




简介:有向无环图(DAG)是一种图结构,它在图论和计算机科学中应用广泛。拓扑排序是一种重要的操作,它按照一定顺序排列DAG中的节点。在进行拓扑排序时,必须确保图中不存在环。本文介绍了如何通过深度优先搜索(DFS)检测图中是否有环,并在存在环的情况下输出环的信息。若图是DAG,则可以进行拓扑排序。拓扑排序的常见方法之一是使用广度优先搜索(BFS)。文章提供了基本的DFS算法实现,以及如何使用邻接矩阵或邻接表来存储图的数据结构。拓扑排序与环检测在编译器依赖分析和项目管理任务调度等实际应用中非常重要。
1. 有向无环图(DAG)的定义及应用
有向无环图(DAG)是一种图形数据结构,其中顶点用有向边相互连接,但没有任何一条边的起点和终点相同,形成闭环。DAG在数据结构和算法中拥有广泛的应用,因为它们可以有效地表示各种实体之间的依赖关系。
1.1 DAG的基本定义
在DAG中,顶点(节点)代表实体,边代表实体间的依赖关系。它不能包含任何循环依赖,这是因为如果存在循环依赖,就无法确定实体间的处理顺序,从而导致无限循环。DAG在解决此类问题时特别有用,因为它能帮助我们定义一个明确的顺序,确保每个节点在依赖它的节点之后处理。
1.2 DAG的应用领域
DAG的应用领域极为广泛,它在多个行业中都是解决问题的重要工具。例如,在软件开发中,可以使用DAG表示模块间的依赖关系;在区块链技术中,它被用来构建交易的区块;而在任务调度系统中,DAG可以优化工作流程和任务的执行顺序。
1.3 DAG的优化和查询
随着应用场景的复杂化,如何有效优化和查询DAG成为了一个研究热点。通过优化,可以减少执行时间,提高系统的效率。例如,通过拓扑排序可以获取节点处理的合理顺序,而通过特定算法如Kahn算法,可以高效地检测图中是否存在环,这对于维持DAG的特性至关重要。这些优化和查询技术,最终服务于提高处理效率和系统性能。
2. 拓扑排序的概念和重要性
拓扑排序是图论中的一个基础概念,尤其在有向无环图(DAG)中具有重要的应用。本章节将详细介绍拓扑排序的基本原理和实际意义,并通过案例展示其在项目管理和编译器构建中的关键作用。
2.1 拓扑排序的基本原理
2.1.1 拓扑排序的定义
拓扑排序是针对DAG的一种排序,它会将图中的所有顶点线性排序,使得对于任意一条从顶点u到顶点v的有向边(u, v),顶点u都在顶点v之前。这样的排序不是唯一的,但每个有效的拓扑排序都反映了图中各顶点之间的依赖关系。若图中存在环,则无法进行拓扑排序,因为环中的节点无法满足上述排序条件。
2.1.2 拓扑排序的性质和目的
拓扑排序的性质保证了图中不存在回路,这一特性对于理解复杂系统的依赖关系非常有帮助。例如,在课程安排中,若一门课程是另一门课程的先决条件,则先决课程必须在后者之前被教授。拓扑排序的目的就是找到这样一种顶点顺序,以反映和满足依赖关系。
2.2 拓扑排序的实际意义
2.2.1 在项目管理中的应用
在项目管理中,拓扑排序可以帮助项目负责人理解任务的依赖性,并据此安排合理的执行顺序。这种排序方式可以清晰地指示哪些任务必须先完成,哪些任务可以同时进行,从而优化资源分配,确保项目按计划高效推进。
2.2.2 在编译器构建中的作用
在编译器的构建过程中,源代码通常会被分解成多个模块,这些模块之间存在依赖关系。通过拓扑排序,编译器可以确定编译的顺序,确保在编译一个模块之前,它的所有依赖模块已经先被编译,从而保证编译过程的顺利进行。
在下一章节中,我们将探讨如何检测DAG中是否存在环,这对于确保拓扑排序的可行性至关重要。
3. 检测DAG中是否存在环的方法
在图论和相关领域中,检测有向无环图(DAG)中是否存在环是基础且至关重要的问题。这不仅关系到图结构的稳定性,而且与算法效率、存储成本以及实际应用息息相关。
3.1 环的基本理论
3.1.1 环的定义和特征
在DAG中,环通常指的是从某个顶点出发,经过一系列边的跳转后,再次回到该顶点的路径,而这条路径上的每一条边都被经过且仅被经过一次。在有向图中,环的出现意味着存在一种逻辑关系或者流程无法顺利执行,因为它们形成了一个循环依赖。
环的存在可能会影响数据处理的流程,使得程序或者算法无法继续执行或者陷入无限循环。因此,在许多实际应用中,例如工作流程管理系统、编译器依赖关系处理等领域,必须保证数据结构是无环的。
