








 本文详细介绍如何使用Hadoop运行WordCount程序,包括启动Hadoop、上传文件至HDFS、执行WordCount任务及查看结果的全过程。同时,针对运行过程中可能出现的错误提供了具体的解决方案。
本文详细介绍如何使用Hadoop运行WordCount程序,包括启动Hadoop、上传文件至HDFS、执行WordCount任务及查看结果的全过程。同时,针对运行过程中可能出现的错误提供了具体的解决方案。
hadoop实现了wordcount.java,并打好了jar包,在目录:
/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar
1.启动hadoop,start-all.sh
2.在hdfs上创建个待分析的文件
[root@master test]# hadoop fs -mkdir -p /test
[root@master test]# hadoop fs -put wordcount.txt /test
[root@master test]# hadoop fs -cat /test/wordcount.txt
3.运行wordcount
命令:hadoop jar jar包 类名 输入路径 输出路径
[root@master mapreduce]# hadoop jar hadoop-mapreduce-examples-3.1.2.jar wordcount /test/wordcount.txt /result
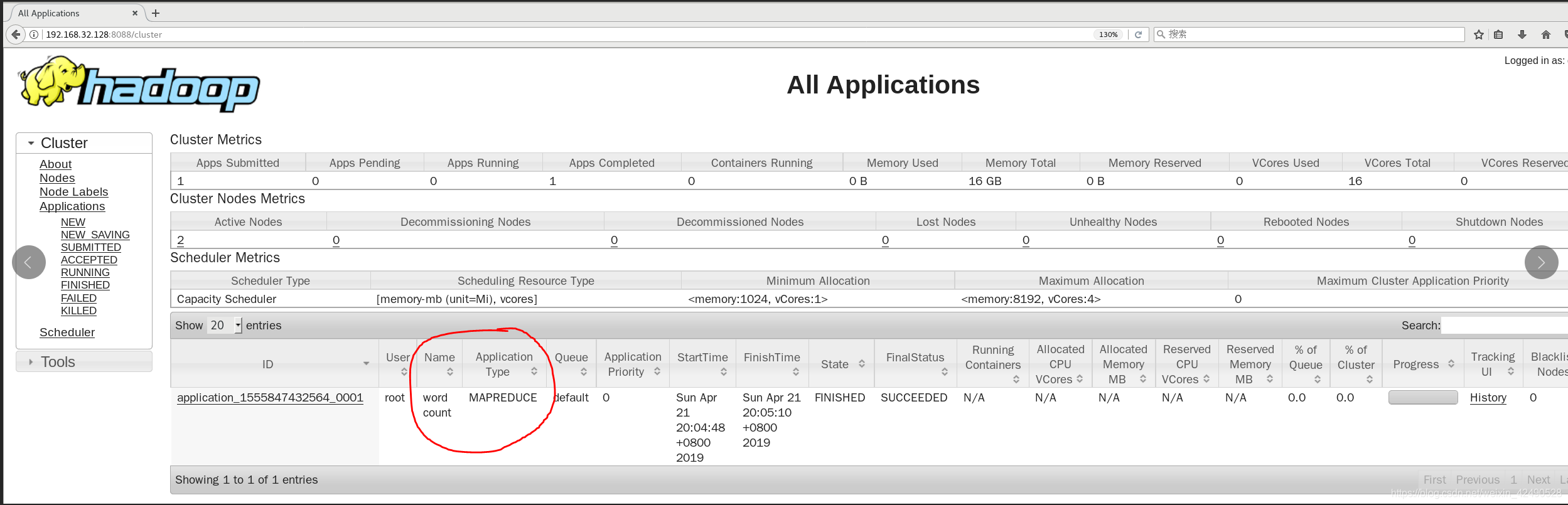
4.查看结果:
[root@master ~]# hadoop fs -ls /result
Found 2 items
-rw-r--r-- 1 root supergroup 0 2019-04-21 20:05 /result/_SUCCESS
-rw-r--r-- 1 root supergroup 1594 2019-04-21 20:05 /result/part-r-00000
[root@master ~]#
结果太长,截选了一些
[root@master ~]# hadoop fs -cat /result/part-r-00000
ANY 1
ASF 1
Apache 2
BASIS, 1
distributed 3
file 3
for 2
governing 1
in 2
one 1
or 3
the 9
this 3
to 3
under 4
use 1
with 2
you 2
[root@master ~]#
遇到错误:
1.hadoop找不到或无法加载主类
org.apache.hadoop.mapreduce.v2.app.MRAppMaster
思路:找不到class path
解决:
查看class path,把得到的结果配置到yarn-site.xml中
[root@hadoop01 ~]# hadoop classpath
yarn-site.xml
<property>
<name>yarn.application.classpath</name> <value>/export/servers/hadoop/etc/hadoop:/export/servers/hadoop/share/hadoop/common/lib/*:/export/servers/hadoop/share/hadoop/common/*:/export/servers/hadoop/share/hadoop/hdfs:/export/servers/hadoop/share/hadoop/hdfs/lib/*:/export/servers/hadoop/share/hadoop/hdfs/*:/export/servers/hadoop/share/hadoop/mapreduce/*:/export/servers/hadoop/share/hadoop/yarn:/export/servers/hadoop/share/hadoop/yarn/lib/*:/export/servers/hadoop/share/hadoop/yarn/*</value>
</property>

















 388
388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









