







 本文详细介绍了数据库索引模型,包括哈希表、有序数组和搜索树(如B树和B+树)的优缺点。重点讨论了InnoDB引擎的B+树索引模型,解释了主键、唯一索引、普通索引、聚簇与非聚簇索引的概念,以及联合索引的最左匹配原则。此外,还涵盖了MySQL中不同的索引类型,如FullText索引,并讨论了索引设计的原则和注意事项,如使用覆盖索引、避免索引失效等。
本文详细介绍了数据库索引模型,包括哈希表、有序数组和搜索树(如B树和B+树)的优缺点。重点讨论了InnoDB引擎的B+树索引模型,解释了主键、唯一索引、普通索引、聚簇与非聚簇索引的概念,以及联合索引的最左匹配原则。此外,还涵盖了MySQL中不同的索引类型,如FullText索引,并讨论了索引设计的原则和注意事项,如使用覆盖索引、避免索引失效等。
1. 索引模型
数据库的常见索引模型有hash表,有序数组和搜索树
- hash表:哈希表是一种以键-值(key-value) 存储数据的结构
- 优点:新增记录时速度很快
- 缺点:不是有序的,hash索引做区间查询很慢
- 有序数组:按照索引递增的顺寻存在数组中
- 优点:有序数组在等值查询和范围查询场景中的性能都非常优秀
- 缺点:新增记录的成本较高
- 搜索树:
- 二叉搜索树:每个节点的左儿子小于父节点, 父节点又小于右儿子。
- 优点:查找的复杂度为log(n)
- 缺点:
- 新增记录的时候,需要维护平衡二叉树,增加的效率也是long(n)
- 每次查询需要访问多个数据块,涉及到了多次磁盘io的操作。 注意,我们说的平衡二叉树结构,指的是逻辑结构上的平衡二叉树,其物理实现是数组。然后由于在逻辑结构上相近的节点在物理结构上可能会差很远。因此,每次读取的磁盘页的数据中有许多是用不上的。因此,查找过程中要进行许多次的磁盘读取操作。
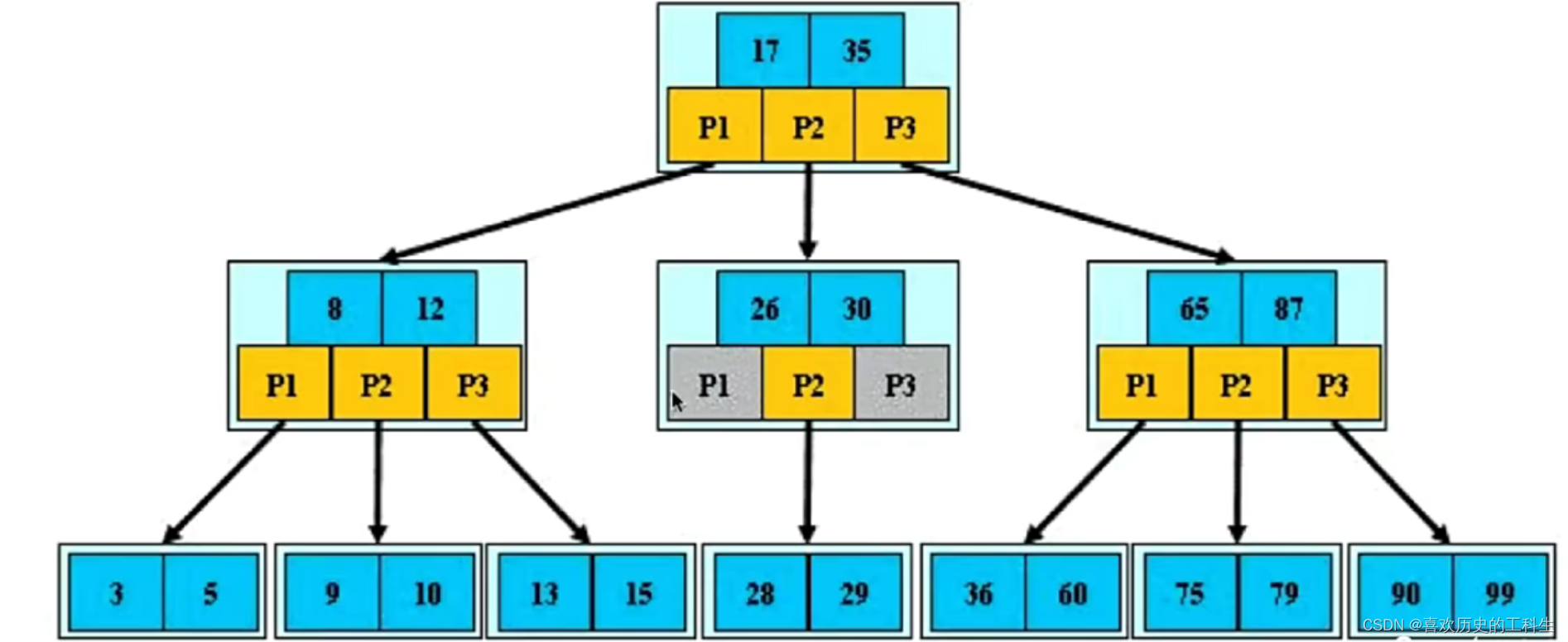
- B树:通过增加子结点的数量和结点中的关键字的数量来减少树的深度,从而减少访问磁盘的次数
-
B树的结构
- 每个节点最多有m-1个关键字(可以存有的键值对)
