







目录
1、<if>
2、<foreach>
3、<sql> &<include>
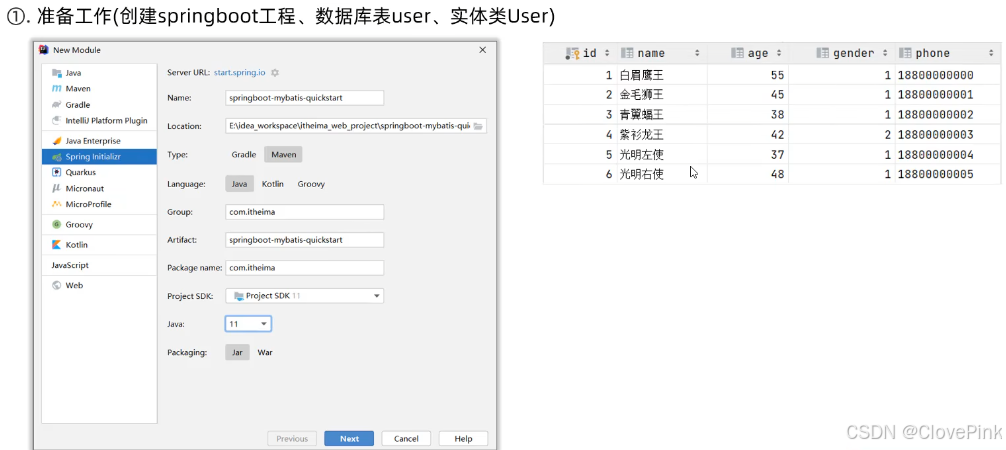
一、Mybatis入门
1、快速入门
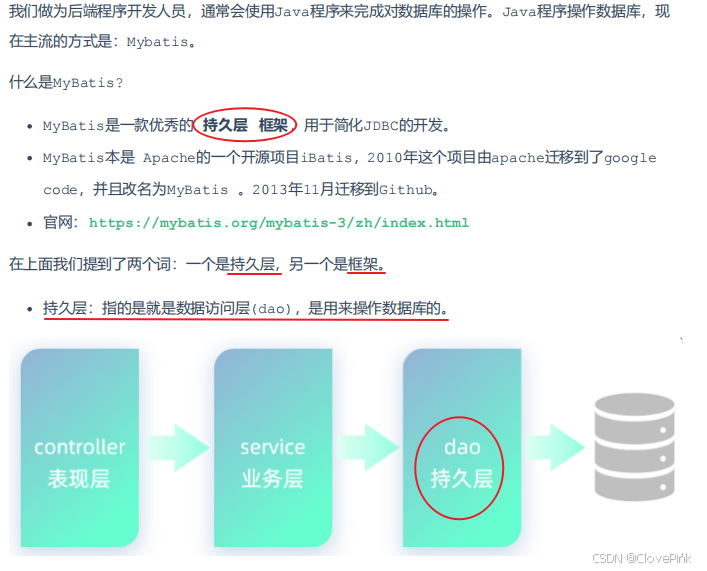
框架:是一个半成品软件,是一套可重用的、通用的、软件基础代码模型。在框架的基础上进行软
件开发更加高效、规范、通用、可拓展。
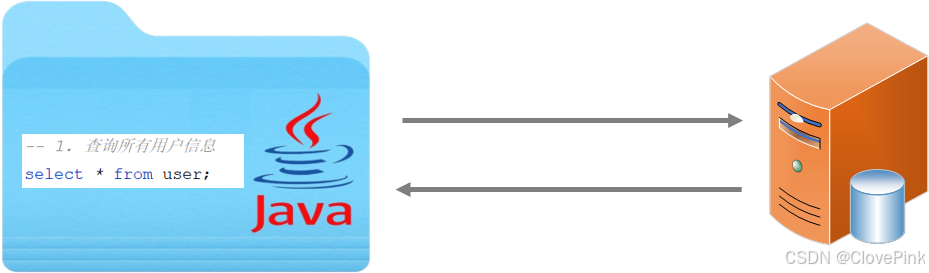
现在使用
Mybatis
操作数据库,就是在
Mybatis
中编写
SQL
查询代码,发送给数据库执行,数据库执行后返回结果。
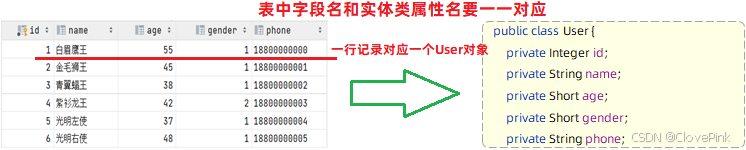
Mybatis
会把数据库执行的查询结果,使用实体类封装起来(一行记录对应一个实体类对象)
@Mapper
注解:表示是
mybatis
中的
Mapper
接口
程序运行时:框架会自动生成接口的实现类对象
(
代理对象
)
,并给交
Spring
的
IOC
容器管理
@Select
注解:代表的就是
select
查询,用于书写
select
查询语句

