






大家在stable diffusion webUI中可能看到过hypernetwork这个词,那么hypernetwork到底是做什么用的呢?
简单点说,hypernetwork模型是用于修改样式的小型神经网络。
什么是 Stable Diffusion 中的hypernetwork?
Hypernetwork 是由 Novel AI 开发的一种微调技术,Novel AI 是 Stable Diffusion 的早期使用者。它是一个小型神经网络,附加到 Stable Diffusion 模型以修改其样式。
前面我们有提到SD模型中最关键的部分就是噪声预测器UNet,而Unet里面的关键部分就是交叉注意力模块。Hypernetwork就是修改了这部分内容。
同样的LoRA 模型也类似地修改了 Stable Diffusion 模型的这一部分,但方式不同。
如果有人还不知道Unet是什么的话,这里给一张官方的图片:
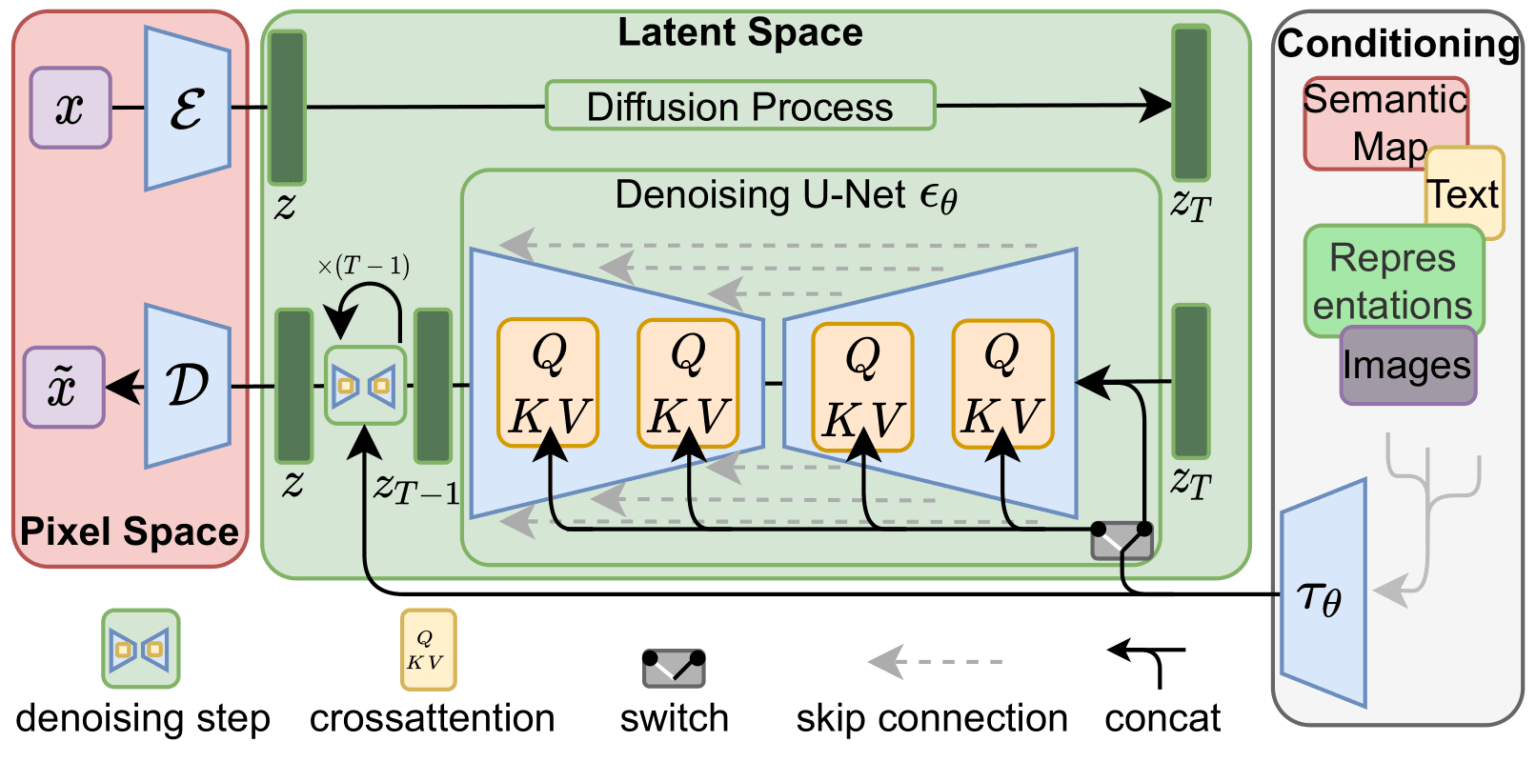
hypernetwork一般是一个结构简单的神经网络:一个包含dropout和激活函数的全连接线性网络,类似于你在神经网络基础课程中所学到的网络类型。它们通过插入两个子网络来转换key和query向量,进而接管了交叉注意力模块。以下是原始模型与接管后的模型架构的对比。
