安全性。将
header
、
payload
,并加
入指定秘钥,通过指定签名算法计算而来。
签名的目的就是为了防
jwt
令牌被篡改,而正是因为
jwt
令牌最后一个部分数字签名的存在,
所以整个
jwt
令牌是非常安全可靠的。一旦
jwt
令牌当中任何一个部分、任何一个字符被篡
改了,整个令牌在校验的时候都会失败,所以它是非常安全可靠的。

JWT是如何将原始的JSON格式数据,转变为字符串的呢?
其实在生成
JWT
令牌时,会对
JSON
格式的数据进行一次编码:进行
base64编码
Base64
:是一种基于
64
个可打印的字符来表示二进制数据的编码方式。既然能编码,那也就意味
着也能解码。所使用的
64
个字符分别是
A
到
Z
、
a
到
z
、
0- 9
,一个加号,一个斜杠,加起来就是
64
个字符。任何数据经过
base64
编码之后,最终就会通过这
64
个字符来表示。当然还有一个符
号,那就是等号。等号它是一个补位的符号
需要注意的是Base64是编码方式,而不是加密方式。
JWT
令牌最典型的应用场景就是登录认证:
1.
在浏览器发起请求来执行登录操作,此时会访问登录的接口,如果登录成功之后,我们需要生成
一个
jwt
令牌,将生成的
jwt
令牌返回给前端。
2.
前端拿到
jwt
令牌之后,会将
jwt
令牌存储起来。在后续的每一次请求中都会将
jwt
令牌携带到服
务端。
3.
服务端统一拦截请求之后,先来判断一下这次请求有没有把令牌带过来,如果没有带过来,直接
拒绝访问,如果带过来了,还要校验一下令牌是否是有效。如果有效,就直接放行进行请求的处
理。
在
JWT
登录认证的场景中我们发现,整个流程当中涉及到两步操作:
1.
在登录成功之后,要生成令牌。
2.
每一次请求当中,要接收令牌并对令牌进行校验。
生成和校验
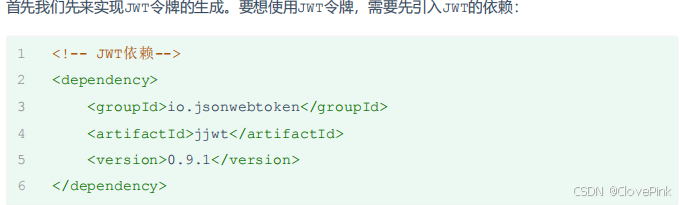

链式编程.builder()
.signWith()
.setClaims()
.setExpiration()
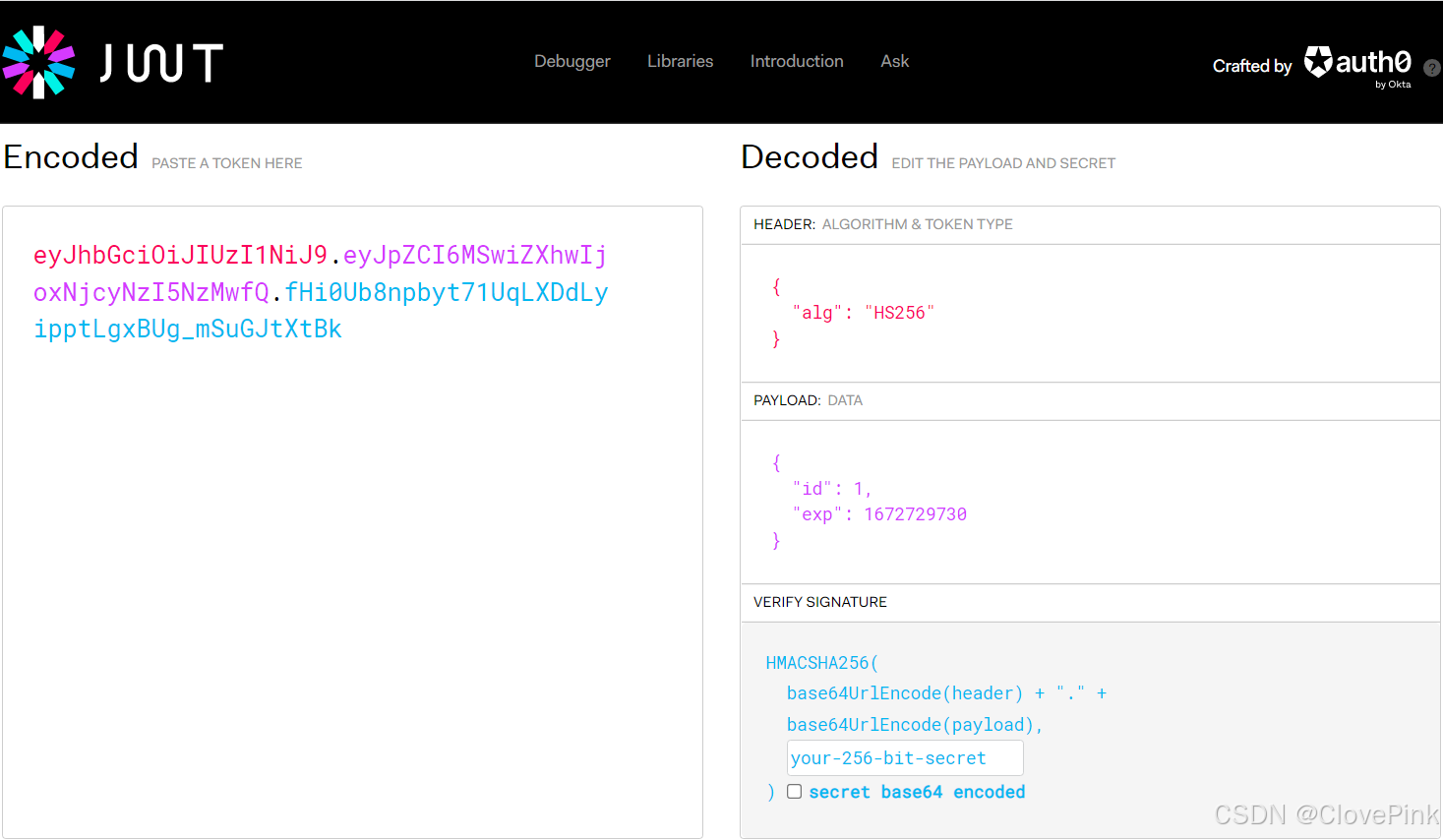
第一部分解析出来,看到
JSON
格式的原始数据,所使用的签名算法为
HS256
。
第二个部分是我们自定义的数据,之前我们自定义的数据就是
id
,还有一个
exp
代表的是我们所设
置的过期时间。
由于前两个部分是
base64
编码,所以是可以直接解码出来。但最后一个部分并不是
base64
编
码,是经过签名算法计算出来的,所以最后一个部分是不会解析的。
实现了
JWT
令牌的生成,下面我们接着使用
Java
代码来校验
JWT
令牌
(
解析生成的令牌
)
:

在使用
JWT
令牌时需要注意:
JWT
校验时使用的签名秘钥,必须和生成
JWT
令牌时使用的秘钥是配套的。
如果
JWT
令牌解析校验时报错,则说明
JWT
令牌被篡改 或 失效了,令牌非法。
登录下发令牌
JWT
令牌的生成和校验的基本操作我们已经学习完了,接下来我们就需要在案例当中通过
JWT
令牌技术来跟踪会话。具体的思路我们前面已经分析过了,主要就是两步操作:
1.