3.1.2 环在图论中的重要性
环在图论中的重要性是显而易见的。首先,在理论研究方面,有环的图与无环的图在性质上有很大差异,许多图论定理的证明依赖于无环这个条件。其次,在实际应用中,如前文所述,环的存在可能导致各种问题。
环还与图的连通性、连通分量、强连通分量(SCC)等概念密切相关,强连通分量检测通常需要先识别图中的环。因此,环检测是图论算法中一个基础而核心的部分。
3.2 环检测算法
3.2.1 深度优先搜索(DFS)环检测
DFS算法是检测图中是否存在环的一种高效算法,其核心思想是遍历图中的节点,在遍历过程中使用标记来记录访问状态,从而检测到回路。在DFS遍历中,有三种节点状态:未访问、访问中、已访问。
算法步骤如下:
1. 从任意顶点开始,将其状态设为“访问中”,并开始DFS遍历。
2. 遍历当前顶点的所有邻接节点,如果邻接节点未被访问,递归访问之,并将其标记为“访问中”。
3. 如果邻接节点已被标记为“访问中”,则说明发现回路,即检测到环。
4. 如果邻接节点已被标记为“已访问”,则忽略,继续检查下一个邻接节点。
5. 当当前顶点的所有邻接节点都被访问后,将其状态设为“已访问”,回溯至上一层。
下面是使用DFS进行环检测的Python代码示例:
def dfs(graph, v, visited, recStack):
# 标记当前节点为已访问
visited[v] = True
recStack[v] = True
# 遍历所有邻接节点
for neighbour in graph[v]:
if visited[neighbour] == False:
if dfs(graph, neighbour, visited, recStack):
return True
elif recStack[neighbour]:
return True # 发现环
# 当前节点的所有邻接节点遍历完毕,设置为未在递归栈中
recStack[v] = False
return False
def isCyclic(graph):
visited = [False] * len(graph)
recStack = [False] * len(graph)
for node in range(len(graph)):
if visited[node] == False:
if dfs(graph, node, visited, recStack):
return True
return False
3.2.2 拓扑排序与环检测的关系
拓扑排序是针对DAG的操作,它可以将图中的顶点排成一个线性序列,使得对于任何一条有向边(u, v),顶点u都在顶点v之前。如果图中存在环,则无法进行拓扑排序。因此,环检测常常是拓扑排序前的必要步骤。
拓扑排序的执行过程实际上是识别DAG中所有顶点的入度,将入度为0的顶点添加到排序结果中,并移除这些顶点及其相关的边,更新其他顶点的入度。如果在排序结束时,图中还有顶点,则说明图中存在环。
综合来看,环检测是许多图算法得以顺利执行的前提条件,也是图理论研究的基础。掌握环检测的各种方法,对于深入理解图论算法和解决实际问题具有重要价值。
4. DFS在环检测中的应用
深度优先搜索(DFS)算法在环检测中的应用是一个经典问题,它通过递归或栈的方式,遍历图中的所有节点,并检测是否存在环。本章将详细探讨DFS的工作原理、在环检测中的具体实现,以及处理复杂图结构的策略。
4.1 DFS算法原理
4.1.1 DFS的工作过程
DFS算法是一种用于遍历或搜索树或图的算法。在图中使用DFS时,算法从一个顶点开始,沿着一条边尽可能深地进入图,直到不能再深入为止,然后回溯到前一个节点,选择另一条边继续探索,直到所有的节点都被访问为止。
4.1.2 DFS与图的遍历
DFS的实现通常是递归的,但也可以用栈来模拟。在遍历过程中,算法会访问图中的所有节点,并可以对这些节点进行标记,例如,使用一个数组来记录节点的访问状态,以避免重复访问同一个节点。状态可以是三种:未访问(WHITE)、已访问但未完全探索(GRAY)、完全探索(BLACK)。这种标记策略有助于在算法的实现中检测出图中是否存在环。
