






 KNN是一种基本的分类与回归方法,用于解决有监督的分类问题。其核心是根据最近K个邻居的类别进行预测,K值的选择影响预测结果。常用的距离度量为欧式距离,K值可通过交叉验证来确定。KNN与K-means的主要区别在于,KNN用于分类,而K-means用于聚类。
KNN是一种基本的分类与回归方法,用于解决有监督的分类问题。其核心是根据最近K个邻居的类别进行预测,K值的选择影响预测结果。常用的距离度量为欧式距离,K值可通过交叉验证来确定。KNN与K-means的主要区别在于,KNN用于分类,而K-means用于聚类。
参考的一些网页:
https://zhuanlan.zhihu.com/p/143092725
1 概念
k近邻算法(k-nearest neighbour,k-NN)是一种基本分类与回归方法,是数据挖掘技术中原理最简单的算法之一。核心功能是解决有监督的分类问题。KNN能够快速高效地建立在特殊数据集上的预测分类问题,但是不产生模型,因此算法准确性高但是不具备强推广性。
KNN 输入实例的特征向量,特征空间;
KNN 输出为实例的类别,K类。
K近邻三个基本要求:k值的选择、距离度量、分类决策规则。
2 原理及举例
KNN的原理就是:当预测一个新的值x所属分类时,根据与它距离最近K个点来判断它属于哪个类别。

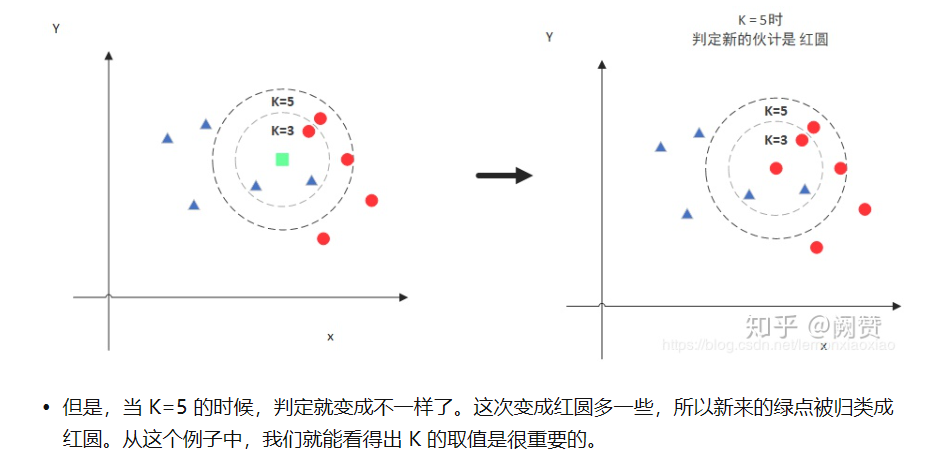
所以说,K的取值还是非常重要的,如上图所示,K=3和K=5会预测得到两个不同的结果。
3 KNN中最常用的距离度量——欧式距离
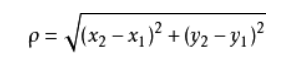
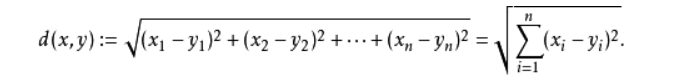
4 K值的选择
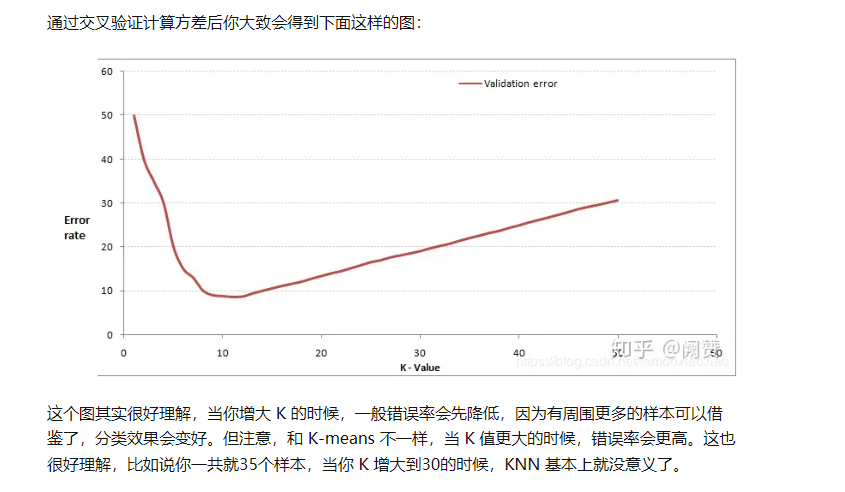
通过上面那张图我们知道 K 的取值比较重要,那么该如何确定 K 取多少值好呢?答案是通过交叉验证(将样本数据按照一定比例,拆分出训练用的数据和验证用的数据,比如6:4拆分出部分训练数据和验证数据),从选取一个较小的 K 值开始,不断增加 K 的值,然后计算验证集合的方差,最终找到一个比较合适的 K 值。
5 knn和k-means的区别
KNN的目的是分类
K-means的目的是聚类



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