生成令牌
在登录成功之后来生成一个JWT
令牌,并且把这个令牌直接返回给前端
2.
校验令牌
拦截前端请求,从请求中获取到令牌,对令牌进行解析校验
那我们首先来完成:登录成功之后生成
JWT
令牌,并且把令牌返回给前端。
实现步骤:
1.
引入
JWT
工具类
在项目工程下创建com.itheima.utils
包,并把提供
JWT
工具类复制到该包下
2.
登录完成后,调用工具类生成
JWT
令牌并返回
服务器响应的
JWT
令牌存储在本地浏览器哪里了呢?
在当前案例中,
JWT
令牌存储在浏览器的本地存储空间
local storage
中了。
local storage
是浏览器的本地存储,在移动端也是支持的。
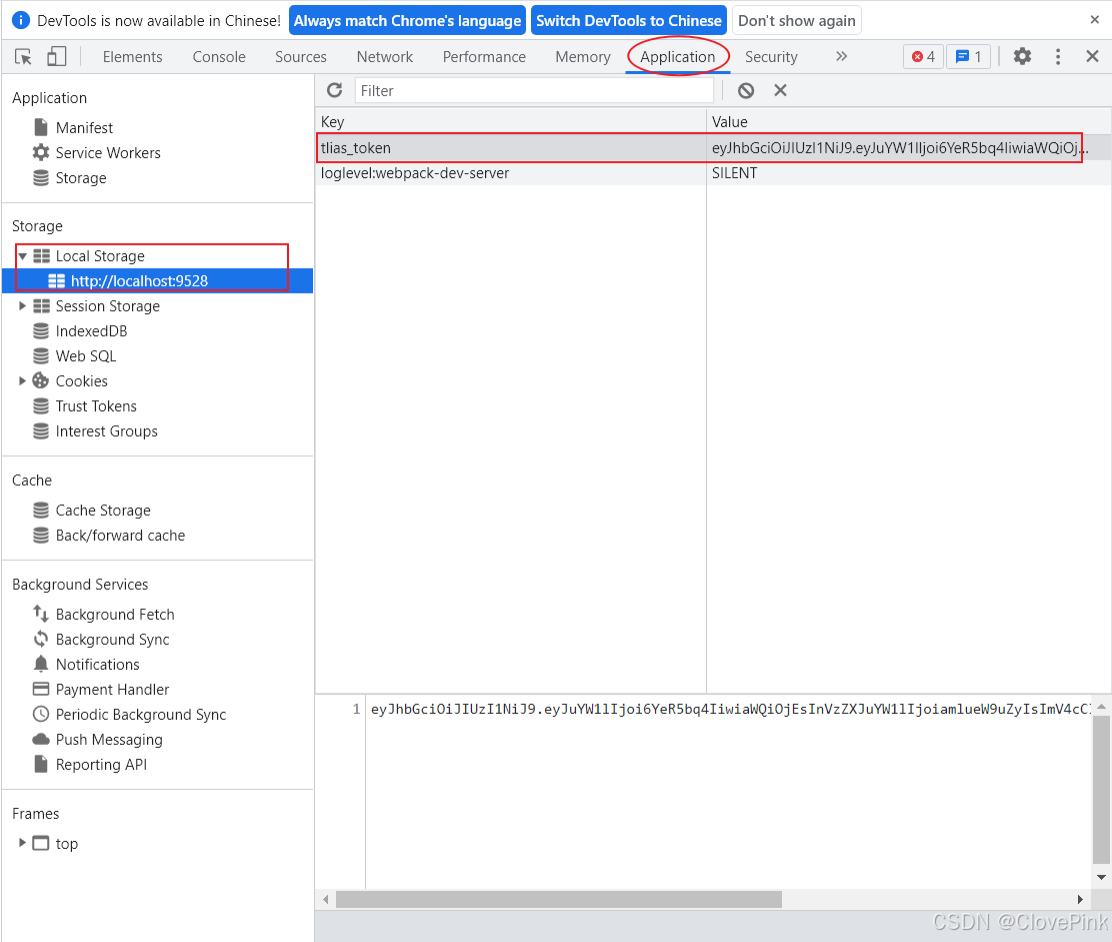
我们在发起一个查询部门数据的请求,此时我们可以看到在请求头中包含一个
token(JWT
令牌
)
,后续的每一次请求当中,都会将这个令牌携带到服务端。
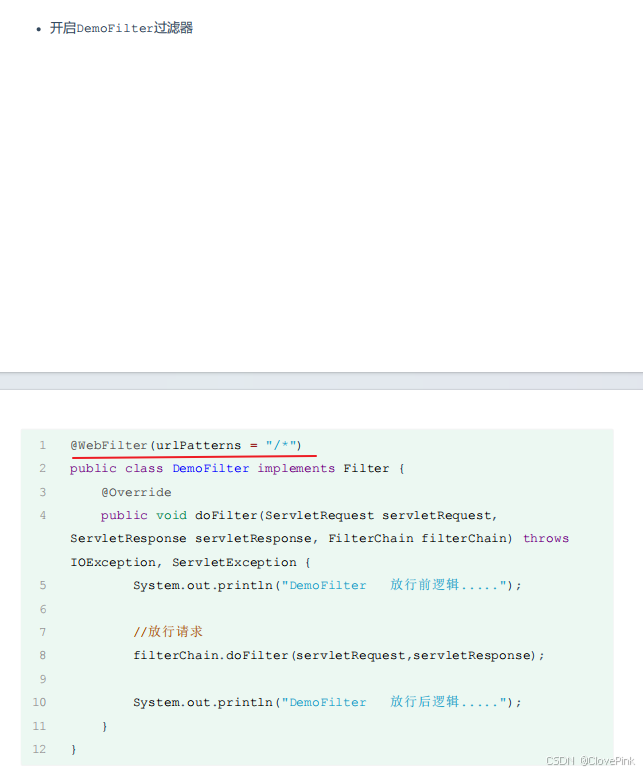
过滤器Filter
刚才通过浏览器的开发者工具,我们可以看到在后续的请求当中,都会在请求头中携带
JWT
令牌到服务端,而服务端需要统一拦截所有的请求,从而判断是否携带的有合法的JWT
令牌。
那怎么样来统一拦截到所有的请求校验令牌的有效性呢?这里我们会学习两种解决方案:
1. Filter
过滤器
2. Interceptor
拦截器
什么是
Filter
?
Filter
表示过滤器,是
JavaWeb
三大组件
(Servlet
、
Filter
、
Listener)
之一。
过滤器可以把对资源的请求拦截下来,从而实现一些特殊的功能
使用了过滤器之后,要想访问
web
服务器上的资源,必须先经过滤器,过滤器处理完毕之后,
才可以访问对应的资源。
过滤器一般完成一些通用的操作,比如:登录校验、统一编码处理、敏感字符处理等。

下面我们通过
