







算法学习、4对1辅导、论文辅导、核心期刊
项目的代码和数据下载可以通过公众号滴滴我
文章目录
一、项目背景
- Kaggle平台数据集,项目目标对流失用户进行预测并找出影响用户流失的重要因子。
- 本项目仅对数据集进行探索性分析,意图找出影响用户流失的重要因子,并给出有业务价值的建议。
分析概述
- 数据集中流失用户的比例约为26%,是一个偏态数据集,整体用户流失率较高
- Contract_Month-to-month与Churn之间相关系数为0.4,呈现较强的正相关关系
- tenure与Churn之间相关系数约为-0.35,呈现较强的负相关关系
- 性别对是否流失没有太大影响
- 老年用户人数不多,但是流失比例较高,流失风险较大
- 没有伴侣的流失风险较高
- 经济不独立的流失风险高
- 未开通服务(网络安全服务、在线备份服务、设备保护、技术支持)的用户- 流失风险较大
- 是否开通网络电视与是否开通网络电影对用户是否流失的影响不大,但未开通的流失风险稍高
- 按月签订合同的用户流失风险较高
- 开通电子账单的用户流失风险较高
- 采用电子支付的用户流失风险很高
- 合同按月签订的用户流失风险较高,流失概率增加10%以上,按年签订的用户不易流失。
- 开通电子账单的用户流失风险较高,流失概率增加约7%
- Contract合同签订方式这一特征对用户是否流失有巨大影响
二、数据说明
该数据集WA_Fn-UseC_-Telco-Customer-Churn.csv共7043行数据,共20个字段,分别是:
| 字段 | 说明 |
|---|---|
| customerID | 用户ID |
| gender | 性别 |
| SeniorCitizen | 是否是老年人(1代表是) |
| Partner | 是否有配偶(Yes or No) |
| Dependents | 是否经济独立(Yes or No) |
| tenure | 用户入网时间 |
| PhoneService | 是否开通电话业务(Yes or No) |
| MultipleLines | 是否开通多条电话业务(Yes 、 No or No phoneservice) |
| InternetService | 是否开通互联网服务(No、DSL数字网络或filber potic光线网络) |
| OnlineSecurity | 是否开通网络安全服务(Yes、No or No internetservice) |
| OnlineBackup | 是否开通在线备份服务(Yes、No or No internetservice) |
| DeviceProtection | 是否开通设备保护服务(Yes、No or No internetservice) |
| TechSupport | 是否开通技术支持业务(Yes、No or No internetservice) |
| StreamingTV | 是否开通网络电视(Yes、No or No internetservice) |
| StreamingMovies | 是否开通网络电影(Yes、No or No internetservice) |
| Contract | 合同签订方式(按月、按年或者两年) |
| PaperlessBilling | 是否开通电子账单(Yes or No) |
