 OpenAI推崇的RL训练方法及优化策略
OpenAI推崇的RL训练方法及优化策略




一、RL的本质
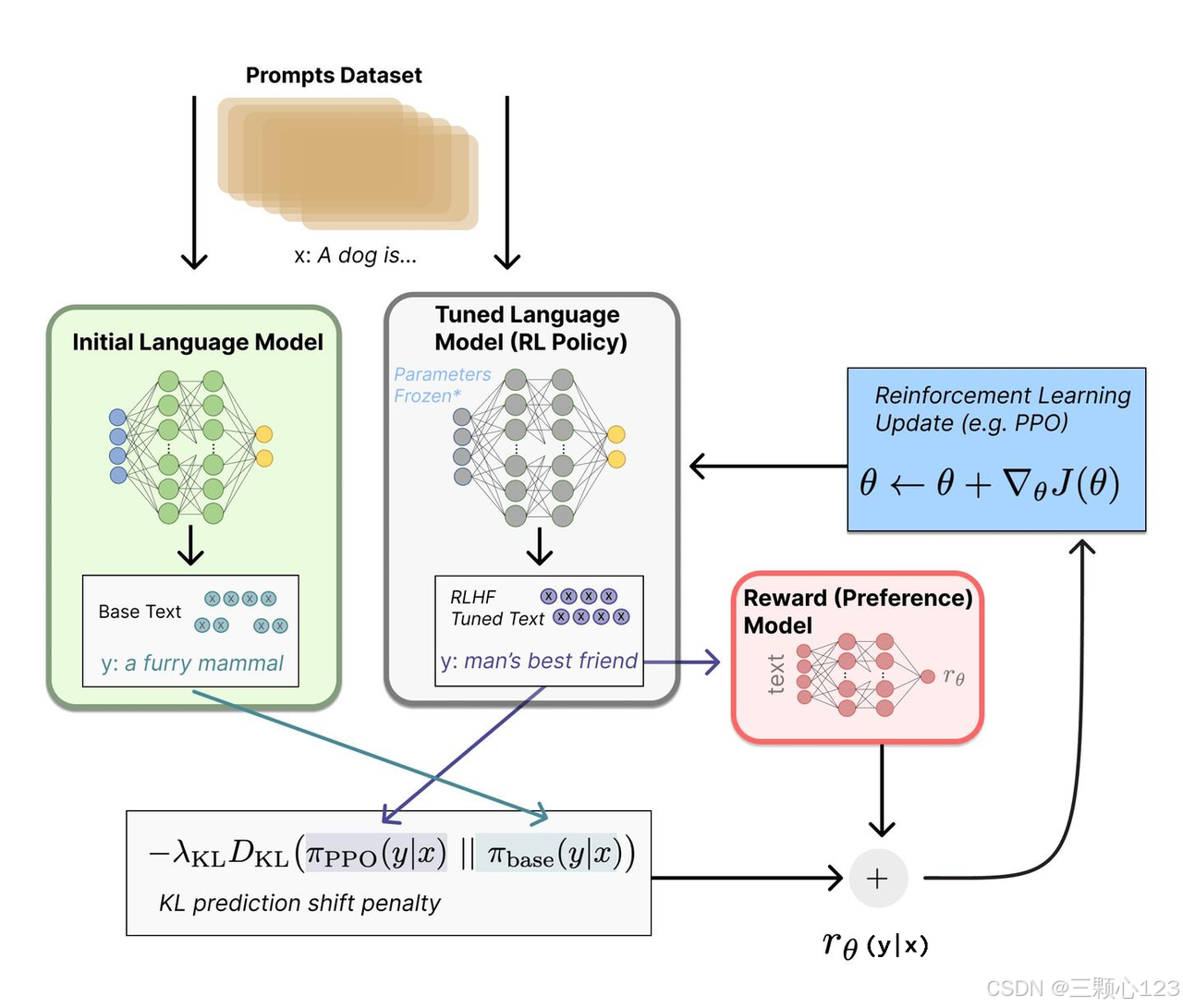
RL的目标是在不严重偏离初始模型太远的情况下调整模型行为。
策略(Policy,π):智能体根据策略来选择动作,策略的本质是代理根据当前状态决定采取何种行动,以便最大化长期的累积奖励。新老策略的比值(行动重要性):
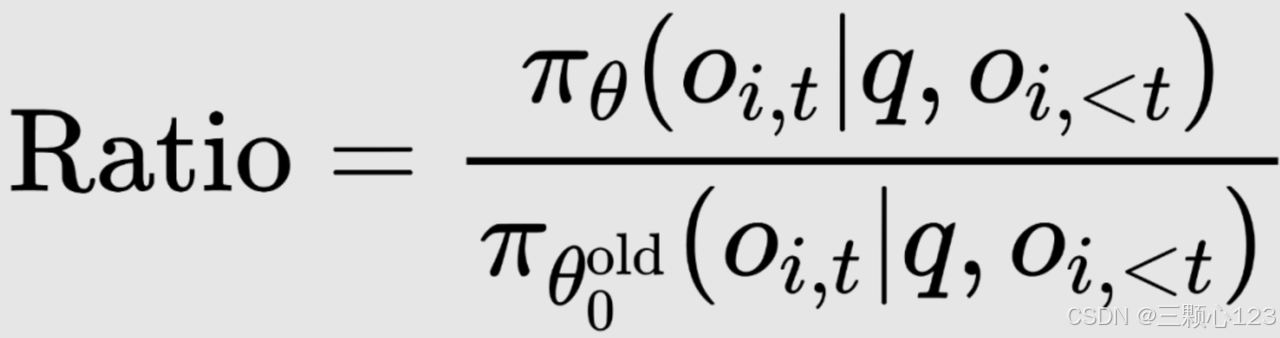
SFT与RL的区别:SFT的loss是在给定context下让模型输出靠近给定的词下一个词(标准答案),属于记忆型,而RL