注解
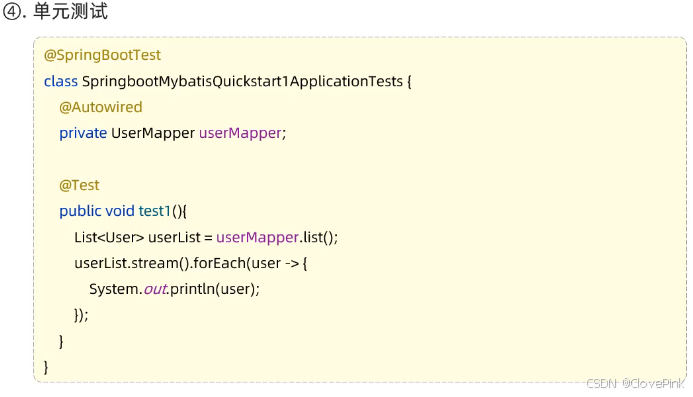
@SpringBootTest
,代表该测试类已经与
SpringBoot
整合。 该测试类在运行时,会自动通过引导类加载Spring
的环境(
IOC容器)。
我们要测试那个
bean
对象,
就可以直接通过
@Autowired
注解直接将其注入进行,然后就可以测试了。
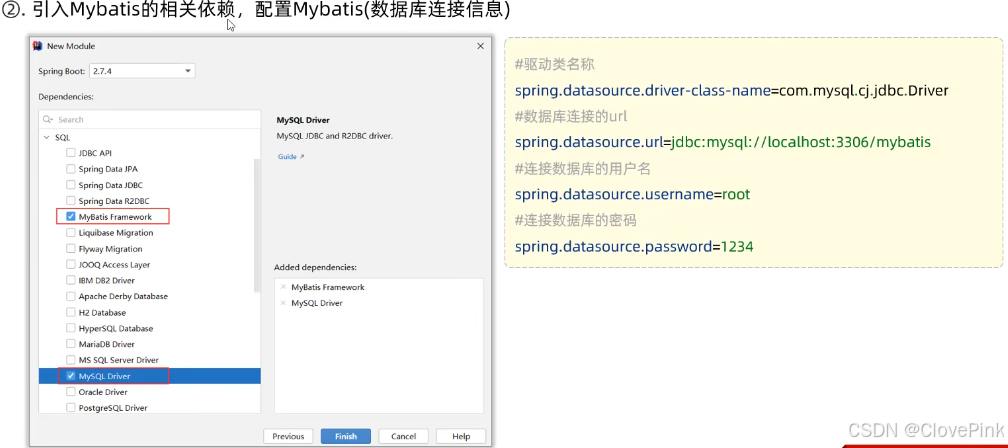
2、JDBC介绍
通过
Mybatis
的快速入门,我们明白了,通过
Mybatis
可以很方便的进行数据库的访问操作。但是大家 要明白,其实java
语言操作数据库呢,只能通过一种方式:使用
sun
公司提供的
JDBC
规范。
Mybatis框架,就是对原始的
JDBC
程序的封装。
JDBC
:
( Java DataBase Connectivity )
,就是使用
Java
语言操作关系型数据库的一套
API
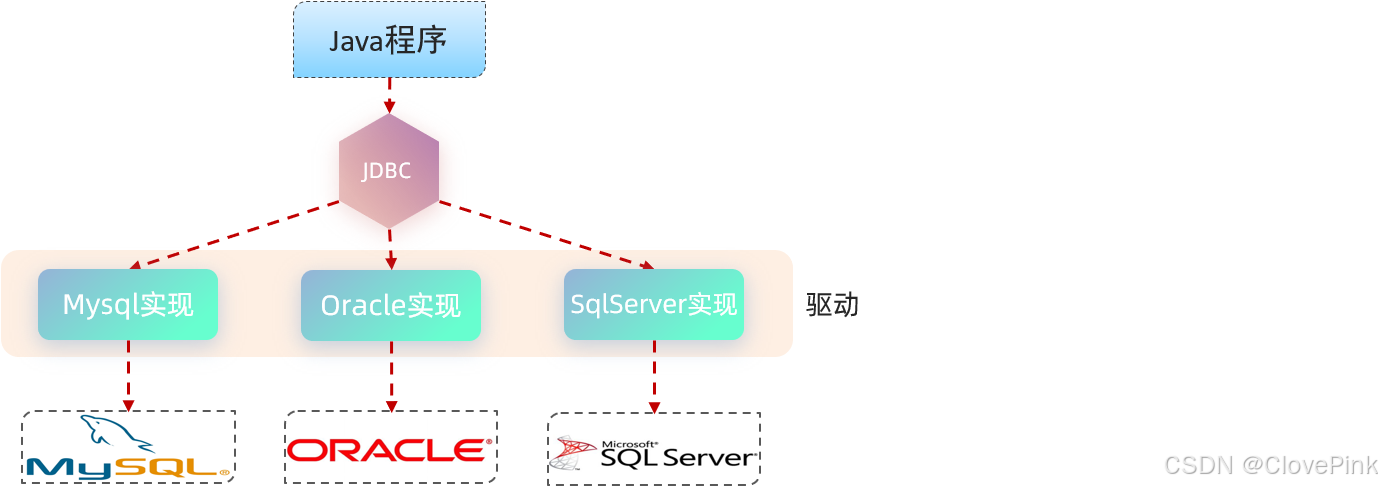
本质:
sun
公司官方定义的一套操作所有
关系型
数据库的规范,即接口。
各个数据库厂商去实现这套接口,提供数据库驱动
jar
包。
我们可以使用这套接口
(JDBC)
编程,真正执行的代码是驱动
jar
包中的实现类。
技术对比
分析了
JDBC
的缺点之后,我们再来看一下在
mybatis
中,是如何解决这些问题的:
1.
数据库连接四要素
(
驱动、链接、用户名、密码
)
,都配置在
springboot
默认的配置文件
application.properties
中
2.
查询结果的解析及封装,由
mybatis
自动完成映射封装,我们无需关注
3.
在
mybatis
中使用了数据库连接池技术,从而避免了频繁的创建连接、销毁连接而带来的资源浪
费。
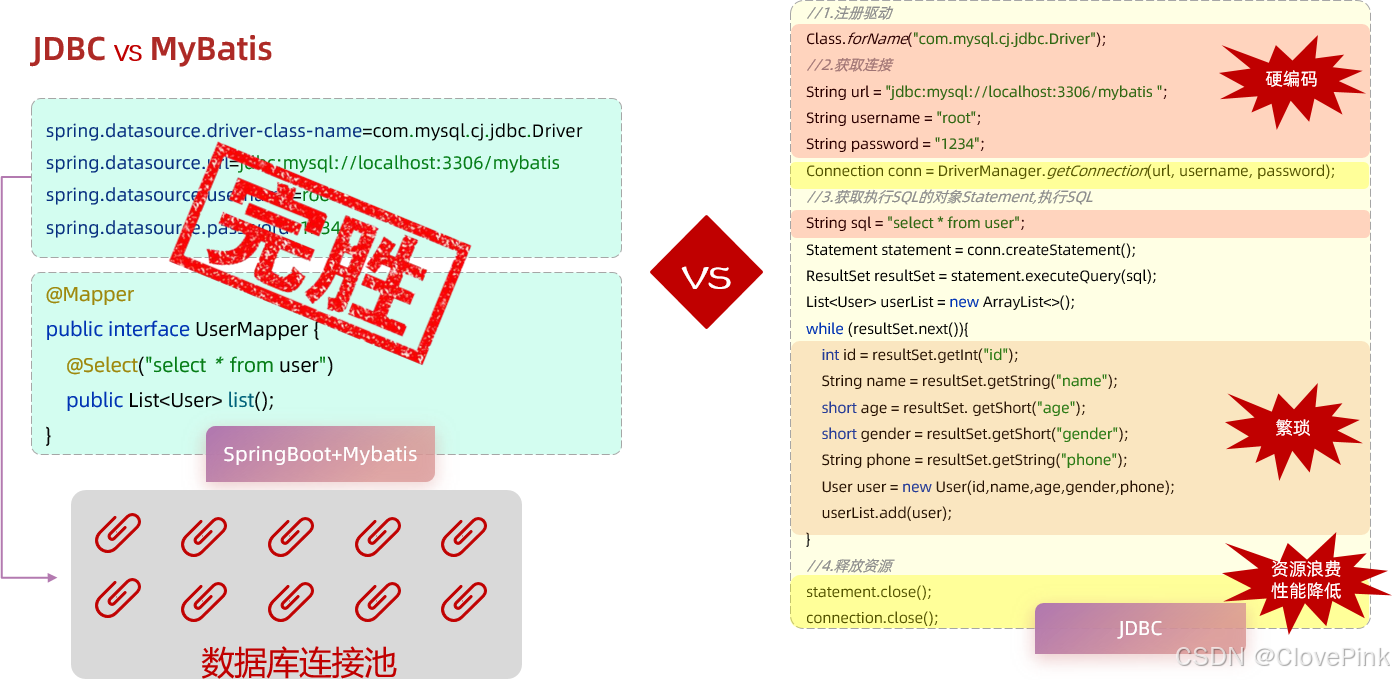
使用
SpringBoot+Mybatis
的方式操作数据库,能够提升开发效率、降低资源浪费
3、数据库连接池

没有使用数据库连接池:
客户端执行
SQL
语句:要先创建一个新的连接对象,然后执行
SQL
语句,
SQL
语句执行后又需要关闭连接对象从而释放资源,每次执行SQL时都需要创建连接、销毁链接,这种频繁的重复创建销毁的过程是比较耗费计算机的性能。
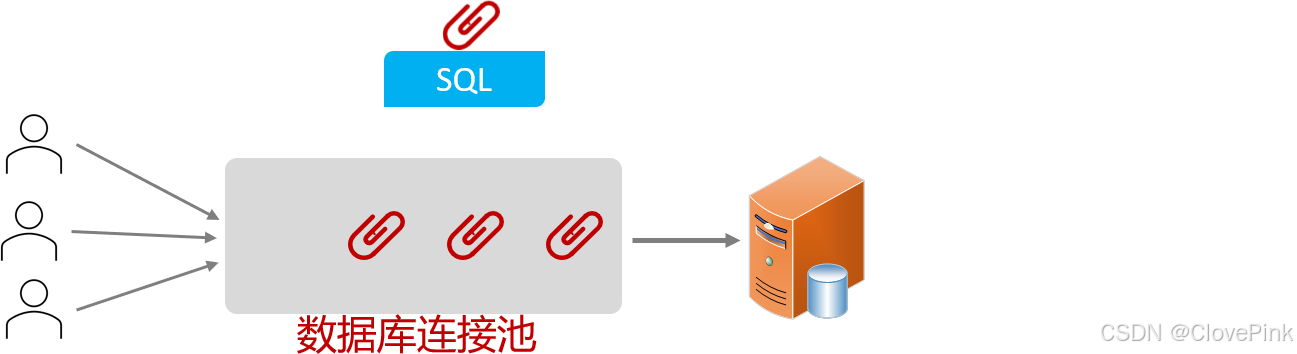
数据库连接池是个容器,负责分配、管理数据库连接
(Connection)
·程序在启动时,会在数据库连接池
(
容器
)
中,创建一定数量的
Connection
对象允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个
·客户端在执行SQL
时,先从连接池中获取一个
Connection
对象,然后在执行
SQL
语句,
SQL
语句
执行完之后,释放
Connection
时就会把
Connection
对象归还给连接池(
Connection
对象可以
复用)
释放空闲时间超过最大空闲时间的连接,来避免因为没有释放连接而引起的数据库连接遗漏
·客户端获取到Connection
对象了,但是
Connection
对象并没有去访问数据库
(
处于空闲
)
,数据
库连接池发现
Connection
对象的空闲时间
>
连接池中预设的最大空闲时间,此时数据库连接池
就会自动释放掉这个连接对象
数据库连接池的好处:
1.
资源重用
2.
提升系统响应速度
3.
避免数据库连接遗漏
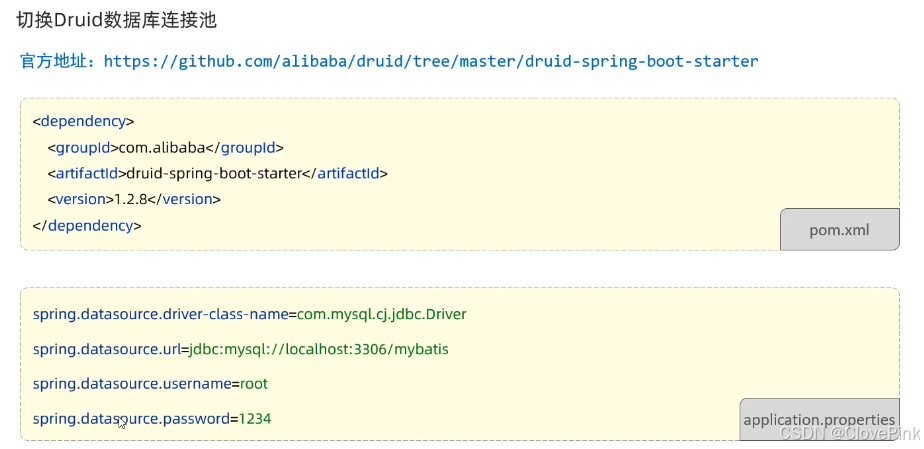
Druid
(德鲁伊)
Druid
连接池是阿里巴巴开源的数据库连接池项目
功能强大,性能优秀,是
Java
语言最好的数据库连接池之一
如果我们想把默认的数据库连接池切换为
Druid
数据库连接池,只需要完成以下两步操作即可:
4、lombok
Lombok
是一个实用的
Java
类库,可以通过简单的注解来简化和消除一些必须有但显得很臃肿的
Java
代码。