| PaymentMethod | 付款方式(bank transfer、credit card、electronic check、mailed check) |
| MonthlyCharges | 月度费用 |
| TotalCharges | 总费用 |
| Churn | 是否流失(Yes or No) |
三、数据处理
3.1 导入包并读取数据
import numpy as np
import pandas as pd
data = pd.read_csv("WA_Fn-UseC_-Telco-Customer-Churn.csv")
data.info()
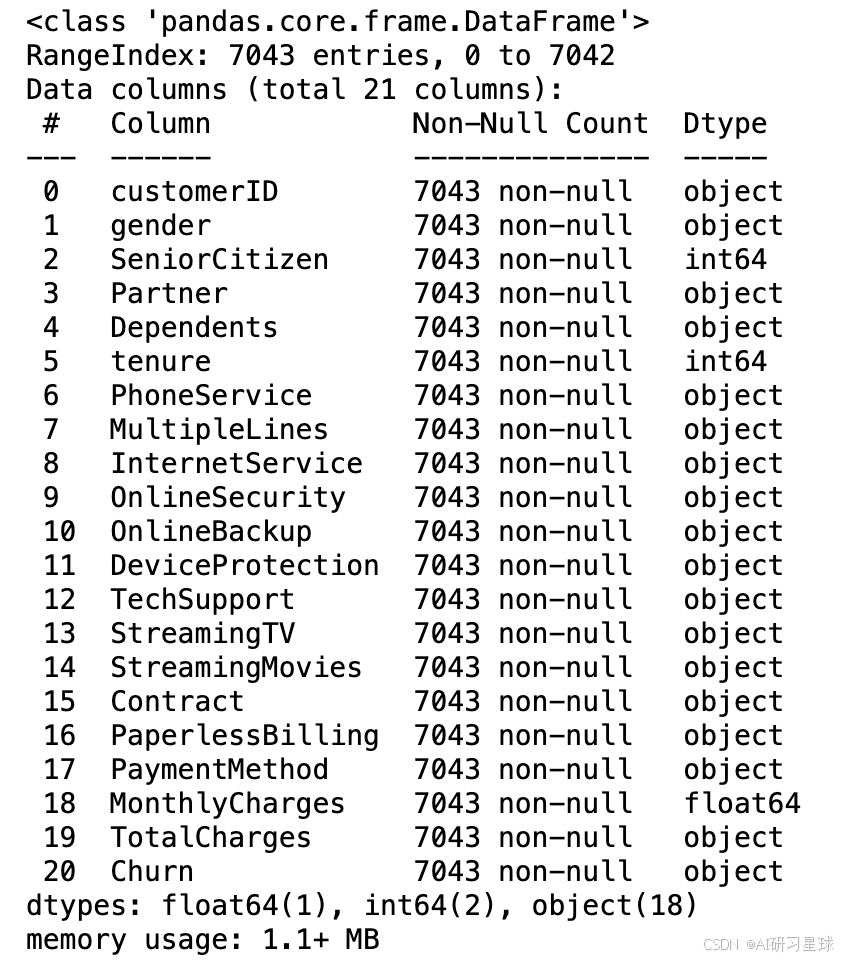
3.2 数据正确性检验
- D列是否有重复值或是空值(info中已验证没有)
- 各个字段的取值是否和给定的取值范围一致
- 数据中是否有重复值(完全相同的两行)
# 判断ID列是否有重复
data['customerID'].nunique() == data.shape[0]
True
# 判断data中是否有重复值
data.duplicated().sum()
0
# 判断data中各个字段的取值是否与数据字典中一致
# 以及判断是否存在额外的空值,如空格表示的空值
for column in data.columns:
print(column + ":" + str(data[column].unique()))
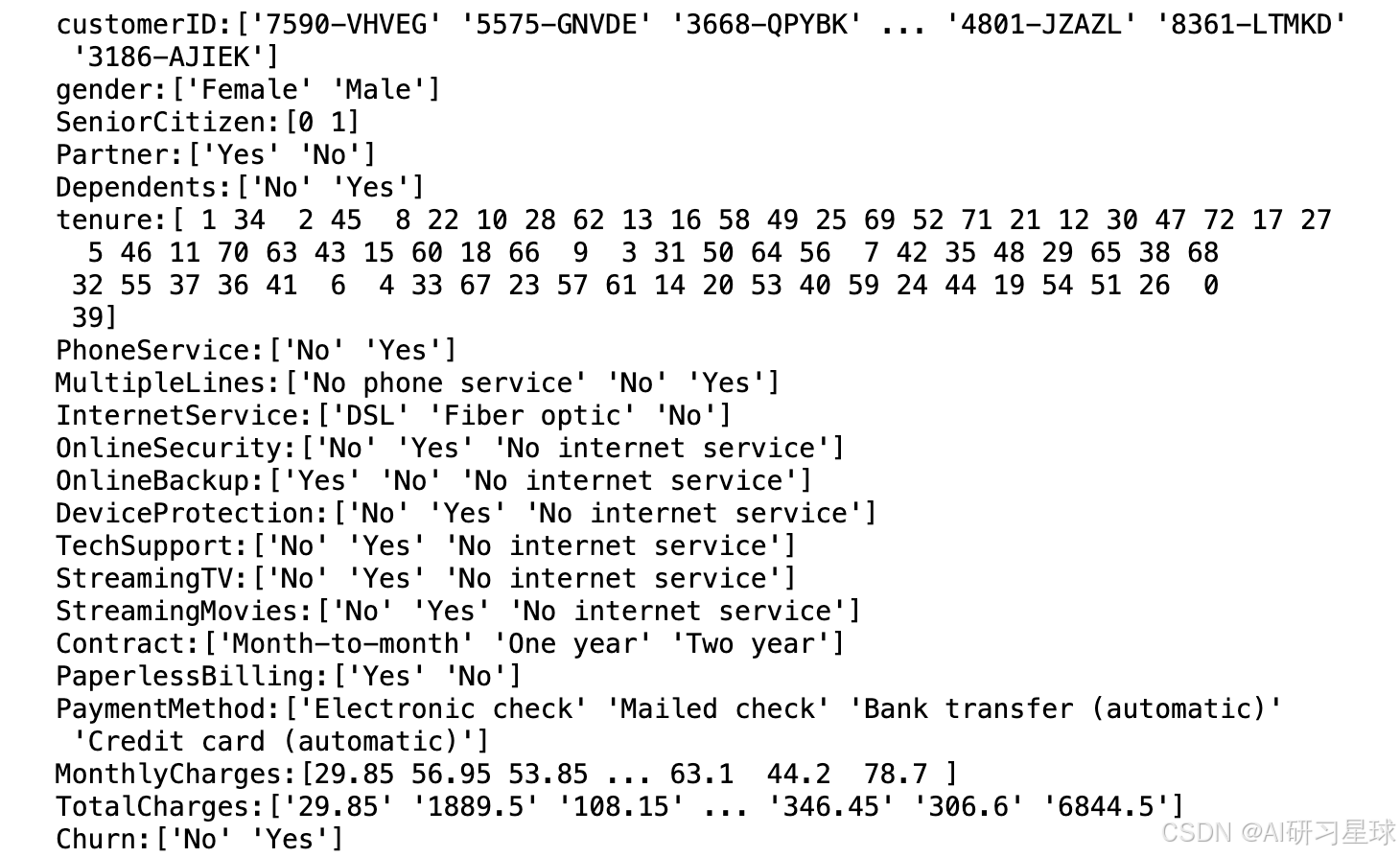
3.3 数据缺失值检验
# 统计数据缺失率
miss_rate = data.apply(lambda x:sum(x.isnull())/len(x),axis=0)
miss_rate
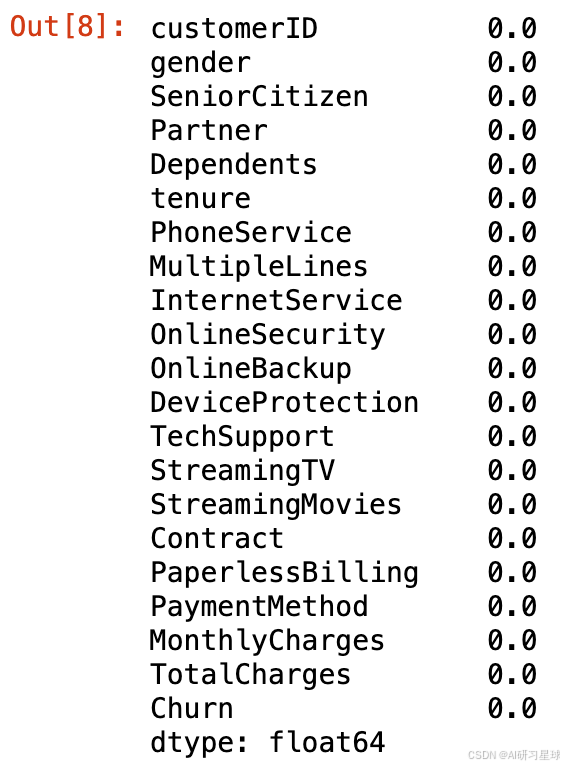
3.4 数据字段类型探索
- LR模型需要对分类变量进行独热编码操作
- object类型无法带入模型进行建模
# 离散字段
category_cols = ['gender', 'SeniorCitizen', 'Partner', 'Dependents',
'PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup',
'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling',
'PaymentMethod']
# 连续字段
numeric_cols = ['MonthlyCharges', 'TotalCharges','tenure']
# 标签
target = 'Churn'
# ID列
ID_col = 'customerID'
# TotalCharges类型转换,报错ValueError: could not convert string to float: ' ',说明其中存在空格
# data['TotalCharges'].astype(float)
# TotalCharges类型转换,空格数据用 0 填充(需要从业务角度理解)
data['TotalCharges'] = data['TotalCharges'].apply(lambda x: 0 if x== ' ' else x).astype(float)
data.info()

3.5 异常值检验
