







 本文深入探讨了语音产生、感知的生理过程以及噪声环境中的人类听觉补偿机制。从谱减法到统计模型和子空间算法,介绍了多种语音增强策略。同时,强调了低频共振峰、周期性和频谱快变在语音识别中的关键作用,以及听觉流、掩蔽间隙利用和空间信息在复杂环境下的语音可懂度提升。
本文深入探讨了语音产生、感知的生理过程以及噪声环境中的人类听觉补偿机制。从谱减法到统计模型和子空间算法,介绍了多种语音增强策略。同时,强调了低频共振峰、周期性和频谱快变在语音识别中的关键作用,以及听觉流、掩蔽间隙利用和空间信息在复杂环境下的语音可懂度提升。
前言
本文主要记录本人选读单麦降噪经典书籍《Speech enhancement: theory and practice》的读书笔记,
内容会持续更新。
第1章~第4章:https://blog.youkuaiyun.com/weixin_42601303/article/details/109667743
第5章:https://blog.youkuaiyun.com/weixin_42601303/article/details/109804212
第6章:https://blog.youkuaiyun.com/weixin_42601303/article/details/114365082
此处附上该书的网盘链接,里面有全套代码,供大家学习参考
链接:https://pan.baidu.com/s/1BFyPPiAigoLJSe995SyPlw
提取码:7ycl
第1章 引言
1.1 了解噪声
噪声:平稳噪声、非平稳噪声
对非平稳噪声进行抑制的难度要远远大于平稳噪声
不同噪声的频谱形状不同,特别是噪声能量在频域的分布
在实际应用中的语音增强算法通常需要在0~15dB SNR的环境下工作
1.2 语音增强算法分类
语音增强算法主要可以分为三类:
谱减法:迄今最容易实现的增强算法。由于噪声是加性的,因此当没有语音的时候,可以估计或更新噪声谱,然后从带噪信号中将噪声减去。
基于统计模型的算法:给定带噪信号的一系列测量参数,例如傅里叶变换系数,我们对感兴趣的参数找到一个线性(或非线性)估计,也就是纯净信号的一种变换系数。维纳(Wiener)算法和最小均方误差(MMSE)算法就属于此类。
子空间算法:源自线性代数理论,通过正交矩阵分解技术将带噪信号向量空间分解为“信号”和“噪声”子空间,特别是奇异值分解(SVD)和特征向量/特征值分解(EVD)。
第3章 语音产生与感知
3.2 语音产生过程
语音的产生涉及一系列的器官和肌肉,包括肺、喉和声道。
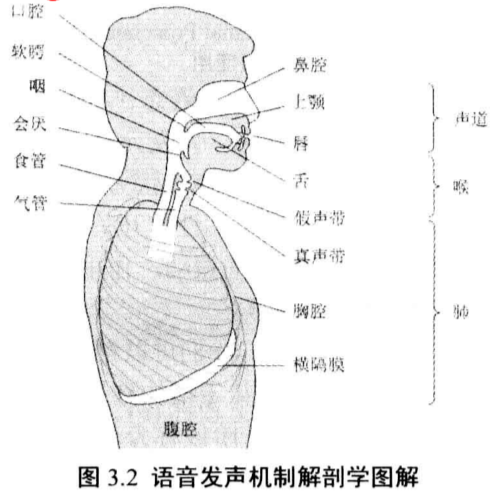
3.2.1 肺
是语音产生的主要激励源
3.2.2 喉与声带
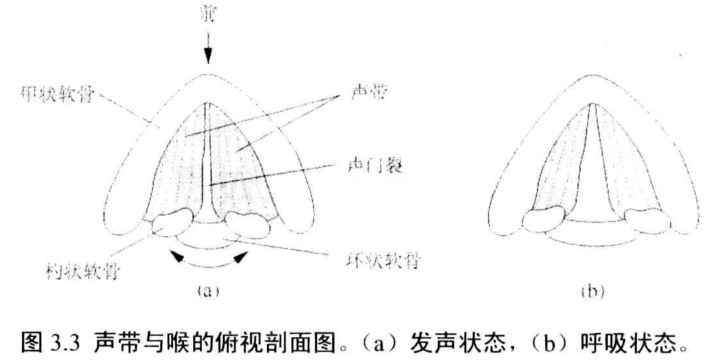
