







一、代码1
#include <stdio.h>
#include <stdlib.h> //malloc头文件
void cpu(int *a, int N)
{
for (int i = 0; i < N; i++)
{
a[i] = i;
}
}
__global__ void gpu(int *a, int N)
{
int threadi = blockIdx.x * blockDim.x + threadIdx.x; //计算出当前是第几个线程
int stride = gridDim.x * blockDim.x; //当前所有线程块*每个线程块有多少线程=所有线程数
for (int i = threadi; i < N; i += stride)
{
a[i] *= 2;
}
}
bool check(int *a, int N) //测试GPU函数中数据是否正确执行
{
for (int i = 0; i < N; i++)
{
if (a[i] != 2 * i) return false;
}
return true;
}
int main()
{
const int N = 500;
size_t size = N * sizeof(int); //需分配的size大小
int *a;
cudaError_t err;
err = cudaMallocManaged(&a, size); //分配malloc,既可以CPU使用,也可以GPU使用
if (err != cudaSuccess)
{
printf("Error:%s\n", cudaGetErrorString(err));
}
cpu(a, N); //数组地址和大小
size_t threads = 256; //一个block256个线程
size_t blocks = 1;
gpu<<<blocks, threads>>>(a, N);
err = cudaGetLastError();
if (err != cudaSuccess)
{
printf("Error:%s\n", cudaGetErrorString(err));
}
cudaDeviceSynchronize();
check(a, N) ? printf("OK!") : printf("error!");
cudaFree(a);
}

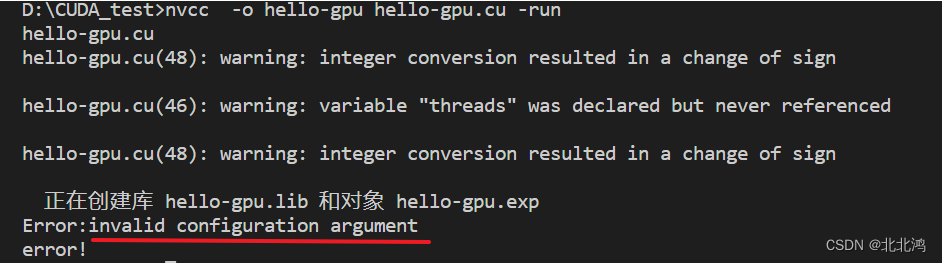
二、代码2
改进代码
#include <stdio.h>
#include <stdlib.h> //malloc头文件
#include <assert.h>
void cpu(int *a, int N)
{
for (int i = 0; i < N; i++)
{
a[i] = i;
}
}
__global__ void gpu(int *a, int N)
{
int threadi = blockIdx.x * blockDim.x + threadIdx.x; //计算出当前是第几个线程
int stride = gridDim.x * blockDim.x; //当前所有线程块*每个线程块有多少线程=所有线程数
for (int i = threadi; i < N; i += stride)
{
a[i] *= 2;
}
}
bool check(int *a, int N) //测试GPU函数中数据是否正确执行
{
for (int i = 0; i < N; i++)
{
if (a[i] != 2 * i) return false;
}
return true;
}
inline cudaError_t checkCuda(cudaError_t result)
{
if (result != cudaSuccess)
{
fprintf(stderr, "CUDA runtime error: %s\n", cudaGetErrorString(result));
assert(result == cudaSuccess);
}
return result;
}
int main()
{
const int N = 500;
size_t size = N * sizeof(int); //需分配的size大小
int *a;
cudaError_t err;
err = cudaMallocManaged(&a, size); //分配malloc,既可以CPU使用,也可以GPU使用
if (err != cudaSuccess)
{
printf("Error:%s\n", cudaGetErrorString(err));
}
cpu(a, N); //数组地址和大小
size_t threads = 256; //一个block256个线程
size_t blocks = 1;
gpu<<<blocks, threads>>>(a, N);
err = cudaGetLastError();
if (err != cudaSuccess)
{
printf("Error:%s\n", cudaGetErrorString(err));
}
checkCuda(cudaDeviceSynchronize());
check(a, N) ? printf("OK!") : printf("error!");
cudaFree(a);
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