- 离散型变量异常值在前期正确性检验阶段已进行验证,故本次只对连续型变量进行异常值检验
data[numeric_cols].describe()
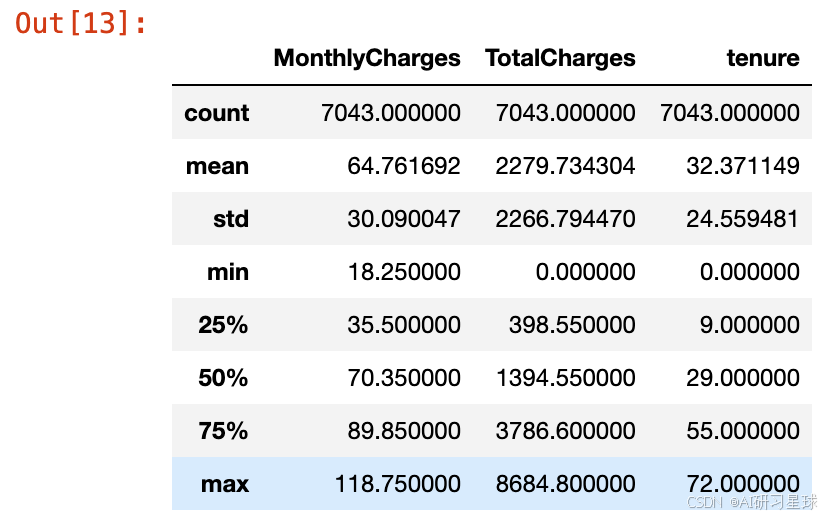
三倍标准差法
for col in numeric_cols:
print(f"{col}:[{data[col].mean() - 3 * data[col].std()},{data[col].mean() + 3 * data[col].std()}]")
MonthlyCharges:[-25.508448832436443,155.0318337536348]
TotalCharges:[-4520.649105503237,9080.117712630881]
tenure:[-41.30729441104045,106.0495917275249]
箱线图法
# 绘制箱线图
import matplotlib.pyplot as plt
plt.figure(figsize=(16, 6), dpi=200)
plt.subplot(121)
plt.boxplot(data['MonthlyCharges'])
plt.xlabel('MonthlyCharges')
plt.subplot(122)
plt.boxplot(data['TotalCharges'])
plt.xlabel('TotalCharges')

- 使用上述两种方案分别进行判断,MonthlyCharges和TotalCharges两者中均不存在异常数据
四、探索性分析
4.1 标签分布分析
y = data['Churn']
print(f'Percentage of Churn:{round(y.value_counts(normalize=True)[1]*100,2)}% --> ({y.value_counts()[1]}customer)')
print(f'Percentage of customer did not churn:{round(y.value_counts(normalize=True)[0]*100,2)} % --> ({y.value_counts()[0]} customer)')
Percentage of Churn:26.54% --> (1869customer)
Percentage of customer did not churn:73.46 % --> (5174 customer)
- 流失用户的比例约为26%,原始数据集是一个偏态数据集
4.2 特征标签相关性分析
- 相关系数矩阵
# 去掉原始数据中ID列
data_temp = data.iloc[:,1:].copy()
# 标签列转换
data_temp['Churn'] = data_temp['Churn'].apply(lambda x: 1 if x=='Yes' else 0)
data_temp['Churn'].replace(to_replace = 'No', value=0, inplace=True)
# 哑变量转换,将分类变量转换为哑变量,否则无法进行相关系数计算
data_dummies = pd.get_dummies(data_temp)
# 计算相关系数矩阵
data_dummies.corr()['Churn'].sort_values(ascending=False)