声带可处于三种状态:呼吸态、浊音态和清音态
呼吸态:空气从肺部自由流过声门(张开)而没有明显阻力。
浊音态:两片声带张力的快速增减,伴随着声门气压的快速变化,导致声带周期性闭合。
元音也被称为浊音
基音周期:一个声门开启闭合往复一次的时间长度称为基音周期,基因周期主要受声带的张力和质量的影响。声带质量越大,振动越慢,基因周期越长。男声的基因频率的范围大约在60Hz到150Hz,而女声和童声大约为200Hz到400Hz。
清音态:声带不振动,但是两片声带更紧绷更靠近,因此气流流经声门时产生湍流,空气湍流发出的声音称为送气声。
清音包括了绝大多数的辅音
3.2.3 声道
声道像一个物理线型滤波器一样重塑声门波的频谱以产生不同的声音,该滤波器的特性随着发声器官的位置或口腔形状改变而改变。
声道就是一个时变的共鸣腔,其形状随时间改变,因而共振频率改变并产生不同声音。
第一共振峰,标注为F1,随口腔的张闭而改变。嘴巴微张时产生较低频率的F1,而嘴巴大张时具有较高的F1。
第二共振峰,标注为F2,与口腔中舌头位置或者嘴唇活动有关。
第三共振峰,标准为F3,随口腔的前后收缩而变化。
对11个元音的F1和F2共振峰频率做测量和比较,实验结果显示,F1频率受噪声影响最小,F2的值受影响最大。这一发现说明,在噪声环境中,听者必定可以得到相对更可靠的F1的信息,但可能只能得到比较模糊的F2的信息。
