






结果

代码
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVCimport utilities
# 加载数据
input_file = 'data_multivar.txt'
X, y = utilities.load_data(input_file)###############################################
# 切分出测试数据
from sklearn import cross_validationX_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.25, random_state=5)
params = {'kernel': 'rbf'}
classifier = SVC(**params)
classifier.fit(X_train, y_train)###############################################
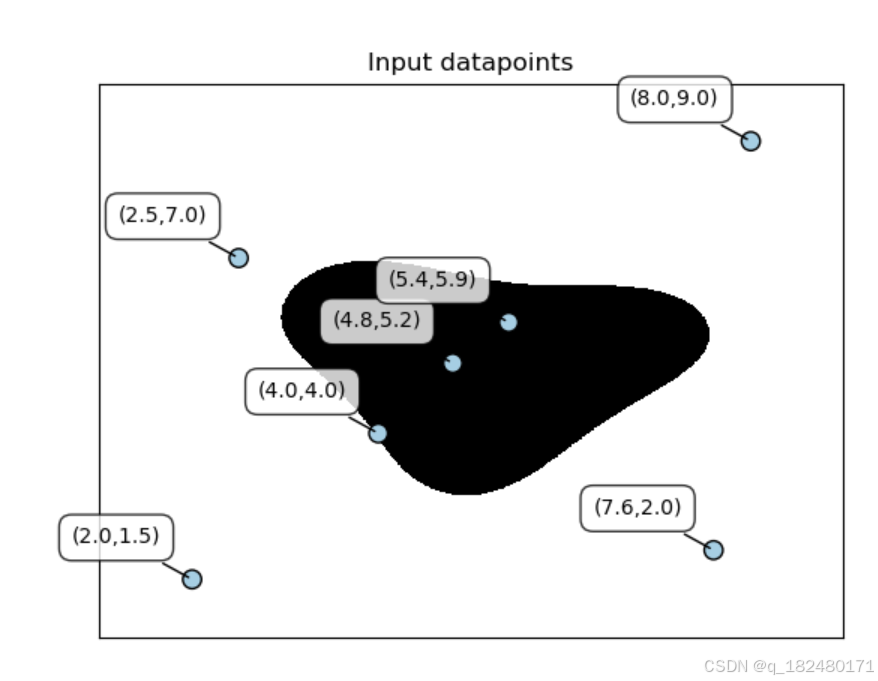
# 设置边界input_datapoints = np.array([[2, 1.5], [8, 9], [4.8, 5.2], [4, 4], [2.5, 7], [7.6, 2], [5.4, 5.9]])
print "\n打印边界距离:"
for i in input_datapoints:
print i, '-->', classifier.decision_function(i)[0]# Confidence measure
params = {'kernel': 'rbf', 'probability': True}
classifier = SVC(**params)
classifier.fit(X_train, y_train)
print "\n设置置信度:"
for i in input_datapoints:
print i, '-->', classifier.predict_proba(i)[0]utilities.plot_classifier(classifier, input_datapoints, [0]*len(input_datapoints), 'Input datapoints', 'True')
plt.show()- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.

















 2102
2102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









