







 Ceph的读/写操作采用Primary-Replica模型,确保数据强一致性。客户端仅向Primary OSD发起请求,Primary OSD负责将数据同步到其他副本。写入时,数据首先写入内存缓冲区,然后持久化到磁盘。读取时,客户端直接从Primary OSD获取数据。整个过程涉及寻址、权限检查、caps管理和数据验证等步骤,保证了可靠性和性能。
Ceph的读/写操作采用Primary-Replica模型,确保数据强一致性。客户端仅向Primary OSD发起请求,Primary OSD负责将数据同步到其他副本。写入时,数据首先写入内存缓冲区,然后持久化到磁盘。读取时,客户端直接从Primary OSD获取数据。整个过程涉及寻址、权限检查、caps管理和数据验证等步骤,保证了可靠性和性能。
相同过程
Ceph的读/写操作采用Primary-Replica模型,客户端只向Object所对应OSD set的Primary OSD发起读/写请求,这保证了数据的强一致性。当Primary OSD收到Object的写请求时,它负责把数据发送给其他副本,只有这个数据被保存在所有的OSD上时,Primary OSD才应答Object的写请求,这保证了副本的一致性。
写入数据
这里以Object写入为例,假定一个PG被映射到3个OSD上。Object写入流程如图所示。
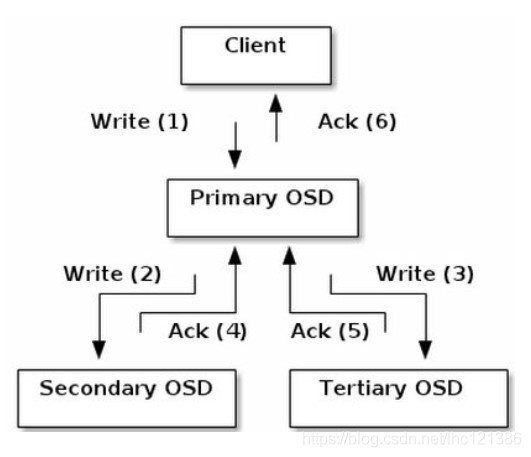
当某个客户端需要向Ceph集群写入一个File时,首先需要在本地完成前面所述的寻址流程,将File变为一个Object,然后找出存储该Object的一组共3个OSD,这3个OSD具有各自不同的序号,序号最靠前的那个OSD就是这一组中的Primary OSD,而后两个则依次Secondary OSD和Tertiary OSD。
找出3个OSD后,客户端将直接和Primary OSD进行通信,发起写入操作(步骤1)。 Primary OSD收到请求后,分别向Secondary OSD和Tertiary OSD发起写人操作(步骤2和步骤3)。当Secondary OSD和Tertiary OSD各自完成写入操作后,将分别向Primary OSD发送确认信息(步骤4和步骤5)。当Primary OSD确认其他两个OSD的写入完成后,则自己也完成数据写入,并向客户端确认Object写入操作完成(步骤6)。
之所以采用这样的写入流程,本质上是为了保证写入过程中的可靠性,尽可能避免出现数据丢失的情况。同时,由于客户端只需要向Primary OSD发送数据,因此在互联网使用场景下的外网带宽和整体访问延迟又得到了一定程度的优化。
当然,这种可靠性机制必然导致较长的延迟,特别是,如果等到所有的OSD都将数据写入磁盘后再向客户端发送确认信号,则整体延迟可能难以忍受。因此, Ceph可以分两次向客户端进行确认。当各个OSD都将数据写入内存缓冲区后,就先向客户端发送一次确认,此时客户端即可以向下执行。待各个OSD都将数据写入磁盘后,会向客户端发送一个最终确认信号,此时客户端可以根据需要删除本地数据。
分析上述流程可以看出,在正常情况下,客户端可以独立完成OSD寻址操作,而不必依赖于其他系统模块。因此,大量的客户端可以同时和大量的OSD进行并行操作。同时,如果一个File被切分成多个Object,这多个Object也可被并行发送至多个OSD上。
从OSD的角度来看,由于同一个OSD在不同的PG中的角色不同,因此,其工作压力也可以被尽可能均匀地分担,从而避免单个OSD变成性能瓶颈。
读取数据
如果需要读取数据,客户端只需完成同样的寻址过程,并直接和Primary OSD联系。在目前的Ceph设计中,被读取的数据默认由Primary OSD提供,但也可以设置允许从其他OSD中获取,以分散读取压力从而提高性能。
原文链接:https://blog.youkuaiyun.com/lhc121386/article/details/113488420
文件读写流程
libcephfs.cc 调用 Client.cc中的client 。client::_write
cephfs:用户态客户端write
摘自:https://zhuanlan.zhihu.com/p/109573019
还是通过cp命令来研究write。
cp 2M_test /mnt/ceph-fuse/test从fuse到cephfs客户端的函数流程如下
client::_write就是核心函数,可以简单分为两个重要部分:get_caps和file_write部分。代码如下。
int Client::_write(Fh *f, int64_t offset, uint64_t size, const char *buf, const struct iovec *iov, int iovcnt)
{ // offset = 0, size = 128K, buf是要写的内容,iov = NULL,iovcnt = 0
Inode *in = f->inode.get(); // in->size = 0
uint64_t endoff = offset + size; // endoff = 128K