一个均匀声管共振的最低频率的波长是声管长度的4倍。声管将在该最低频率的奇数倍上产生谐振。
3.3 语音产生的工程模型
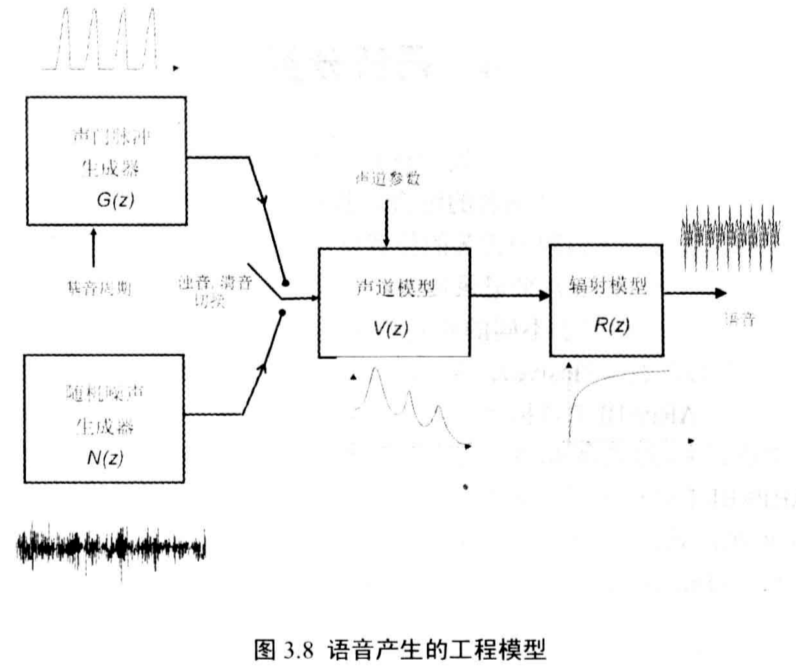
声带为声道提供激励源,激励可以是周期的或者非周期的,取决于声带的状态。
3.5 语音感知的声学特征
3.5.1 元音和双元音
稳态(元音中间段)共振峰频率是元音感知的主要音征,但不是唯一的,其他的音征(例如持续时长、频谱变化等)也常用于元音辨识。
3.5.2 半元音
尽管半元音具有与元音相似的特征,但是它们被归为辅音类,这是由于它们和其他辅音一样,只是在音节的起始和结尾的时候出现。与元音不同的是,半元音的共振峰并不能达到稳态。
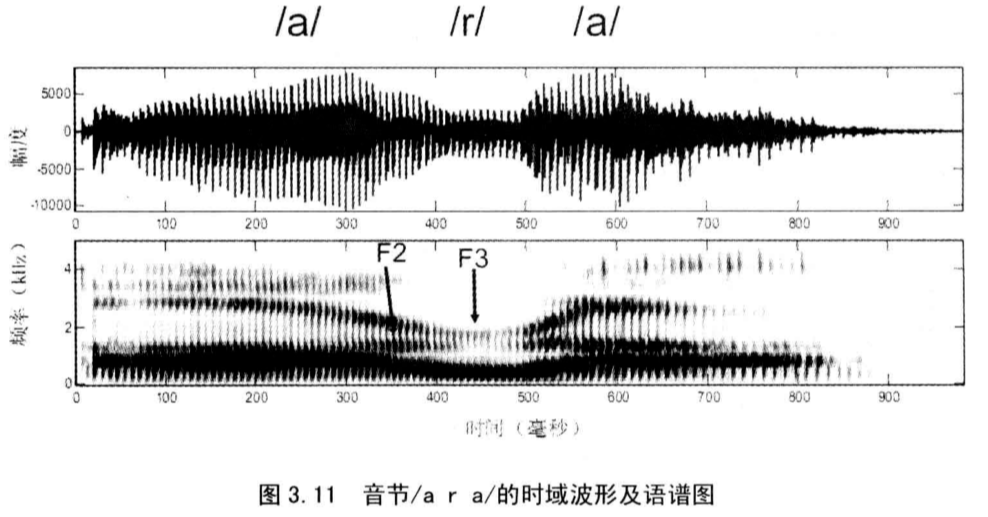
共振峰转换是半元音感知的重要音征,尤其重要的是F2和F3频率的变化。
3.5.3 鼻音
在发鼻音的时候,软腭降低,鼻腔入口张开,口腔通道阻断。在声道中引入鼻腔就产生了一个更大更长的共振腔,这样的共振腔具有更低的共振频率。
由于发鼻音是口腔通道完全关闭,所以会出现反共振,其结果是高阶共振峰被严重衰减。
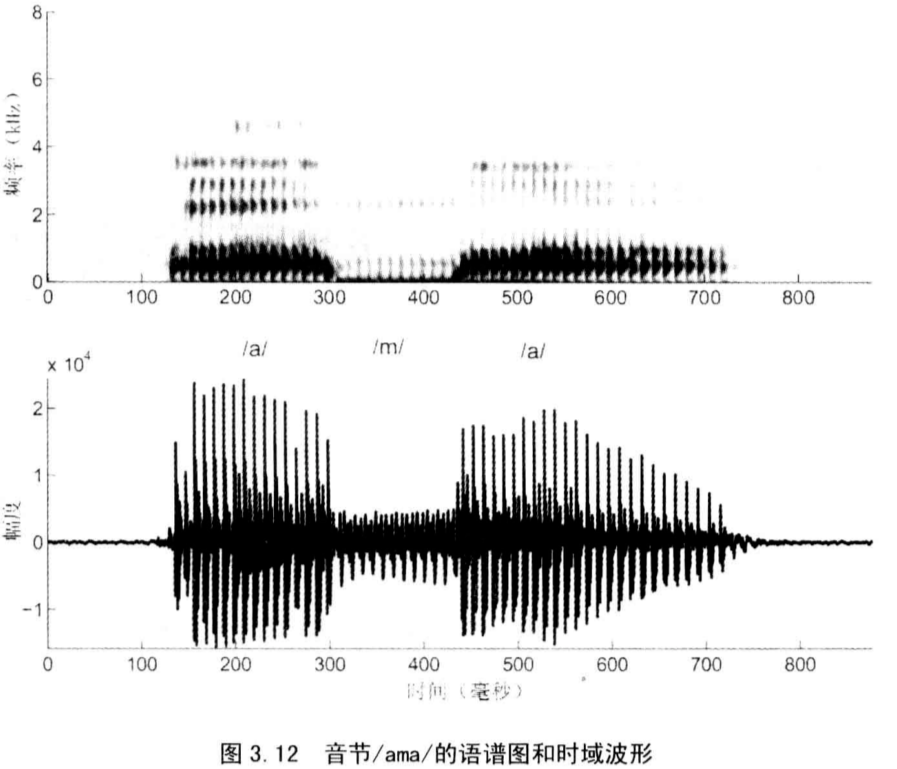
有两个特征可以区分鼻音和其他语音:
第一是衰减以后的高频共振峰的强度;
第二是是否出现低频共振(<500Hz);
