







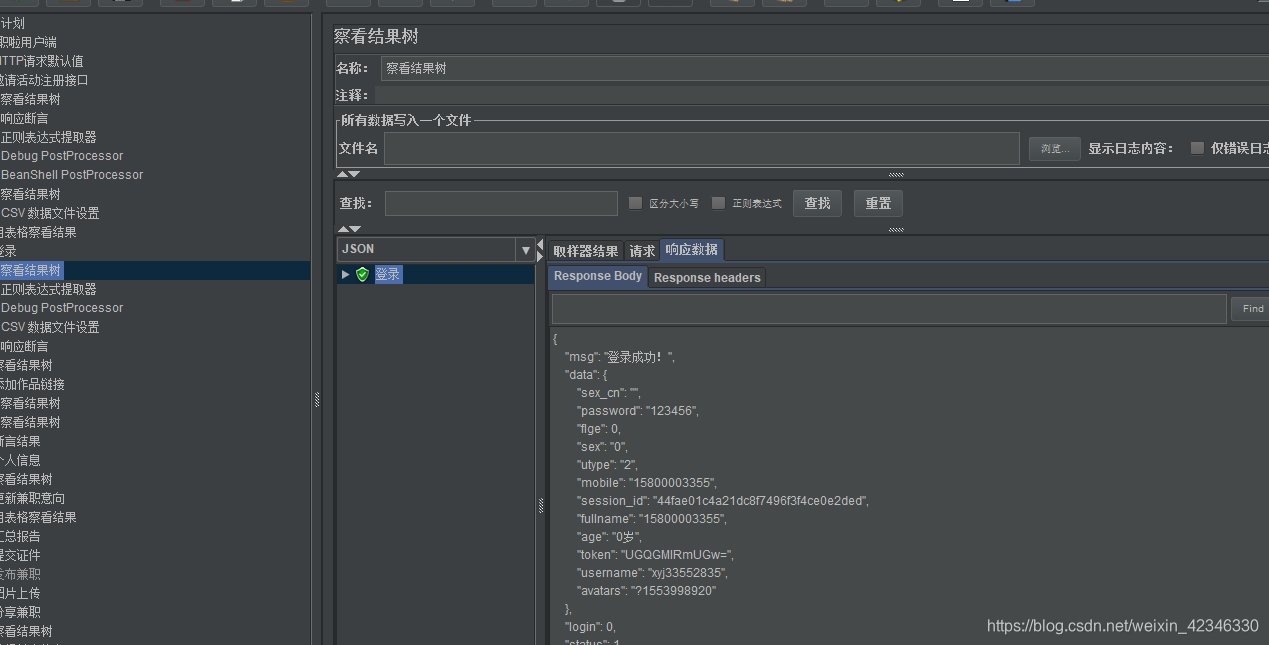
 本文介绍了如何解决JMeter在处理响应结果时出现的中文乱码问题,以及中文断言失败的问题。主要方法包括:1) 修改jmeter.properties文件,将默认编码更改为UTF-8;2) 添加BeanShellPostProcessor后置处理器,设置数据编码为UTF-8;3) 对于断言失败,使用特定的BeanShell脚本进行数据转换。
本文介绍了如何解决JMeter在处理响应结果时出现的中文乱码问题,以及中文断言失败的问题。主要方法包括:1) 修改jmeter.properties文件,将默认编码更改为UTF-8;2) 添加BeanShellPostProcessor后置处理器,设置数据编码为UTF-8;3) 对于断言失败,使用特定的BeanShell脚本进行数据转换。
1.encoding编码修改配置
打开apache-jmeter-2.11\bin\jmeter.properties文件,搜索“encoding”关键字,找到如下配置:
# The encoding to be used if none is provided (default ISO-8859-1)
#sampleresult.default.encoding=ISO-8859-1
将注释删掉,并改成utf-8编码,即:
The encoding to be used if none is provided (default utf-8)
sampleresult.default.encoding=utf-8
重启JMeter即可
2.在相应节点的下方,比如http请求,添加后置处理器–》BeanShellPostProcessor ,然后在其脚本框中添加如下代码
prev.setDataEncoding(“UTF-8”) 即可
3. 关于中文断言结果失败问题,


在后面添加后置处理器BeanShellPostProcessor,添加以下代码 ,再次启动,就可以了
String s=new String(prev.getResponseData(),"UTF-8");
char aChar;
int len= s.length();
StringBuffer outBuffer=new StringBuffer(len);
for(int x =0; x <len;){
aChar= s.charAt(x++);
if(aChar=='\\'){
aChar= s.charAt(x++);
if(aChar=='u'){
int value =0;
for(int i=0;i<4;i++){
aChar= s.charAt(x++);
switch(aChar){
case'0':
case'1':
case'2':
case'3':
case'4':
case'5':
case'6':
case'7':
case'8':
case'9':
value=(value <<4)+aChar-'0';
break;
case'a':
case'b':
case'c':
case'd':
case'e':
case'f':
value=(value <<4)+10+aChar-'a';
break;
case'A':
case'B':
case'C':
case'D':
case'E':
case'F':
value=(value <<4)+10+aChar-'A';
break;
default:
throw new IllegalArgumentException(
"Malformed \\uxxxx encoding.");}}
outBuffer.append((char) value);}else{
if(aChar=='t')
aChar='\t';
else if(aChar=='r')
aChar='\r';
else if(aChar=='n')
aChar='\n';
else if(aChar=='f')
aChar='\f';
outBuffer.append(aChar);}}else
outBuffer.append(aChar);}
prev.setResponseData(outBuffer.toString());
---------------------

















 1611
1611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









