






 本文深入探讨了Java编程中的面向对象概念,包括继承、封装、多态和抽象的特性,并对比了基本类型int与包装类Integer的区别。接着,详细阐述了==与equals的区别,以及ArrayList和LinkedList在数据结构和操作效率上的差异。此外,重点讲解了反射机制,解释了其在运行时动态加载类、创建对象和调用方法的能力,以及在实际应用如数据库驱动加载和Spring框架中的作用。最后,举例说明了反射在程序设计中的实用性,如动态实例化类。
本文深入探讨了Java编程中的面向对象概念,包括继承、封装、多态和抽象的特性,并对比了基本类型int与包装类Integer的区别。接着,详细阐述了==与equals的区别,以及ArrayList和LinkedList在数据结构和操作效率上的差异。此外,重点讲解了反射机制,解释了其在运行时动态加载类、创建对象和调用方法的能力,以及在实际应用如数据库驱动加载和Spring框架中的作用。最后,举例说明了反射在程序设计中的实用性,如动态实例化类。
目录
你是怎样理解面向对象的?
面向对象是利于语言对现实事物进行抽象。面向对象具有以下四大特征:
(1)继承:继承是从已有类得到继承信息创建新类的过程;
(2)封装:通常认为封装是把数据和操作数据的方法绑定起来,对数据的访问只能通过已定义的接口;
(3)多态:多态性是指允许不同子类型的对象对同一消息作出不同的响应;
(4)抽象:抽象是将一类对象的共同特征总结出来构造类的过程,包括数据抽象和行为抽象两方面。
int和Integer有什么区别?
(1)Integer是int的包装类,int是Java的一种基本数据类型;
(2)Integer变量必须实例化后才能使用,而int变量不需要;
(3)Integer实际是对象的引用,当new一个Integer时,实际上是生成一个指针指向此对象;而int则是直接存储数据值;
(4)Integer的默认值是null,int的默认值是0;(Integer可以区分出未赋值和值为0的区别,int则无法表达出未赋值的情况,例如,要想表达出没有参加考试和考试成绩为0的区别,则只能使用Integer)
(5)java在编译Integer i = 100 ;时,会翻译成为Integer i = Integer.valueOf(100)。而java API中对Integer类型的valueOf的定义如下,对于-128到127之间的数,会进行缓存,Integer i = 127时,会将127这个Integer对象进行缓存,下次再写Integer j = 127时,就会直接从缓存中取,就不会new了
==和Equals的区别
(1) ==
如果比较的是基本数据类型,那么比较的是变量的值;
如果比较的是引用数据类型,那么比较的是地址值(两个对象是否指向同一块内存)。
(2) equals
如果没重写equals方法,比较的是两个对象的地址值;
如果重写了equals方法,往往比较的是对象中的属性的内容;
equals方法是从Object类中继承的,默认的实现就是使用==。
public boolean equals(Object obj) {
return (this == obj);
}相关页面:== 和 equals 的区别是什么?
要点:对象类型不同,比较的对象不同(见上)和运行速度不同
对象类型:
1、equals():是超类Object中的方法。
2、==:是操作符(关系运算符)。
运行速度:==比equals()快,因为==只是比较引用。
谈谈你对反射的理解
(1)反射机制:
所谓的反射机制就是java语言在运行时拥有一项自观的能力。通过这种能力可以彻底地了解自身的情况为下一步的动作做准备。
Java的反射机制的实现要借助于4个类:Class,Constructor,Field,Method;
其中,Class代表的是类对象,Constructor-类的构造器对象,Field-类的属性对象,Method-类的方法对象。通过这四个对象我们可以粗略地看到一个类的各个组成部分。
(2)Java反射的作用:
在Java运行时环境中,
对于任意一个类,可以知道这个类有哪些属性和方法。
对于任意一个对象,可以调用它的任意一个方法。这种动态获取类的信息以及动态调用对象的方法的功能来自于Java 语言的反射(Reflection)机制。
(3)Java反射机制提供的功能
在运行时判断任意一个对象所属的类。
在运行时构造任意一个类的对象。
在运行时判断任意一个类所具有的成员变量和方法。(延申:Java属性和成员变量的区别)
在运行时调用任意一个对象的方法。
相关页面:学习java应该如何理解反射?