鼻音产生前后的共振峰的转换是识别鼻音最有效的音征。
3.5.4 闭塞音(爆破音)
元音、半元音和鼻音都有一个特点,即气流都可以相对自由地通过声带。而对于闭塞音和摩擦音,发这些音时,气流受约束。某些情况下甚至会被阻断。
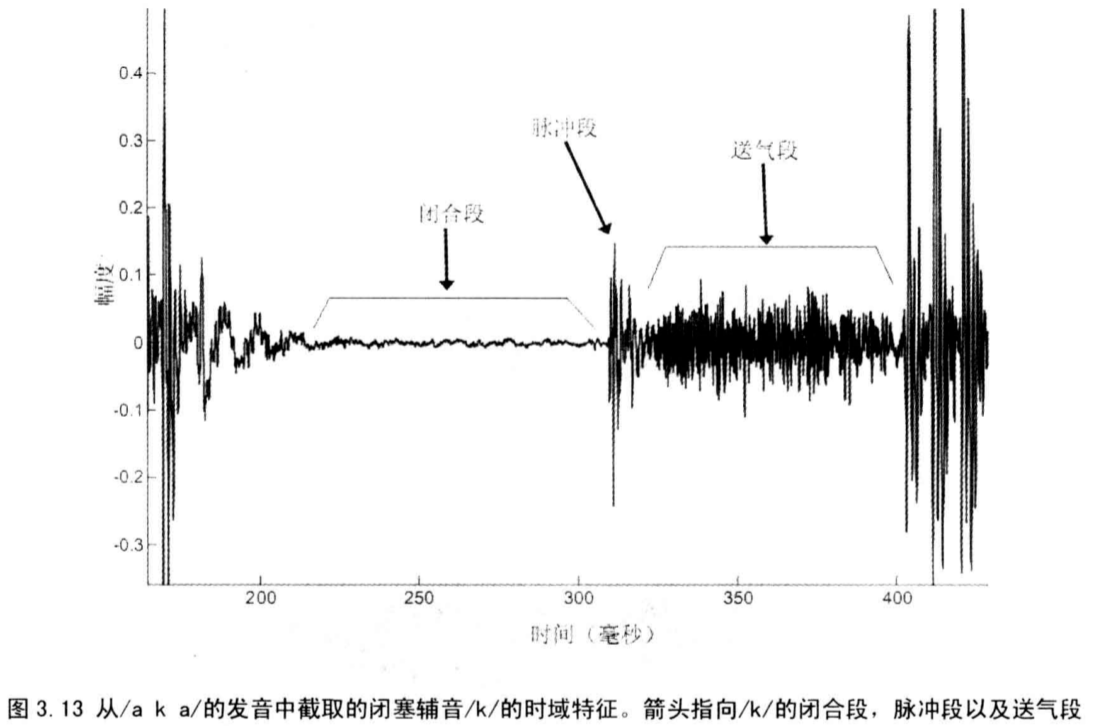
闭塞音拥有两个特有的性质:
第一,闭塞音发声时,存在声道的完全闭合,以至于短暂的阻断气流,在声学信号中其表现为静音;
第二,在气流受阻气压累积之后,气流被快速释放,听起来像是短暂的噪声脉冲,脉冲之后的噪声称为送气声;
闭合期以及气流释放形成的脉冲式闭塞辅音类的两个主要声学音征。
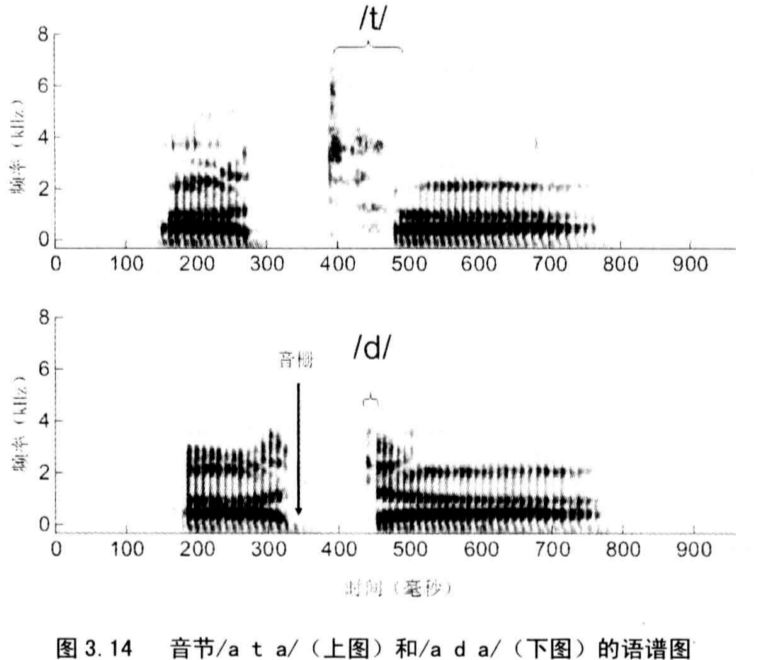
闭塞音又分为清闭塞音(/p,t,k/)和浊闭塞音(/b,d,g/)。
- 清闭塞音在闭合期没有气流流经声道,对于浊闭塞音,在闭合期的全部或者部分时间内有低强度的周期信号(以基音频率)通过。
- 浊闭塞音的平均时长要短于清闭塞音。浊音启动时间,即发出脉冲到声带振动开始的时间间隔,对于浊闭塞音来讲大约有10ms到20ms,清闭塞音则有40ms到100ms。
- 清闭塞音的气流释放形成的脉冲强度要强于浊闭塞音。
3.5.5 摩擦音
与闭塞辅音类似,发摩擦音时,发声器官在声道某处形成窄的收缩甚至阻隔,当气流流经这些成阻区时就产生噪声,继而被声道整形。