通过注解的形式自动生成构造器、
getter/setter
、
equals
、
hashcode
、
toString
等方法,并可以自动化生成日志变量,简化java
开发、提高效率。

第
1
步:在
pom.xml文件中引入依赖
<!--
在
springboot
的父工程中,已经集成了
lombok
并指定了版本号,故当前引入依赖
时不需要指定
version -->
<dependency>
<groupId>
org.projectlombok
</groupId>
<artifactId>
lombok
</artifactId>
</dependency>
第
2
步:在实体类上添加注解
import
lombok
.
Data
;
@Data
public class
User
{
private
Integer
id
;
private
String
name
;
private
Short
age
;
private
Short
gender
;
private
String
phone
;
}
在实体类上添加了
@Data
注解,那么这个类在编译时期,就会生成
getter/setter
、
equals
、
hashcode
、
toString
等方法。
说明:@Data注解中不包含全参构造方法,通常在实体类上,还会添加上:全参构造、无参构造
Lombok的注意事项:
Lombok
会在编译时,会自动生成对应的
java
代码。在使用lombok
时,还需要安装一个
lombok
的插件(新版本的
IDEA
中自带)
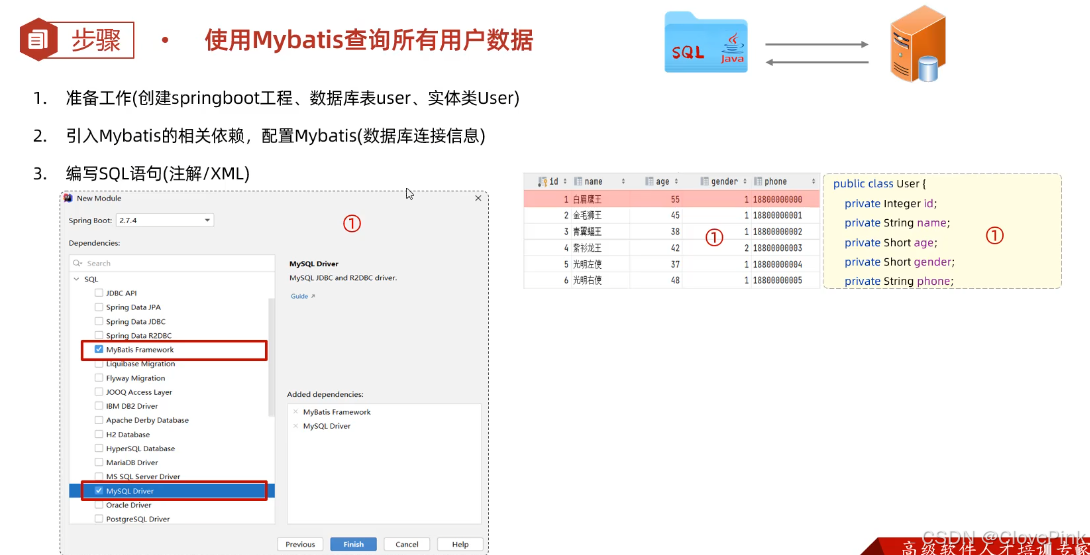
二、Mybatis基础增删改查
1、准备
实施前的准备工作:
1.
准备数据库表
2.
创建一个新的
springboot
工程,选择引入对应的起步依赖(
mybatis
、
mysql
驱动、
lombok
)
3. application.properties
中引入数据库连接信息
4.
创建对应的实体类
Emp
(实体类属性采用驼峰命名)
5.
准备
Mapper
接口
EmpMapper
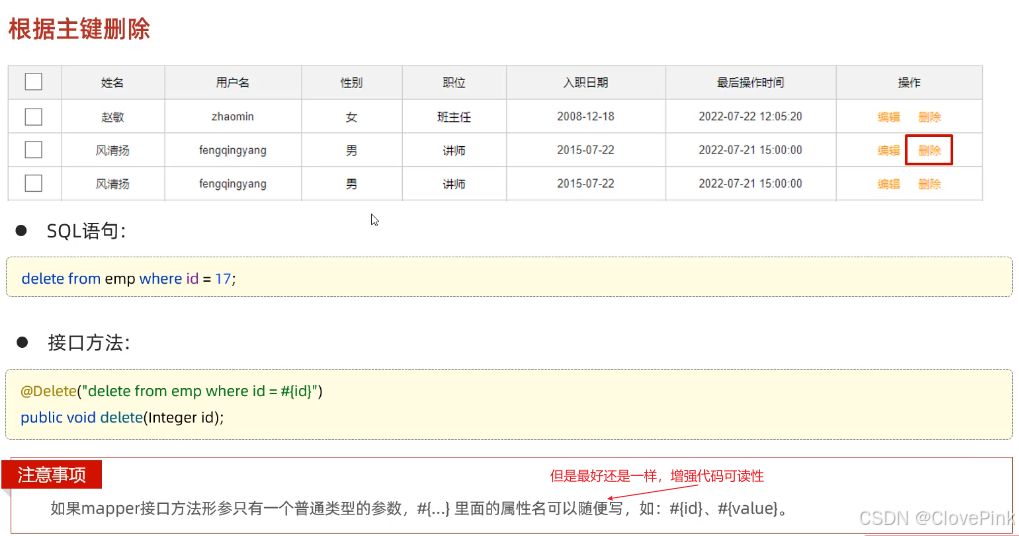
2、删除
页面原型:

当我们点击后面的
"
删除
"
按钮时,前端页面会给服务端传递一个参数,也就是该行数据的
ID
。
我们接收到
ID
后,根据
ID
删除数据即可。
@Test 注解
在 Java 单元测试框架中非常常见,主要用于标记一个方法为测试方法。以下是一些关于 @Test 注解的关键点:
用途:
标记一个方法为测试方法,该方法将被测试运行器执行。
测试方法通常是无参数且返回值为 void 的。
常用框架:
JUnit:最常用的 Java 单元测试框架之一。
TestNG:另一个流行的 Java 测试框架,支持更复杂的测试场景。
用途:
标记一个方法为测试方法,该方法将被测试运行器执行。
测试方法通常是无参数且返回值为 void 的。
常用框架:
JUnit:最常用的 Java 单元测试框架之一。
TestNG:另一个流行的 Java 测试框架,支持更复杂的测试场景。
1)日志输出
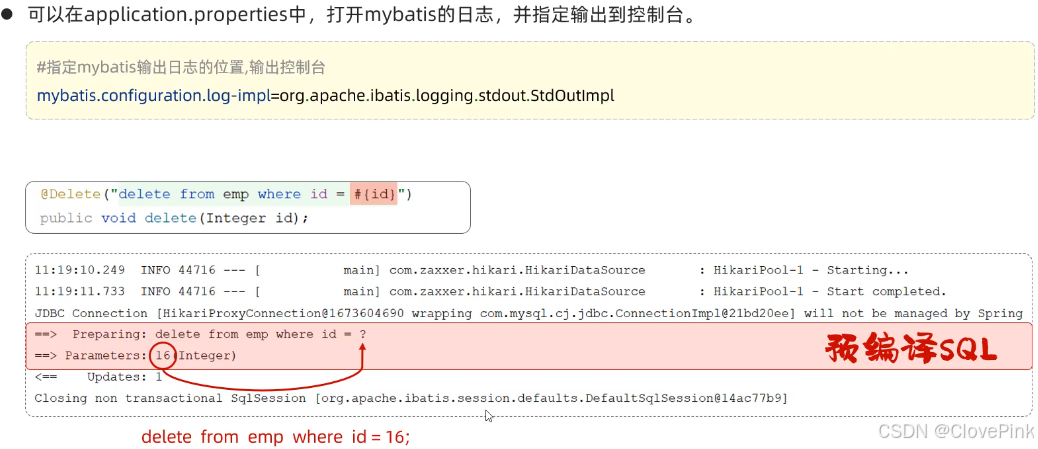
2)预编译SQL
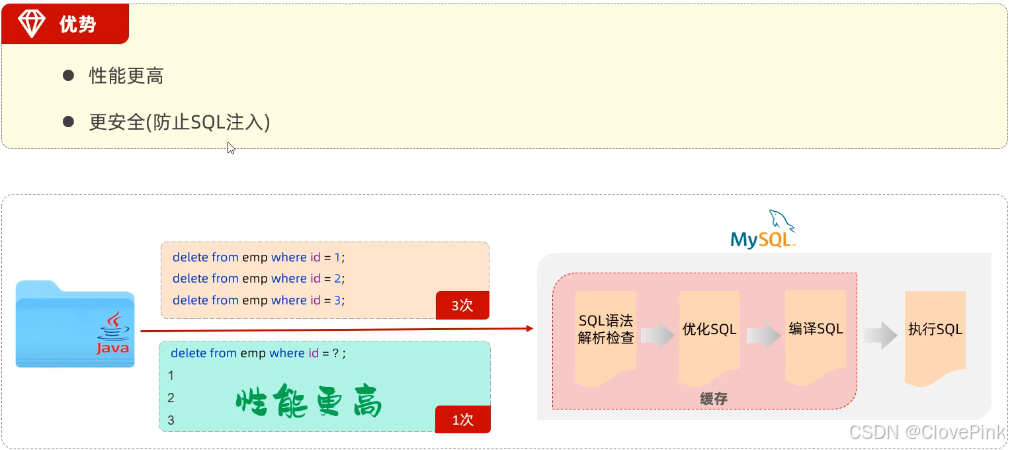
性能更高:预编译
SQL
,编译一次之后会将编译后的
SQL
语句缓存起来,后面再次执行这条语时,不会再次编译。(只是输入的参数不同)
更安全
(
防止
SQL
注入
)
:将敏感字进行转义,保障
SQL
的安全性。
3)SQL注入
SQL
注入:是通过操作输入的数据来修改事先定义好的
SQL
语句,以达到执行代码对服务器进行攻击的方法。
由于没有对用户输入进行充分检查,而
SQL
又是拼接而成,在用户输入参数时,在参数中添加一些
SQL
关键字,达到改变
SQL
运行结果的目的,也可以完成恶意攻击。
存在SQL注入:由于没有对用户输入内容进行充分检查,而
SQL
又是字符串拼接方式而成,在用户输入参数时,在
参数中添加一些
SQL
关键字,达到改变
SQL
运行结果的目的,从而完成恶意攻击。
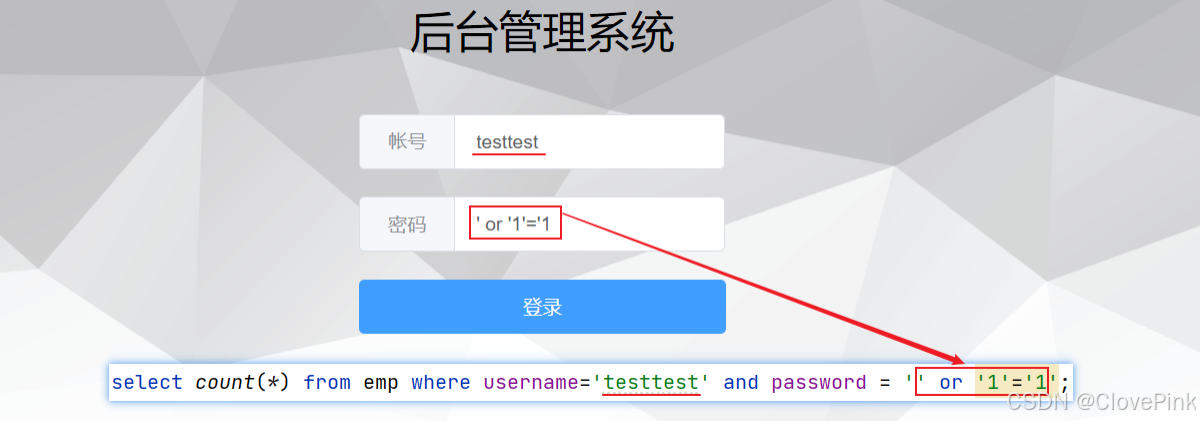
已解决SQL注入:

4)参数占位符

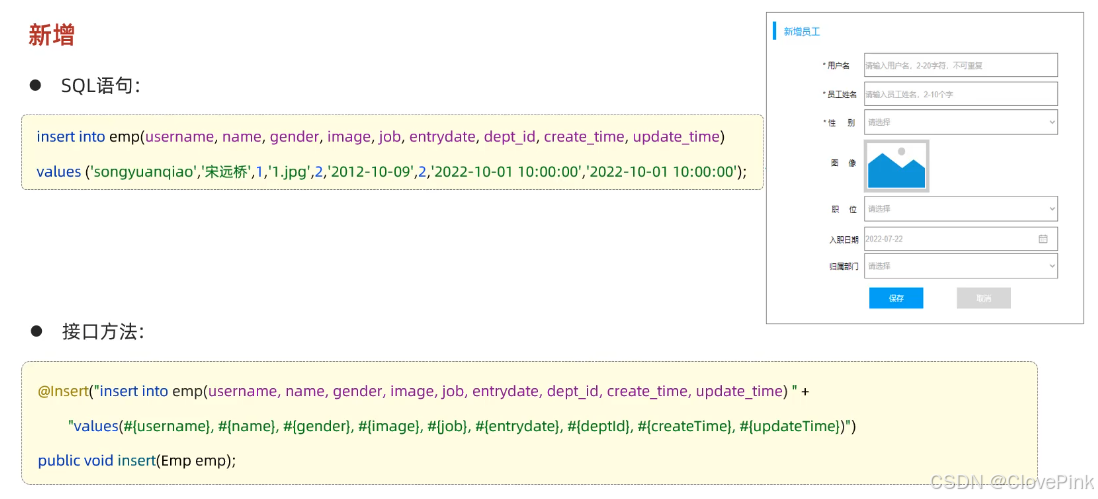
3、新增
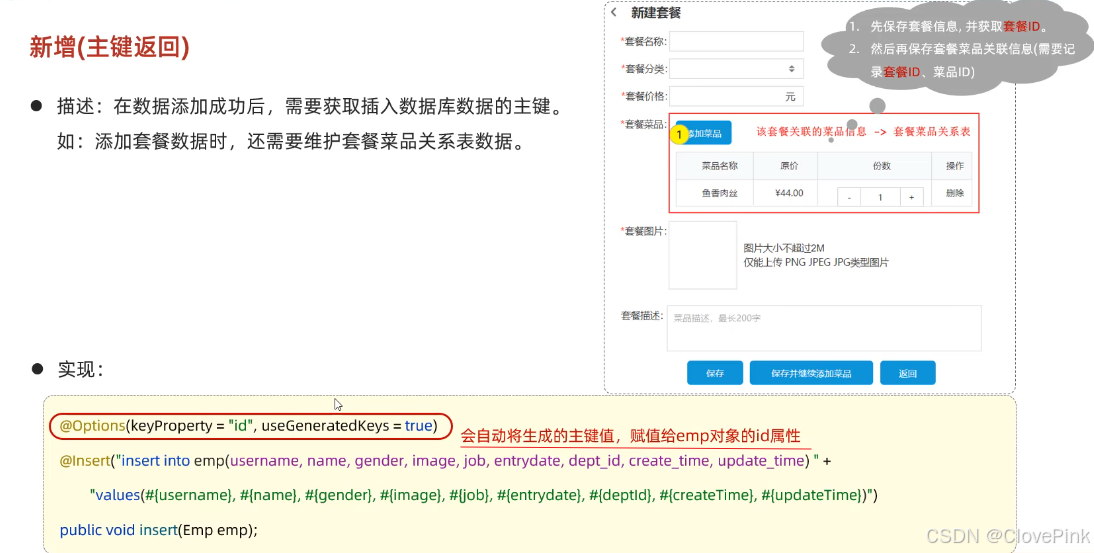
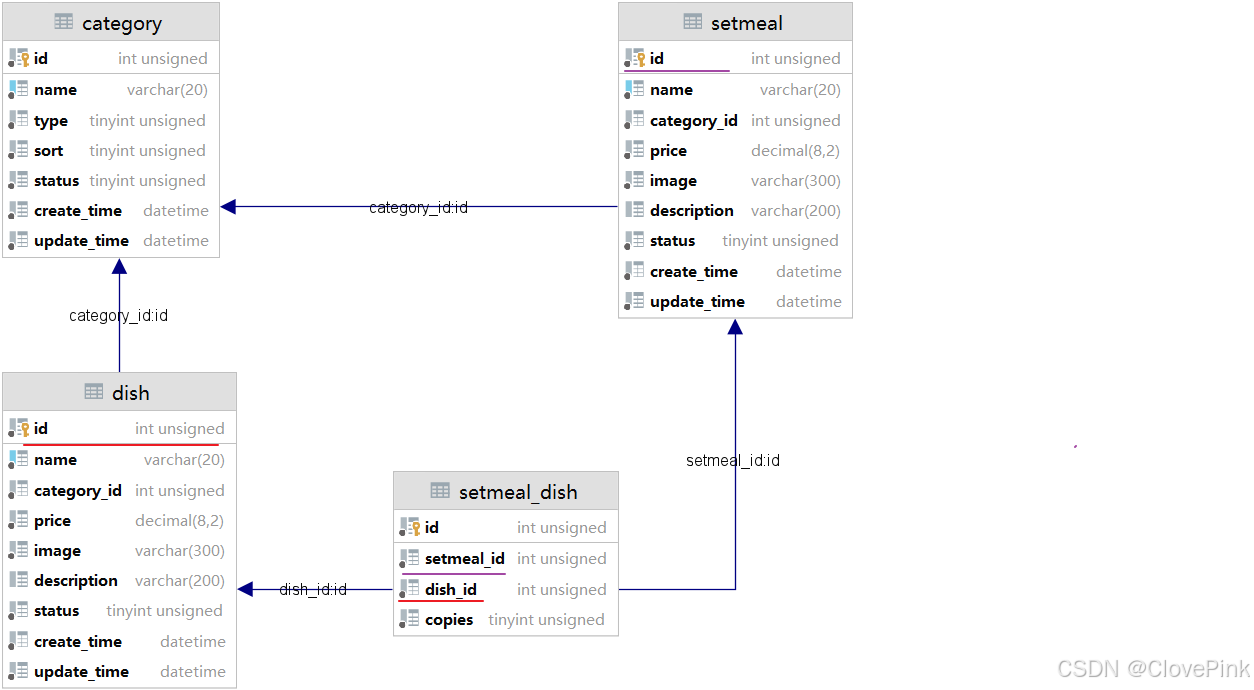
业务场景:在前面讲解到的苍穹外卖菜品与套餐模块的表结构,菜品与套餐是多对多的关系,一个
套餐对应多个菜品。既然是多对多的关系,是不是有一张套餐菜品中间表来维护它们之间的关系。
在添加套餐的时候,我们需要在界面当中来录入套餐的基本信息,还需要来录入套餐与菜品的关联
信息。这些信息录入完毕之后,我们一点保存,就需要将套餐的信息以及套餐与菜品的关联信息都
需要保存到数据库当中。其实具体的过程包括两步,首先第一步先需要将套餐的基本信息保存了, 接下来第二步再来保存套餐与菜品的关联信息。套餐与菜品的关联信息就是往中间表当中来插入数
据,来维护它们之间的关系。而中间表当中有两个外键字段,一个是菜品的
ID
,就是当前菜品ID,还有一个就是套餐的
ID
,而这个套餐的
ID
指的就是此次我所添加的套餐的
ID
,所以我们 在第一步保存完套餐的基本信息之后,就需要将套餐的主键值返回来供第二步进行使用。这个时候 就需要用到主键返回功能。
那要如何实现在插入数据之后返回所插入行的主键值呢?
默认情况下,执行插入操作时,是不会主键值返回的。如果我们想要拿到主键值,需要在Mapper 接口中的方法上添加一个Options
注解,并在注解中指定属性
useGeneratedKeys=true
和
keyProperty="
实体类属性名
"
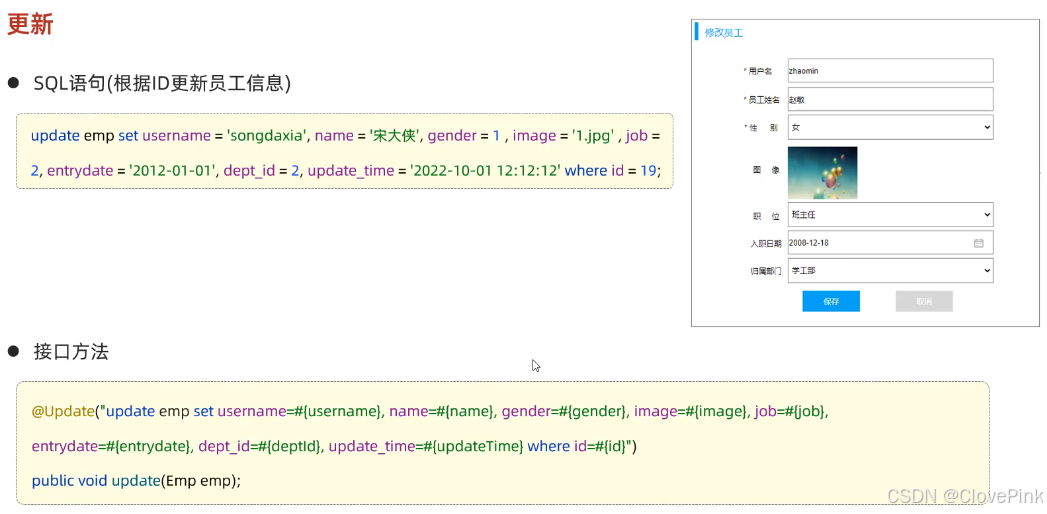
4、更新
5、查询
1)根据ID查询
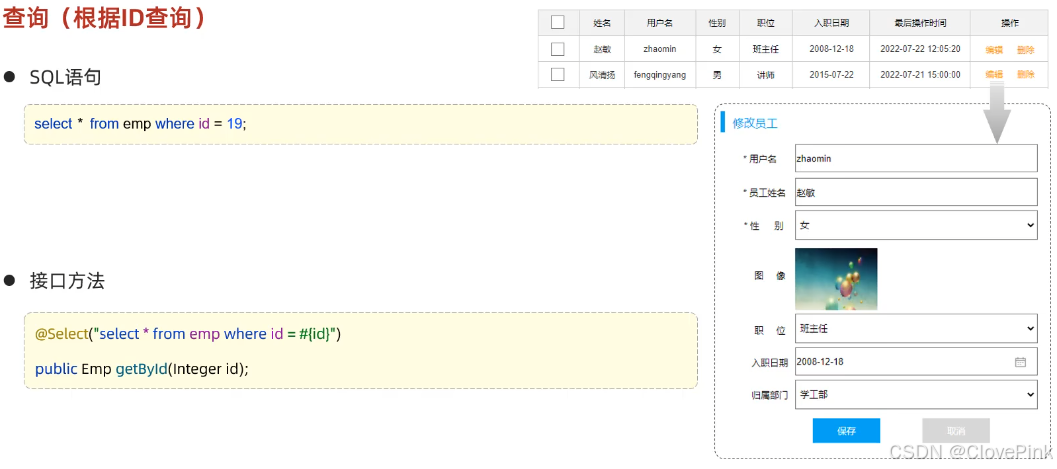
执行结果:

我们看到查询返回的结果中大部分字段是有值的,但是
deptId
,
createTime
,
updateTime
这几个字
段是没有值的,而数据库中是有对应的字段值的,这是为什么呢?
原因如下:
·实体类属性名和数据库表查询返回的字段名一致,mybatis
会自动封装。
·如果实体类属性名和数据库表查询返回的字段名不一致,不能自动封装。
解决方案:
1.起别名
2. 结果映射
3. 开启驼峰命名
起别名
:在
SQL
语句中,对不一样的列名起别名,别名和实体类属性名一样
@Select
(
"select id, username, password, name, gender, image, job,
entrydate, "
+
"dept_id AS deptId, create_time AS createTime, update_time AS
updateTime "
+
"from emp "
+
"where id=#{id}"
)
public
Emp
getById
(
Integer
id
);
手动结果映射
:通过
@Results
及
@Result
进行手动结果映射
@Results
({
@Result
(
column
=
"dept_id"
,
property
=
"deptId"
),
@Result
(
column
=
"create_time"
,
property
=
"createTime"
),
@Result
(
column
=
"update_time"
,
property
=
"updateTime"
)})
@Select
(
"select id, username, password, name, gender, image, job,
entrydate, dept_id, create_time, update_time from emp where id=#{id}"
)
public
Emp
getById
(
Integer
id
);
开启驼峰命名
(
推荐
)
:如果字段名与属性名符合驼峰命名规则,
mybatis
会自动通过驼峰命名规则映射
驼峰命名规则:
abc_xyz => abcXyz
表中字段名:abc_xyz
类中属性名:abcXyz
#
在
application.properties
中添加:
mybatis.configuration.map-underscore-to-camel-case
=
true
要使用驼峰命名前提是 实体类的属性 与 数据库表中的字段名严格遵守驼峰命名。
2)条件查询
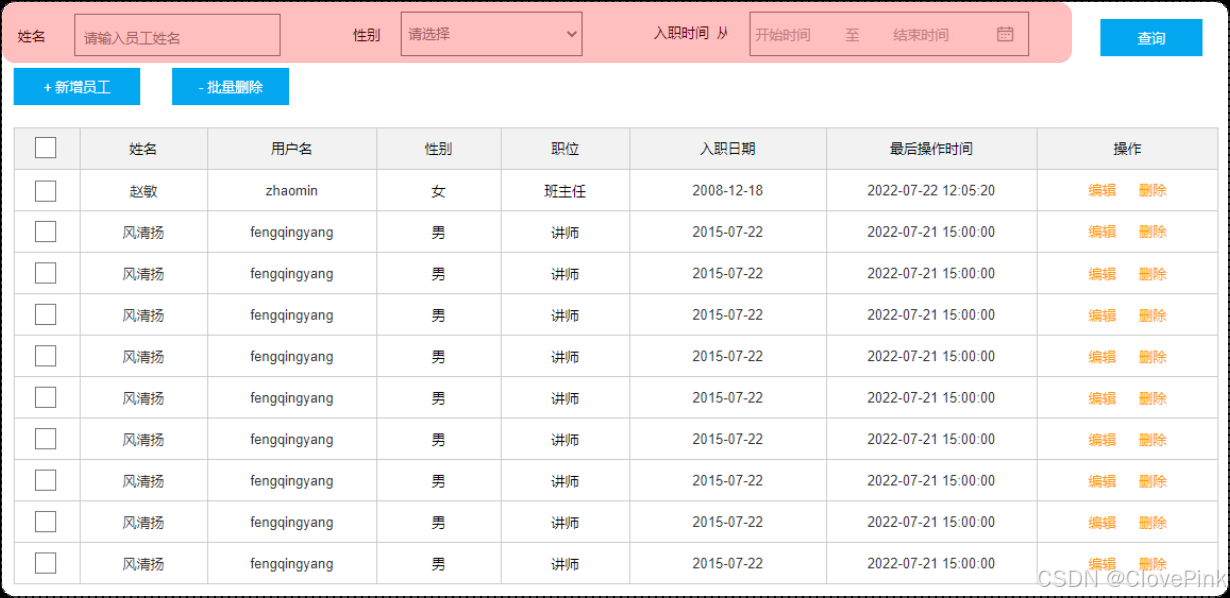
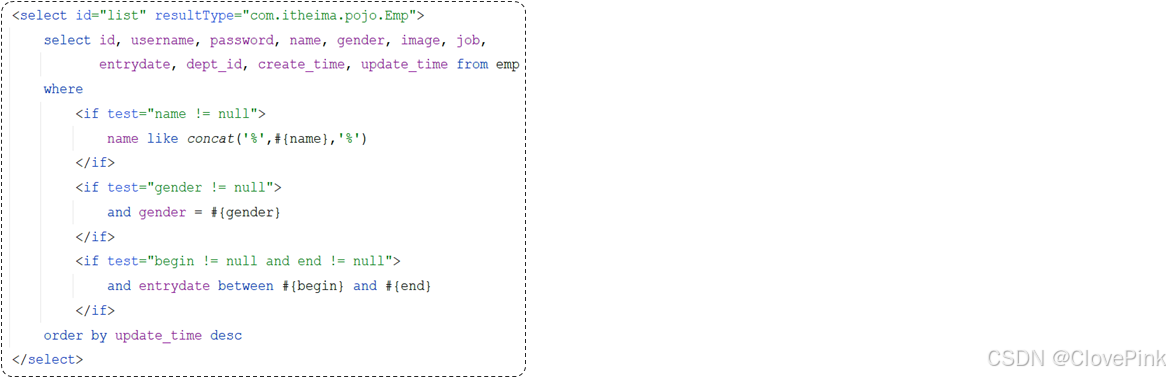
在员工管理的列表页面中,我们需要根据条件查询员工信息,查询条件包括:姓名、性别、入职时间。
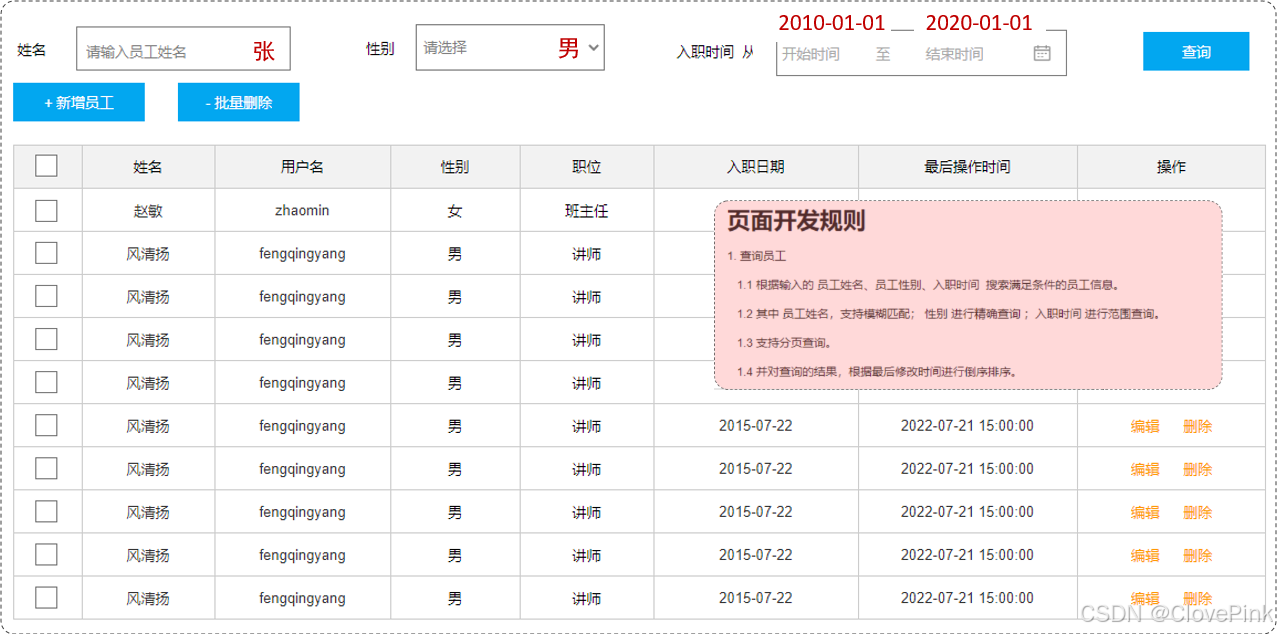
通过页面原型以及需求描述我们要实现的查询:
姓名:要求支持模糊匹配
性别:要求精确匹配
入职时间:要求进行范围查询
根据最后修改时间进行降序排序
SQL
语句:
select
id, username,
password
, name, gender, image, job, entrydate,
dept_id, create_time, update_time
from
emp
where
name
like
'%
张
%'
and
gender
=
1
and
entrydate
between
'2010-01-01'
and
'2020-01-01 '
order by
update_time
desc
;
接口方法:
方式一
@Mapper
public interface
EmpMapper
{
@Select
(
"select * from emp "
+
"where name like '%${name}%' "
+
"and gender = #{gender} "
+
"and entrydate between #{begin} and #{end} "
+
"order by update_time desc"
)
public
List
<
Emp
>
list
(
String
name
,
Short
gender
,
LocalDate begin
,
LocalDate end
);
}