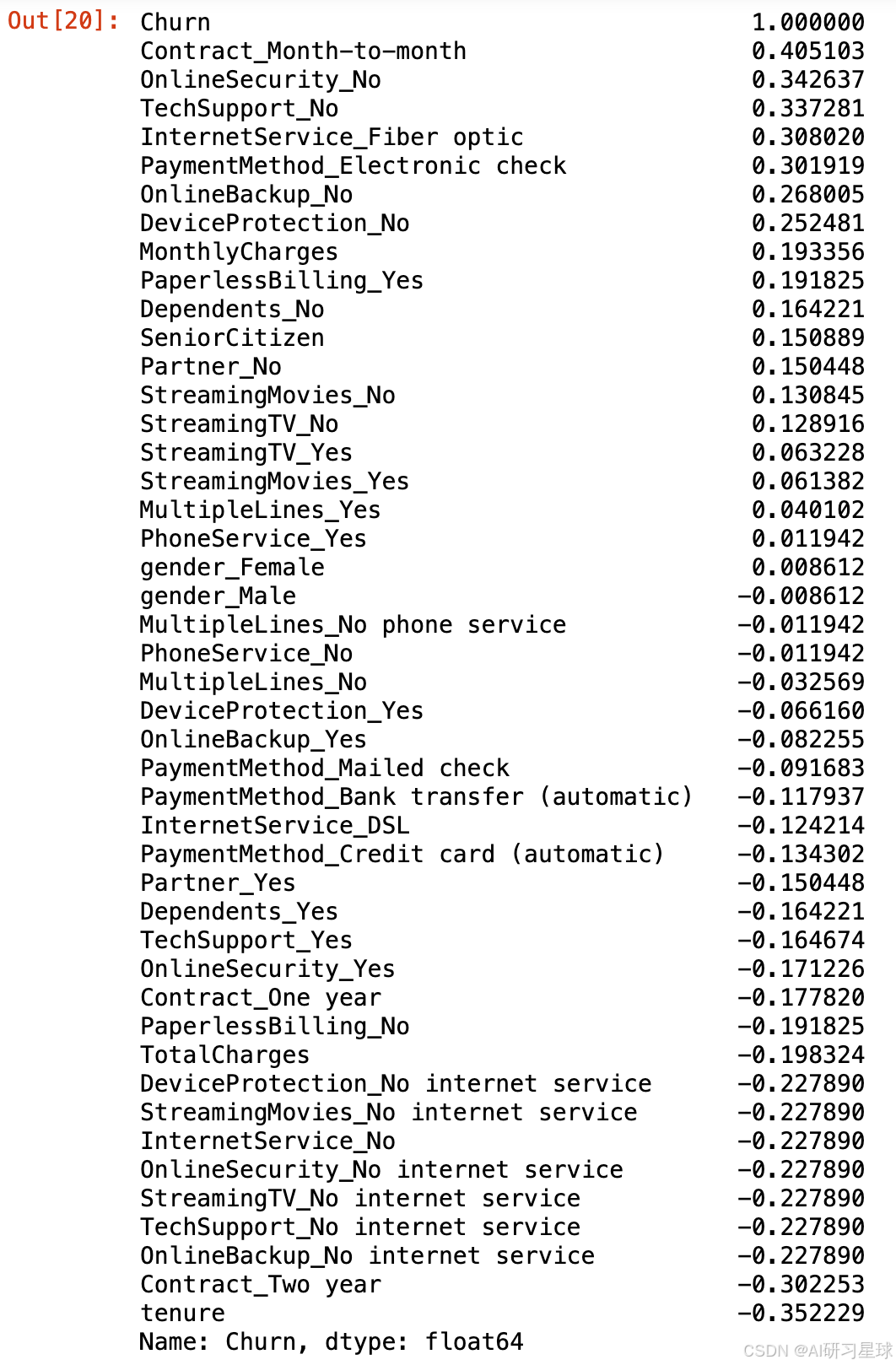
# 相关系数可视化展示
import seaborn as sns
sns.set()
plt.figure(figsize=(15,8), dpi=200)
data_dummies.corr()['Churn'].sort_values(ascending=False).plot(kind='bar')
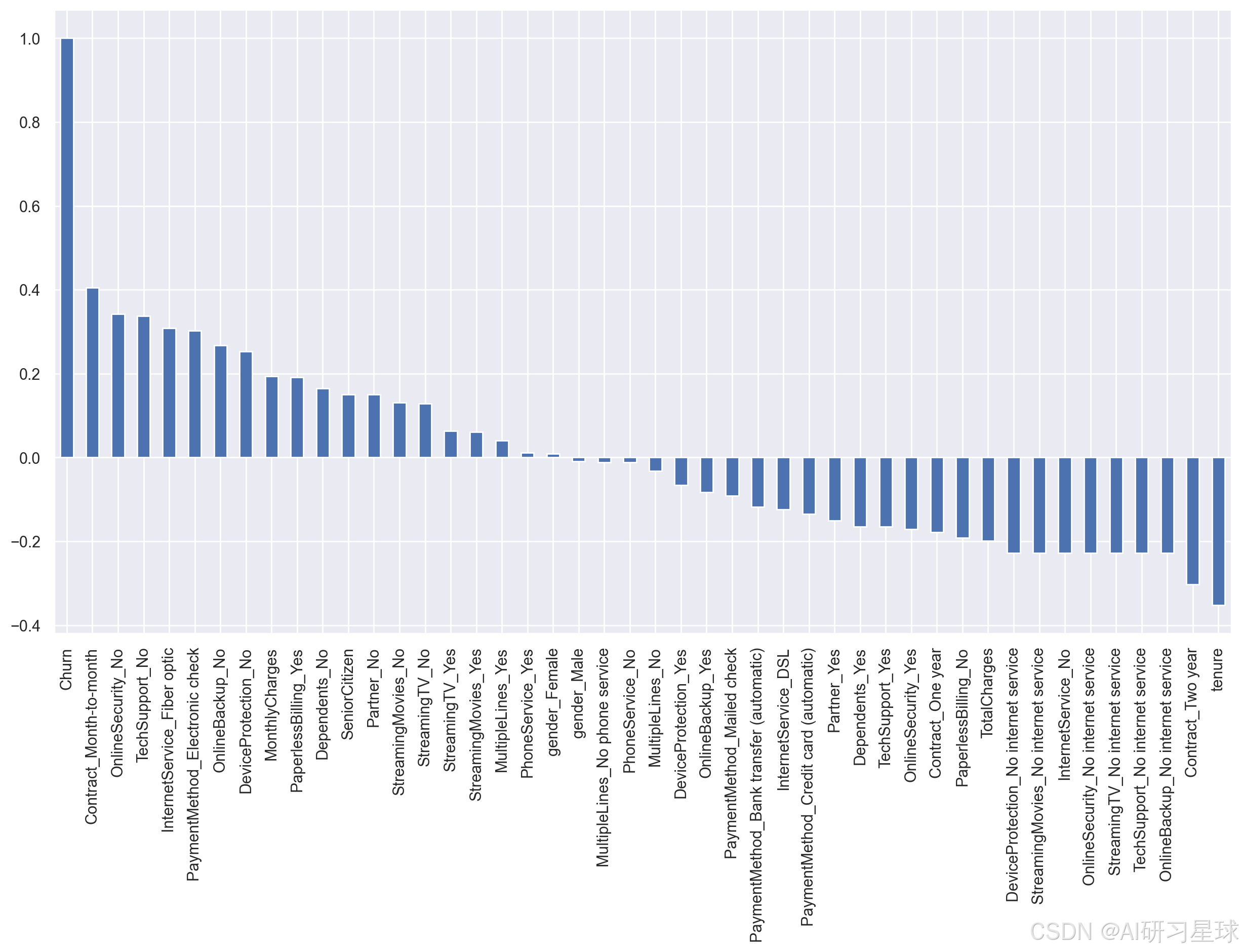
- Contract_Month-to-month与Churn之间相关系数为0.4,呈现较强的正相关关系
- tenure与Churn之间相关系数约为-0.35,呈现较强的负相关关系
4.3 数据可视化探索
col_1 = ["gender", "SeniorCitizen", "Partner", "Dependents"]
fig,axes=plt.subplots(nrows=2,ncols=2,figsize=(16,12), dpi=200)
# 采用原始数据集进行绘制
for i, item in enumerate(col_1):
plt.subplot(2,2,(i+1)) #子图标记从1开始
ax=sns.countplot(x=item,hue="Churn",data=data,palette="Blues", dodge=False)
plt.xlabel(item)
plt.title("Churn by "+ item)
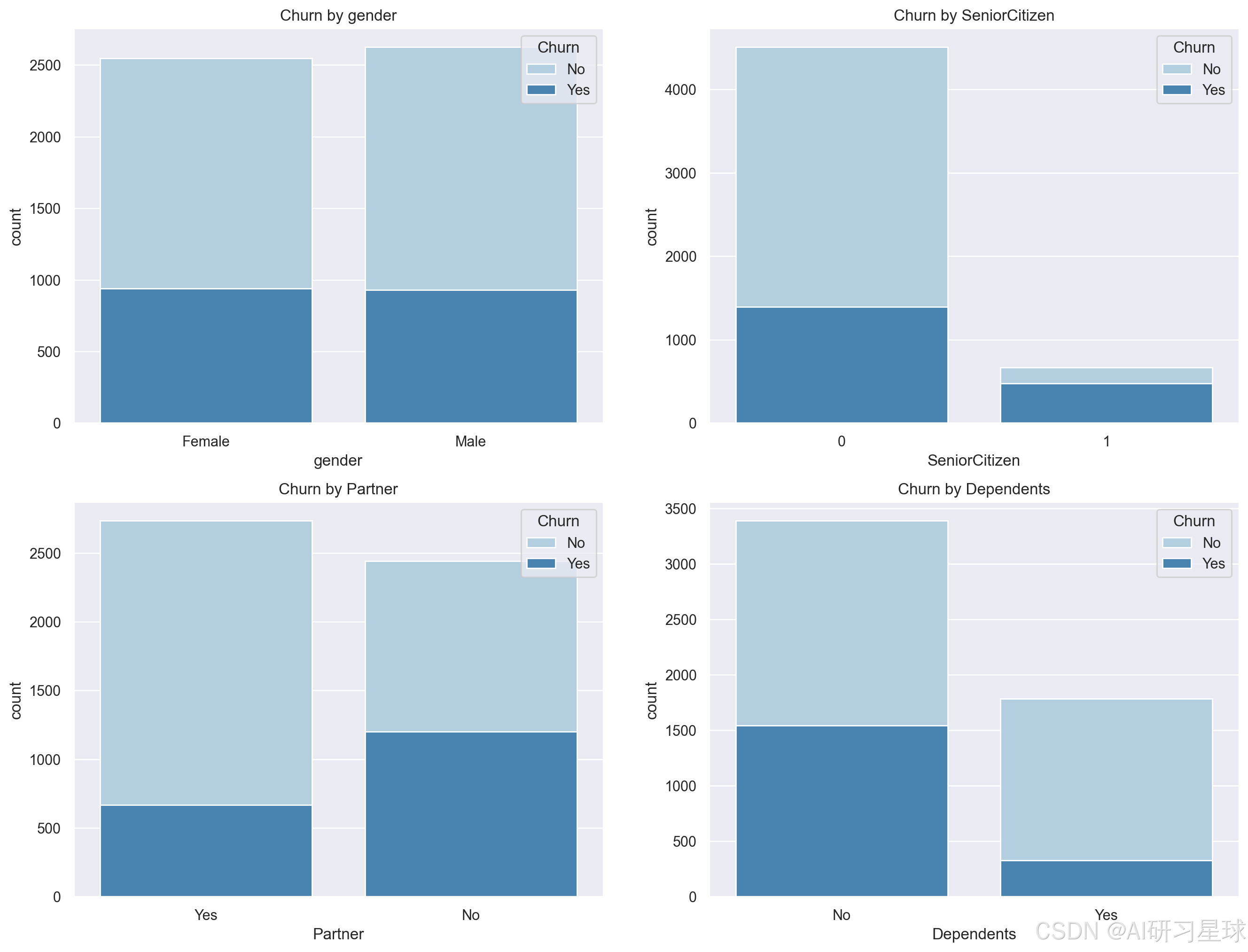
- 性别对是否流失没有太大影响
- 老年用户人数不多,但是流失比例较高,流失风险较大
- 没有伴侣的流失风险较高
- 经济不独立的流失风险高
col_2 = ["OnlineSecurity", "OnlineBackup", "DeviceProtection", "TechSupport", "StreamingTV", "StreamingMovies"]
fig,axes=plt.subplots(nrows=2,ncols=3,figsize=(16,12))
for i, item in enumerate(col_2):
plt.subplot(2,3,(i+1))
ax=sns.countplot(x=item,hue="Churn",data=data,palette="Blues",order=["Yes","No","No internet service"], dodge=False)
plt.xlabel(item)
plt.title("Churn by "+ item)
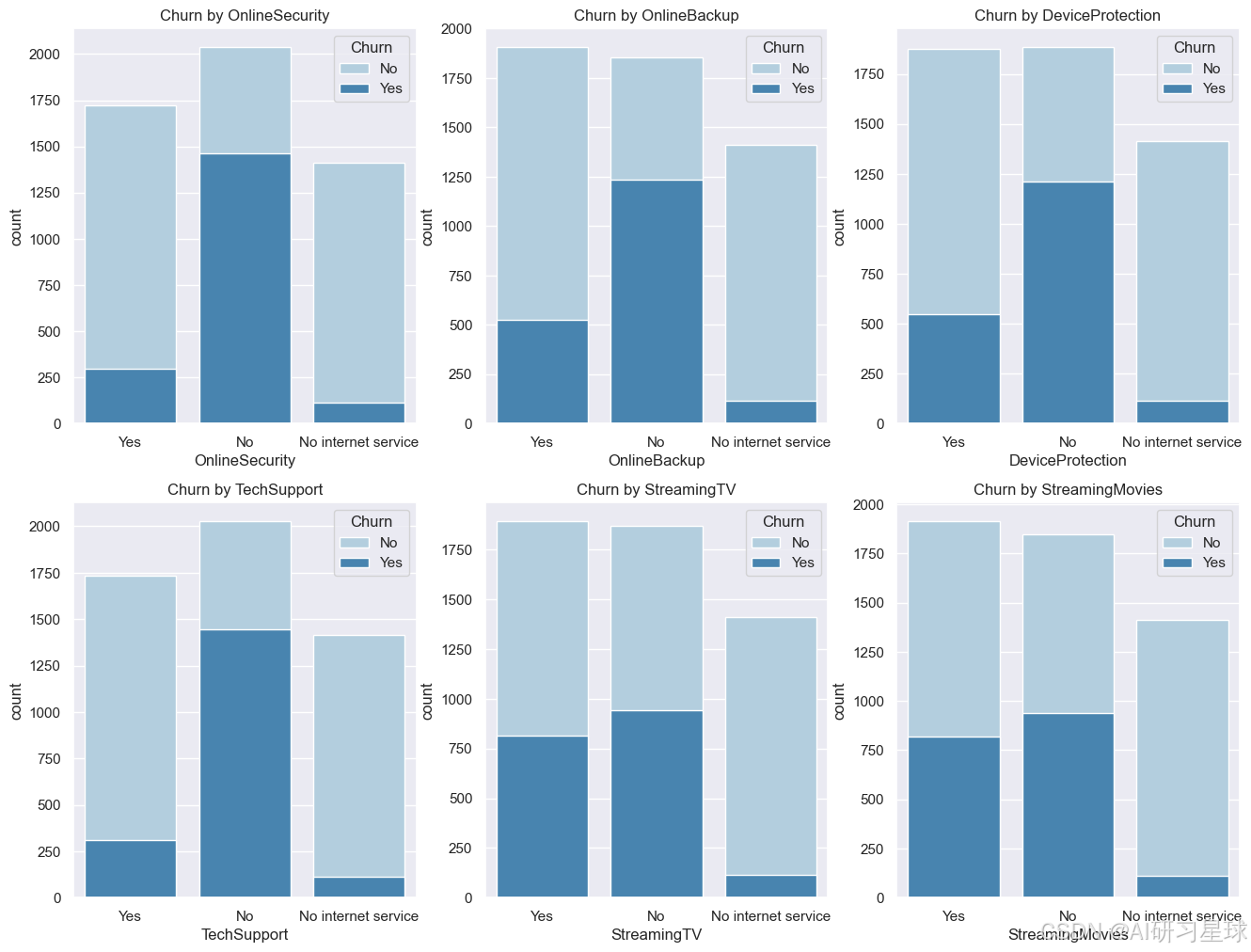
- 未开通服务(网络安全服务、在线备份服务、设备保护、技术支持)的用户流失风险较大
- 是否开通网络电视与是否开通网络电影对用户是否流失的影响不大,但未开通的流失风险稍高
col_3 = ["Contract", "PaperlessBilling", "PaymentMethod"]
fig,axes=plt.subplots(nrows=2,ncols=2,figsize=(16,12))
for i, item in enumerate(col_3):
plt.subplot(2,2,(i+1))