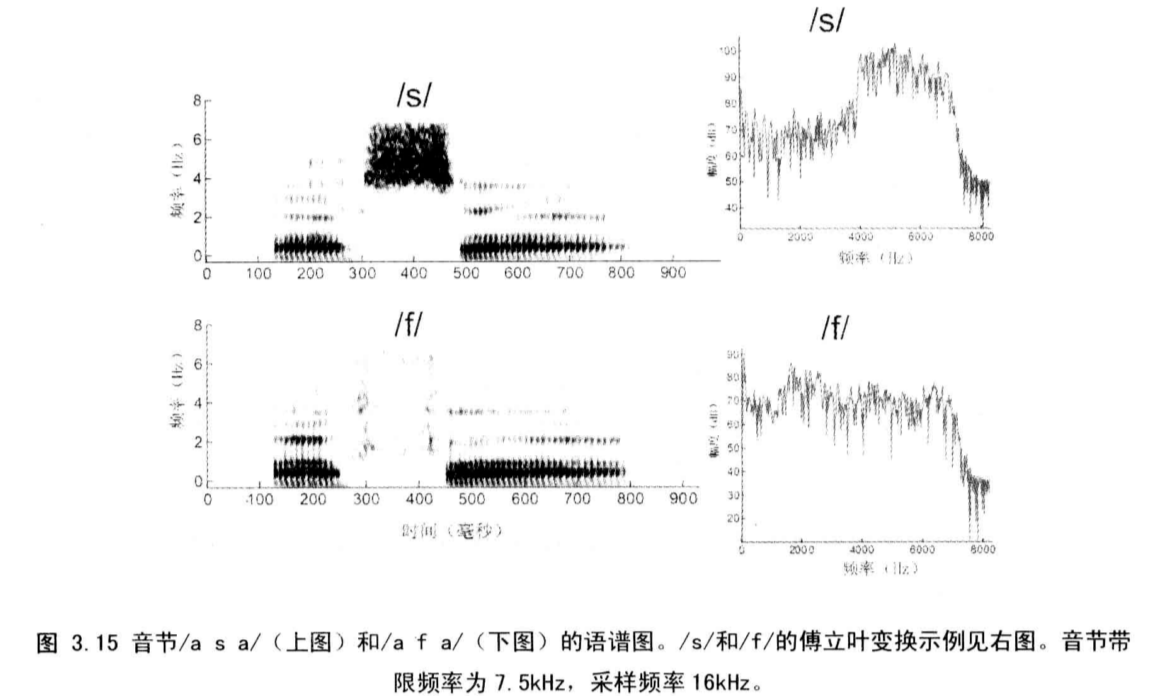
摩擦音的主要音征在于存在相对较长的非周期噪声段。
对于摩擦音的发生位置有三个主要的音征:
第一是摩擦噪声的强度;
第二是摩擦音的频谱形状;
第三是与前后浊音之间的F2和F3共振峰的过渡。
第4章 人类对噪声的听觉补偿
4.1 多说话人环境下的语音可懂度
以便区分,用掩蔽语音信号(masker)和目标语音信号(target)来分别表示干扰信号和希望提取的语音信号。
4.1.1 掩蔽信号的时频特性和说话人数的影响:单耳听觉
一些研究证实,在稳态噪声中语言辨识会比在单竞争说话人条件下更为困难。通过利用单个(或少数)竞争说话人来取代稳态噪声作为干扰信号而提高可懂度的现象在文献中称为去掩蔽。
所有这些掩蔽信号被用于评估导致其与竞争语音掩蔽信号之间的性能差异的原因,是由其时域波动的异同引起的。
4.1.2 声源的空间位置影响:双耳听觉
源自不同位置的信号到达每只耳朵的时间有所不同,并且由于经过头部阻挡的衰减,幅度也会不同,通常称为“头影(head shadow)”。由于头影效应而导致的幅度差别称为双耳强度差(ILDs),到达双耳的时间差称为双耳时差(ITDs)。
噪声源的空间分布以及数量对双耳听觉下的语音可懂度会有影响。
双耳听觉带来的好处通常称为空间去掩蔽,主要归因于两个因素,一是头部掩影的作用,二是耳间时差。
4.2 影响鲁棒性的语音声学属性