原始的交叉注意力模块直接利用输入的key和query向量来计算注意力权重。
但在hypernetwork介入后,这些向量会先经过hypernetwork中的两个子网络进行变换,然后再用于注意力机制的计算。这种变换使得模型能够以一种更加动态的方式调整其注意力机制,可能会增强模型对输入数据的敏感度和适应能力。
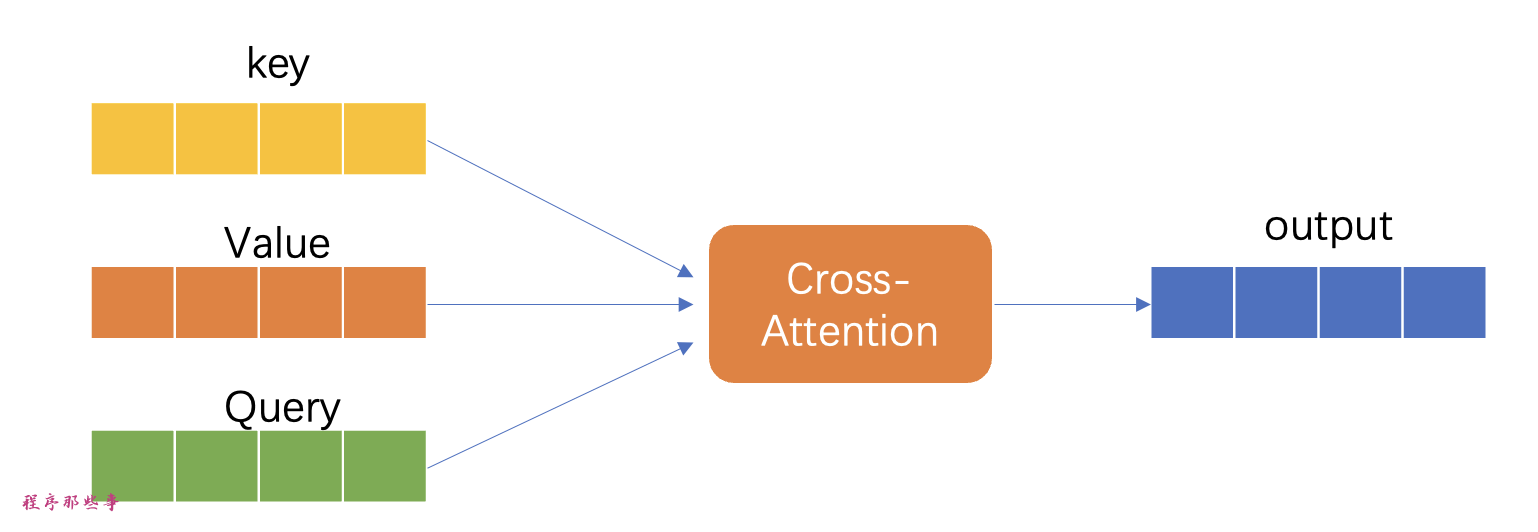
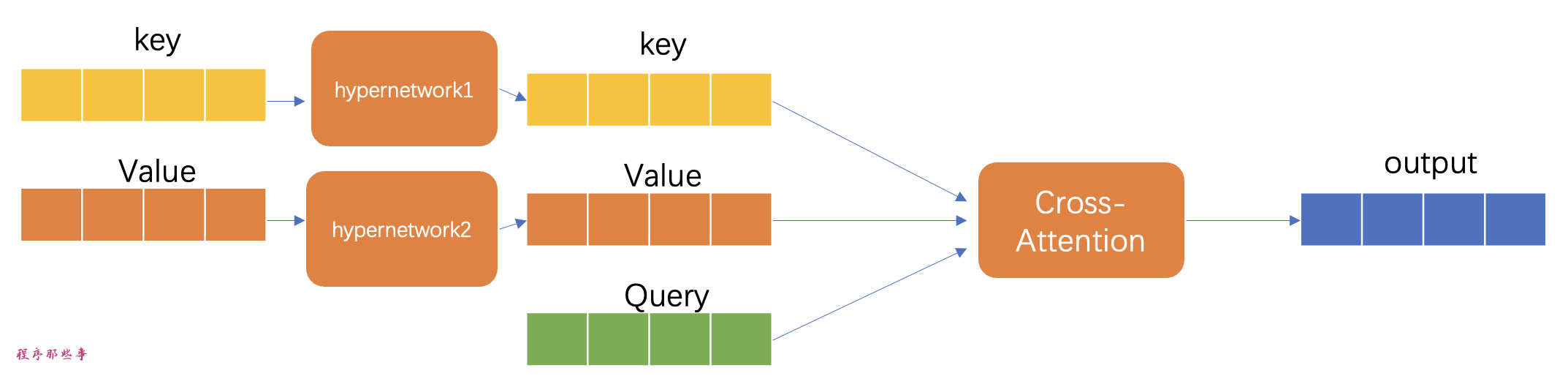
在训练过程中,Stable Diffusion 模型本身保持固定,但允许附加的hypernetwork进行调整。由于hypernetwork的规模较小,它能够快速训练,且所需的计算资源不多,这使得训练过程甚至可以在一台普通的计算机上完成。
快速的训练能力和较小的模型文件大小是hypernetwork的主要优势。
需要注意的是,Stable Diffusion 中的hypernetwork与机器学习领域中通常所指的hypernetwork有所不同。在这里,hypernetwork的作用是为另一个神经网络生成权重。因此,Stable Diffusion 的hypernetwork并不是在 2016 年发明的,它是一种更新的、专门用于生成网络权重的技术。
