







 本文介绍了RDMA中MPA(Marker PDU Aligned framing)协议的重要作用,它作为DDP(Direct Data Placement)和TCP之间的适配层,解决了基于消息的DDP与基于流的TCP之间的数据边界识别问题。MPA通过插入头部信息、Marker以及CRC校验来确保数据传输的正确性,并支持乱序接收,提高处理效率。文章详细阐述了MPA的报文格式、FPDU对齐、协商流程以及发送和接收方的行为,帮助读者理解MPA的工作机制。
本文介绍了RDMA中MPA(Marker PDU Aligned framing)协议的重要作用,它作为DDP(Direct Data Placement)和TCP之间的适配层,解决了基于消息的DDP与基于流的TCP之间的数据边界识别问题。MPA通过插入头部信息、Marker以及CRC校验来确保数据传输的正确性,并支持乱序接收,提高处理效率。文章详细阐述了MPA的报文格式、FPDU对齐、协商流程以及发送和接收方的行为,帮助读者理解MPA的工作机制。
 https://blog.youkuaiyun.com/bandaoyu/article/details/120485737
https://blog.youkuaiyun.com/bandaoyu/article/details/120485737简略
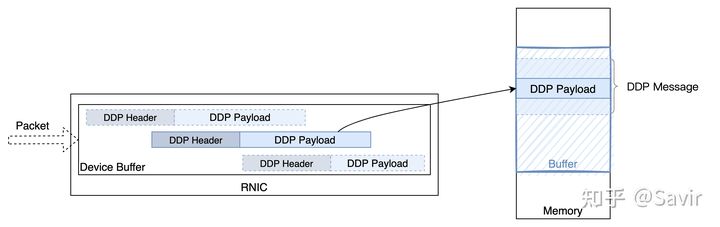
MPA负责在TCP层的负载中标记和识别出DDP Segment的边界,起到承上启下的作用,使得DDP及其上层协议可以适配TCP/IP协议栈。
正文
转自:https://zhuanlan.zhihu.com/p/435467605 作者:Savir
本文欢迎非商业转载,转载请注明出处。