4.2.1 语音频谱形状
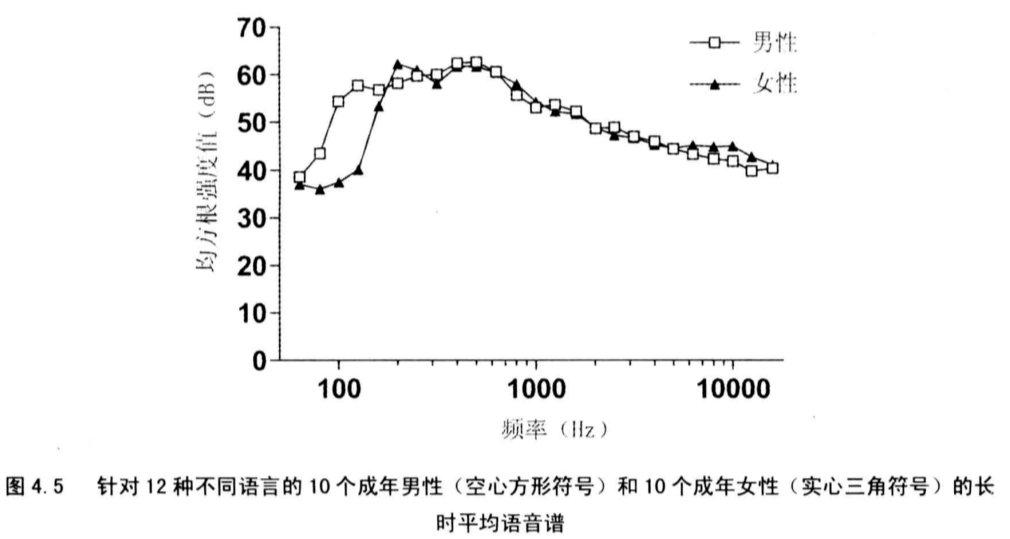
从图中可以看出,大多数的语音能量落在低于1KHz的频率上,峰值在500Hz,从500Hz往上,能量逐渐下降。
这种低频重音能弱化失真和噪声的影响进而保护语音信息,原因有几点:
第一,伴随着信噪比的下降,低频区域是最后被噪声掩蔽的区域;
第二,听者能获取到可靠的F1和F2的信息,该信息对于元音辨识和闭塞辅音的感知具有关键作用;
第三,低频部分的语音谐波比高频部分所受的影响小,因此,听着可能获得相对可靠的F0音征,从竞争语音中区分出目标语音需要用到该音征;
第四,听觉得频率选择性在低频部分最强,往高频部分则下降,这让听者对F0有较好的分辨能力。
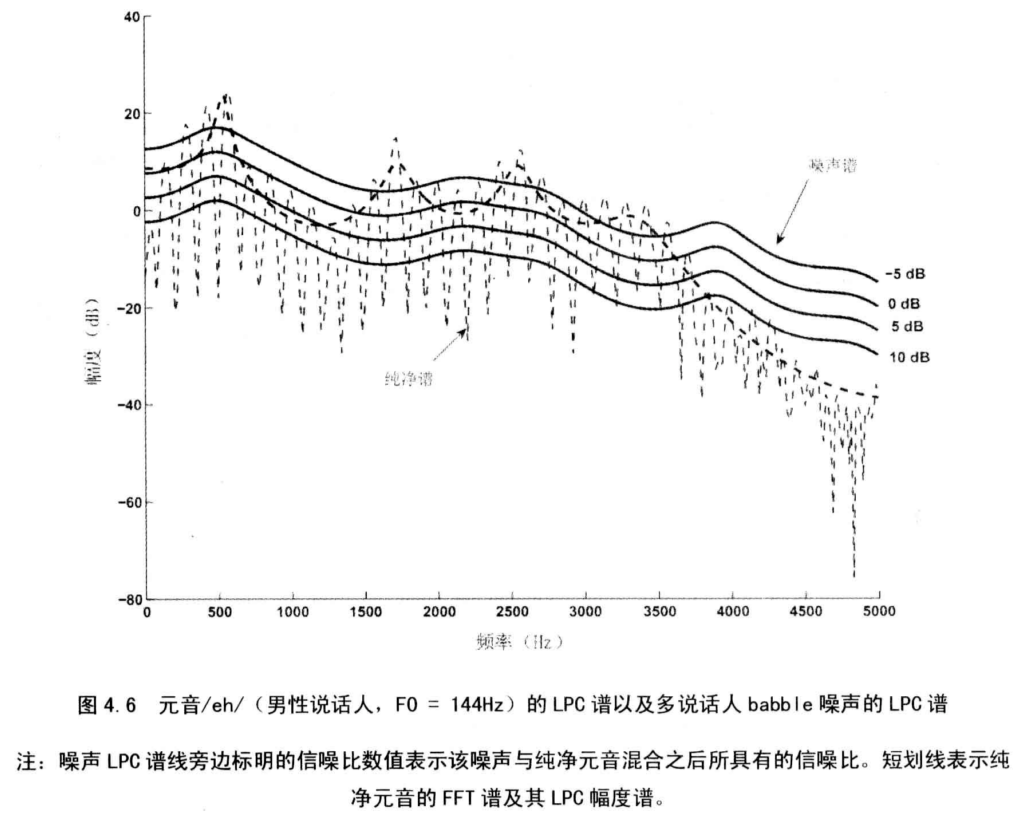
4.2.2 谱峰
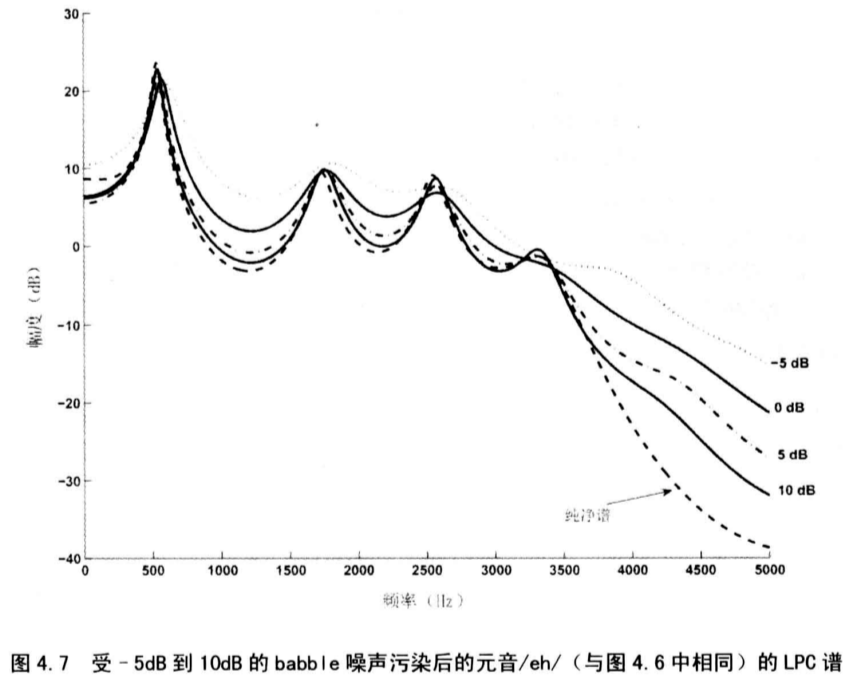
在噪声中,低频谱峰的信息比谱谷的信息更可能得以保存。
如图所示,前三个共振峰的频率位置,即对应于最低频率的三个共振峰(F1~F3),在叠加噪声之后变化不大。
噪声可以给语音频谱带来失真,改变谱斜率,并且减小谱线动态范围,但是低频共振峰的频率位置能得到一定程度的保留。
4.2.3 周期性
至少1Khz以内的低阶谐波在噪声中能得以较好的保存,这表明噪声环境下听者仍然有可能得到相对精确的F0信息。