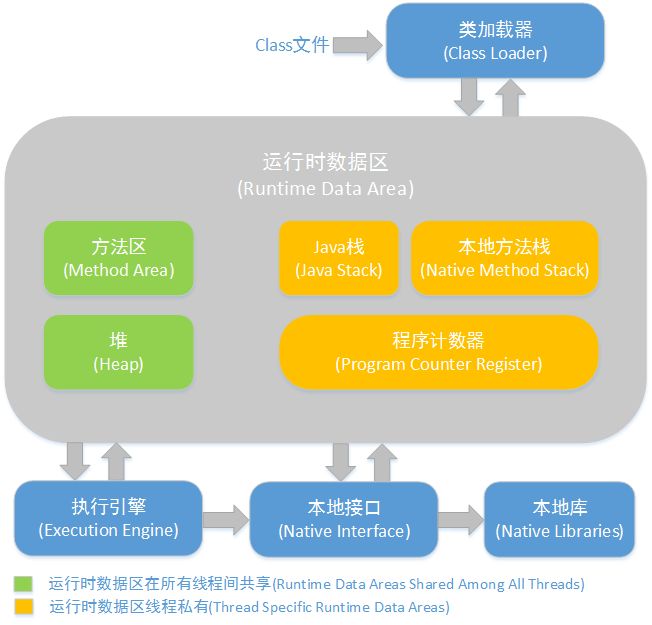
假如你写了一段代码:
Object o = new Object();运行了起来!
首先JVM会启动,代码会编译成一个.class文件,然后被类加载器加载进jvm的内存中,类Object加载到方法区中,创建了Object类的class对象到堆中,注意这个不是new出来的对象,而是类的类型对象,每个类只有一个class对象,作为方法区类的数据结构的接口。jvm创建对象前,会先检查类是否加载,寻找类对应的class对象,若加载好,则为对象分配内存,初始化也就是代码:new Object()。
上面的流程就是你自己写好的代码扔给jvm去跑,跑完就over了,jvm关闭,你的程序也停止了。
为什么要讲这个呢?因为要理解反射必须知道它在什么场景下使用。
上面的程序对象是自己new的,程序相当于写死了给jvm去跑。假如一个服务器上突然遇到某个请求要用到某个类,但没加载进jvm,是不是要停下来自己写段代码,new一下,启动一下服务器。
反射是什么呢?程序运行时,需要动态地加载一些类,这些类可能之前用不到,所以不用加载到jvm,而是在运行时根据需要加载,这样的好处对于服务器来说不言而喻,举个例子我们的项目底层有时用mysql,有时用oracle,需要动态地根据实际情况加载驱动类,这个时候反射就有用了,假设 com.java.dbtest.myqlConnection,com.java.dbtest.oracleConnection这两个类我们要用,这时,程序就写得比较动态化,通过Class tc = Class.forName("com.java.dbtest.TestConnection");通过类的全类名让jvm在服务器中找到并加载这个类,而如果是oracle则传入的参数就变成另一个了。这时候就可以看到反射的好处了,这个动态性就体现出java的特性了!举多个例子,大家如果接触过spring,会发现当你配置各种各样的bean时,是以配置文件的形式配置的,你需要用到哪些bean就配哪些,spring容器就会根据你的需求去动态加载,你的程序就能健壮地运行。
答案比较粗糙,点到为止!
更新一个实例辅助更好地理解
在使用Spring写业务代码的时候,我们经常会用到注解来进行类的实例化,我们自定义一个注解
GPService
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface GPService {
String value() default "";
}我们的业务类QuerySerivce,这里就是模拟Spring的Service注解,我们用一个自定义注解。
@GPService
public class QuerySerivce implements IQueryService {
public String query(String name) {
return "query service result";
}
}然后我们在容器初始化的时候,我们需要扫描标有service注解的类,然后实例化后放进容器内。大概的代码如下:
//拿到全类名,用于定位类,这一步一般Spring是通过扫描项目路径来获取,这一步是动态获取的,反射的作用其实就在这里,思考下如果不用反射,我们要怎么实例化,不可能一个类一个类去定位,然后实例化
String className = "com.demo.QueryService";
//反射获取类的Class对象
Class<?> clazz=Class.forName(className);
//如果该类标注有GPService注解,我们就实例化这个类
if(clazz.isAnnotationPresent(GPService.class){
Object instance = clazz.newInstance();
//用map来模拟容器
map.put(clazz.getSimpleName(),instance);
}ArrayList和LinkedList区别
(1)ArrayList是实现了基于动态数组(可以动态修改的数组)的数据结构,LinkedList基于链表的数据结构。
(2)对于随机访问get和set,ArrayList优于LinkedList,因为LinkedList要移动指针。
(3)对于新增和删除操作add和remove,LinkedList比较占优势,因为ArrayList要移动数据。 这一点要看实际情况的。若只对单条数据插入或删除,ArrayList的速度反而优于LinkedList。但若是批量随机地插入删除数据,LinkedList的速度大大优于ArrayList,因为ArrayList每插入一条数据,要移动插入点及之后的所有数据。

















 75万+
75万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









