







0 写在前面
- 之前通过观看b站视频,浅学了一些关于PyTorch的知识,现在希望基于书本,将之前所学的知识融会贯通起来。
- 本篇文章旨在记录学习过程,并且用通俗易懂的语言将自己的理解表达出来!
- 如果这篇文章对你有帮助的话,谢谢点赞关注收藏噢!
1 准备pytorch
这里默认大家已经在Windows系统下,配置了PyTorch!
2 Tensor基础知识
2.1 如何创建和操作Tensor
- Tensor是PyTorch中进行数据存储和运算的基本单元。
- Tensor之于PyTorch,相当于Array之于Numpy。
- Tensor,中文名叫张量,是PyToch中最基本的数据类型。
- 我们之前学习的标量、向量、矩阵都是张量的特例,标量是零维张量,向量是一维张量,矩阵是二维张量。张量还有三维、四维…甚至更多维!
2.1.1 基本创建方法:torch.Tensor()
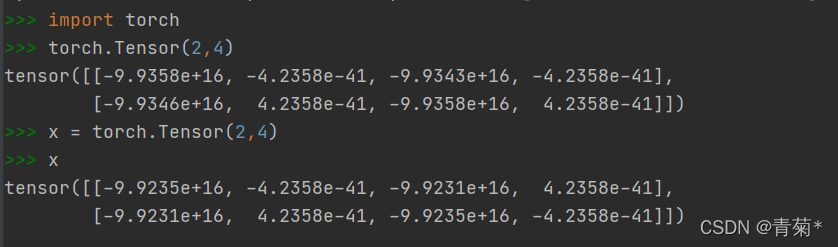
- x = torch.Tensor(2,4)
- 创建一个2*4的矩阵。
- 虽然没有初始化,但是这个矩阵中已经有值了。类型是32为float
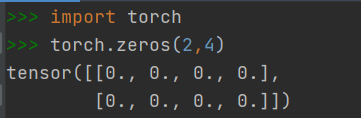
2.1.2 快速创建方法:torch.zeros()
- 创建元素全为0 的Tensor
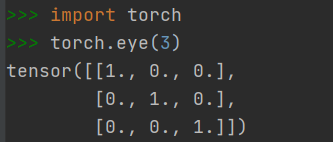
2.1.3 快速创建方法:torch.eyes()
- 创建对角线位置的元素全为1,其他位置为0的Tensor
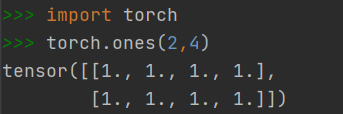
2.1.4 快速创建方法:torch.ones()
- 创建元素全为1的Tensor
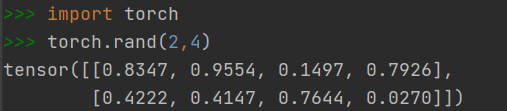
2.1.5 快速创建方法:torch.rand()
- 创建元素区间为[0,1]的随机数Tensor
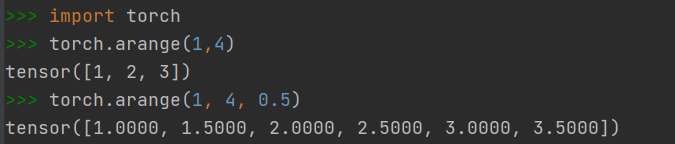
2.1.6 快速创建方法:torch.arange()
- 创建一个在区间内按指定步长递增的一维Tensor
- 前两个参数指定区间范围,左闭右开
- 第三个参数指定步长,默认为1
2.1.7 快速创建方法:torch.randn()
- 创建服从标准正态分布的一组随机数Tensor

关于PyTorch的操作函数,以后再说,等我们用到什么百度什么就好了!
2.2 Autograd的基本原理
Autograd中文:自动微分,是PyTorch进行神经网络优化的核心。自动微分,就是PyTorch自动为我们计算微分。
- Tensor在自动微分方面有3个重要属性:requires_grad,grad、grad_fn。
- requires_grad属性是一个布尔值,默认为
False。当设置为True时,表示该Tensor需要自动微分。 - grad属性用于存储Tensor的微分值。
- grad_fn属性用于存储Tensor的微分函数。
注意下面几点:
- 当叶子结点的
requires_grad=True时,信息流经过该结点时,所有中间结点的requreis_grad都会=True。 - 在输出结点调用反向传播函数:
backward(),PyTorch就会自动求出叶子结点的微分值,并更新存储到叶子结点的grad属性中。
2.2.1 举个例子
-
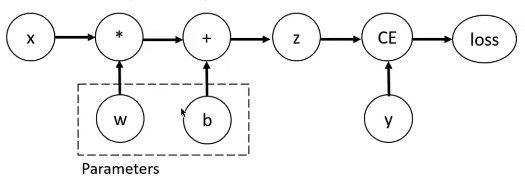
比如说一个 y + w ∗ x + b y+ w * x+ b y+w∗x+b的线性模型:
-
下面是这个计算过程的计算图:
-
其中,z是预测输出(计算输出),y是实际输出。loss函数就是用来计算这两个输出之间的差距大小,loss越小,模型预测效果越好!
-
下面代码可以直接运行!
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
wimport torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = torch.Tensor([1.0])
w.requires_grad = True
def forward(x):
return w * x
def loss(x, y): # 这里采用MSE均方差计算损失值
y_pred = forward(x)
return (y_pred - y) ** 2
print("在模型计算之前对于x=4的预测是:", 4, forward(4).item, '\n\n')
for epoch in range(20):
for x, y in zip(x_data, y_data):
l = loss(x, y)
l.backward()
print('\tgrad:', x, y, w.grad.item())
w.data = w.data - 0.01 * w.grad.data
w.grad.data.zero_()
print("process:", epoch, l.item(), '\n')
print("在模型计算之后对于x=4的预测是:", 4, forward(4).item( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









