







 本文详细解析KNN算法,包括其工作原理、K值选择、距离度量与决策规则,以及在约会网站优化中的实际应用。讨论了K值对精度的影响,以及如何通过kd树加速搜索。
本文详细解析KNN算法,包括其工作原理、K值选择、距离度量与决策规则,以及在约会网站优化中的实际应用。讨论了K值对精度的影响,以及如何通过kd树加速搜索。
算法原理
KNN是监督学习的一种,K近邻法假设给定一个训练数据集,其中的实例类别已定。分类时对新的实例,根据其K个最近邻的训练实例的类别,通过多数表决等方式进行预测。K值的选择、距离度量及分类决策规则是K近邻法的三个基本要素。
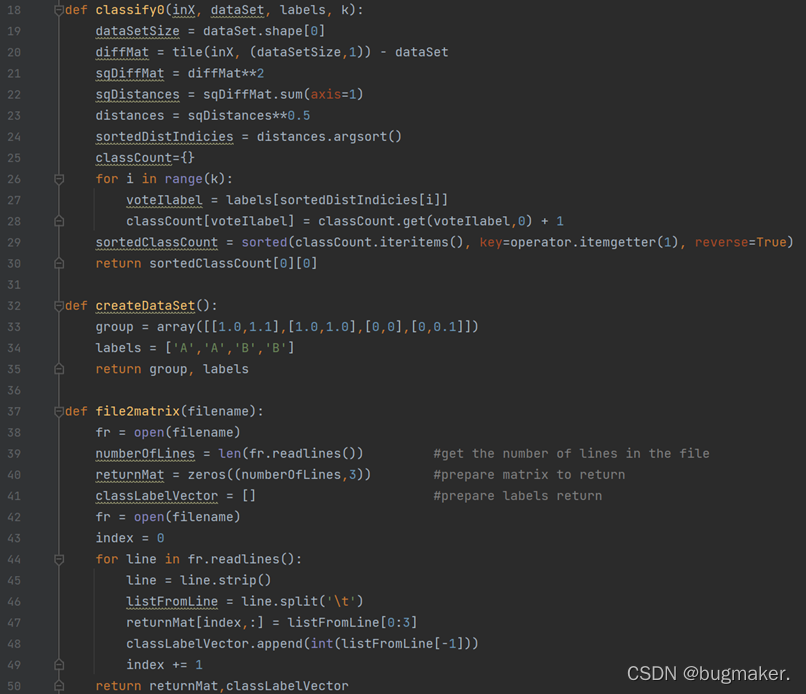
具体来说KNN算法分为以下几步:
- 计算已知类别的数据集中的每个点与当前点之间的距离
- 按照距离递增的顺序将这些已知类别的点排序
- 选取与当前点距离最小的K个点
- 确定前K个点所在类别的出现频率
- 返回前K个点出现频率最高的类别作为当前点的预测分类
K值的选择
K值的选择会对KNN算法的结果产生重大影响,如果选择较小的K,学习的近似误差会减小,只有与输入实例较接近的训练实例才会对预测结果起作用,缺点是“学习”估计误差会增大,预测结果会对邻居的实例点非常敏感,如果邻近点恰好是噪声,预测结果就会出错。
同理,如果选择较大的K值,可以减少估计误差,但是近似误差会增大。
距离的度量
KNN一般选择欧氏距离,当然其他的距离也可以使用。
决策规则
KNN中的决策规则是多数表决,即前K个点出现频率最高的类别作为当前点的预测分类
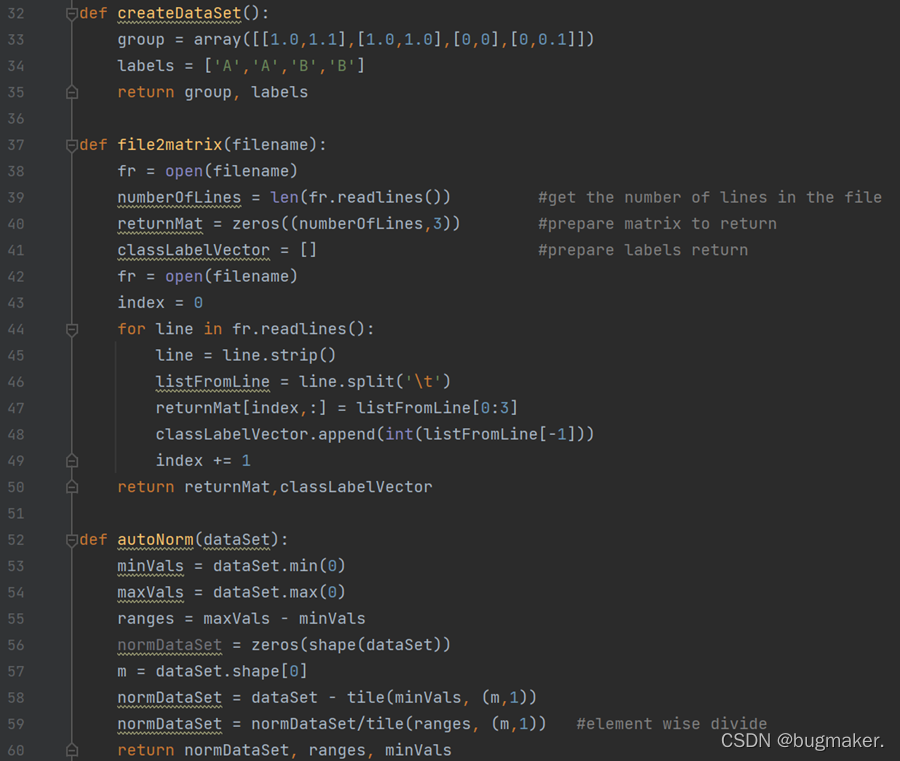
实现