Filter
快速入门程序掌握过滤器的基本使用操作:
第
1
步,定义过滤器 :
1.
定义一个类,实现
Filter
接口,并重写其所有方法。
第
2
步,配置过滤器:
Filter
类上加
@WebFilter
注解,配置拦截资源的路径。引导类上加
@ServletComponentScan
开启
Servlet
组件支持。

init
方法:过滤器的初始化方法。在
web
服务器启动的时候会自动的创建
Filter
过滤器对
象,在创建过滤器对象的时候会自动调用
init
初始化方法,这个方法只会被调用一次。
doFilter
方法:这个方法是在每一次拦截到请求之后都会被调用,所以这个方法是会被调
用多次的,每拦截到一次请求就会调用一次
doFilter()
方法。
destroy
方法: 是销毁的方法。当我们关闭服务器的时候,它会自动的调用销毁方法
destroy
,而这个销毁方法也只会被调用一次。
在定义完
Filter
之后,
Filter
其实并不会生效,还需要完成
Filter
的配置,
Filter
的配置非常简
单,只需要在
Filter
类上添加一个注解:
@WebFilter
,并指定属性
urlPatterns
,通过这个属性指
定过滤器要拦截哪些请求

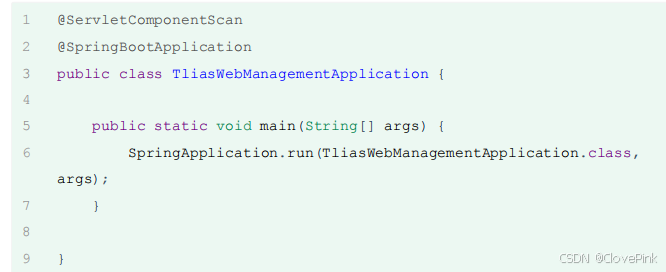
当我们在
Filter
类上面加了
@WebFilter
注解之后,接下来我们还需要在启动类上面加上一个注解
@ServletComponentScan
,通过这个
@ServletComponentScan
注解来开启
SpringBoot
项目对于
Servlet
组件的支持。
Filter详解
Filter
过滤器的快速入门程序我们已经完成了,接下来我们就要详细的介绍一下过滤器
Filter
在使用
中的一些细节。主要介绍以下
3
个方面的细节:
1.
过滤器的执行流程
2.
过滤器的拦截路径配置
3.