ax=sns.countplot(x=item,hue="Churn",data=data,palette="Blues", dodge=False)
plt.xlabel(item)
plt.title("Churn by "+ item)
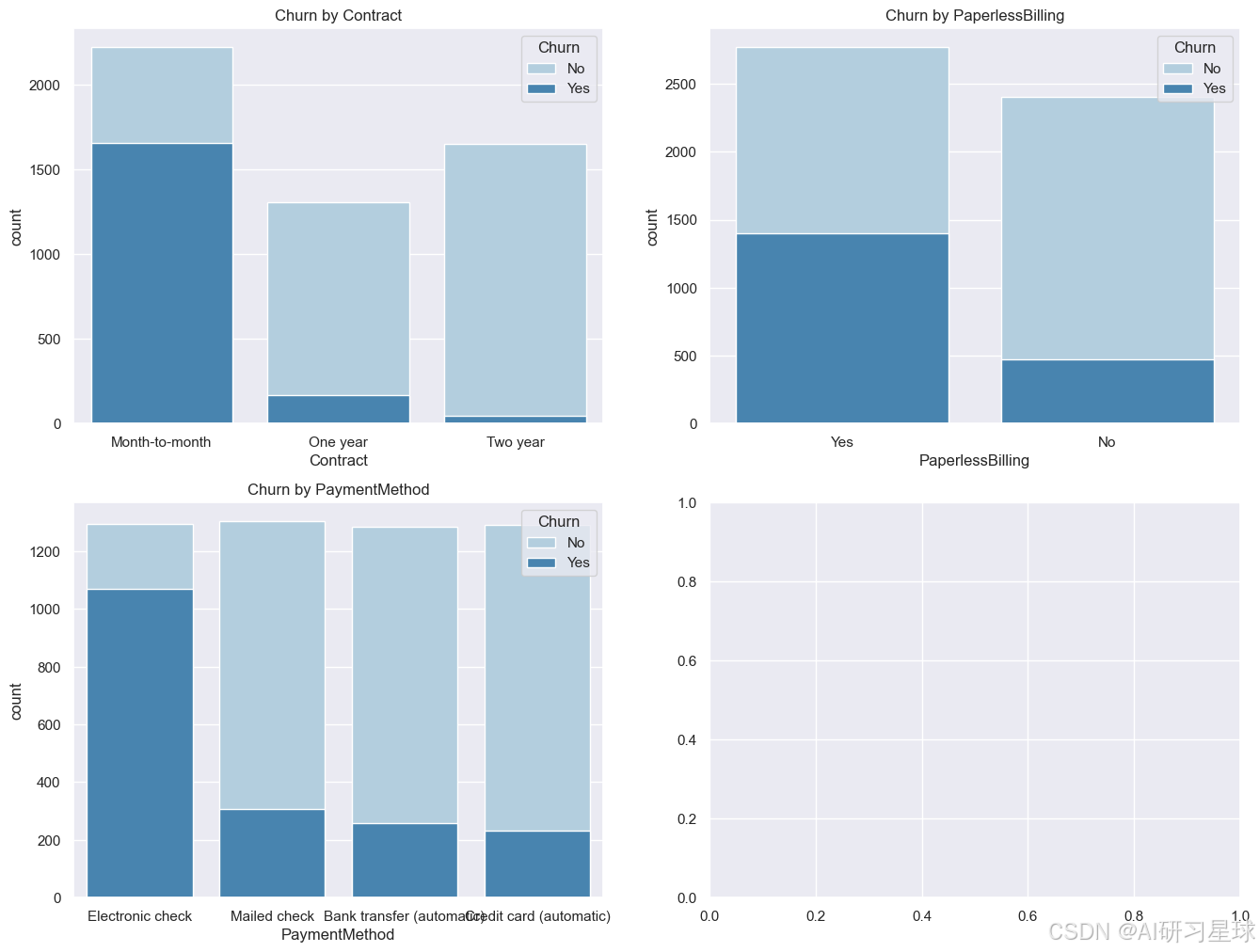
- 按月签订合同的用户流失风险较高
- 开通电子账单的用户流失风险较高
- 采用电子支付的用户流失风险很高,猜测是否是在线支付服务较差
五、逻辑回归建模
- 借助逻辑回归线性方程中对应特征的参数探索影响用户流失的重要因子
- 针对逻辑回归模型来说,对离散变量需要进行独热编码,对连续变量需要进行标准化
5.1 建模
from sklearn import preprocessing
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from sklearn.pipeline import make_pipeline
import time
def cate_colName(Transformer, category_cols, drop='if_binary'):
"""
离散字段独热编码后字段名创建函数
:param Transformer: 独热编码转化器(已经训练好的)
:param category_cols: 输入转化器的离散变量
:param drop: 独热编码转化器的drop参数
"""
cate_cols_new = []
col_value = Transformer.categories_
for i, j in enumerate(category_cols):
if (drop == 'if_binary') & (len(col_value[i]) == 2):
cate_cols_new.append(j)
else:
for f in col_value[i]:
feature_name = j + '_' + f
cate_cols_new.append(feature_name)
return(cate_cols_new)
dataLR = data.copy()
dataLR['Churn'] = dataLR['Churn'].apply(lambda x: 1 if x=='Yes' else 0)
# 切分训练集和测试集
train, test = train_test_split(dataLR, test_size=0.3, random_state=21)
# 划分特征和标签
X_train = train.drop(columns=[ID_col, target]).copy()
y_train = train['Churn'].copy()
X_test = test.drop(columns=[ID_col, target]).copy()
y_test = test['Churn'].copy()
# 数据预处理:对离散变量进行独热编码(跳过二分类变量),对连续变量进行z-score标准化
logistic_preprocess = ColumnTransformer([
('cat', preprocessing.OneHotEncoder(drop='if_binary'), category_cols),
('num', preprocessing.StandardScaler(), numeric_cols)
