







 本文利用Adaboost算法对手写数字数据集进行分类,通过展示数据、分析迭代次数(分类器数量)对模型性能的影响,以及探讨学习率对模型效果的关键作用。实验表明,增加分类器数量能提升模型表现,而合适的学习率选择对Adaboost算法至关重要。
本文利用Adaboost算法对手写数字数据集进行分类,通过展示数据、分析迭代次数(分类器数量)对模型性能的影响,以及探讨学习率对模型效果的关键作用。实验表明,增加分类器数量能提升模型表现,而合适的学习率选择对Adaboost算法至关重要。
使用Adaboot对手写数字数据集sklearn.datasets.load_digits进行分类。
1.首先对前五个数字进行了展示

2.训练AdaboostClassifier,使用AdaBoostClassifier.stagend_predict(x)可以获得分阶段的预测结果。求得对数据集的随着迭代次数增加(弱分类器的增加)的误差变化情况。
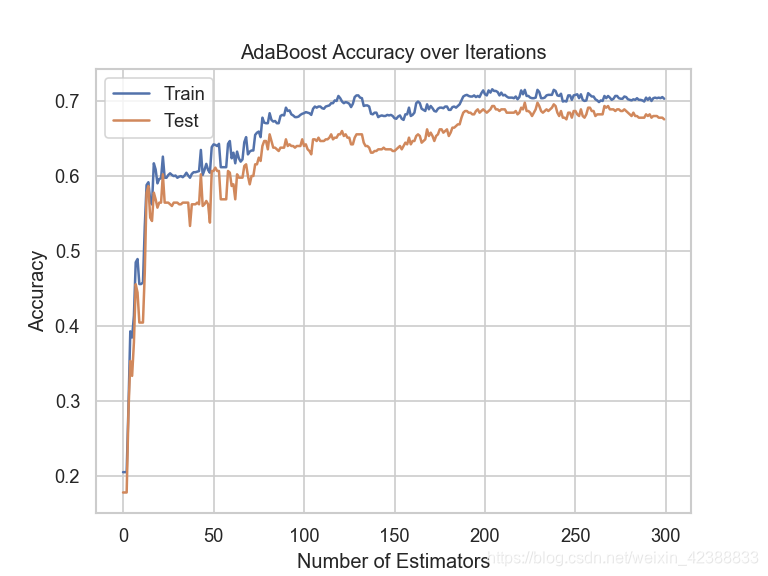
观察可知,随着分类器的增加,Adaboost模型的分类的表现会更好。
3.最后研究了学习率对Adaboost模型的影响。在Adaboost中,学习率即每次新训练的弱分类器对整体预测的影响。选取了,0.125、0.25、0.5、1、2作为学习率使用交叉验证进行对比。
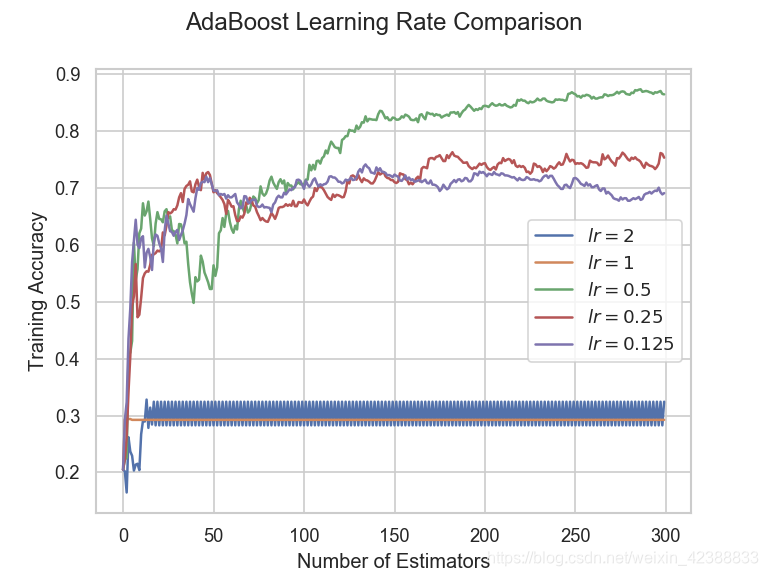
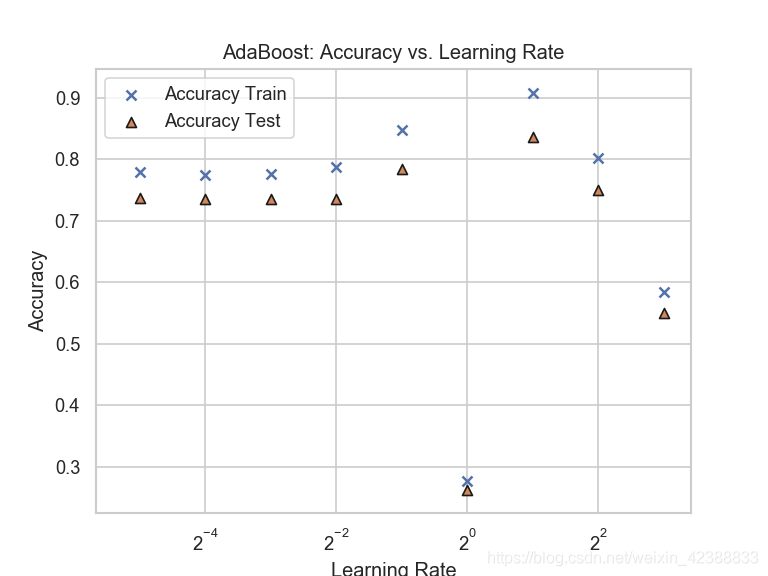
观察可得,学习率的选择对Adaboost算法非常重要,一般对一系列备选学习率进行交叉验证。
# coding: utf-8
# Referenzen
# - https://scikit-learn.org/stable/modules/ensemble.html#ada_boost
# [2] T. Hastie, R. Tibshirani and J. Friedman, The Elements of Statistical Learning, Second Edition, Section 10.13.2, Springer, 2009.
from sklearn.tree import DecisionTreeClassifier
import numpy as np
from sklearn.ensemble import AdaBoostClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import utils
def plot_digit_dataset(X_train: np.ndarray, y_train: np.ndarray) -> None:
"""Plots the first 5 images of the digit dataset."""
plt.figure()
for i, (x_i, y_i) in enumerate(zip(X_train[:5], y_train[:5]), start=1):
plt.subplot(150+i)
plt.imshow(x_i.reshape(8,8),cmap="gray" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 9173
9173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