过滤器链
过滤器的执行流程:
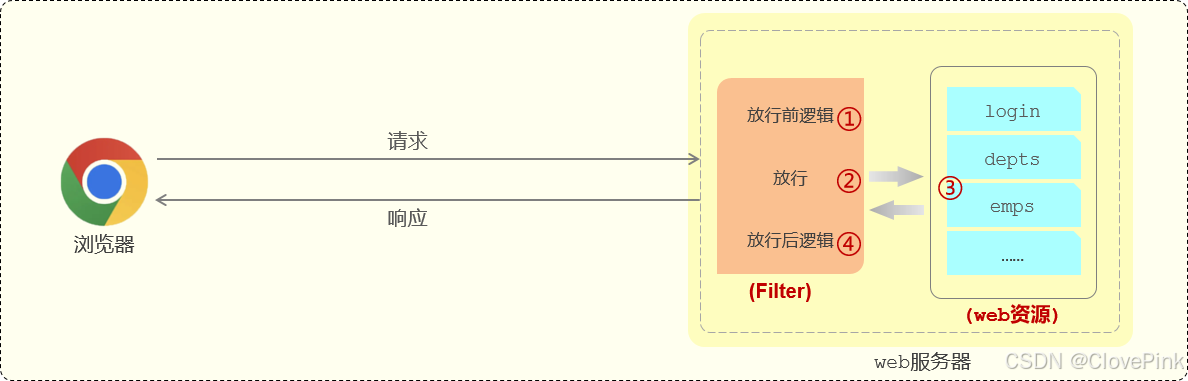
过滤器当中我们拦截到了请求之后,如果希望继续访问后面的
web
资源,就要执行放行操作,放行就是调用 FilterChain
对象当中的
doFilter()
方法,在调用
doFilter()
这个方法之前所编写的代码属
于放行之前的逻辑。
在放行后访问完
web
资源之后还会回到过滤器当中,回到过滤器之后如有需求还可以执行放行之后的逻辑,放行之后的逻辑我们写在doFilter()
这行代码之后。

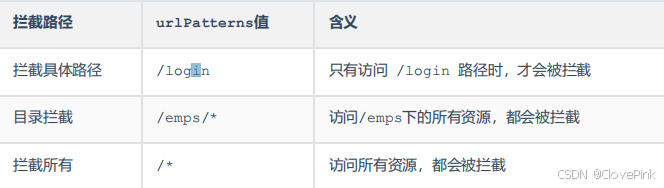
拦截路径
执行流程我们搞清楚之后,接下来再来介绍一下过滤器的拦截路径,
Filter
可以根据需求,配置不同的拦截资源路径:
过滤器链
最后我们在来介绍下过滤器链,什么是过滤器链呢?所谓过滤器链指的是在一个
web
应用程序当中,可以配置多个过滤器,多个过滤器就形成了一个过滤器链。
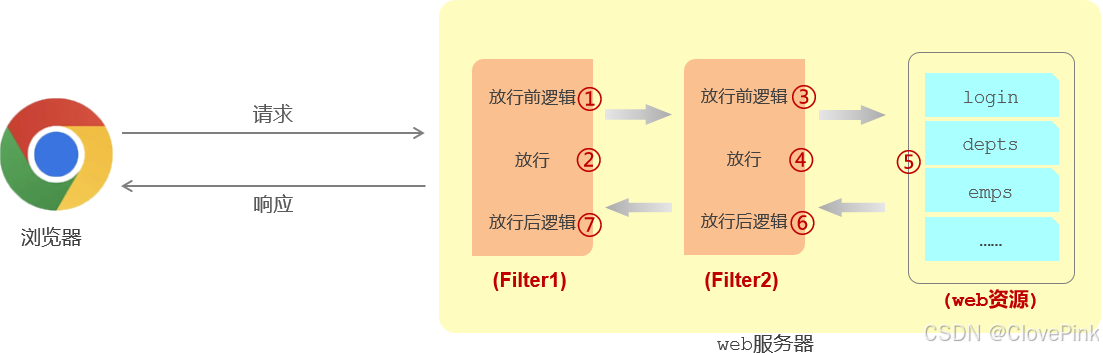
比如:在我们
web
服务器当中,定义了两个过滤器,这两个过滤器就形成了一个过滤器链。
而这个链上的过滤器在执行的时候会一个一个的执行,会先执行第一个
Filter
,放行之后再来执行第二个Filter
,如果执行到了最后一个过滤器放行之后,才会访问对应的
web
资源。
访问完
web
资源之后,按照我们刚才所介绍的过滤器的执行流程,还会回到过滤器当中来执行过滤器放行后的逻辑,而在执行放行后的逻辑的时候,顺序是反着的。
先要执行过滤器
2
放行之后的逻辑,再来执行过滤器
1
放行之后的逻辑,最后在给浏览器响应数据。
以注解方式配置的
Filter
过滤器,它的执行优先级是按过滤器类名的自动排序确定的,类名排名越靠前,优先级越高。
假如我们想让DemoFilter
先执行,怎么办呢?答案就是修改类名。
登录校验-Filter
我们要完成登录校验,主要是利用Filter过滤器实现,而Filter过滤器的流程步骤:
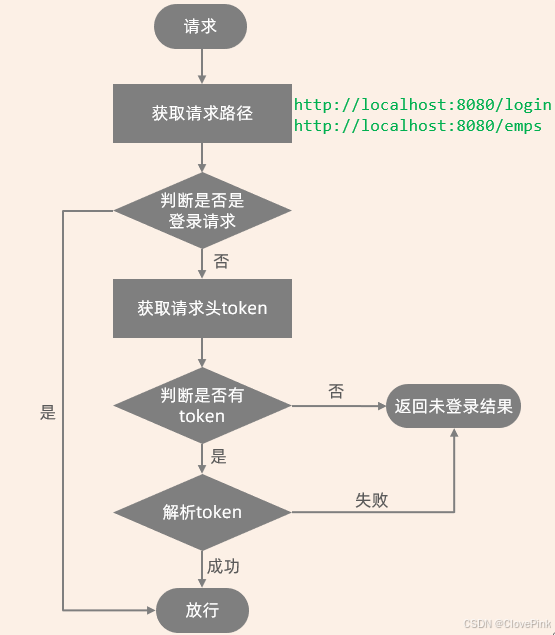
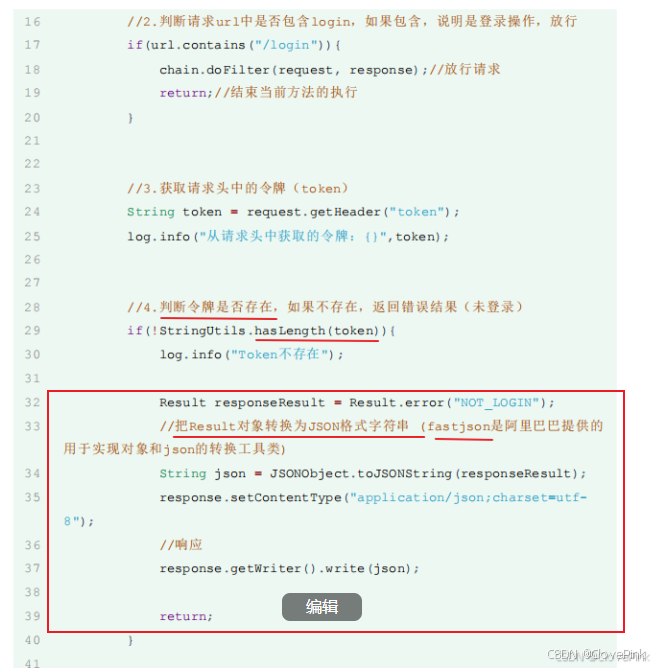
基于上面的业务流程,我们分析出具体的操作步骤:
1.
