







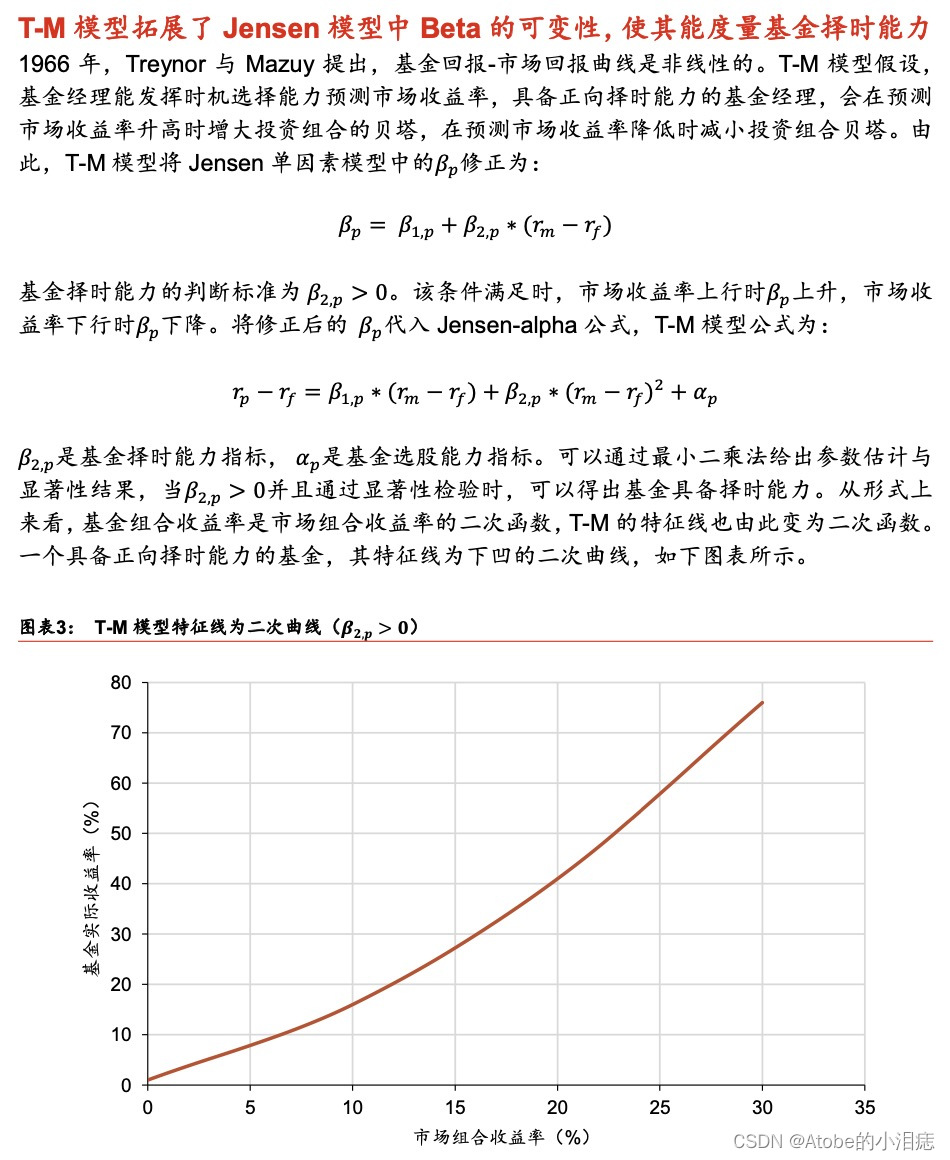
 该博客介绍了如何在R语言中使用`lm`和`nls`函数进行线性与非线性回归分析。通过最小二乘法,对数据进行参数估计,并绘制实际数据与拟合曲线的图表。文章还展示了如何筛选数据并使用`ggplot2`包进行数据可视化,描绘了基金实际收益率与市场组合收益率之间的关系。
该博客介绍了如何在R语言中使用`lm`和`nls`函数进行线性与非线性回归分析。通过最小二乘法,对数据进行参数估计,并绘制实际数据与拟合曲线的图表。文章还展示了如何筛选数据并使用`ggplot2`包进行数据可视化,描绘了基金实际收益率与市场组合收益率之间的关系。
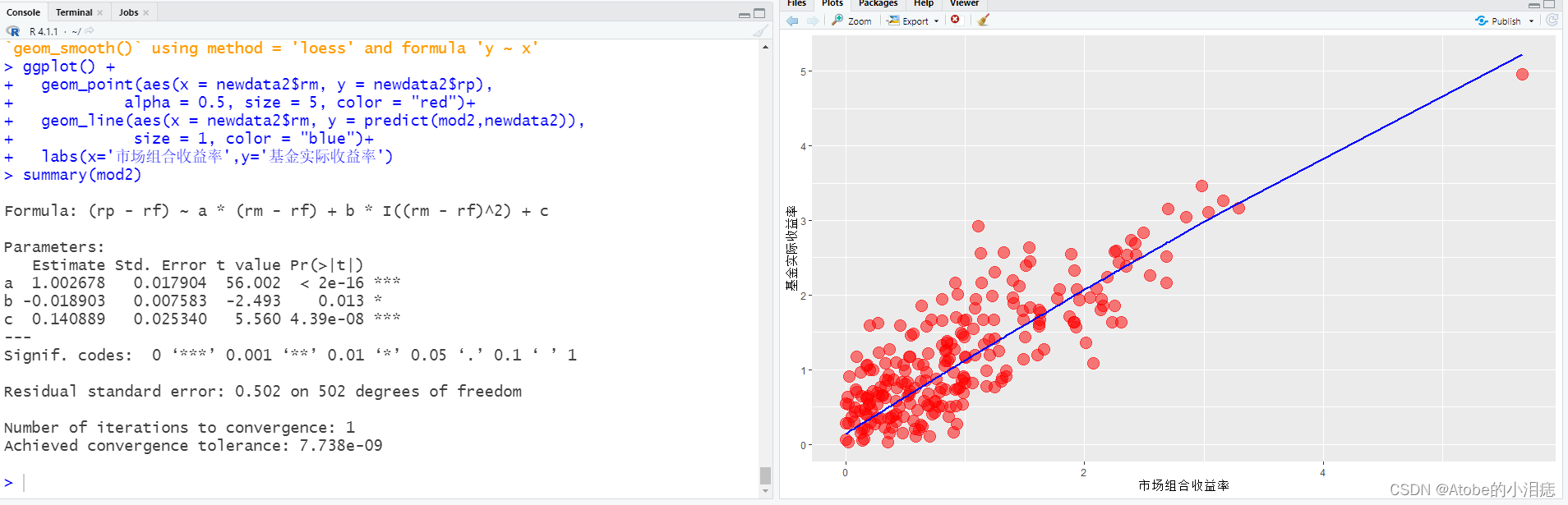
根据最小二乘法进行参数估计,然后把实际数据和估计参数后的曲线方程画个图
R语言中,lm是线性回归建模,如果指定方程是非线性的话就将曲线直线化再做回归。
nls是直接拟合曲线,表示非线性回归建模函数,参数是显示的,也就是建模时要把系数标注出来并给出范围。
#最小二乘回归
mod1<-lm((rp-rf)~(rm-rf)+I((rm-rf)^2),data=TMdata)
mod2<-nls((rp-rf)~a*(rm-rf)+b*I((rm-rf)^2)+c,data=TMdata,start=c(a=0,b=0,c=0))
summary(mod1)
summary(mod2)
#保留rprm大于0的数据
newdata<-subset(TMdata,TMdata$rp>0)
newdata2<-subset(newdata,newdata$rm>0)
ggplot() +
geom_point(aes(x = newdata2$rm, y = newdata2$rp),
alpha = 0.5, size = 5, color = "red")+
geom_line(aes(x = newdata2$rm, y = predict(mod2,newdata2)),
size = 1, color = "blue")+
labs(x='市场组合收益率',y='基金实际收益率')

















 1723
1723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