我们在之前的文章中介绍了iWARP协议栈中的DDP和RDMAP层,它们分别起到了实现零拷贝和向上层提供RDMA语义的功能。本文中,我将给大家介绍iWARP协议栈中的最后一层,也是最复杂的一层——MPA。它负责在TCP层的负载中标记和识别出DDP Segment的边界,起到承上启下的作用,使得DDP及其上层协议可以适配TCP/IP协议栈。
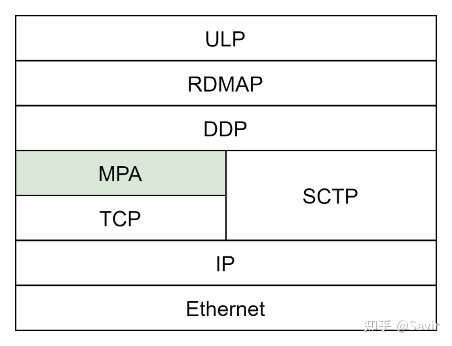
MPA在iWARP协议栈中的位置
阅读本文前,建议回顾下《DDP》一文。
概述
MPA的全称是Marker PDU(Protocol Data Unit) Aligned framing,其作为适配层,在基于消息的DDP和基于字节流的TCP协议间做转换。
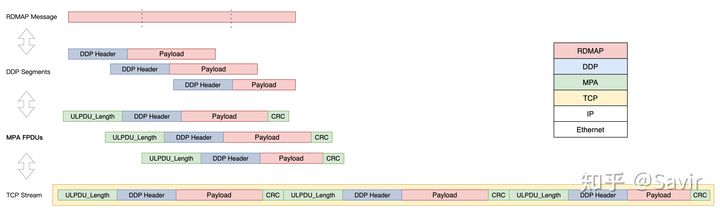
注意图中并没有表示出RDMAP Header,TCP Header等
读者可能会问“基于流”和“基于消息”是什么意思呢?它们是在计算机网络中传输信息两种模式,基于流的模式被称为Stream-based或者Bytestream-based,基于消息的模式被称为Message-based。它们的区别在于从协议的上层用户的视角来看, 数据是如何被协议"组织"到一起的。
基于流的协议
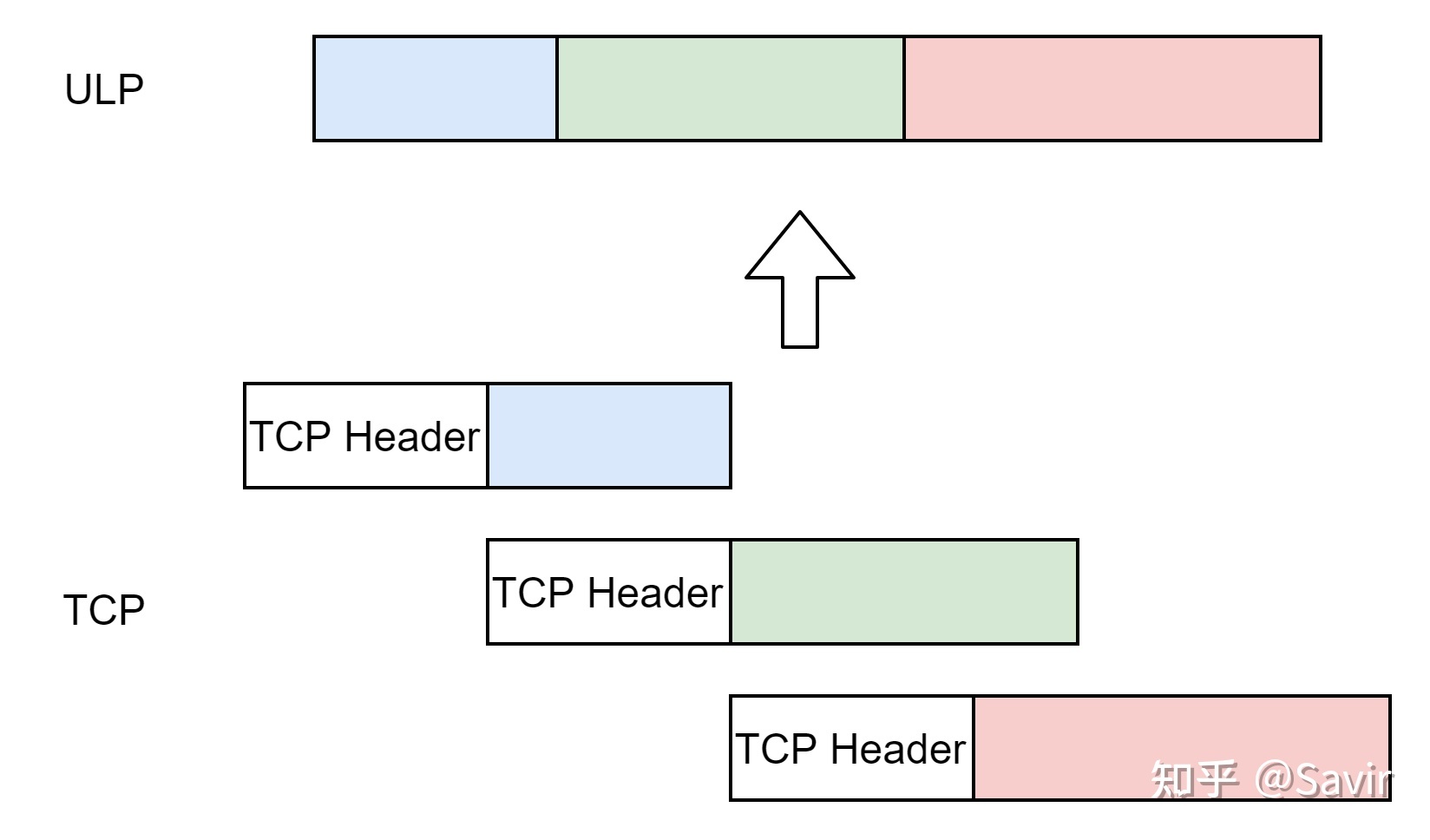
说到流,我们很容易想到水流和电流这种在某种通道里连续不断流动的介质,数据流也是如此。基于流的协议就像打电话,信息是连续不断的。
这种模式最典型的例子就是TCP协议,对于TCP层的ULP来说,它把数据交给TCP缓冲区后,TCP按照分段规则将其分段后交给IP层,这个分段大小与ULP的数据长度没有任何关系。TCP不关心数据的分界,它只保证数据能够准确、按照顺序的到达。至于如何分割和解析数据,那是上层用户的事情。