以上方式注意事项:
1.
方法中的形参名和
SQL
语句中的参数占位符名保持一致
2.
模糊查询使用
${...}
进行字符串拼接,这种方式呢,由于是字符串拼接,并不是预编译的
形式,所以效率不高、且存在
sql
注入风险。
方式二(解决
SQL
注入风险)
使用
MySQL
提供的字符串拼接函数:
concat('%' , '
关键字
' , '%')
@Mapper
public interface
EmpMapper
{
@Select
(
"select * from emp "
+
"where name like concat('%',#{name},'%') "
+
"and gender = #{gender} "
+
"and entrydate between #{begin} and #{end} "
+
"order by update_time desc"
)
public
List
<
Emp
>
list
(
String
name
,
Short
gender
,
LocalDate
begin
,
LocalDate end
);
}
执行结果:生成的
SQL
都是预编译的
SQL
语句(性能高、安全)

3)XML映射文件
Mybatis
的开发有两种方式:
1.
注解
2. XML
使用
Mybatis
的注解方式,主要是来完成一些简单的增删改查功能。如果需要实现复杂的
SQL
功能,建议使用XML
来配置映射语句,也就是将
SQL
语句写在
XML
配置文件中。
在
Mybatis
中使用
XML
映射文件方式开发,需要符合一定的
规范
:
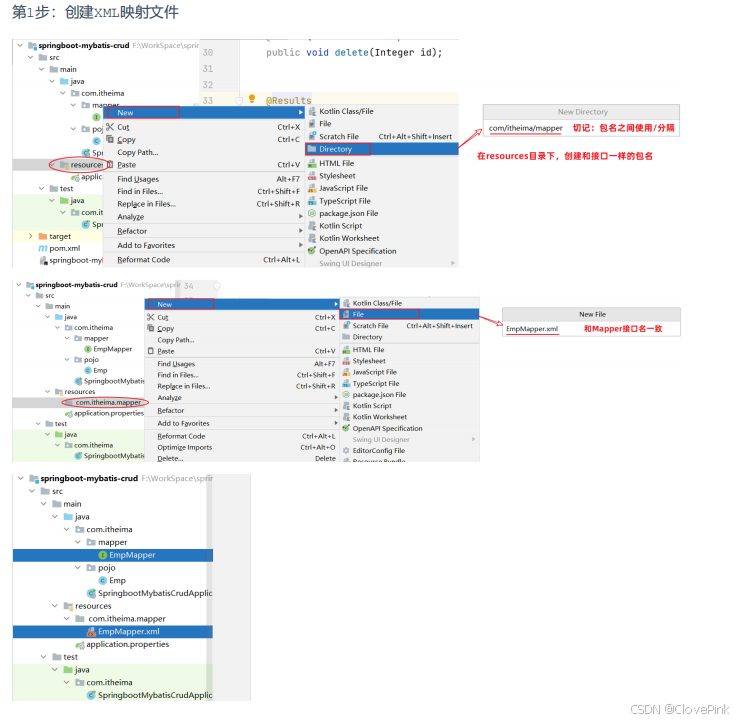
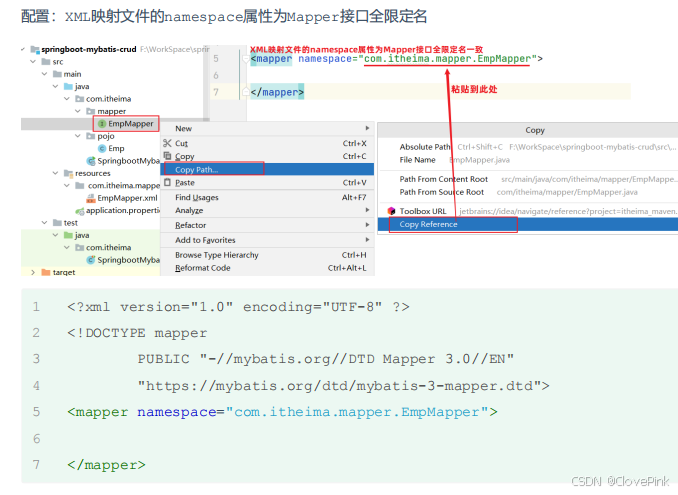
1. XML
映射文件的名称与
Mapper
接口名称一致,并且将
XML
映射文件和
Mapper
接口放置在相同包下
(同包同名)
2. XML
映射文件的
namespace
属性为
Mapper
接口全限定名一致
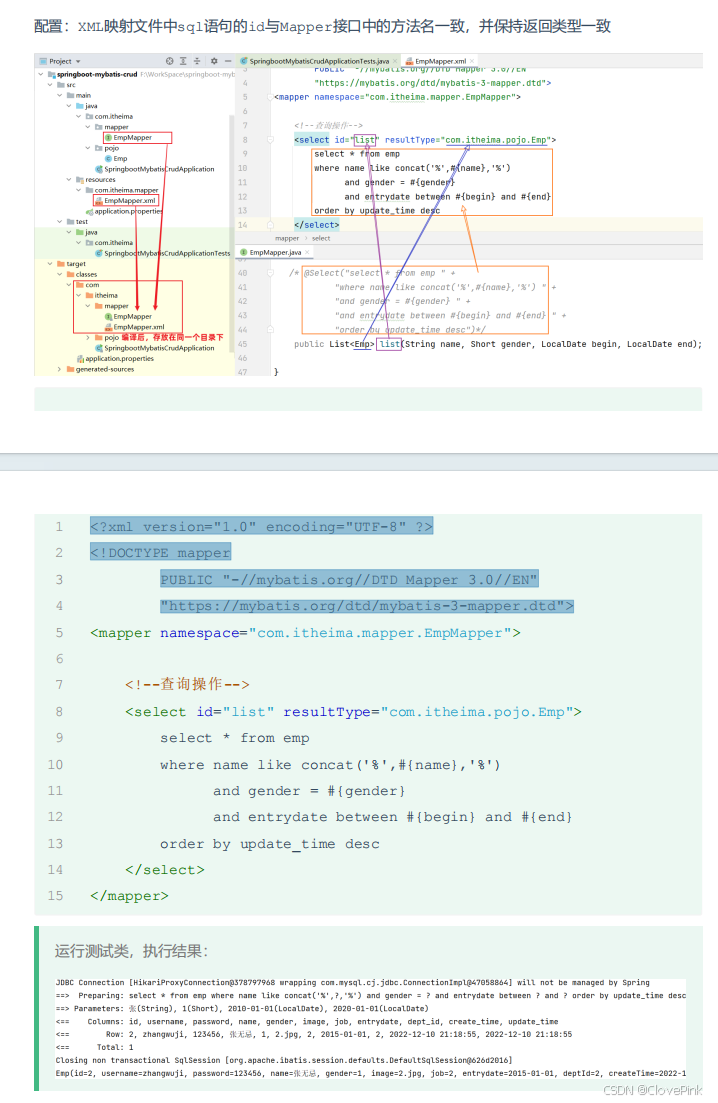
3. XML
映射文件中
sql
语句的
id
与
Mapper
接口中的方法名一致,并保持返回类型一致。
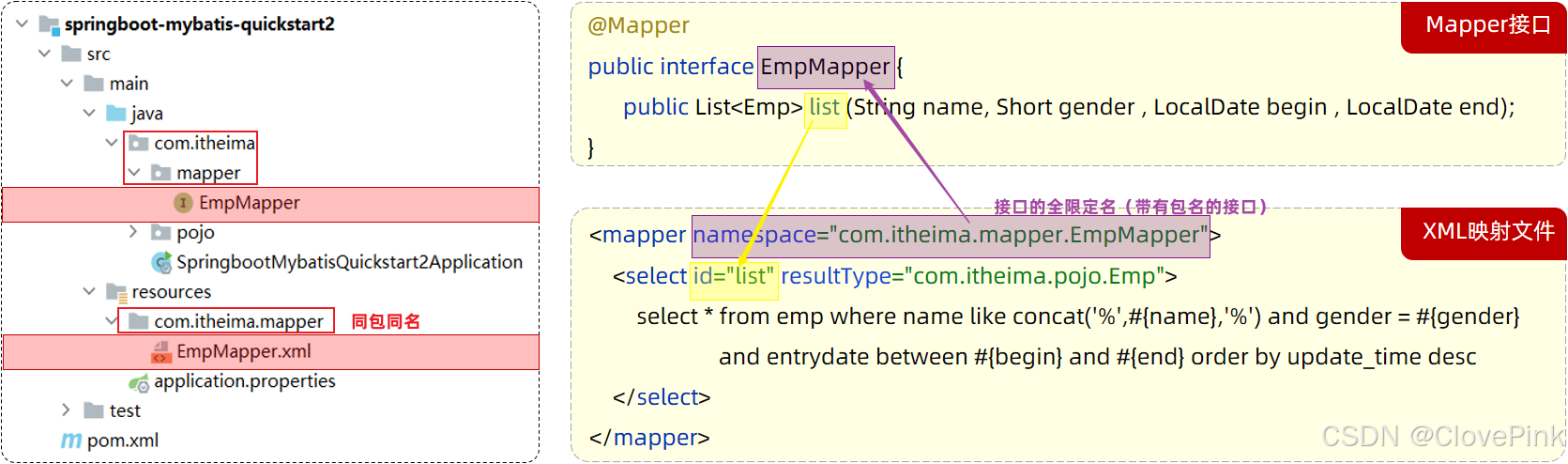
<select>
标签:就是用于编写
select
查询语句的。
resultType
属性,指的是查询返回的单条记录所封装的类型。
学习了
Mybatis
中
XML
配置文件的开发方式了,大家可能会存在一个疑问:到底是使用注解方式开发还是使用XML
方式开发?
结论:使用Mybatis
的注解,主要是来完成一些简单的增删改查功能。如果需要实现复杂的
SQL
功能,建议使用XML
来配置映射语句。
三、Mybatis动态SQL
 什么是动态SQL?
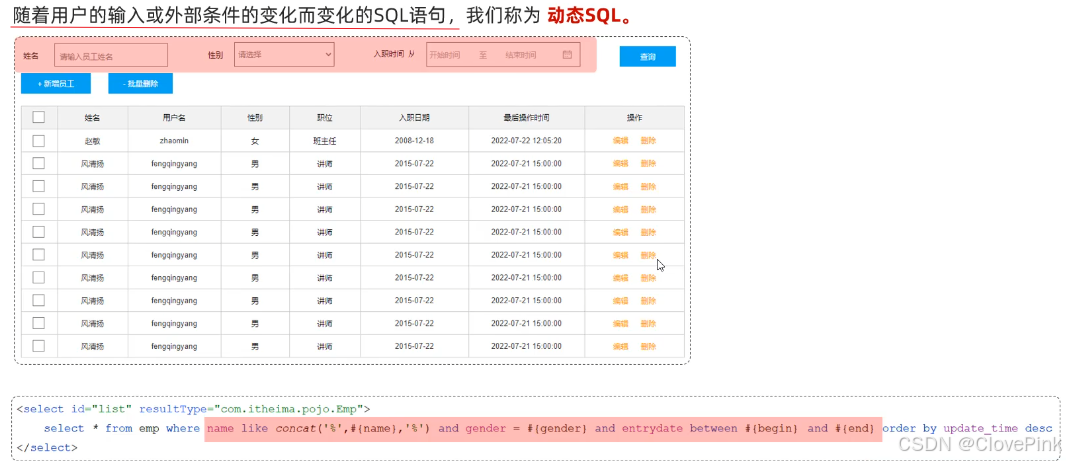
什么是动态SQL?
在页面原型中,列表上方的条件是动态的,是可以不传递的,也可以只传递其中的
1
个或者
2
个或者全部。