获取请求
url
2.
判断请求
url
中是否包含
login
,如果包含,说明是登录操作,放行
3.
获取请求头中的令牌(
token
)
4.
判断令牌是否存在,如果不存在,返回错误结果(未登录)
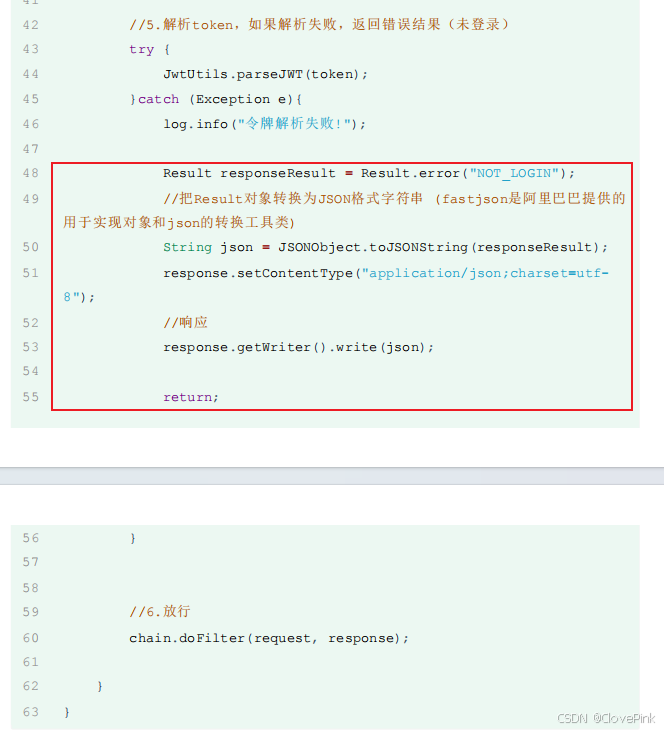
5.
解析
token
,如果解析失败,返回错误结果(未登录)
6.
放行

拦截器Interceptor
什么是拦截器?
是一种动态拦截方法调用的机制,类似于过滤器。
拦截器是
Spring
框架中提供的,用来动态拦截控制器方法的执行。
拦截器的作用:
拦截请求,在指定方法调用前后,根据业务需要执行预先设定的代码。
在拦截器当中,我们通常也是做一些通用性的操作,比如:我们可以通过拦截器来拦截前端发起的请求,将登录校验的逻辑全部编写在拦截器当中。在校验的过程当中,如发现用户登录了(
携带
JWT
令牌且是合法令牌)
,就可以直接放行,去访问
spring
当中的资源。如果校验时发现并没有登录或是非法令牌,就可以直接给前端响应未登录的错误信息。
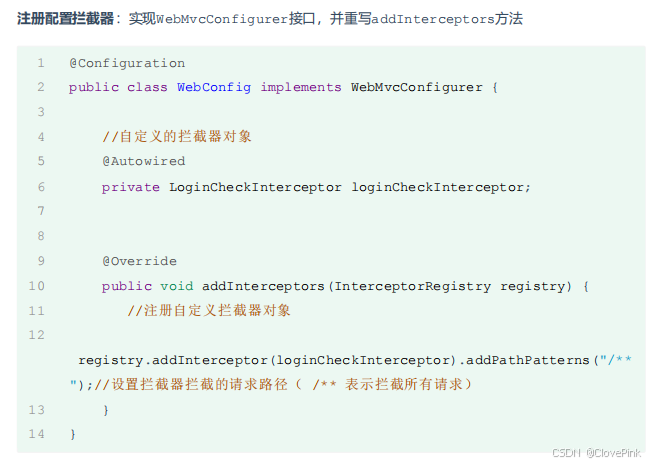
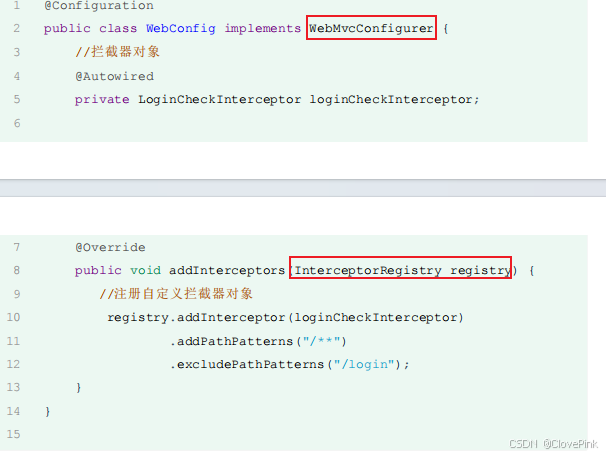
下面我们通过快速入门程序,来学习下拦截器的基本使用。拦截器的使用步骤和过滤器类似,也分为两步:
1.