的loss则是模型在sample出来这个词之后输出能获得多少奖励,属于推断型,后者模拟了生物进化中的趋利避害行为,但计算机对于真实世界环境的刺激没有深切的五感体验,仅限于“表皮”的模拟。

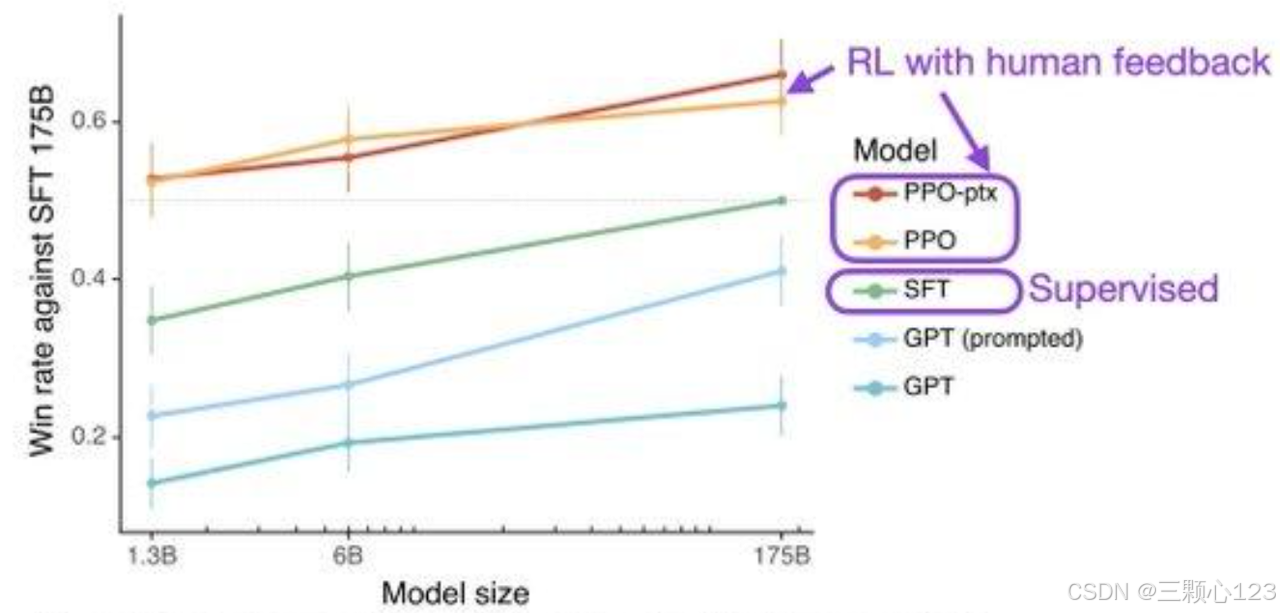
研究表明,预训练好大模型且SFT后,继续使用RLHF训练,比SFT训练效果好很多。 RL的典型代表PPO(Proximal Policy Optimization)是一种策略优化算法,它的核心思想是对策略更新进行限制,使训练更加稳定,同时保持效率。
 RL如何调整策略以最大化奖励呢?换言之,如何设计一个可学习的优化目标,使奖励最大化呢?
