






MHA架构图
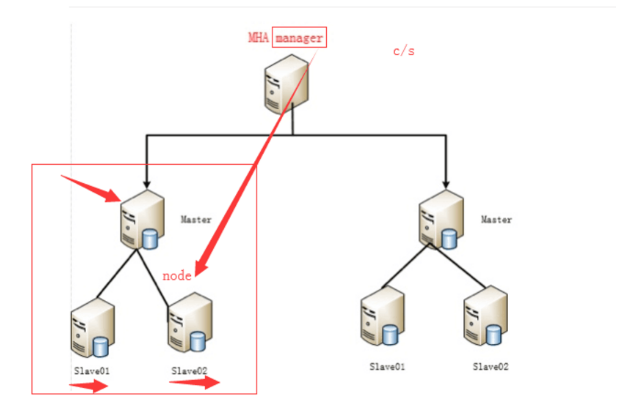
本次MHA的部署基于GTID复制成功构建,普通主从复制也可以构建MHA架构。
下载所需的软件包
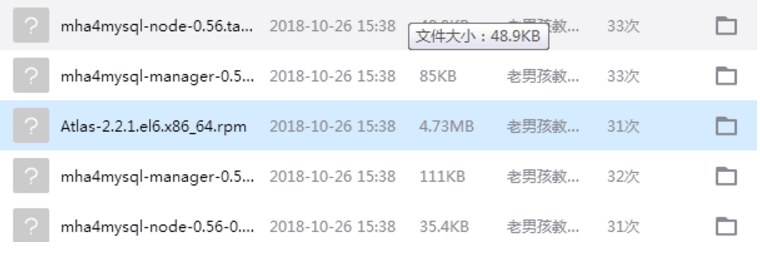
mkdir /server/tools -p //创建存放包的目录
[root@db01 tools]# ll
total 5136
-rw-r--r-- 1 root root 4963681 Oct 26 15:39 Atlas-2.2.1.el6.x86_64.rpm
-rw-r--r-- 1 root root 87119 Oct 26 15:39 mha4mysql-manager-0.56-0.el6.noarch.rpm
-rw-r--r-- 1 root root 113914 Oct 26 15:39 mha4mysql-manager-0.56.tar.gz
-rw-r--r-- 1 root root 36326 Oct 26 15:39 mha4mysql-node-0.56-0.el6.noarch.rpm
-rw-r--r-- 1 root root 50172 Oct 26 15:39 mha4mysql-node-0.56.tar.gz
下载地址:https://github.com/yoshinorim/mha4mysql-manager/wiki/Downloads
安装依赖包(所有节点)
yum install perl-DBD-MySQL -y
所有节点安装node
#安装node包
[root@mysql-db01 tools]# rpm -ivh mha4mysql-node-0.56-0.el6.noarch.rpm
Preparing... ########################################### [100%]
1:mha4mysql-node ########################################### [100%]
创建mha用户(主库)
grant all privileges on *.* to mha@'10.0.0.%' identified by 'mha'; //主库上创建,从库会自动复制(在从库上查看)
创建命令软连接(重要)
//如果不创建命令软连接,检测mha复制情况的时候会报错
ln -s /usr/local/mysql/bin/mysql /usr/bin/mysql
ln -s /usr/local/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog
//在所有节点创建
部署管理节点(mha-manager)
在mysql-db03上部署管理节点
# 安装epel源,软件需要
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
# 安装manager 依赖包
yum install -y perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes
# 安装manager管理软件
rpm -ivh mha4mysql-manager-0.56-0.el6.noarch.rpm
出现的报错
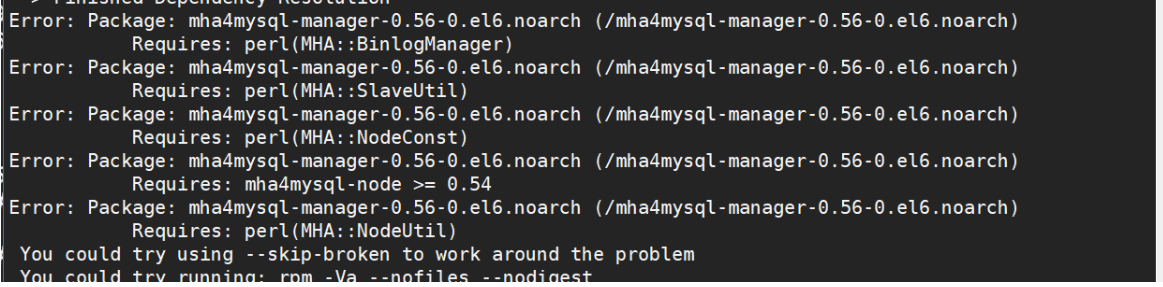
解决办法:
更新epel源 ,yum clean all ,yum makecache
下载epel 7 的源
再次执行下载
创建必须的目录(db03)
mkdir -p /etc/mha //创建配置文件目录
mkdir -p /var/log/mha/app1 ----> 可以管理多套主从复制 ,创建日志目录
编辑MHA配置文件(db03)
[root@mysql-db03 ~]# vim /etc/mha/app1.cnf
[server default]
manager_log=/var/log/mha/app1/manager
manager_workdir=/var/log/mha/app1
master_binlog_dir=/usr/local/mysql/data
user=mha
password=mha
ping_interval=2
repl_user=rep
repl_password=123
ssh_user=root
[server1]
hostname=10.0.0.51
port=3306
[server2]
candidate_master=1
check_repl_delay=0
hostname=10.0.0.52
port=3306
[server3]
hostname=10.0.0.53
port=3306
配置文件详解
[server default]
#设置manager的工作目录
manager_workdir=/var/log/masterha/app1
#设置manager的日志
manager_log=/var/log/masterha/app1/manager.log