定义拦截器
2.
注册配置拦截器

注意:
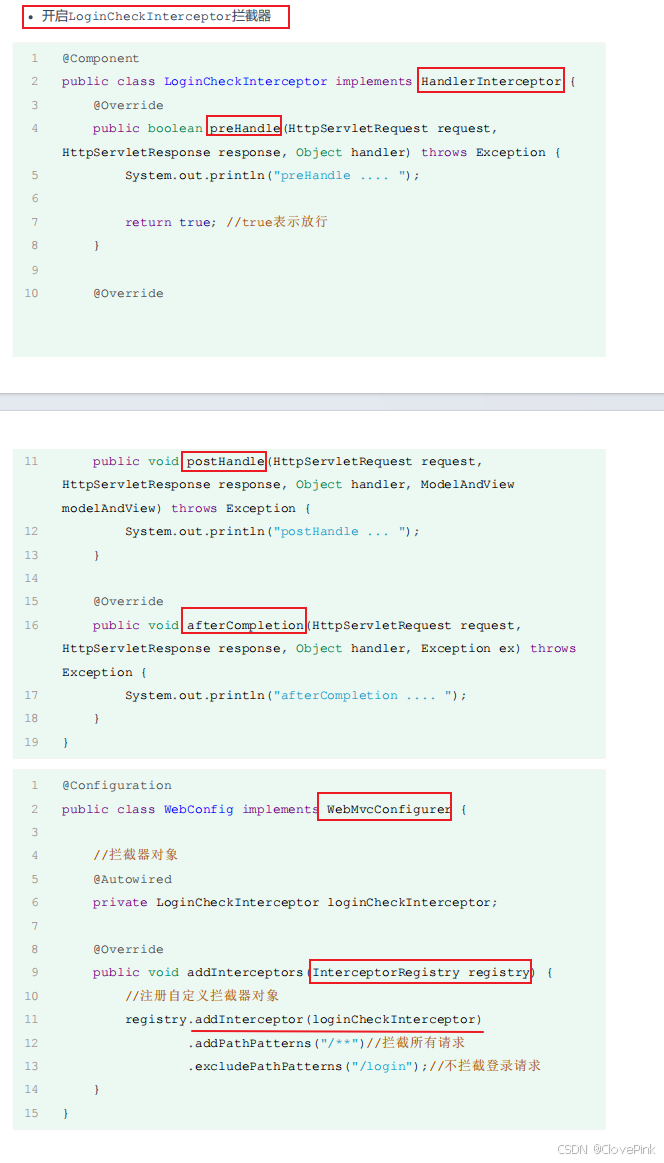
preHandle
方法:目标资源方法执行前执行。 返回
true
:放行 返回
false
:不放行
postHandle
方法:目标资源方法执行后执行
afterCompletion
方法:视图渲染完毕后执行,最后执行
Interceptor详解
拦截器的入门程序完成之后,接下来我们来介绍拦截器的使用细节。拦截器的使用细节我们主要介绍两个部分:
1.
拦截器的拦截路径配置
2.
拦截器的执行流程
拦截路径
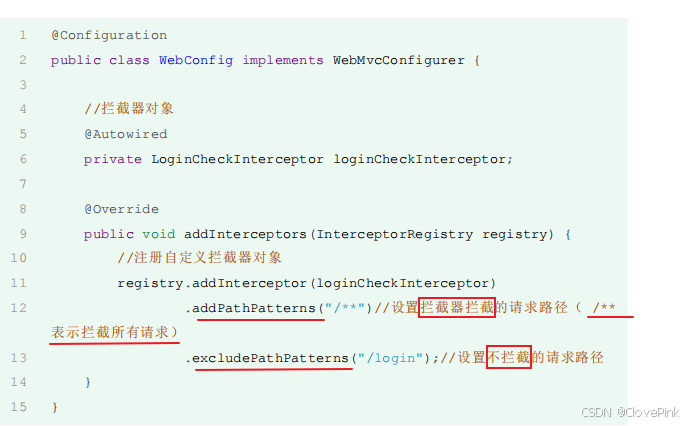
首先我们先来看拦截器的拦截路径的配置,在注册配置拦截器的时候,我们要指定拦截器的拦截路径,通过
addPathPatterns("
要拦截路径
")
方法,就可以指定要拦截哪些资源。
在入门程序中我们配置的是
/**
,表示拦截所有资源,而在配置拦截器时,不仅可以指定要拦截哪些资源,还可以指定不拦截哪些资源,只需要调用
excludePathPatterns("
不拦截路径
")
方法,指定哪些资源不需要拦截。
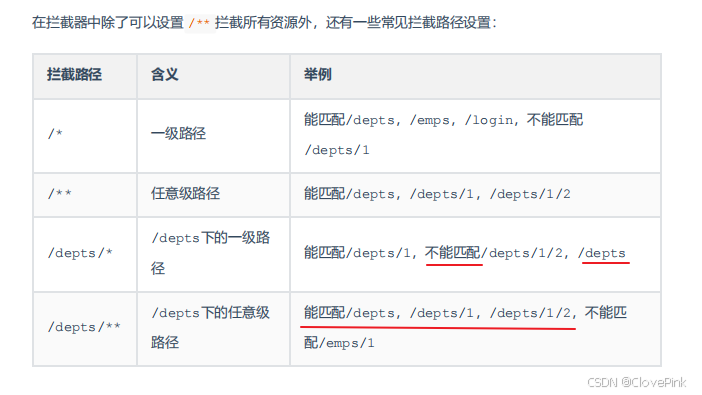
执行流程
介绍完拦截路径的配置之后,接下来我们再来介绍拦截器的执行流程。通过执行流程,大家就能够清晰的知道过滤器与拦截器的执行时机。
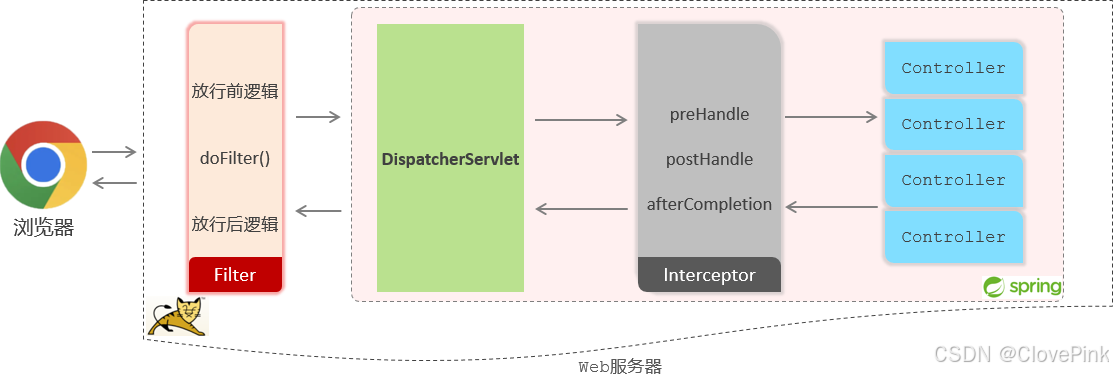