而在我们刚才编写的
SQL
语句中,我们会看到,我们将三个条件直接写死了。 如果页面只传递了参数姓名name
字段,其他两个字段性别和入职时间没有传递,那么这两个参数的值就是
null
。
此时,执行的
SQL
语句为:

这个查询结果是不正确的。正确的做法应该是:传递了参数,再组装这个查询条件;如果没有传递参数,就不应该组装这个查询条件。
比如:如果姓名输入了"
张
",
对应的
SQL
为
:
select
*
from
emp
where
name
like
'%
张
%'
order by
update_time
desc
;
如果姓名输入了
"
张
",
,性别选择了
"
男
"
,则对应的
SQL
为
:
select
*
from
emp
where
name
like
'%
张
%'
and
gender
=
1
order by
update_time
desc
;
SQL
语句会随着用户的输入或外部条件的变化而变化,我们称为:
动态
SQL
。
在
Mybatis
中提供了很多实现动态
SQL
的标签,我们学习
Mybatis
中的动态
SQL
就是掌握这些动态
SQL标签。
1、<if>
<if>
:用于判断条件是否成立。使用
test
属性进行条件判断,如果条件为
true
,则拼接
SQL
。
1
<if
test
=
"
条件表达式
"
>
2
要拼接的sql
语句
3
</if>


小结
<if>
用于判断条件是否成立,如果条件为true
,则拼接
SQL
形式:
<if
test
=
"name != null"
>
…
</if>
<where>
where元素只会在子元素有内容的情况下才插入
where
子句,而且会自动去除子句的开头的
AND或
OR
<set>
动态地在行首插入 SET
关键字,并会删掉额外的逗号。(用在
update
语句中)
2、<foreach>
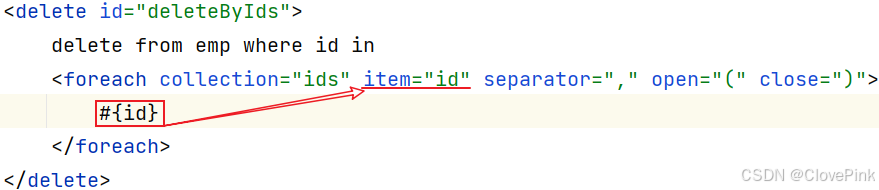
collection
=
"要遍历的
集合名称
"
item
=
"
集合遍历出来的元素
/
项
"
separator
=
"
每一次遍历使用的分隔符"
open
=
"
遍历开始前拼接的片段
"
close
=
"
遍历结束后拼接的片段
3、<sql> <include>
问题分析:
在
xml
映射文件中配置的
SQL
,有时可能会存在很多重复的片段,此时就会存在很多冗余的代码


我们可以对重复的代码片段进行抽取,将其通过
<sql>
标签封装到一个
SQL
片段,然后再通过
<include>
标签进行引用。
<sql>
:定义可重用的
SQL
片段
<include>
:通过属性
refid
,指定包含的
SQL
片段
SQL
片段: 抽取重复的代码
1
<sql
id
=
"commonSelect"
>
2
select id, username, password, name, gender, image, job,
entrydate, dept_id, create_time, update_time from emp
3
</sql>
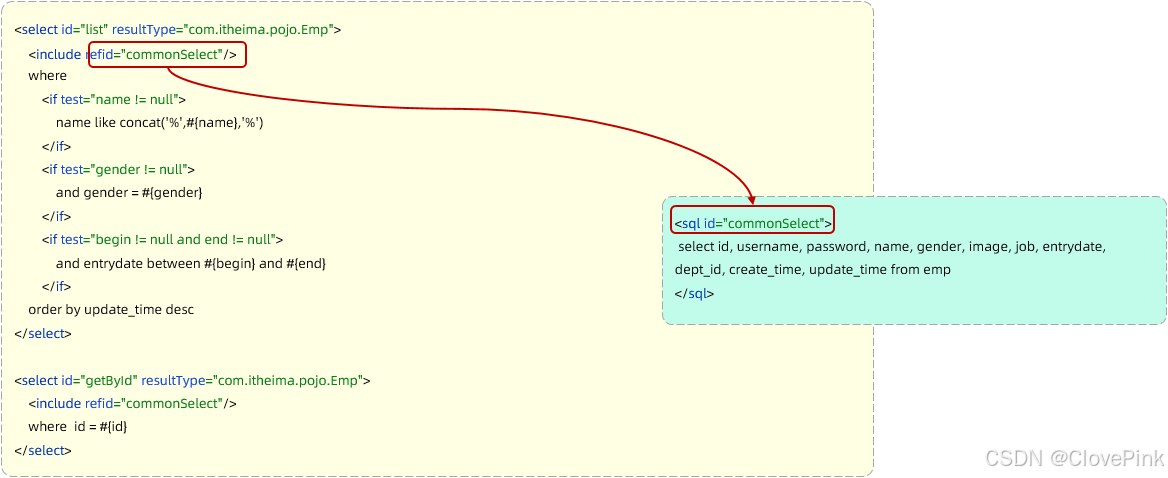
然后通过
<include>
标签在原来抽取的地方进行引用。操作如下:
<select
id
=
"list"
resultType
=
"com.itheima.pojo.Emp"
>
<include
refid
=
"commonSelect"
/>
<where>
<if
test
=
"name != null"
>
name like concat('%',#{name},'%')
</if>
<if
test
=
"gender != null"
>
and gender = #{gender}
</if>
<if
test
=
"begin != null and end != null"
>
and entrydate between #{begin} and #{end}
</if>
</where>
order by update_time desc
</select>

















 2101
2101

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