假如我们的应用想要发送“Hello World”,“This is a test”两句话给对端,虽然在应用层它们是两个独立的句子,但是基于TCP时,它们会被视为一条流,然后按照TCP的规则进行分段。接收端的用户可能从TCP层接收到前后三个分段“Hello Wo”、“rldThis i”、和“s a test”,即一系列有序的分段,这些分段连在一起就是字节流。当然,也可能被分段成”Hell","o Wo","rldT",“his ”,"is a",“ tes”和“t"或者其他不等长的形式。
但是无论中间怎么分段,从接收端的ULP来看,TCP层将分段还原之后传递给它的报文都是:“Hello WorldThis is a test ”,两个句子“黏”在了一起。此时必须依靠ULP自己的能力来将这个流还原成原本的信息,比如提前在其中加入标点符号分隔符等手段。
基于消息的协议
基于消息的协议就像是发短信,每一条短信都是完整而独立的。
这种模式一个典型的例子就是UDP,对于使用UDP协议通信的两端的ULP来说。发送端每次发送的数据有多长,接收端收到的就有多长;发送端发送几个消息,接收端就会接收几个消息。
而如果基于UDP的话,发送端如何分隔信息,接收端还会原封不动的收到信息,只是不保证顺序。还是举上面的例子,接收端一定会收到两个数据报:“This is a test”,“Hello World”。消息一定是有头有尾的到达的,至于顺序和可靠性,需要上层来保证。
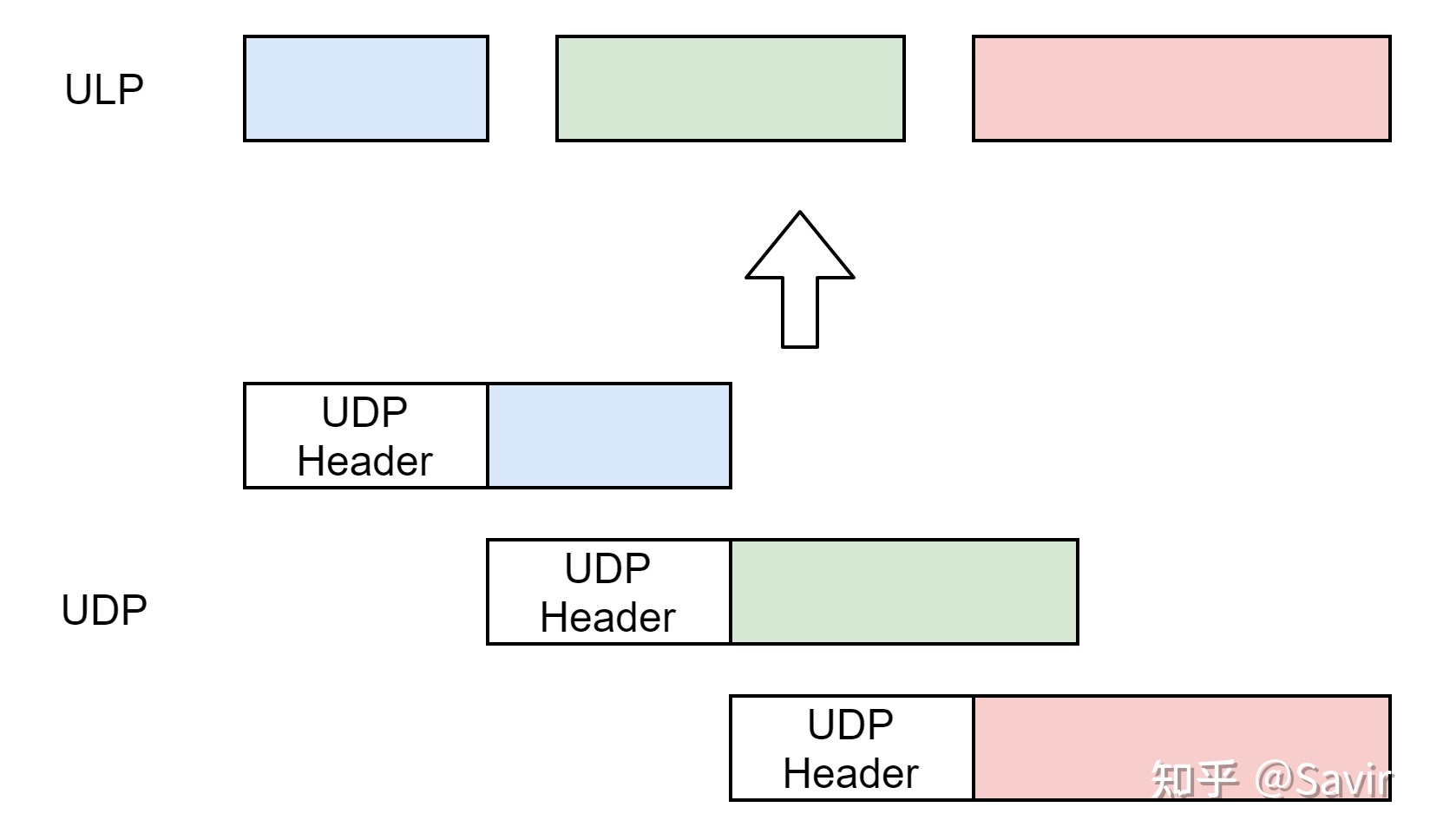
iWARP协议栈中的DDP层就是一种基于消息的协议,接收端的网卡每收到一个DDP分段,都可以根据其内容进行内存拷贝工作。