4.2 DFS在环检测的具体实现
4.2.1 算法步骤和示例
为了在图中检测环,DFS算法的每一步都涉及以下步骤:
- 选择一个未访问的节点,将其标记为GRAY,并将其加入到当前的路径中。
- 对于该节点的每一个相邻节点,如果它未被访问(WHITE),则递归地继续DFS过程。
- 如果相邻节点已被访问但仍在当前路径中(GRAY),则存在一个环。
- 如果相邻节点已被完全探索(BLACK),则忽略,继续对其他相邻节点进行操作。
- 当当前节点的相邻节点都被访问后,将其标记为BLACK,表示它已被完全探索。
下面是一个使用Python实现DFS检测有向图中环的代码示例:
def dfs(graph, node, visited, rec_stack):
visited[node] = True
rec_stack[node] = True
for neighbour in graph[node]:
if not visited[neighbour]:
if dfs(graph, neighbour, visited, rec_stack):
return True
elif rec_stack[neighbour]:
return True
rec_stack[node] = False
return False
def is_cyclic(graph):
visited = {k: False for k in graph}
rec_stack = {k: False for k in graph}
for node in graph:
if not visited[node]:
if dfs(graph, node, visited, rec_stack):
return True
return False
# 示例图
graph = {
'A': ['B', 'C'],
'B': ['D', 'E'],
'C': ['F'],
'D': [],
'E': ['F'],
'F': []
}
print(is_cyclic(graph)) # 输出结果:False
4.2.2 处理复杂图结构的策略
对于复杂图结构的环检测,需要额外考虑的策略包括:
- 处理有向无环图(DAG)时,可能需要记录节点的入度和出度,以优化算法性能。
- 对于加权图或者需要计算距离的场景,可以使用带权DFS。
- 在检测大规模网络时,可能需要使用并行或分布式DFS算法来提高效率。
- 在实际应用中,环检测算法可能需要与其他算法(例如贪心算法、动态规划等)结合使用,以解决更复杂的问题。
在处理大型图或复杂网络时,优化算法性能是实现快速环检测的关键。实际操作中,可以采用多线程或分布式计算技术,通过并行处理节点以降低计算复杂度。在某些特定场景,如社交网络分析,可以利用图数据库和它们内建的环检测功能,从而提高处理效率。
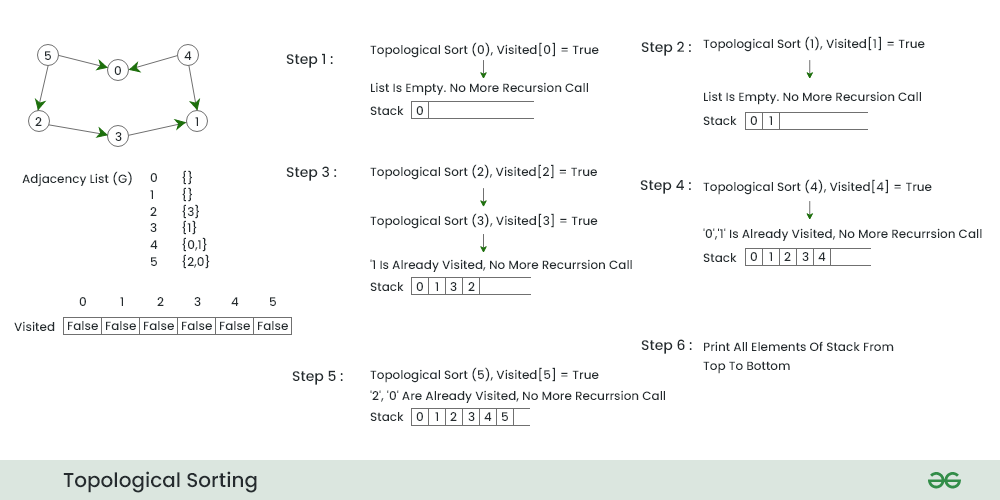
5. DAG无环时的拓扑排序方法
拓扑排序是一种将有向无环图(DAG)中的顶点线性排序的算法,使得对于任意一条有向边(u, v),顶点u都出现在顶点v之前。拓扑排序的结果并不是唯一的,但每个有效的排序都可以为理解图的依赖关系提供重要的信息。
5.1 无环图拓扑排序步骤
无环图的拓扑排序通常使用深度优先搜索(DFS)或广度优先搜索(BFS)实现。在本章节中,我们将探讨基于邻接表和邻接矩阵的排序步骤。
5.1.1 基于邻接表的排序过程
在邻接表表示法中,图由节点和与之相连的边列表组成。以下是基于邻接表的拓扑排序的步骤:
- 对于每个节点,计算其入度(即有多少条边指向该节点)。
- 将所有入度为零的节点放入一个队列中。
- 当队列非空时,重复以下步骤:
- 取出队列中一个节点,并将其加入到排序结果中。
- 遍历该节点的邻接表,将所有相邻节点的入度减一。
- 若相邻节点的入度减为零,则将其加入到队列中。 - 如果排序结果中的节点数等于图中节点总数,则排序完成。否则,图中存在环,无法进行拓扑排序。
5.1.2 基于邻接矩阵的排序过程
在邻接矩阵表示法中,图由一个二维数组表示,其中元素值为1表示节点之间存在边,否则为0。基于邻接矩阵的拓扑排序步骤如下:
- 计算每行的和,即为每个节点的入度。
- 创建一个队列,并将所有入度为零的节点加入队列。
- 当队列非空时,重复以下步骤:
- 取出队列中的一个节点,并将其加入到排序结果中。
- 将该节点的行中所有为1的列对应的节点的入度减一。
- 若任何节点的入度减为零,则将其加入队列。 - 如果排序结果中的节点数等于图中节点总数,则排序成功。否则,图中存在环。
5.2 拓扑排序的代码实现
下面的示例代码将展示如何使用Python实现基于邻接表的拓扑排序。
5.2.1 编程语言选择与环境搭建
选择Python作为示例编程语言,因为它简洁易懂,适合算法实现。在开始编码前,确保你的环境已安装Python,并且可以选择一个合适的IDE进行开发。
5.2.2 关键代码解析与演示
from collections import defaultdict, deque
# 定义图结构
class Graph:
def __init__(self, vertices):
self.graph = defaultdict(list) # 邻接表
self.V = vertices
# 添加边到图中
def addEdge(self, u, v):
self.graph[u].append(v)
# 执行拓扑排序算法
def topologicalSort(self):
in_degree = [0] * self.V # 存储所有顶点的入度数
# 计算每个顶点的入度数
for i in self.graph:
for j in self.graph[i]:
in_degree[j] += 1
# 初始化队列并添加入度为0的顶点
queue = deque()
for i in range(self.V):
if in_degree[i] == 0:
queue.append(i)
# 存储排序结果
top_order = []
# 循环直到队列为空
while queue:
# 取出一个顶点
u = queue.popleft()
top_order.append(u)
# 对每个邻接点减小入度,并检查是否为0
for i in self.graph[u]:
in_degree[i] -= 1
if in_degree[i] == 0:
queue.append(i)
# 检查是否所有顶点都被访问过,否则存在环
if len(top_order) != self.V:
print("存在环,无法进行拓扑排序")
return
# 打印拓扑排序结果
print(top_order)
# 示例使用
g = Graph(6)
g.addEdge(5, 2)
g.addEdge(5, 0)
g.addEdge(4, 0)
g.addEdge(4, 1)
g.addEdge(2, 3)
g.addEdge(3, 1)
print("拓扑排序结果:")
g.topologicalSort()
代码逻辑分析:
-
Graph类表示图,并使用邻接表作为内部数据结构。 -
addEdge方法用于向图中添加边。 -
topologicalSort方法执行拓扑排序算法。首先计算所有顶点的入度数,并将入度为零的顶点加入队列。 - 通过一个循环,每次从队列中取出一个顶点,并将其加入到排序结果列表中,同时遍历该顶点的所有邻接点,将邻接点的入度数减一,若邻接点的入度变为零,则加入队列。
- 最后检查排序结果的长度是否等于顶点数量,若不等则说明图中存在环,无法完成拓扑排序。
在上述代码中,图的节点数量 V 以及边的添加是根据实际情况来设定的。每个 addEdge 调用添加一条边到图中,并更新所有相关顶点的入度。
通过这个算法,我们可以得到一个合法的拓扑排序,或者识别出图中存在环。对于有向无环图(DAG),这个排序是有效的,并可以用来解决诸如课程安排和项目管理中依赖关系的问题。
6. 使用BFS进行拓扑排序的步骤
在有向无环图(DAG)中,进行拓扑排序是管理依赖关系或确定任务执行顺序的重要过程。与深度优先搜索(DFS)不同,广度优先搜索(BFS)提供了一种不同的方法来进行排序。BFS的核心思想是按照顶点的入度进行排序,确保每当一个顶点被访问时,其所有依赖的顶点都已经处理完毕。
