







实现WordCount
MapReduce实现WordCount
1、需求
- 基于MapReduce开发实现对文件中的单词进行统计,统计每个单词出现的次数
- 将程序写好以后,打成jar包,上传到Linux中,提交给YARN运行
2、分析
Input:
- /wordcount/input/wordcount.txt
- 将每一行数据变成一个keyvalue
- value就是这一行的内容
Map:
- 将value进行分割,得到每个单词,将单词作为key,1作为value输出
Shuffle:
- 分组:按照单词做分组,相同单词的value都在一个迭代器中
- 排序:按照单词做排序
Reduce
- 对每个单词的迭代器中进行聚合
Output:/wordcount/output4
3、代码实现
创建一个子模块,导入Maven依赖
注意:如果apache版本依赖下载不下来,建议你可以从别的人那拷贝一份本地库,覆盖自己的本地库
- Driver类
package bigdata.hanjiaxiaozhi.cn.mapreduce.wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* @ClassName WordCountDriver
* @Description TODO 实现Wordcount程序的Driver类
* 1-包含程序的入口,main
* 2-必须构建一个 MapReduce的job,配置job,提交运行job
* @Date 2020/5/29 15:29
* @Create By hanjiaxiaozhi
*/
public class WordCountDriver extends Configured implements Tool {
/**
*-必须构建一个 MapReduce的job,配置job,提交运行job
* @param args
* @return
* @throws Exception
*/
@Override
public int run(String[] args) throws Exception {
//todo:1-构建一个MapReduce的job对象
Job job = Job.getInstance(this.getConf(),"userwc");//第一个参数是conf对象,第二个程序的名字
//设置可运行的类
job.setJarByClass(WordCountDriver.class);
//todo:2-配置这个job的五个阶段
//配置输入
Path inputPath = new Path(args[0]);//这里不写死,通过参数的形式来传递,用程序的第一个参数来代表输入的路径
TextInputFormat.setInputPaths(job,inputPath);//为当前job设置输入读取的HDFS的路径
//配置Map
job.setMapperClass(WordCountMapper.class);//指定Mapper的类
job.setMapOutputKeyClass(Text.class);//指定Map输出的key的类型
job.setMapOutputValueClass(IntWritable.class);//指定Map输出的Value的类型
//配置shuffle:Shuffle我们不干预,使用默认的
//配置reduce
job.setReducerClass(WordCountReducer.class);//指定Reduce的类
job.setOutputKeyClass(Text.class);//指定Reduce输出的key的类型
job.setOutputValueClass(IntWritable.class);//指定Reduce输出的Value的类型
//配置输出
Path outputPath = new Path(args[1]);//这里不写死,通过参数的形式来传递,用程序的第二个参数来代表输出的路径
TextOutputFormat.setOutputPath(job,outputPath);//为当前的job设置输出的路径,结果保存的路径
//todo:3-提交这个job的运行
return job.waitForCompletion(true) ? 0 : -1;
}
/**
* 负责调用run方法
* @param args
*/
public static void main(String[] args) throws Exception {
//第一个参数:Configuration对象,所有Hadoop程序都需要的
Configuration conf = new Configuration();
//第二个参数:tool对象,你要调用哪个对象的run方法
//第三个参数:将args数组传递过去
int status = ToolRunner.run(conf, new WordCountDriver(), args);
//在run方法中会提交程序运行,返回运行的结果,如果运行结果为0.就正常退出
System.exit(status);
}
}
- Mapper类
package bigdata.hanjiaxiaozhi.cn.mapreduce.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* KEYIN, VALUEIN, KEYOUT, VALUEOUT
* Map输入的Key和Value类型
* Map输出的Key和Value类型
*
* @ClassName WordCountMapper
* @Description TODO 现Wordcount程序的Mapper类
* @Date 2020/5/29 15:48
* @Create By hanjiaxiaozhi
*/
public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
//定义输出的Key
Text outputKey = new Text();
//定义输出的Value
IntWritable outputValue = new IntWritable(1);
/**
* Input阶段传递进来的每一个KeyValue都会调用一次map方法
* @param key:这条数据中的key:行的偏移量
* @param value:这条数据中的value:行的内容
* @param context:上下文对象 ,用于输出的
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//对这一行的内容,进行分割,得到每个单词
String[] words = value.toString().split(" ");
//遍历得到每个单词
for (String word : words) {
//将单词封装成Key
this.outputKey.set(word);
//输出这个单词和1
context.write(this.outputKey,this.outputValue);
}
}
}
- Reducer类
package bigdata.hanjiaxiaozhi.cn.mapreduce.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* KEYIN,VALUEIN,KEYOUT,VALUEOUT
* Reduce输入的Key和Value类型 = Map阶段输出的Key和Value的类型
* Reduce输出的Key和Value类型 = 最后结果的类型
* @ClassName WordCountReducer
* @Description TODO 实现Wordcount程序的MReducer类
* @Date 2020/5/29 16:09
* @Create By hanjiaxiaozhi
*/
public class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
IntWritable outputValue = new IntWritable();
/**
* shuffle输出的每一个KeyValue都会调用一次reduce方法
* @param key:shuffle分组排序以后的每个key
* @param values:这个key对应的value的迭代器结合
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
//从迭代器中取出这个key的每一个value
for (IntWritable value : values) {
sum += value.get();
}
//key不变,sum作为新的value输出
this.outputValue.set(sum);
context.write(key,this.outputValue);
}
}
4、提交运行
- 打成jar包
- 提交yarn集群运行
上传
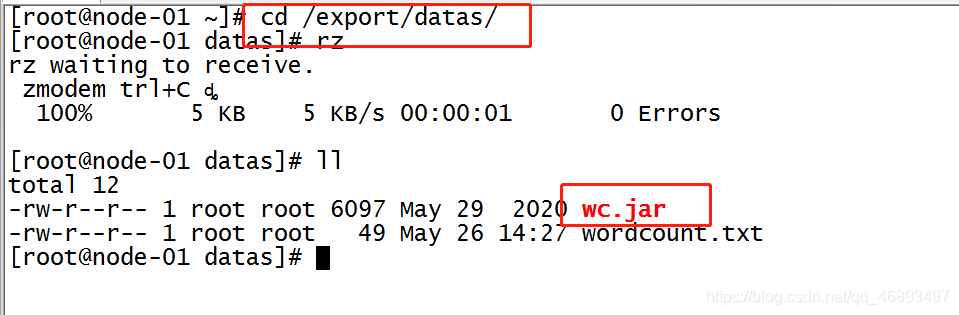
运行
yarn jar /export/datas/wc.jar bigdata.hanjiaxiaozhi.cn.mapreduce.wc.WordCountDriver /wordcount/input/wordcount.txt /wordcount/output4
5、总结
- 开发一个MapReduce程序
- Driver:负责构建一个job,定义五个阶段,提交job运行
- Mapper:负责重写map方法
- Reducer:负责重写reduce方法


















 2080
2080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