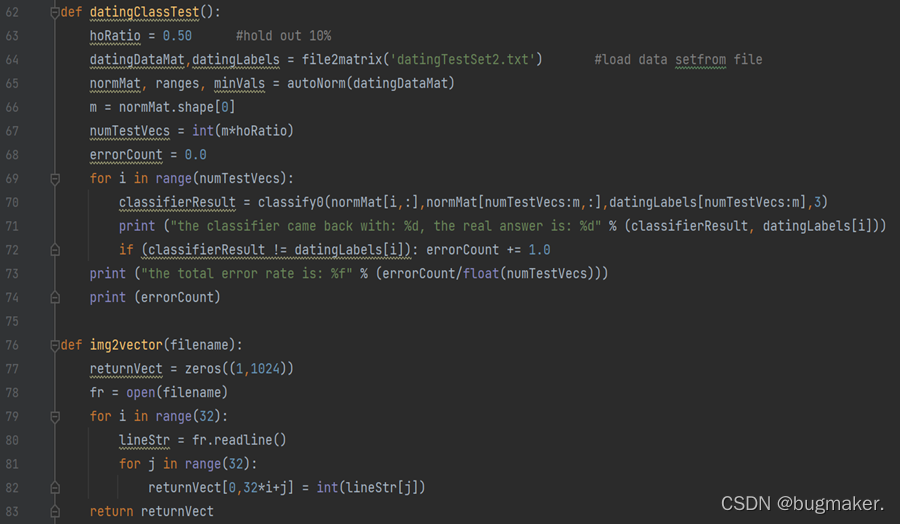
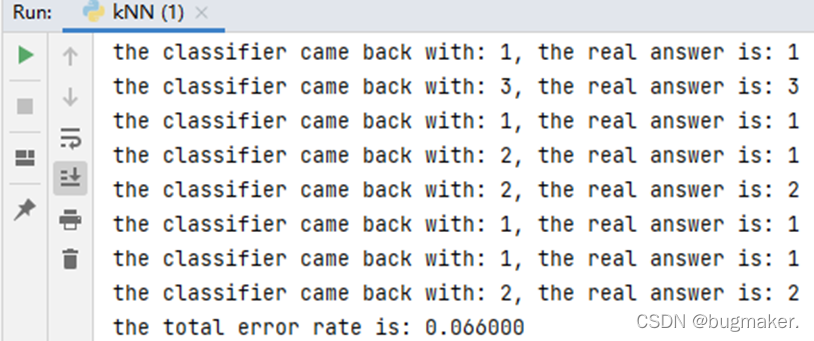
使用KNN算法改进了约会网站的配对效果(使用KNN算法分析约会对象的相关特征,将约会对象划分到确切的分类中,从而为用户提供匹配度更高的约会对象)。实验结果表明,KNN算法处理约会数据集的错误率为6.6%,取得了一个不错的结果。
总结
(1)k近邻法是基本且简单的分类与回归方法。K近邻的基本做法是:对给定的训练实例点和输入实例占,首先确定输入实例上的K个最近邻训练实例点,然后利用这k个训练实例点的类的多数来预测输入实例点的类。
(2)k近邻模型对应于基于训练数据集特征空间的一个划分。k近邻法中,当训练集、距离度量、k值及分类决策规则确定后,其结果唯一确定。
(3)k近邻法三要素:距离度量、k值的选择和分类决策规则。常用的距离度量是欧氏距离及更一般的Lp距离。k值小时,k近邻模型更复杂;k值大时,k近邻模型更简单。k值的选择反映了对近似误差与估计误差之间的权衡,通常由交叉验证选择最优的k。常用的分类决策规则是多数表决,对应于经验风险最小化。
(4)k近邻法的实现需要考虑如何快速搜索k个最近邻点。kd树是一种便于对k维空间中的数据进行快速检索的数据结构。kd树是二叉树,表示对k维空间的一个划分,其每个结点对应于k维空间划分中的一个超矩形区域。利用 kd树可以省去对大部分数据点的搜索,从而减少搜索的计算量。

















 907
907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