RL如何调整策略以最大化奖励呢?换言之,如何设计一个可学习的优化目标,使奖励最大化呢?
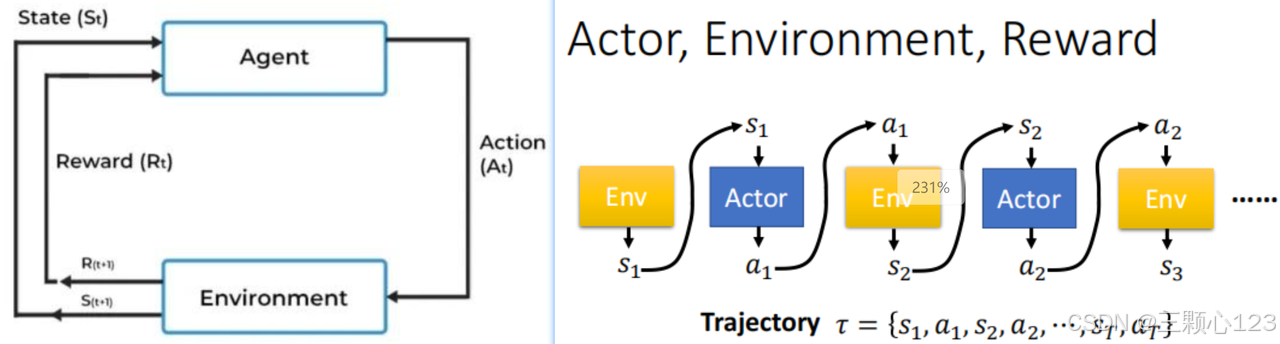
我们首先与环境进行一系列交互,从初始状态s1开始到结束状态s_final,模型依次做出了动作a1~an并分别获得了奖励r1~rn,在每步做决策时,模型都会给出概率分布π(at|st),这一从开始到结束的交互过程我们称之为一条轨迹,将这条轨迹的所有奖励求和即可得到轨迹的总奖励R(π)。下文为几种高效的策略调整方法:
 二、PPO
二、PPO
Actor-Critic模式,PPO使用重要性采样来调整旧数据,使其适用于新策略,在PPO中,计算旧策略θold和新策略θ下的行动的重要性权重,然后使用这些权重来调整旧数据,使其反映新策略的期望。这样,就可以在不牺牲样本效率的情况下,利用旧数据来更新策略。
PPO 引入裁剪式替代目标(clipped surrogate objective)来执行策略优化,通过使用裁剪将策略更新限制在先前策略的近端区域内,PPO 可以让训练稳定并提高样本效率。
 其中:
其中:
1、新策略θ与旧策略θold的比值代表重要度,θ和θold不能差太远,因为差太远会引入问题,这并不是说参数的值不能差太多,而是说,输入同样的state,网络得到的动作的概率分布不能差太远。这是因为OpenAI提出PPO时Comparison Data不是一个很大的数据集,不会包含全部的回答,对于任何给定的提示,都有许多可能的回答,其中绝大多数是奖励模型RM以前从未见过的,对于许多未知(提示、响应)对,RM可能会错误地给出极高或极低的分数,如果没有这个约束,模型可能会偏向那些得分极高的回答,它们可能不是好的回答;
2、clip部分是对策略的重要度采样进行限制,它在目标函数中进行限制,以保证新的参数和旧的参数的差距不会太大,当新旧策略的比率ratio超出[1-ε,1+ε]范围时,剪裁函数会限制其影响,防止策略更新过大,超参ε通常设置为 0.1 或 0.2;
3、At为优势函数(奖励),表示在给定状态下采取某个动作的期望奖励。PPO算法需要维护一个与策略模型大小相当的价值网络来估计优势函数,这在大模型场景下会导致显著的内存占用和计算代价。例如,在数十亿甚至千亿参数的语言模型上应用PPO时,价值网络的训练和更新会消耗大量的计算资源,使得训练过程变得低效且难以扩展;
 4、最后对这两项再取min,防止了θ更新太快。
4、最后对这两项再取min,防止了θ更新太快。
PPO 的直观类比:
假设你是一个篮球教练,训练球员投篮:
如果每次训练完全改变投篮动作,球员可能会表现失常(类似于策略更新过度)。