- 另外,我们需要注意一个概念,描述一颗B树时需要指定它的阶数,阶数表示了一个节点最多有多少个孩子节点,一般用字母m表示阶数。
- 根节点最少可以只有1个关键字。
- 非根节点至少有m/2个关键字。
- 每个节点中的关键字都按照从小到大的顺序排列,每个关键字的左子树中的所有关键字都小于它,而右子树中的所有关键字都大于它。
- 所有叶子节点都位于同一层,或者说根节点到每个叶子节点的长度都相同。
- 每个节点都存有索引和数据,也就是对应的key和value。
- 每个节点最多有m-1个关键字(可以存有的键值对)
-
优点:降低IO操作的次数。磁盘一次读取一页的磁盘数据,这时将节点大小设置为磁盘页的大小,也正因每个节点存储着非常多个关键字,树的深度就会非常的小。进而要执行的磁盘读取操作次数就会非常少,更多的是在内存中对读取进来的数据进行查找。
-
B+ 树:B树的变体(Innodb的索引模型)
- B+相比B树有如下改进
- 非叶子节点的子树指针和关键字个数相同
- 非叶子节点的子树指针P[i],指向 关键字[K[i], K[i+1] 的子树
- 非叶子节点仅用来索引,数据都保存在叶子节点中
- 所有叶子节点均有一个链指针指向下一个节点
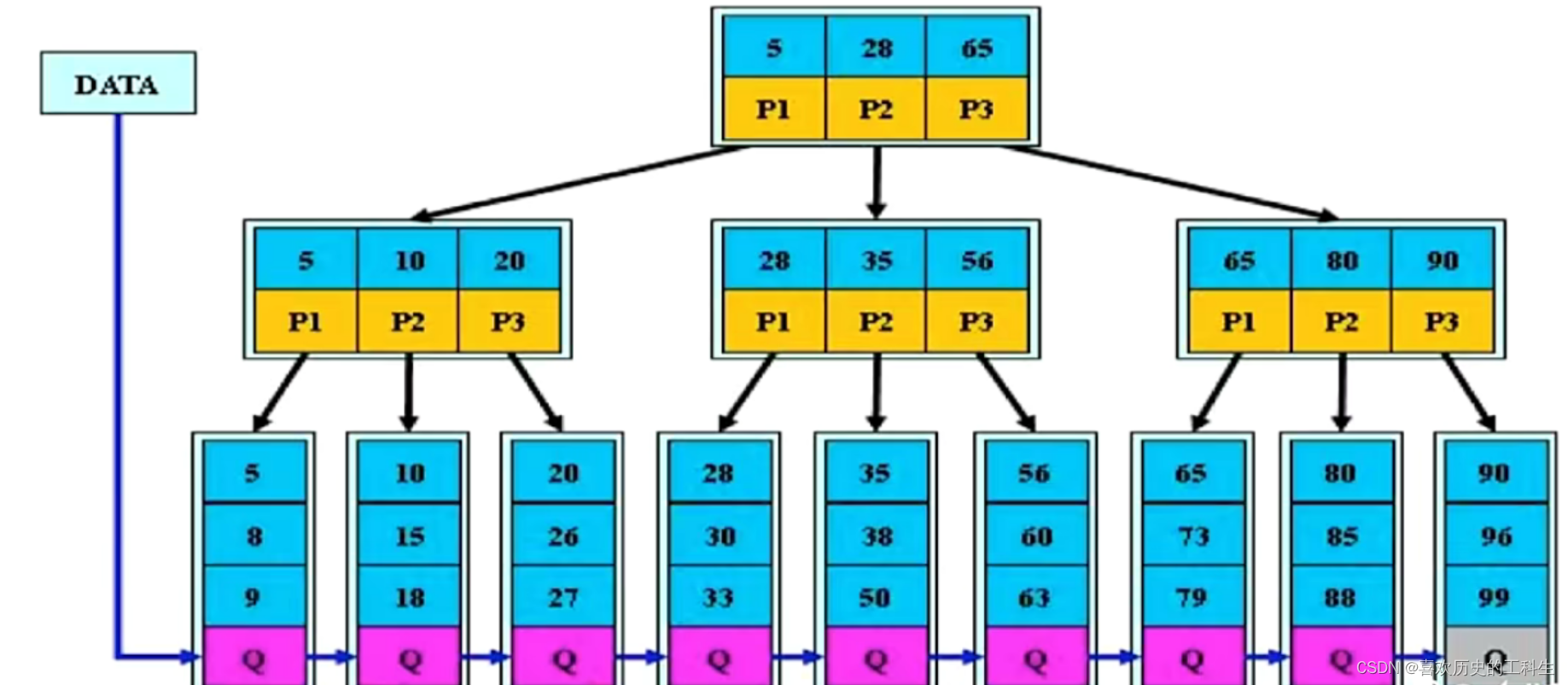
- B+树相比B树的优势
- B+树的磁盘读写代价更低 :由于非叶子节点不存储数据,同一盘块中存放索引的个数更多
- B+树查询效率更稳定:内部节点并不是最终指向文件内容的节点,所以任何关键字的索引必须走一条从根节点到叶子节点的路
- B+树更有利于对数据库的扫描
- B+相比B树有如下改进
-
- 二叉搜索树:每个节点的左儿子小于父节点, 父节点又小于右儿子。
Mysql中的索引类型?
- FullText:即为全文索引,其可以在CTREATE TABLE,ALTER TABLE ,CREATE TABLE, CREATE INDEX使用,不过目前只有CHAR,VARCHAR,TEXT列上可以创建全文索引(和模糊查询相似,但是比模糊查询快)
- 主键索引:主键是一种唯一
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