接下来我们就来演示下过滤器和拦截器同时存在的执行流程:
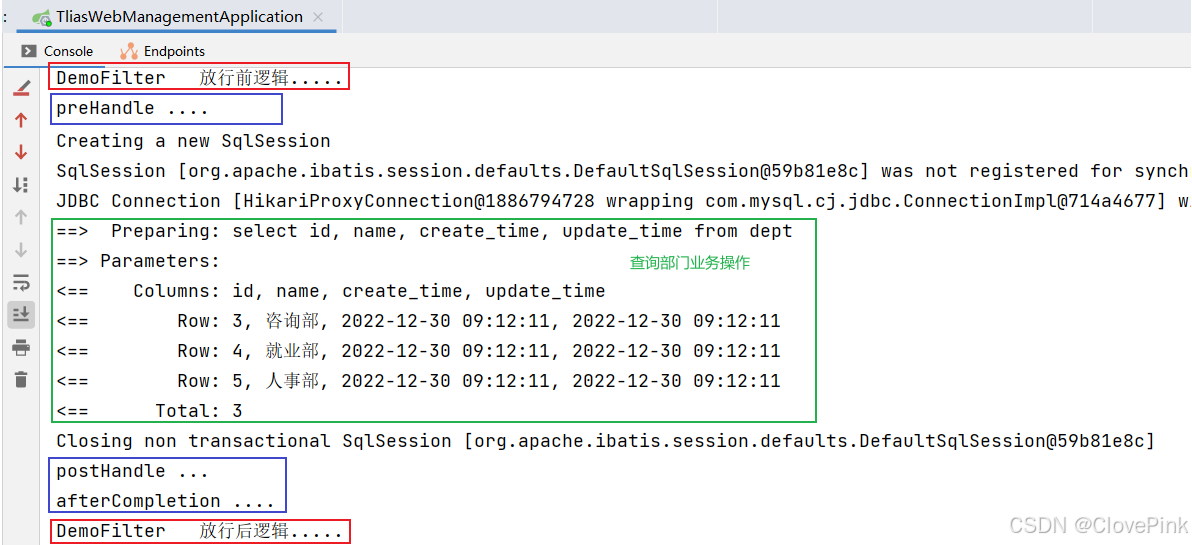
以上就是拦截器的执行流程。通过执行流程分析,大家应该已经清楚了过滤器和拦截器之间的区别,其实它们之间的区别主要是两点:
接口规范不同:过滤器需要实现
Filter接口
,而拦截器需要实现
HandlerInterceptor接口
。
拦截范围不同:过滤器
Filter
会
拦截所有的资源
,而
Interceptor
只会拦截Spring环境中的资
源。
登录校验- Interceptor
登录校验拦截器


注册配置拦截器
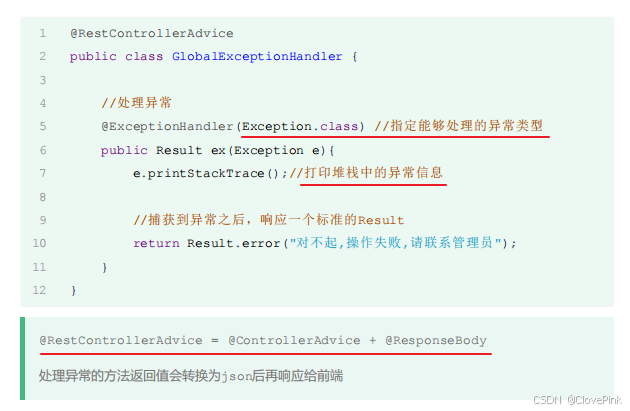
全局异常处理器
我们该怎么样定义全局异常处理器?
定义全局异常处理器非常简单,就是定义一个类,在类上加上一个注解
@RestControllerAdvice
,加上这个注解就代表我们定义了一个全局异常处理器。
在全局异常处理器当中,需要定义一个方法来捕获异常,在这个方法上需要加上注解
@ExceptionHandler
。通过
@ExceptionHandler
注解当中的
value
属性来指定我们要捕获的
是哪一类型的异常。
事务管理
事务
是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体,一起向数据库提交或者是撤销操作请求。所以这组操作要么同时成功,要么同时失败。
事务的操作主要有三步:
1.