如果每次训练动作变化太小,可能很难进步(类似于更新不足)。
PPO 的剪裁机制就像一个“适度改进”的规则,告诉球员在合理范围内调整投篮动作,同时评估每次投篮的表现是否优于平均水平。
PPO-Clip之前的PPO-Penalty也使用过KL惩罚来动态改变θ与θold分布的差异,以保证新的参数和旧的参数的差距不会太大,但Clip的方式更加直接,就替代了KL。
 三、GRPO
三、GRPO
GRPO 消除了价值函数以减少计算量和显存占用,它以群组相关的方式来估计优势。对于特定的问答对 (q, a),行为策略 π_θ_old 采样一组 G 个个体响应,然后通过对群组级奖励进行归一化来计算第 i 个响应的优势,通过组内相对奖励的计算,GRPO减少了策略更新的计算量与方差,确保了更稳定的学习过程:
 与 PPO 类似,GRPO 也采用了裁剪目标,同时还添加了一个 KL 惩罚项,作者认为KL散度约束能够更精细柔性地控制策略更新的幅度,防止策略更新过于剧烈,保持策略分布的稳定性:
与 PPO 类似,GRPO 也采用了裁剪目标,同时还添加了一个 KL 惩罚项,作者认为KL散度约束能够更精细柔性地控制策略更新的幅度,防止策略更新过于剧烈,保持策略分布的稳定性:
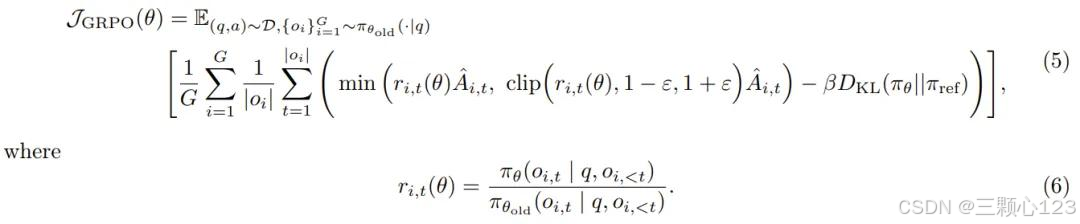 GRPO 是在样本层级计算目标,GRPO 首先会计算每个生成序列中的平均损失,然后再对不同样本的损失进行平均。
GRPO 是在样本层级计算目标,GRPO 首先会计算每个生成序列中的平均损失,然后再对不同样本的损失进行平均。
四、DAPO
DAPO 仍然是对每个问题q和答案a的一组G输出进行采样,并通过以下目标优化策略:
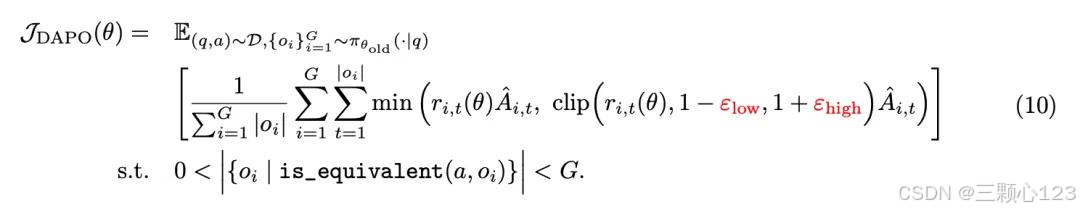
![]()
但人们在使用 PPO 或 GRPO 的实验中,研究者经常遇到熵崩溃现象,很少有研究者能复现出开源效果。随着训练的进行,策略的熵迅速下降,即某些组的采样响应通常几乎相同,这表明有限的探索和早期的确定性策略会阻碍扩展过程,另外,现在的数据集很多都比Comparison Data大,需要减弱新老策略更新相似度的限制才能训练出更高精度的模型,以后的研究可能会完全去掉限制以保障精度,于是提出以下几点优化:
1、去除KL散度 :KL 惩罚项的作用是调节在线策略和冻结参考策略之间的偏离情况,在 RLHF 场景中,RL 的目标是在不偏离初始模型太远的情况下调整模型行为,然而,在训练长 CoT 推理模型时,模型分布可能会与初始模型有显著差异,因此这种限制是不必要的,因此,在DAPO中,去除了KL项;