4.2.4 频谱快变:辅音的信号
与元音不同,辅音的持续时间短,声强小,因而,辅音比元音更容易受噪声或失真的干扰。
元音或者双元音的共振峰转移是缓慢而渐进的,相反,辅音则具有快速的频谱变化和快速的共振峰转换,在噪声中,这种快速频谱变化将在一定程度上被感知,从而成为辅音存在与否的标志信号。
4.3 噪声环境中听觉的感知策略
4.3.1 听觉流
将属于同一声源的声学分量称为“听觉流”
有两种类型的整合对语音源的分离是必要的:
第一,将相继发生的且时间上接近的时间进行整合;
第二,将同时发生于频谱上不同区域的声学分量进行整合。
4.3.2 掩蔽间隙的瞬时听觉
听者会通过竞争语音信号中的静音间隙或波形中的“波谷”来识别目标语句中的内容,这些见习或者幅度低谷区域为听者提供了“瞥视”目标语音中的整个音节或词语的可能性。
4.3.3 利用F0的差异
在竞争语音条件下,掩蔽语音和目标语音之间的基音频率差异对语音识别具有重要作用。
4.3.4 利用语言学知识
在恶劣环境中的语音可懂度与听者利用语言学知识的能力有很大关系,尤其是当声学信号中的音征较弱的时候。语音内容能够限制候选词语的范围,进而提高语句的可懂度。

















 3590
3590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