utime_t start = ceph_clock_now();
// copy into fresh buffer (since our write may be resub, async)
bufferlist bl;
if (buf) { if (size > 0) bl.append(buf, size);
} else if (iov){ ... }
uint64_t totalwritten;
int have;
int r = get_caps(in, CEPH_CAP_FILE_WR|CEPH_CAP_AUTH_SHARED, CEPH_CAP_FILE_BUFFER, &have, endoff);
if (r < 0)
return r;
...
}get_caps
get_caps的入参need是"AsFw", want是"Fb"。need表示需要的cap,而want表示想要的cap,在get_caps中跟revoke有关。
need和want最关键的区别是:如果mds赋予客户端的caps中不包含need,那就无法往下写。Fw就是写的能力,而As,是因为需要获取本地缓存的Inode的mode值,需要判断(S_ISUID|S_ISGID);want在caps中可有可无,不耽误写,只与写的方式有关。
int Client::get_caps(Inode *in, int need, int want, int *phave, loff_t endoff)
{ // need = "AsFw", want = "Fb", phave是要赋值的int值,endoff = 128K
int r = check_pool_perm(in, need);
...
}首先判断是否有操作pool的权限。在Client类里面pool_perms成员是用来保存客户端对池的操作属性:即读或写。
std::map<std::pair<int64_t,std::string>, int> pool_perms;pool_perms里面的value就是属性集合,也就4种,根据字面意思,很好理解
enum {
POOL_CHECKED = 1,
POOL_CHECKING = 2,
POOL_READ = 4,
POOL_WRITE = 8,
};Client::check_pool_perm代码如下
int Client::check_pool_perm(Inode *in, int need)
{
int64_t pool_id = in->layout.pool_id; // pool_id = 2
std::string pool_ns = in->layout.pool_ns; // pool_ns = ""
std::pair<int64_t, std::string> perm_key(pool_id, pool_ns); //
int have = 0;
while (true) {
auto it = pool_perms.find(perm_key); // 看pool_perms中是否有该pool的key
if (it == pool_perms.end()) // 如果没有直接跳出
break;
if (it->second == POOL_CHECKING) { // 如果有,且正在checking中,等待check结束
// avoid concurrent checkings
wait_on_list(waiting_for_pool_perm);
} else { // 否则,就是已经check完了。
have = it->second; // 获取目前该池的权限
assert(have & POOL_CHECKED);
break;
}
}
if (!have) {
pool_perms[perm_key] = POOL_CHECKING; // 置上POOL_CHECKING标志
char oid_buf[32];
snprintf(oid_buf, sizeof(oid_buf), "%llx.00000000", (unsigned long long)in->ino); //对象名存入oid_buf
object_t oid = oid_buf;
SnapContext nullsnapc;
C_SaferCond rd_cond;
ObjectOperation rd_op;
rd_op.stat(NULL, (ceph::real_time*)nullptr, NULL);
objecter->mutate(oid, OSDMap::file_to_object_locator(in->layout), rd_op, // 发送CEPH_OSD_OP_STAT请求给osd
nullsnapc, ceph::real_clock::now(), 0, &rd_cond);
C_SaferCond wr_cond;
ObjectOperation wr_op;
wr_op.create(true);
objecter->mutate(oid, OSDMap::file_to_object_locator(in->layout), wr_op, // 发送CEPH_OSD_OP_CREATE请求给osd