#设置master 保存binlog的位置,以便MHA可以找到master的日志,我这里的也就是mysql的数据目录
master_binlog_dir=/data/mysql
#设置自动failover时候的切换脚本
master_ip_failover_script= /usr/local/bin/master_ip_failover
#设置手动切换时候的切换脚本
master_ip_online_change_script= /usr/local/bin/master_ip_online_change
#设置mysql中root用户的密码,这个密码是前文中创建监控用户的那个密码
password=123456
#设置监控用户root
user=root
#设置监控主库,发送ping包的时间间隔,尝试三次没有回应的时候自动进行failover
ping_interval=1
#设置远端mysql在发生切换时binlog的保存位置
remote_workdir=/tmp
#设置复制用户的密码
repl_password=123456
#设置复制环境中的复制用户名
repl_user=rep
#设置发生切换后发送的报警的脚本
report_script=/usr/local/send_report
#一旦MHA到server02的监控之间出现问题,MHA Manager将会尝试从server03登录到server02
secondary_check_script= /usr/local/bin/masterha_secondary_check -s server03 -s server02 --user=root --master_host=server02 --master_ip=192.168.0.50 --master_port=3306
#设置故障发生后关闭故障主机脚本(该脚本的主要作用是关闭主机放在发生脑裂,这里没有使用)
shutdown_script=""
#设置ssh的登录用户名
ssh_user=root
[server1]
hostname=10.0.0.51
port=3306
[server2]
hostname=10.0.0.52
port=3306
#设置为候选master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slave。
candidate_master=1
#默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
check_repl_delay=0
配置ssh信任(所有节点)
#创建秘钥对
[root@mysql-db01 ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa >/dev/null 2>&1
#发送公钥,包括自己
[root@mysql-db01 ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub root@10.0.0.51
[root@mysql-db01 ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub root@10.0.0.52
[root@mysql-db01 ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub root@10.0.0.53
分发完成后测试分发是否成功
for i in 1 2 3 ;do ssh 10.0.0.5$i date ;done
或
[root@db03 ~]# masterha_check_ssh --conf=/etc/mha/app1.cnf
最后一行信息为如下字样即为分发成功:
Thu Dec 28 18:44:53 2017 - [info] All SSH connection tests passed successfully.
启动测试
经过上面的部署过后,mha架构已经搭建完成
# 启动mha
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
启动成功后,检查主库状态
[root@db03 ~]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:3298) is running(0:PING_OK), master:10.0.0.51
ssh免密测试
#测试ssh
[root@mysql-db03 ~]# masterha_check_ssh --conf=/etc/mha/app1.cnf
#看到如下字样,则测试成功
Tue Mar 7 01:03:33 2017 - [info] All SSH connection tests passed successfully.
#测试复制
[root@mysql-db03 ~]# masterha_check_repl --conf=/etc/mha/app1.cnf
#看到如下字样,则测试成功
MySQL Replication Health is OK.
