






在上一篇文章中,带大家了解了文本的存储方式和json的存储方式,而这篇文章是要大家掌握其余的数据存储方式。
CSV存储文件存储
CSV,全称为 Comma-Separated Values,中文可以叫作逗号分隔值或字符分隔值,其文件以纯文本形式存储表格数据。该文件是一个字符序列,可以由任意数目的记录组成,记录间以某种换行符分隔。每条记录由字段组成,字段间的分隔符是其他字符或字符串,最常见的是逗号或制表符。不过所有记录都有完全相同的字段序列,相当于一个结构化表的纯文本形式。它比 Excel 文件更加简洁,XLS 文本是电子表格,它包含了文本、数值、公式和格式等内容,而 CSV 中不包含这些内容,就是特定字符分隔的纯文本,结构简单清晰。所以,有时候用 CSV 来保存数据是比较方便的。现在,我们来讲解Python 读取和写入 CSV 文件的过程。
CSV的写入数据的方式主要有以下两种,分别是列表和字典。
列表数据的写入
在CSV中有两种文件的写入方式,分别是单行写入和多行写入,下面来看看代码示例:
单行写入
import csv
columns = ['id', 'name', 'age']
data1 = ['1', '小明', '12']
data2 = ['2', '小红', '12']
with open('data.csv', 'w', newline='', encoding='ANSI') as csvfile:
# 将普通文本对象转换为csv文件对象
writer = csv.writer(csvfile)
writer.writerow(columns)
writer.writerow(data1)
writer.writerow(data2)
在这段代码中,创建了三个列表,第一个列表定义了表格数据的列名,另外两个列表定义了表格数据,另外保存CSV数据的时候,编码格式设置为了ANSI,主要是考虑到有些朋友的电脑可能会出现乱码,绝大多数windows系统的电脑若设置成utf-8遇到中文字符保存进CSV中均有可能会遇到乱码问题。
多行写入
多行写入其实道理非常的简单,无非就是将列表嵌套列表即可。
import csv
columns = ['id', 'name', 'age']
data1 = ['1', '小明', '12']
data2 = ['2', '小红', '12']
datas = [['3', '小李', '15'], ['3', '小王', '20']]
with open('data.csv', 'w', newline='', encoding='ANSI') as csvfile:
# 将普通文本对象转换为csv文件对象
writer = csv.writer(csvfile)
writer.writerow(columns)
writer.writerow(data1)
writer.writerow(data2)
writer.writerows(datas)
在上述示例代码中,
datas = [['3', '小李', '15'], ['3', '小王', '20']]
这里,我构建了一个列表,在列表中又嵌套了两个列表,那么可以通过方法writerows(),将嵌套的两个列表写入文件中。
注意,当你将上述代码运行后一定会生成一个data.csv文件,若你还需要将后续数据保存到该文件中,一定要先将data.csv关闭。否则,会出现如下错误:
PermissionError: [Errno 13] Permission denied: 'data.csv'
字典数据的写入
具体代码如下所示:
import csv
# 定义字典的键
filenames = ['id', 'name', 'sex', 'age']
# 定义写入的数据
data1 = {
'id': '1',
'name': '小李',
'sex': '男',
'age': 18
}
data2 = {
'id': '2',
'name': '小王',
'sex': '女',
'age': 20
}
data3 = {
'id': '3',
'name': '小张',
'sex': '男',
'age': 25
}
with open('dict_data.csv', 'w', newline='') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=filenames)
# 写入列名
writer.writeheader()
writer.writerow(data1)
writer.writerow(data2)
writer.writerow(data3)
print('保存成功!')