])
# 实例化逻辑回归模型
logistic_model = LogisticRegression(max_iter=int(1e8))
# 设置pipeline
logistic_pipeline = make_pipeline(logistic_preprocess, logistic_model)
# 网格搜索参数空间
num_pre = ['passthrough', preprocessing.StandardScaler()]
# 注意是两个下划线__
logistic_param = [
{'columntransformer__num':num_pre, 'logisticregression__penalty': ['l1'], 'logisticregression__C': np.arange(0.1, 2.1, 0.1).tolist(), 'logisticregression__solver': ['saga']},
{'columntransformer__num':num_pre, 'logisticregression__penalty': ['l2'], 'logisticregression__C': np.arange(0.1, 2.1, 0.1).tolist(), 'logisticregression__solver': ['lbfgs', 'newton-cg', 'sag', 'saga']},
{'columntransformer__num':num_pre, 'logisticregression__penalty': ['elasticnet'], 'logisticregression__C': np.arange(0.1, 1, 0.1).tolist(), 'logisticregression__l1_ratio': np.arange(0.1, 1.1, 0.1).tolist(), 'logisticregression__solver': ['saga']}
]
# 实例化网格搜索评估器
logistic_GS = GridSearchCV(estimator = logistic_pipeline,
param_grid = logistic_param)
s = time.time()
logistic_GS.fit(X_train, y_train)
print(time.time()-s, "s")
1960.2904598712921 s
logistic_GS.best_score_
0.8046653144016227
logistic_GS.best_params_

from sklearn.metrics import accuracy_score, recall_score, precision_score, f1_score, roc_auc_score
def result_df(model, X_train, y_train, X_test, y_test, metrics=
[accuracy_score, recall_score, precision_score, f1_score, roc_auc_score]):
res_train = []
res_test = []
col_name = []
for fun in metrics:
res_train.append(fun(model.predict(X_train), y_train))
res_test.append(fun(model.predict(X_test), y_test))
col_name.append(fun.__name__) # 输出评估指标函数的名字 .__name__ 函数的名字
idx_name = ['train_eval', 'test_eval']
res = pd.DataFrame([res_train, res_test], columns=col_name, index=idx_name)
return res
result_df(logistic_GS.best_estimator_, X_train, y_train, X_test, y_test)

5.2 流失因子探索
- 借助逻辑回归模型中线性方程的参数探索特征重要性
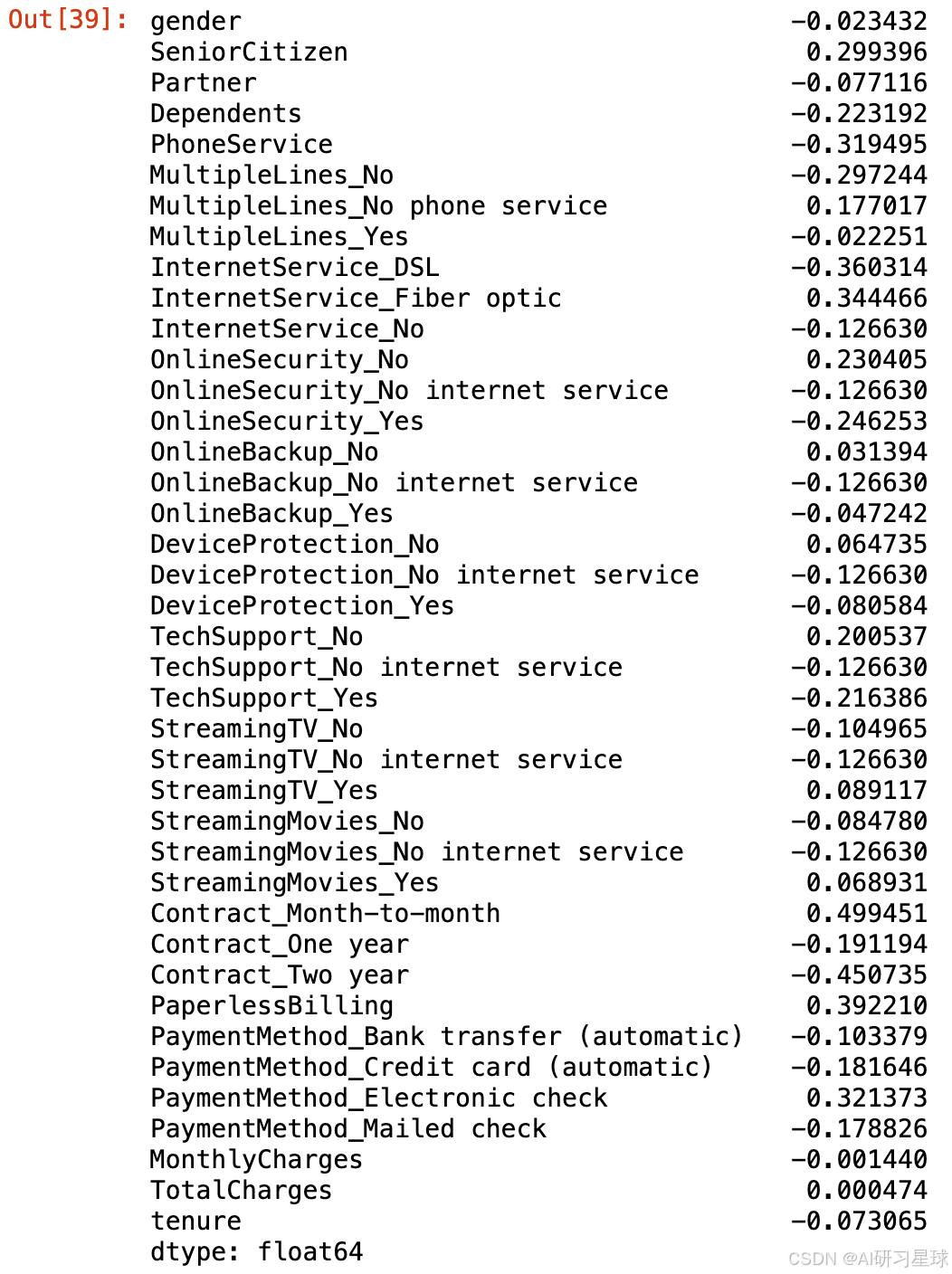
# 获取逻辑回归线性方程的系数
coef = logistic_GS.best_estimator_.named_steps['logisticregression'].coef_
# 将系数与特征对应
onehot_tf = logistic_GS.best_estimator_.named_steps['columntransformer'].named_transformers_['cat']
# 独热编码后离散变量的变量名
category_cols_new = cate_colName(onehot_tf, category_cols)
# 全部特征的变量名
features = category_cols_new + numeric_cols
# 特征和权重之间的对应关系
feature_to_weight = pd.Series(coef.flatten(), index=features)
feature_to_weight
# 可视化展示
plt.figure(figsize=(16, 6), dpi=200)
# 挑选正相关的前10个变量
plt.subplot(121)
feature_to_weight.sort_values(ascending = False)[:10].plot(kind='bar')
# 挑选负相关的前10个变量
plt.subplot(122)
feature_to_weight.sort_values(ascending = False)[-10:].plot(kind='bar')
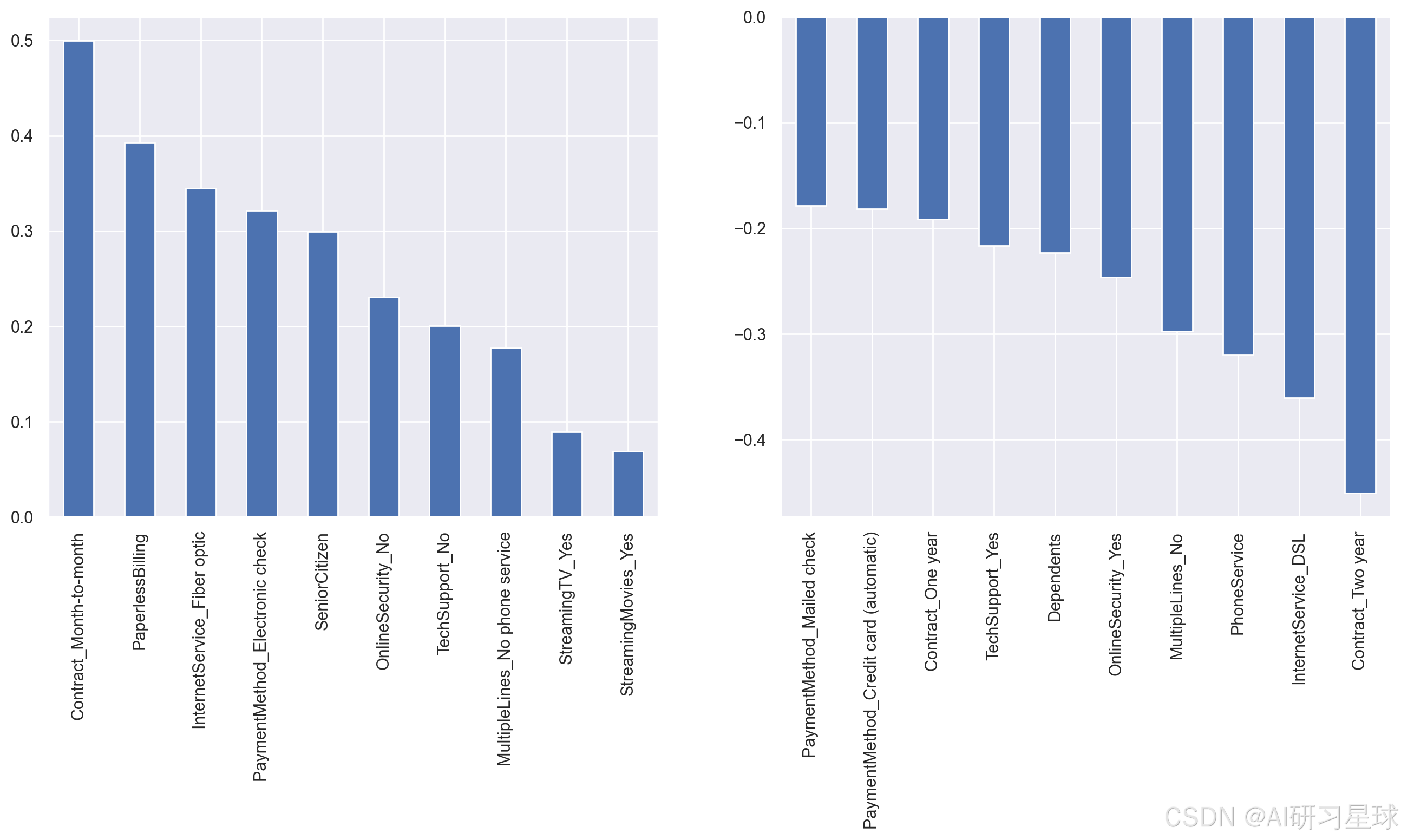
- 合同按月签订的用户流失风险较高,流失概率增加10%以上,按年签订的用户不易流失。
- 开通电子账单的用户流失风险较高,流失概率增加约7%。
六、决策树建模
- 决策树建模无需独热编码,只需进行OrdinalEncoder
- 树模型无需标准化处理
- 树模型具有一定随机性,多次运行得到的结果可能不一样,也不能像逻辑回归那样有具体的参数,故最终结果仅供参考
6.1 建模
from sklearn.tree import DecisionTreeClassifier
# 数据预处理
tree_pre = ColumnTransformer([
('cat', preprocessing.OrdinalEncoder(), category_cols),
