




除了在训练本身所面临的工程化难度和挑战外,也想从围绕大模型另外几个技术挑战做些补充:

数据之难:难在对数据分布本身的理解和掌握,数据或信息是对真实世界诸多现象的某种映射和表征,这种映射可以以投影在生物体中的大脑神经元激活的的形式表征 也可以以编码的形式存在于机器中,对数据的充分理解与洞察,才能更好驱动个体去完成融入真实世界的决策、行动、反馈当中来。而不管是“碳基”也好还是“硅基”也罢,在理解和掌握繁杂的数据与信息过程中均会面对噪音干扰、分布平衡、语义表征维度的熵增熵减等各种复杂而抽象过程性问题。当然这对于一个努力实现AGI的LLM来说难度和挑战是显而易见的,它来自于世界的复杂本身。
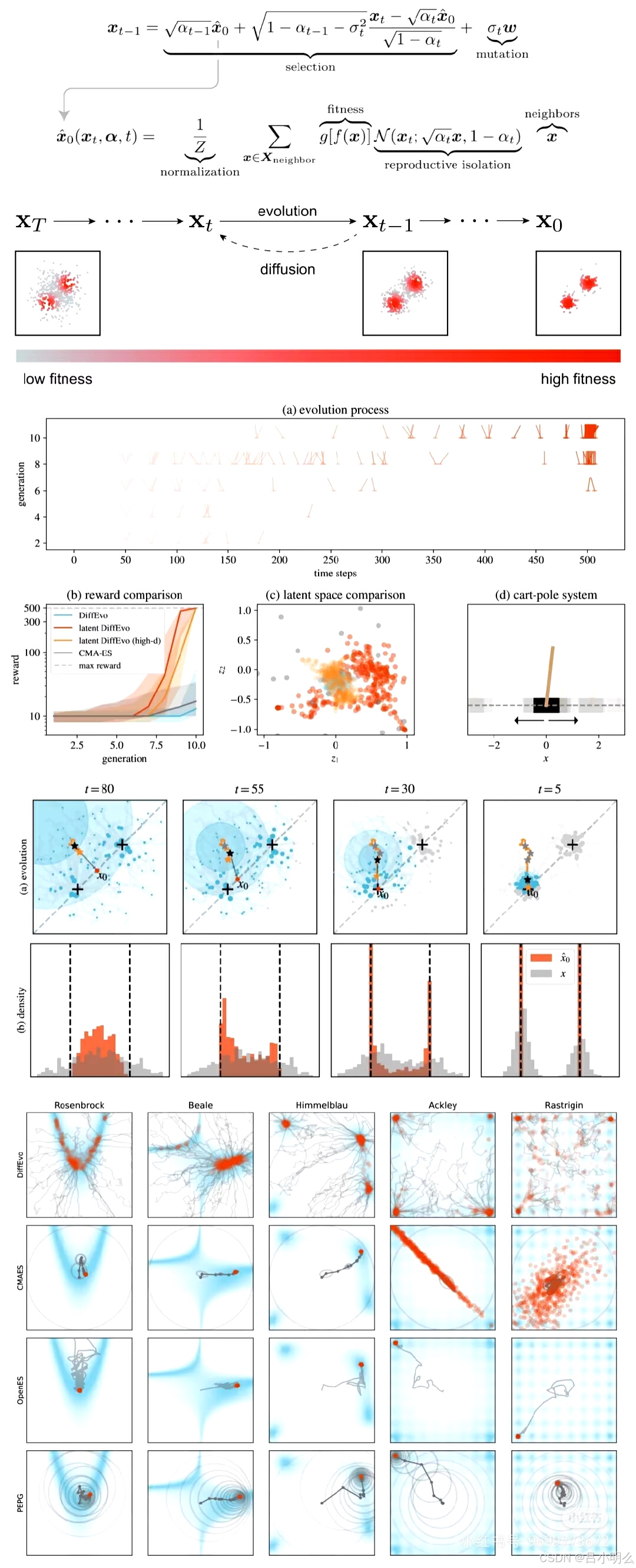
算法之难:这里其实包含了两种算法维度,一种是比较偏宏观的训练与推理范式上的算法或者说方法;一种是深入模型内部结构的算法或者说数学思想与内涵。而两者之间又存在着诸多联系和影响,当然也即可以完整统一的来看也可以进一步将其中的每一个环节掰开揉碎组合来看,比如:以chatGPT为代表的LLM与传统NLP或领域小模型在整体模型训练与推理范式上的方法,包含了生成式、预训练、tokenize、无监督等思想和方法联合创新运用;再比如对于另一学习范式取得很大成功的RL来说,其中的训练范式和思想方法似乎与LLM间表面上存在着非常大的差异但两者背后也许存下着很多联系和共性,同时RL内部本身亦参考依赖诸如博弈论、拓补学、微分几何等诸多数学思想和方法。其中所体现出的奥秘和复杂性亦可见一斑。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2501
2501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