实战案例
实战案例中涉及到的内容均以学习为目的,不参与任何的商业行为。若出现任何问题均与本作者无关
aHR0cDovL2NoYW5ncy5jY2dwLWh1bmFuLmdvdi5jbi9ncC9ub3RpY2VTZXJhY2guaHRtbD9hcnRpY2xlVHlwZT0yJmJhc2ljQXJlYT1nYW94aW4=

当你切换页面时,会发现网址并没有发生变化,因此可以判断出该页面是一个动态加载的页面,这是局部刷新的效果。
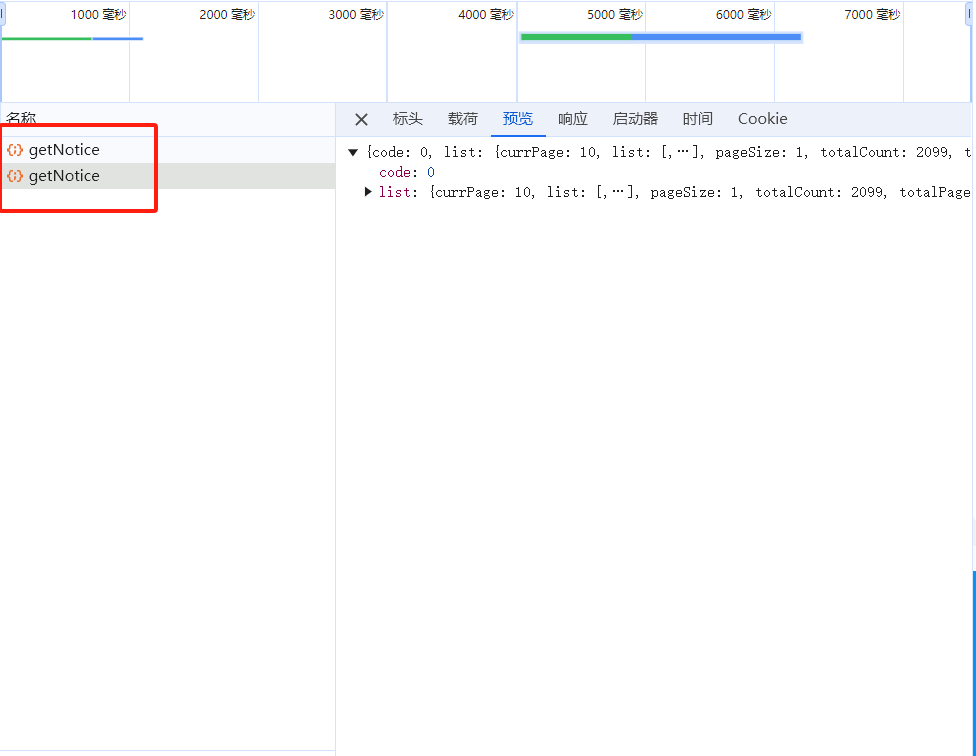
如上图所示,点击切换页面后,浏览器会监测到名为getNotice的数据包,通过这个数据包中的标头和载荷数据即可向目标网站发起请求。
具体代码
url = 'xxx'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36'}
data = {
'page': 1,
'limit': 10,
'sidx': '',
'order': '',
'categoryId': '',
'articleType': 2,
'projid': '',
'name': '',
'cgType': 0,
'buyerNm': '',
'buyerOrgNm': '',
'supplyNm': '',
'basicType': '',
'basicDatetime': '2024-01-01',
'basicDatetimes': '2024-10-24',
'type': 0,
'basicArea': 'gaoxin',
'categoryType': 0
}
res = requests.post(url, headers=headers, data=data)
print(res.json())
运行得到的结果是一串Json格式的字符串,具体结果就不再展示,自行运行查看即可。
数据保存
仔这段运行的结果中,我需要提取,author、basicDatetime、basicTitle、basicId,将这些数据保存到csv文件中。
具体代码
columns = ['author', 'basicDatetime', 'basicTitle', 'basicId']
with open('政府采购.csv', 'a', encoding='ANSI', newline='') as f:
csv_writer = csv.DictWriter(f, fieldnames=columns)
csv_writer.writeheader()
for i in res.json()['list']['list']:
item = {}
item['author'] = i['author']
item['basicDatetime'] = i['basicDatetime']
item['basicTitle'] = i['basicTitle']
item['basicId'] = i['basicId']
csv_writer.writerow(item)
print('保存成功')
最后,仔当前文件夹下查看,便可以发现,出现了政府采购.csv文件。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