2、解耦Clip的上下限:研究者增加了ε_high的值,以便为低概率token的增加留出更多空间,这一调整有效地提高了策略的熵,有利于生成更多样化的样本。同时,研究者选择将ε_low保持在相对较小的范围内,因为增大ε_low会将这些token的概率压制为 0,导致采样空间的崩溃,从而增加系统的多样性;
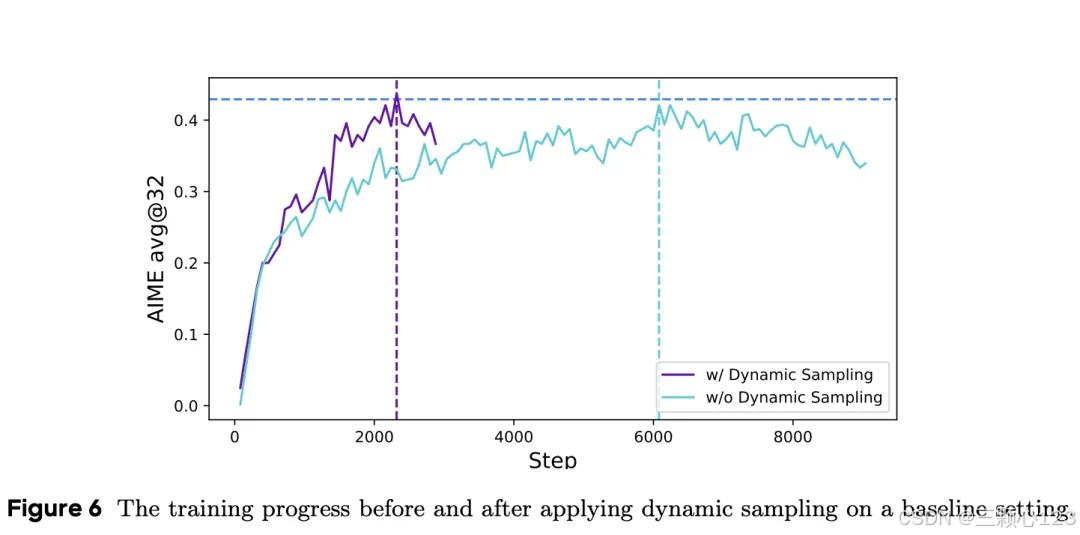
3、动态采样:当某些提示的准确度等于 1 时,现有的 RL 算法就会出现梯度递减问题,根据经验,准确率等于 1 的样本数量会继续增加,这意味着每批样本中的有效提示次数会不断减少,从而导致梯度方差增大,抑制了模型训练的梯度信号。研究者建议进行过度采样,过滤掉精度等于 1 和 0 的提示语,保留批次中所有具有有效梯度的提示语,并保持一致的提示语数量,在训练之前不断采样,直到批次中全部都是准确率既不等于 0 也不等于 1 的样本,动态采样是DAPO最大的改进,只需要一半的训练step就可达到ORPO的精度;
4、Token 级策略梯度损失:GRPO中所有样本在损失计算中的权重相同,长回复中的 token 对总体损失的贡献可能会不成比例地降低,这可能会导致两种不利影响:a、对于高质量的长样本来说,这种影响会阻碍模型学习其中与推理相关的模式的能力;b、过长的样本往往表现出低质量的模式,如胡言乱语和重复词语。样本级损失计算由于样本权重相同无法有效惩罚长样本中的不良模式,会导致熵和响应长度的不健康增长。研究者提出一种长度感知惩罚机制Soft Overlong Punishment,旨在塑造截断样本的奖励,即当响应长度超过预定义的最大值时,研究者会定义一个惩罚区间,在这个区间内,响应越长,受到的惩罚就越大。这种惩罚会添加到基于规则的原始正确性奖励中,从而向模型发出信号,避免过长的响应;
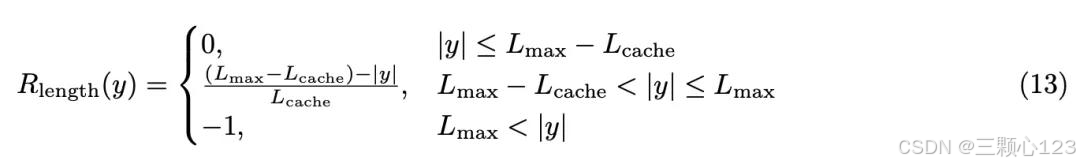
在 RL 训练过程中,研究者观察到一个有趣的现象:Actor 模型的推理模式会随着时间的推移而动态演化,算法不仅强化了有助于正确解决问题的现有推理模式,还逐渐产生了最初不存在的全新推理模式,在模型训练的早期阶段,几乎不存在对之前推理步骤的检查和反思,然而,随着训练的进行,模型表现出明显的反思和回溯行为,这一发现揭示了RL算法的适应性和探索能力,并为模型的学习机制提供了新的见解。
小结:以后32B左右的模型是大语言模型的主流,目前强化学习的有效演化主线是对PPO这种RLHF算法进行优化。

















 6148
6148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