开启事务(一组操作开始前,开启事务):
start transaction / begin ;
2.
提交事务(这组操作全部成功后,提交事务):
commit ;
3.
回滚事务(中间任何一个操作出现异常,回滚事务):
rollback ;
Transactional注解
@Transactional
作用:就是在当前这个方法执行开始之前来开启事务,方法执行完毕之后提交
事务。如果在这个方法执行的过程当中出现了异常,就会进行事务的回滚操作。
@Transactional
注解:我们一般会在
业务层
当中来控制事务,因为在业务层当中,一个业务功
能可能会包含多个数据访问的操作。在业务层来控制事务,我们就可以将多个数据访问操作控制在
一个事务范围内。
@Transactional
注解书写位置:
方法
当前方法交给spring
进行事务管理
类
当前类中所有的方法都交由spring
进行事务管理
接口
接口下所有的实现类当中所有的方法都交给
spring
进行事务管理
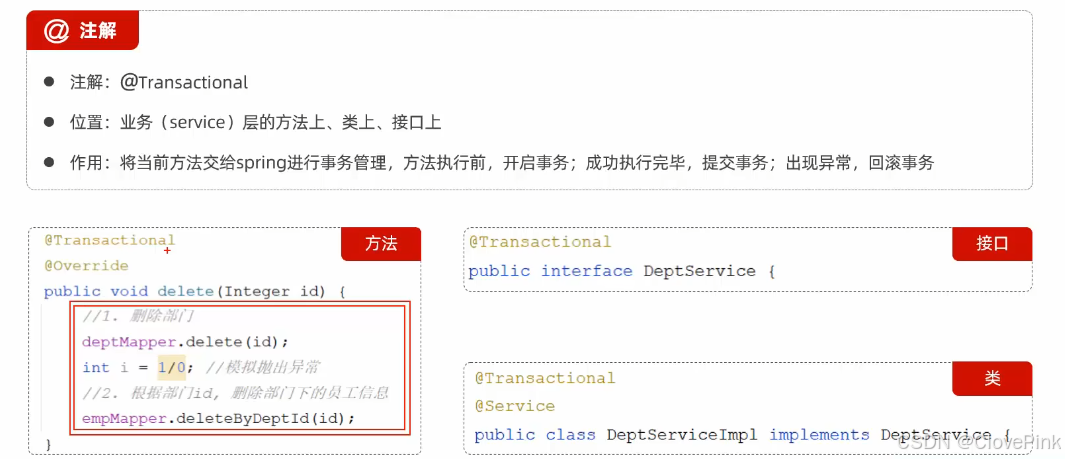
介绍
@Transactional
注解当中的两个常见的属性:
1.
异常回滚的属性:
rollbackFor
2.
事务传播行为:
propagation
rollbackFor
默认情况下,只有出现
RuntimeException(
运行时异常
)
才会回滚事务。
假如我们想让所有的异常都回滚,需要来配置
@Transactional
注解当中的
rollbackFor
属性,通过
rollbackFor
这个属性可以指定出现何种异常类型回滚事务。
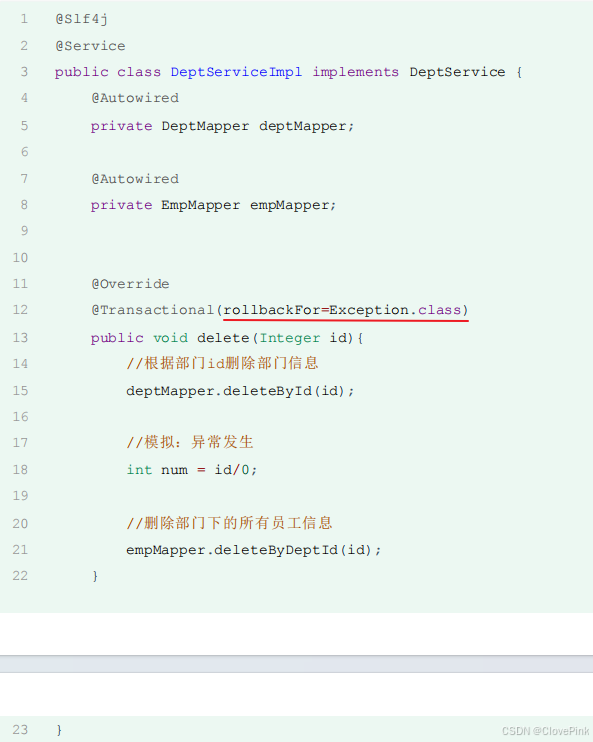
结论:
在
Spring
的事务管理中,默认只有运行时异常
RuntimeException
才会回滚。
如果还需要回滚指定类型的异常,可以通过
rollbackFor
属性来指定。
propagation
什么是事务的传播行为呢?
就是当一个事务方法被另一个事务方法调用时,这个事务方法应该如何进行事务控制。
例如:两个事务方法,一个
A
方法,一个
B
方法。在这两个方法上都添加了
@Transactional
注解,就代表这两个方法都具有事务,而在A
方法当中又去调用了
B
方法。

所谓事务的传播行为,指的就是在
A
方法运行的时候,首先会开启一个事务,在
A
方法当中又调用了
B
方法, B
方法自身也具有事务,那么
B
方法在运行的时候,到底是加入到
A
方法的事务当中来,还是
B
方法在运行的时候新建一个事务?这个就涉及到了事务的传播行为。
我们要想控制事务的传播行为,在
@Transactional
注解的后面指定一个属性
propagation
,通过
propagation
属性来指定传播行为。接下来我们就来介绍一下常见的事务传播行为。

对于这些事务传播行为,我们只需要关注以下两个就可以了:
1. REQUIRED
(默认值)
2. REQUIRES_NEW

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