报错:
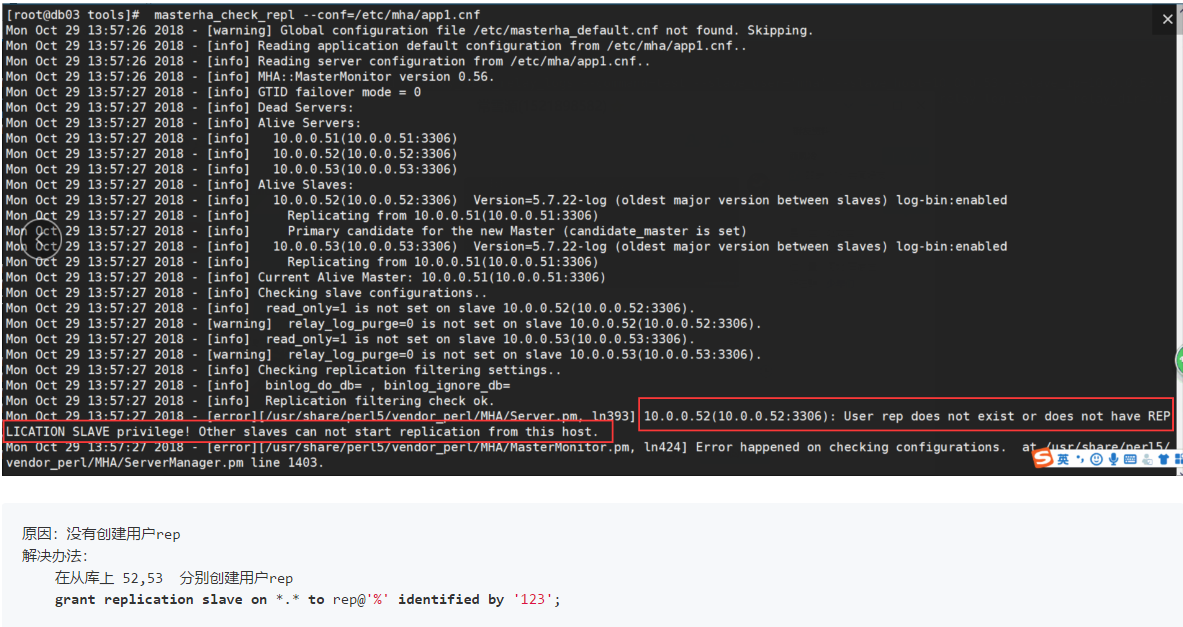
切换master测试
查看现在的主库是哪个
[root@db03 ~]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:11669) is running(0:PING_OK), master:10.0.0.51 ------> 51为主库
手动停止主库
[root@db01 ~]# systemctl stop mysqld
再停止数据的同时查看日志信息的变化
[root@db03 ~]# grep -i "change master to" /var/log/mha/app1/manager

修复主从
启动原主库,添加change master to 信息
[root@db01 ~]# systemctl start mysqld
mysql> CHANGE MASTER TO MASTER_HOST='10.0.0.52', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='123';
mysql> start slave;
查看主从复制状态
mysql> show slave status\G
Master_Host: 10.0.0.52
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
修复MHA
修改app1.cnf配置文件,添加回被剔除主机
[root@db03 ~]# cat /etc/mha/app1.cnf
[binlog1]
hostname=10.0.0.53
master_binlog_dir=/data/mysql/binlog/
no_master=1
[server default]
manager_log=/var/log/mha/app1/manager
manager_workdir=/var/log/mha/app1
master_binlog_dir=/data/mysql
master_ip_failover_script=/usr/local/bin/master_ip_failover
password=mha
ping_interval=2
repl_password=123
repl_user=repl
ssh_user=root
user=mha
[server1]
hostname=10.0.0.51
port=3306
[server2]
hostname=10.0.0.52
port=3306
[server3]
hostname=10.0.0.53
port=3306
检查状态
mha检查复制状态
[root@db03 ~]# masterha_check_repl --conf=/etc/mha/app1.cnf
MySQL Replication Health is OK.
启动mha程序
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
到此主库切换成功
[root@db03 ~]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:11978) is running(0:PING_OK), master:10.0.0.52
实验结束将主库切换回db01
① 停止mha
[root@db03 ~]# masterha_stop --conf=/etc/mha/app1.cnf
Stopped app1 successfully.
② 停止所有从库slave(所有库操作)
stop slave;
reset slave all;
③ 重做主从复制(db02、db03)
CHANGE MASTER TO
MASTER_HOST='10.0.0.51',
MASTER_PORT=3306,
MASTER_AUTO_POSITION=1,
MASTER_USER='repl',
MASTER_PASSWORD='123';
④ 启动slave
start slave; //启动之后检查从库是否为两个yes show slave status\G
⑤ mha检查主从复制
[root@db03 ~]# masterha_check_repl --conf=/etc/mha/app1.cnf
MySQL Replication Health is OK.
⑥ 启动mha
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
//检查切换是否成功
[root@db03 ~]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:12127) is running(0:PING_OK), master:10.0.0.51 //到此主主节点有切回到db01
设置权重
修改[server1]的权重
[server1]
hostname=10.0.0.51port=3306candidate_master=1check_repl_delay=0配置说明:
candidate_master=1 ----> 不管怎样都切到优先级高的主机,一般在主机性能差异的时候用
check_repl_delay=0 ----> 不管优先级高的备选库,数据延时多久都要往那切

















 2693
2693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