nullsnapc, ceph::real_clock::now(), 0, &wr_cond);
client_lock.Unlock();
int rd_ret = rd_cond.wait(); // 等待stat回复
int wr_ret = wr_cond.wait(); // 等待create回复
client_lock.Lock();
bool errored = false;
if (rd_ret == 0 || rd_ret == -ENOENT)
have |= POOL_READ; // 如果返回0或-ENOENT,则表示有READ权限
else if (rd_ret != -EPERM) {
errored = true; // stat出现错误
}
if (wr_ret == 0 || wr_ret == -EEXIST)
have |= POOL_WRITE; // 如果返回0或-EEXIST,则表示有write权限
else if (wr_ret != -EPERM) {
errored = true; // create出现错误
}
if (errored) {
pool_perms.erase(perm_key);
signal_cond_list(waiting_for_pool_perm); // 唤醒waiting_for_pool_perm
return -EIO;
}
pool_perms[perm_key] = have | POOL_CHECKED; // 置上POOL_CHECKED标志
signal_cond_list(waiting_for_pool_perm); // 唤醒waiting_for_pool_perm
}
if ((need & CEPH_CAP_FILE_RD) && !(have & POOL_READ)) { // 如果没有POOL_READ,则返回-EPERM
return -EPERM;
}
if ((need & CEPH_CAP_FILE_WR) && !(have & POOL_WRITE)) { // 如果没有POOL_WRITE,则返回-EPERM
return -EPERM;
}
return 0;
}检查完对pool的权限后,首先要判断客户端在Inode上拥有的caps是否有"Fw",如果有"Fw",那就得校验要写的范围,如果超过了in->max_size,即endoff > in->max_size,就说明此刻已经超过了mds分给客户端能写的范围,所以需要等待mds分配新的范围即in->max_size,并且要check_caps。
如果have中也没有"As",也需要等待caps,当然还有其他的情况。如果考虑太多,反而不太理解。简而言之,在get_caps中就两件事:
1,如果已有的caps没有"AsFw",则等待caps
2,如果已有的caps有"AsFw",则校验endoff。如果endoff > in->max_size,就去check_caps,并等待;如果endoff < in->max_size,只需要记录"AsFw"的引用。
int Client::get_caps(Inode *in, int need, int want, int *phave, loff_t endoff)
{
int r = check_pool_perm(in, need);
while (1) {
int file_wanted = in->caps_file_wanted(); // 此时open_by_mode中有{CEPH_FILE_MODE_WR=1},所以file_wanted = "pAsxXsxFxwb"
if ((file_wanted & need) != need) { ... } // "pAsxXsxFxwb" & "AsFw" == "AsFw"
int implemented;
int have = in->caps_issued(&implemented); // have = implemented = "pAsxLsXsxFsxwrcb"
bool waitfor_caps = false;
bool waitfor_commit = false;
if (have & need & CEPH_CAP_FILE_WR) { // "pAsxLsXsxFsxwrcb" & "AsFw" & "Fw" = "Fw"
if (endoff > 0 && (endoff >= (loff_t)in->max_size || endoff > (loff_t)(in->size << 1))
&& endoff > (loff_t)in->wanted_max_size) {
in->wanted_max_size = endoff;
check_caps(in, 0);
}
// 如果en 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2690
2690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