与其他model的区别
除了hypernetwork, SD中还有几个其他的几个model:checkpoint model、LoRA 和embedding。这里讲一下他们的区别:
checkpoint model
checkpoint model包含生成图像所需的所有信息。这种模型的大小从 2 GB 到 7 GB不等。而hypernetwork的大小通常低于 200 MB。
hypernetwork不能单独运行。它需要使用checkpoint model来生成图像。
checkpoint model比hypernetwork更强大。它可以比hypernetwork更好地存储样式。训练checkpoint model时,会对整个模型进行微调。训练hypernetwork时,仅对hypernetwork进行微调。
LoRA
LoRA 模型与hypernetwork最相似。它们都很小,只修改了交叉注意力模块。区别在于他们如何修改它。
LoRA 模型通过改变其权重来修改交叉注意力。hypernetwork通过插入其他网络来实现。
通常来说 LoRA 模型会产生更好的结果。它们的文件大小相似,通常小于 200MB。
LoRA 是一种数据存储技术,它并不直接规定训练流程,无论是 dreambooth 训练还是其他形式的额外训练都是可行的。而超网络则确实规定了训练流程。
LoRA 利用低秩矩阵来高效地调整和存储网络权重的变化,这使得模型可以更加高效地进行特定任务的微调,而不需要对整个模型架构进行大规模的改动。
与此相对,超网络通过生成另一个网络的权重来定义训练过程,为训练中的网络提供动态的权重,从而允许在训练过程中进行更灵活的学习和调整。
embedding
嵌入向量是“文本反转”微调技术的结果。与超网络一样,文本反转不会更改模型的架构,而是通过定义新的关键词来捕捉某些特定的风格或属性。
文本反转和超网络在稳定扩散模型中各司其职。文本反转在文本编码器层面上生成新的嵌入,而超网络则通过在噪声预测器的交叉注意力模块中插入一个小网络来实现其功能。
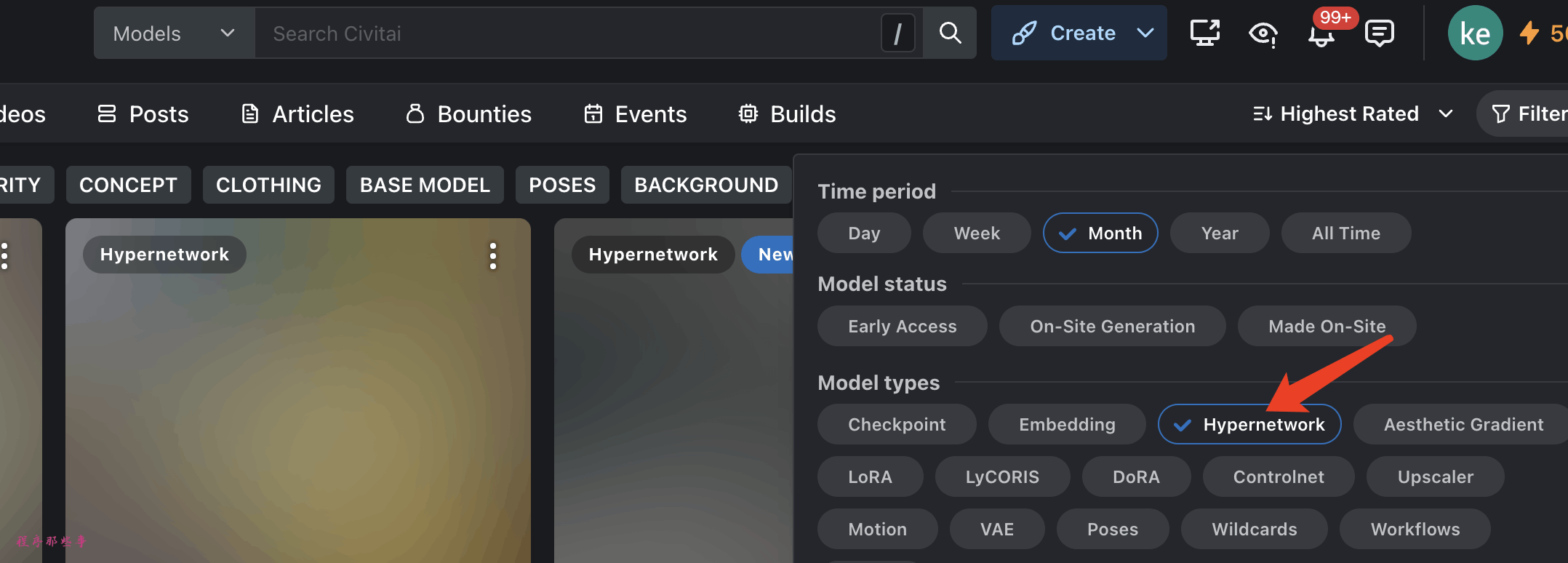
在哪下载hypernetwork
当然下载模型的最好的地方是 civitai.com。使用 hypernetwork 筛选模型类型。
如何使用hypernetwork