('num', 'passthrough', numeric_cols)
])
# 实例化模型
tree_model = DecisionTreeClassifier()
# 构造pipeline
tree_pipeline = make_pipeline(tree_pre, tree_model)
# 构造包含阈值的参数空间
tree_param = {'decisiontreeclassifier__ccp_alpha': np.arange(0, 1, 0.1).tolist(),
'decisiontreeclassifier__max_depth': np.arange(2, 8, 1).tolist(),
'decisiontreeclassifier__min_samples_split': np.arange(2, 5, 1).tolist(),
'decisiontreeclassifier__min_samples_leaf': np.arange(1, 4, 1).tolist(),
'decisiontreeclassifier__max_leaf_nodes':np.arange(6,10, 1).tolist()}
# 网格搜索
tree_GS = GridSearchCV(estimator = tree_pipeline,
param_grid = tree_param)
# 在训练集上进行训练
s = time.time()
tree_GS.fit(X_train, y_train)
print(time.time()-s, "s")
168.0950047969818 s
result_df(tree_GS.best_estimator_, X_train, y_train, X_test, y_test)

tree_GS.best_score_
0.79026369168357
tree_GS.best_params_

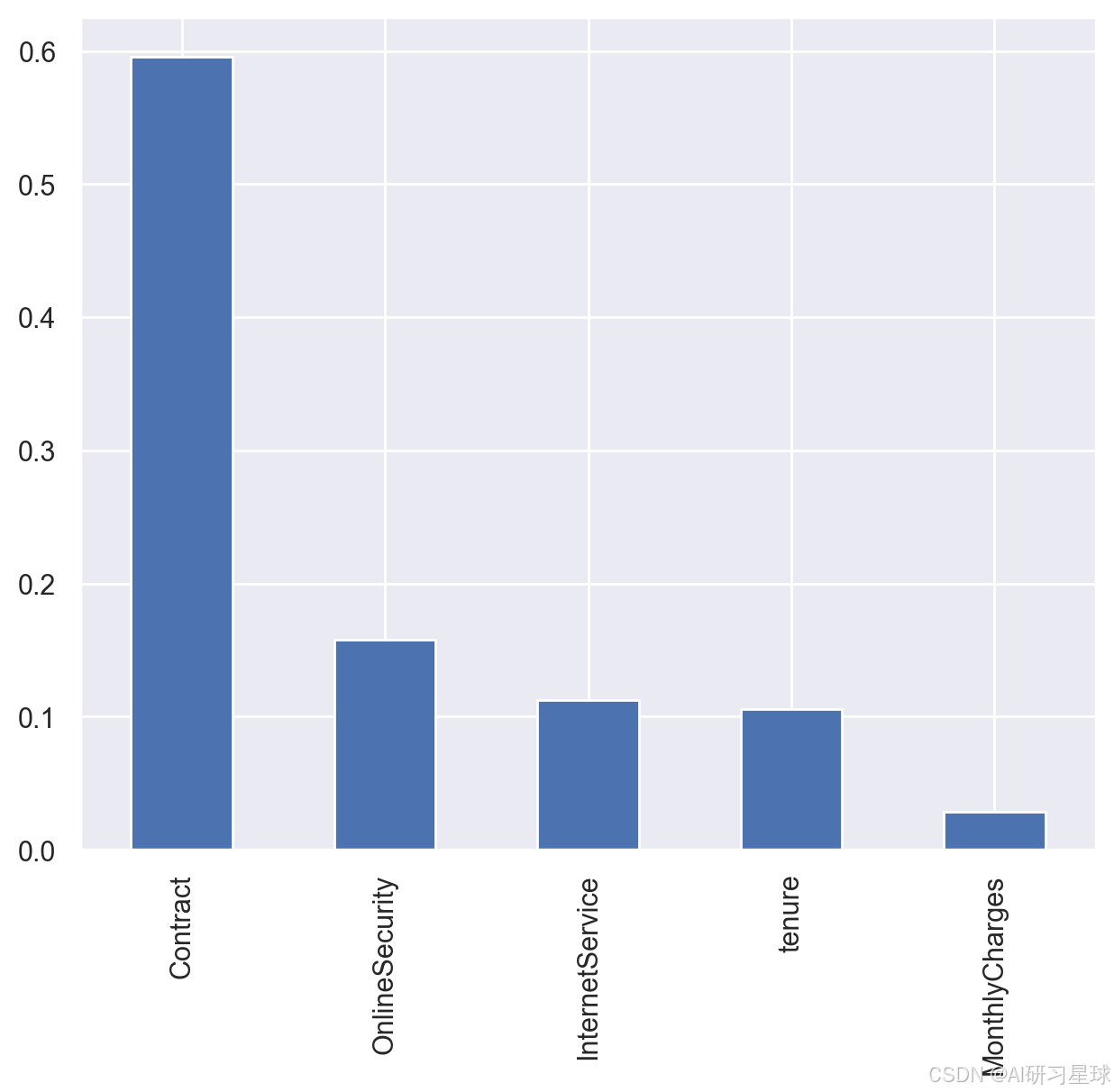
6.2 流失因子探索
- 借助树模型的feature_importances_属性探索各个特征的重要性
feature_importance = tree_GS.best_estimator_.named_steps['decisiontreeclassifier'].feature_importances_
feature_to_importance = pd.Series(feature_importance, index=category_cols + numeric_cols)
feature_to_importance
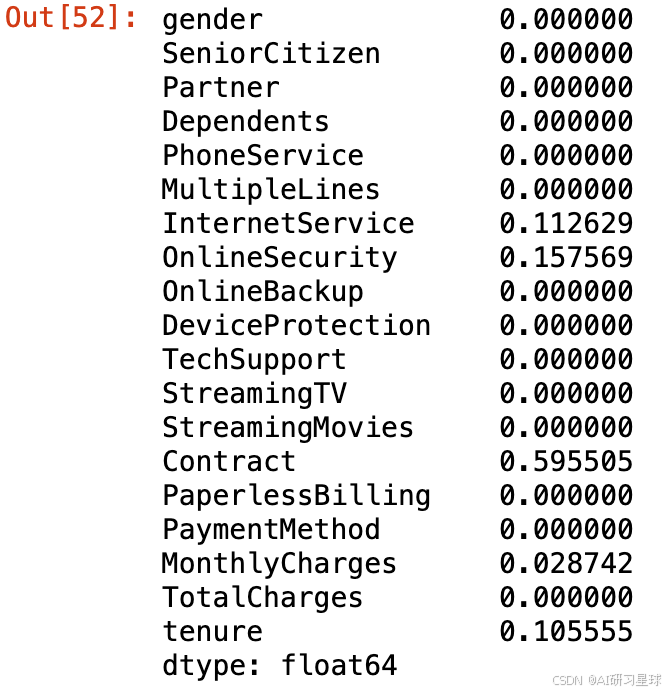
- 共有5个特征参与了决策树模型的构建
# 可视化展示
plt.figure(figsize=(16, 6), dpi=200)
# 挑选正相关的前10个变量
plt.subplot(121)
feature_to_importance.sort_values(ascending = False)[:5].plot(kind='bar')
算法学习、4对1辅导、论文辅导、核心期刊
项目的代码和数据下载可以通过公众号滴滴我



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