在有了上面的背景知识之后,我们很容易就能发现DDP over TCP面临的问题:DDP是以Segment为单位的,每个Segment都承载了一些Payload,但是它的Header中没有定义Payload长度。而TCP流是没有边界的,即使在流上只有一个DDP Segment的时候,接收端也无法知道Header后的Payload有多长,自然无法恢复数据。更何况大部分情况下,一个流上都会有多个DDP Segment,除了第一个Segment的Header之外,其他的Segment是无法定位出来的。下图是一条TCP流上首尾相连的多个DDP Segment(上帝视角):

但是从接收端ULP的视角看,从TCP层拿到的数据是下图这样的,没有边界,不知道该从哪里如何解析:

那么如何解决这个问题呢?有两种主流的思路:
- 在报文中插入固定值来方便定位分段,比如在每个DDP Segment之间插入一串约定好的bit,比如“0101 1010”,这样接收端每次检测到这个比特序列,都认为是DDP Segment的边界。但是DDP本身是可以携带Payload的,Payload由ULP传入,包含任何序列都是可能的,这种方法极有可能导致接收端的混淆。

- 在字节流的固定位置插入信息,方便接收端能够还原出原始的分段。原理如下图所示,两端都遵守协议的规定,那么收端就可以去约定好的位置去读取控制信息,然后识别出DDP Segment的边界。比如根据一个Control Field中的信息,推知下一个Control Field的位置。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9936
9936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