步骤 1:安装hypernetwork模型
要在 Webui AUTOMATIC1111安装hypernetwork模型,请将模型文件放在以下文件夹中。
'stablediffusion-webui/models/hypernetworks'
步骤 2:使用hypernetwork模型
若要使用hypernetwork,请在提示符中输入以下描述。
<hypernet:filename:multiplier>
其中filename是hypernetwork的文件名,不包括扩展名 (.pt .bin等)。
multiplier是应用于hypernetwork模型的权重。默认值为 1。将其设置为 0 将禁用模型。
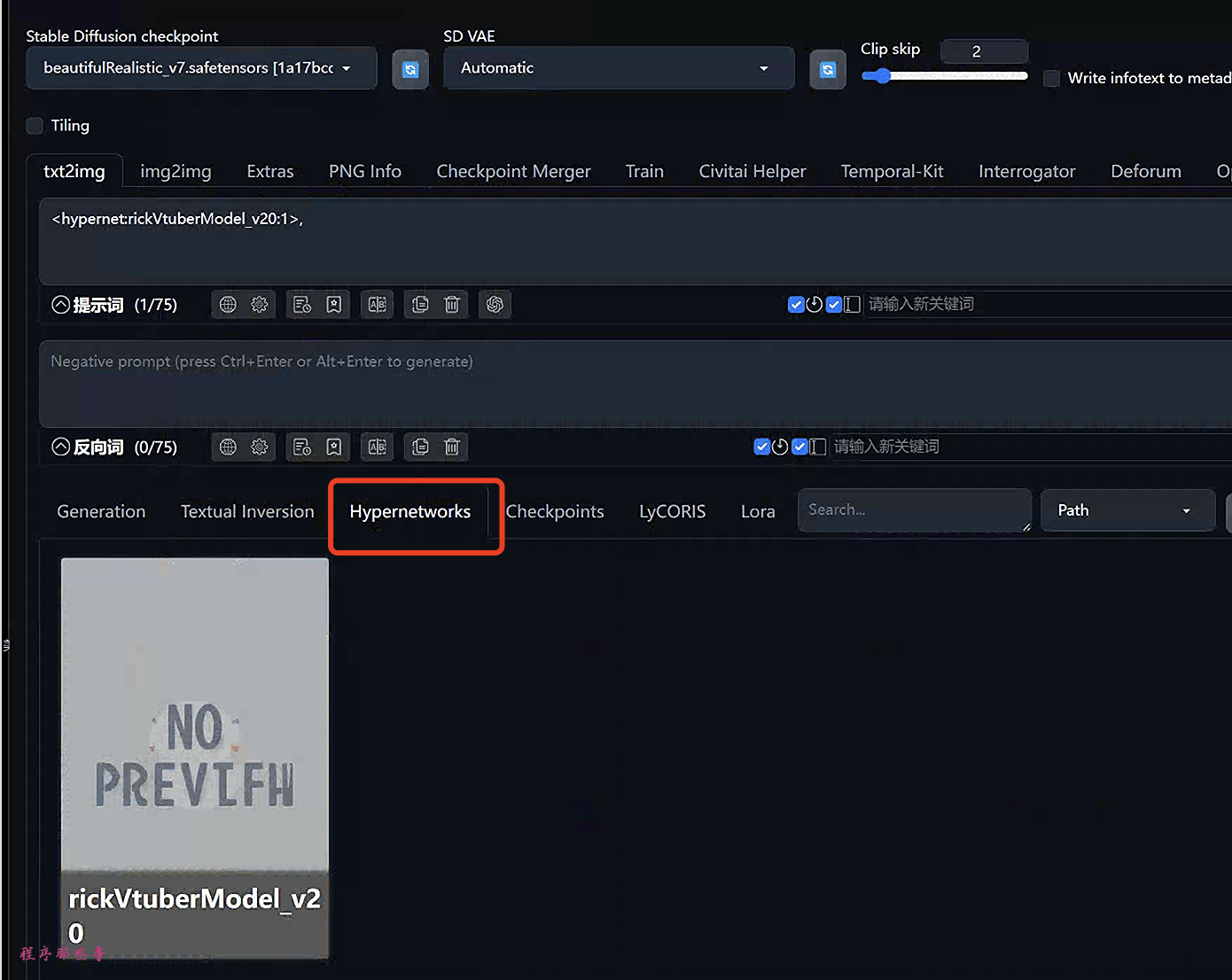
如何不知道文件名怎么办呢?在webUI中有一个更简单的办法:单击“hypernetwork”选项卡。你应该会看到已安装的hypernetwork列表。单击要使用的那个。
对应的描述将插入到提示中。

















 671
671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