6.1 BFS算法概述
6.1.1 BFS的特点和适用场景
BFS算法在图论中是一种基础的遍历算法,它从一个指定的起始节点出发,逐层向外扩展访问所有未被访问过的节点。BFS的特点是使用队列数据结构来追踪待访问的节点,并且最先访问到的节点是离起始节点最近的。BFS适用于那些需要找到从起始节点到其他所有节点的最短路径的场景,以及进行层次遍历的场合。
6.1.2 BFS与其他图遍历算法的比较
相较于DFS,BFS能更有效地找到最短路径,因为它首先访问距离起始点较近的节点。然而,对于非树形结构或需要找到所有可能路径的场景,DFS可能更为合适。BFS的内存消耗通常高于DFS,因为它需要记录所有待访问的节点。而在拓扑排序中,BFS能够提供一个更高效的排序方法,尤其是在顶点的入度分布不均匀时。
6.2 BFS在拓扑排序中的应用
6.2.1 排序的具体实现方法
使用BFS进行拓扑排序的关键在于按照顶点的入度进行排序。具体步骤如下:
- 计算图中每个顶点的入度。
- 将所有入度为0的顶点放入一个队列中。
- 当队列非空时,重复执行以下操作:
- 取出队列前端的顶点,并将其输出或标记为已访问。
- 遍历该顶点指向的所有邻接顶点,将这些邻接顶点的入度减1。
- 如果邻接顶点的入度变为0,则将其加入队列。
6.2.2 代码实现与案例分析
以下是使用Python实现BFS拓扑排序的代码示例:
from collections import deque, defaultdict
# 创建图
graph = defaultdict(list)
indegree = defaultdict(int)
# 假设这是DAG的边
edges = [
('A', 'B'),
('A', 'C'),
('B', 'D'),
('B', 'E'),
('C', 'F')
]
# 初始化图并计算入度
for edge in edges:
parent, child = edge
graph[parent].append(child)
indegree[child] += 1
# 创建一个队列用于BFS
queue = deque([k for k in indegree if indegree[k] == 0])
# 进行拓扑排序
sorted_elements = []
while queue:
current_node = queue.popleft()
sorted_elements.append(current_node)
for neighbor in graph[current_node]:
indegree[neighbor] -= 1
if indegree[neighbor] == 0:
queue.append(neighbor)
print("拓扑排序的结果:", sorted_elements)
案例分析:
上述代码中,我们首先创建了一个DAG并初始化了顶点的入度。接着,我们创建了一个队列并将所有入度为0的顶点加入。通过BFS算法,我们不断从队列中取出节点,并更新其邻接节点的入度,当邻接节点入度变为0时,将其加入队列。最终, sorted_elements 列表中存储的就是按拓扑顺序排序的节点列表。
通过这个案例,我们可以看到BFS算法在处理DAG拓扑排序时的高效性与简洁性,尤其是当图中存在大量的节点和边时,BFS可以快速地进行排序。
简介:有向无环图(DAG)是一种图结构,它在图论和计算机科学中应用广泛。拓扑排序是一种重要的操作,它按照一定顺序排列DAG中的节点。在进行拓扑排序时,必须确保图中不存在环。本文介绍了如何通过深度优先搜索(DFS)检测图中是否有环,并在存在环的情况下输出环的信息。若图是DAG,则可以进行拓扑排序。拓扑排序的常见方法之一是使用广度优先搜索(BFS)。文章提供了基本的DFS算法实现,以及如何使用邻接矩阵或邻接表来存储图的数据结构。拓扑排序与环检测在编译器依赖分析和项目管理任务调度等实际应用中非常重要。

















 839
839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









