







爬虫程序做的是:模拟浏览器发送请求–>获取网页代码–>筛选提取数据–>存放数据。

前期准备
爬虫程序中需要用到一些第三方库,我们这里使用的是requests库和BeautifulSoup4库。话不多说,让我们先来做好这些准备
- 打开cmd
- 输入
pip install requests - 输入
pip install BeautifulSoup4
发送请求
模拟浏览器发送请求时,我们可以使用requests库帮助我们。下面给出requests库的7个主要方法:
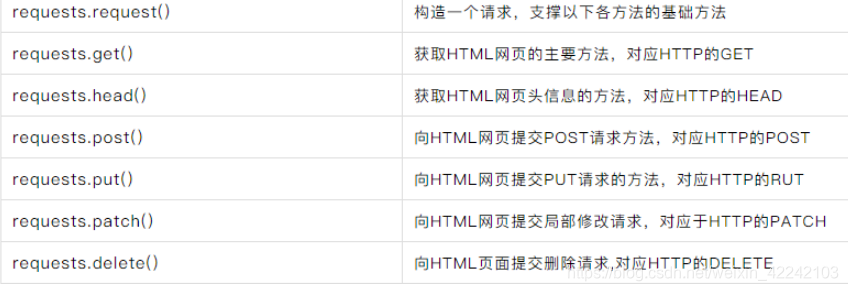
发送请求后,服务器会接受请求,并返回一个response。
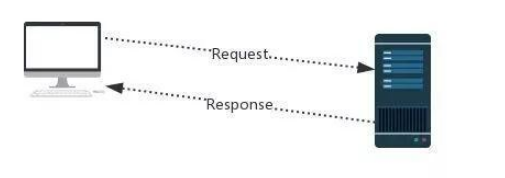

接下来,我们以访问百度主页的代码为例来看看吧!
# -*- coding: utf-8 -*-
import requests
url = "https://www.baidu.com/" #必须输入完整的网址
res = requests.get(url)
print(res.status_code)
#200
其中,我们介绍一下requests.get()函数的带参数形式。params是字典或字节序列,可以添加到url中;****headers是HTTP的定制头等等。我们以headers为例,headers是HTTP的定制头,一些服务器在处理requests请求时会识别请求头,并拦截python爬虫。
# -*- coding: utf-8 -*-
import requests
url="http://www.zhihu.com/"
res=requests.get(url)
print(res.status_code)
#403
print(res.request.headers)
#{'User-Agent': 'python-requests/2.22.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
可以看到我们通过python访问知乎首页被拦截了,查看请求头时发现User-agent是python—-requests/2.22.0。下面我们尝试修改请求头伪装成浏览器:
# -*- coding: utf-8 -*-
import requests
pre={'User-agent':'Mozilla/5.0'} #浏览器头
res=requests.get("https://www.zhihu.com/",headers=pre) #获取
print(res.status_code)
#200
查看浏览器User-agent的方法是,谷歌浏览器输入chrome://version/
用户代理就是user-agent
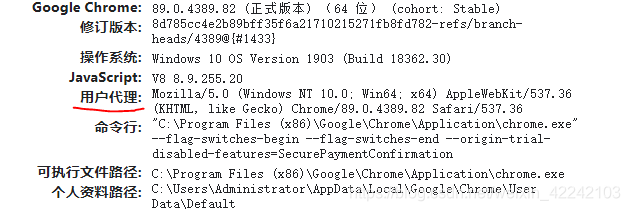
可见,修改请求头后访问成功。利用requests的get方法和response的content属性(图片以二进制形式保存),我们可以下载网络上的一些图片,下面以获取新浪新闻的一张图片为例:
# -*- coding: utf-8 -*-
import sys
import requests
url="http://www.sinaimg.cn/dy/slidenews/5_img/2015_48/30939_1300019_688168.jpg"
path='test.jpg' #文件默认在当前目录
try:
res=requests.get(url) #发送请求
with open(path,'wb') as pic: #with open比直接open更安全
pic.write(res.content)
pic.close()
print("文件保存成功")
except:
print("爬取失败")
解析内容
Beautiful Soup库是解析、遍历、维护文档树的功能库。
简单地说,BeautifulSoup能够帮助用户将response中的html内容解析,得到一个BeautifulSoup的对象,并且能够以标准的缩进格式输出。我们以知乎热榜网页为例(注意B和S要大写哦):
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
pre={'User-agent':'Mozilla/5.0'}
res=requests.get("https://www.zhihu.com/billboard",headers=pre)
rep=res.text
soup=BeautifulSoup(rep,"html.parser")#加html.parse代表识别为html语言
print(soup)
这里,我们来认识一下BeautifulSoup类的部分元素:

在代码运行返回的html内容中,可以看见a标签里包含了
等子孙标签,其中包含了我们需要的热榜话题,利用这段代码我们可以获取热榜第一的信息进而获取榜单全部话题。
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
pre={'User-agent':'Mozilla/5.0'}
try:
res=requests.get("https://www.zhihu.com/billboard",headers=pre)
print(res.raise_for_status)
rep=res.text
except:
print("连接失败")
try:
soup=BeautifulSoup(rep,"html.parser")#加html.parse代表识别为html语言
con=soup.find_all('div',class_="HotList-itemTitle")
for i in range(len(con)):
print(con[i].text)
except:
print("获取失败")
我们观察到所有热榜话题所在标签name都是div,属性中都包含class=“HotList- itemTitle”。我们使用bs4的find_all函数,返回一个包含许多元素的列表,然后利用text属性提取有用的字符逐个输出。

以下为获取旅游网的信息
# -*- coding: utf-8 -*-
import requests #导入requests包
from bs4 import BeautifulSoup
url='http://www.cntour.cn/'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'}
strhtml=response = requests.get(url,headers=headers)
soup=BeautifulSoup(strhtml.text,'lxml') #解析
#手动选择
data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li:nth-child(3) > a')
print(data)
print(soup.p.string)#获取字符串
for item in data:
result={
'title':item.get_text(), #获取内容
'link':item.get('href') #获取链接
}
print(result)
import re
for item in data:
result={
"title":item.get_text(),
"link":item.get('href'),
'ID':re.findall('\d+',item.get('href'))#使用正则表达式
}
print(result)
代码说明:
1.
data = soup.select('#main>div>div.mtop.firstMod.clearfix>div.centerBox>ul.newsList>li>a')
获取选择方法是,选中想要的模块,右键点击检查
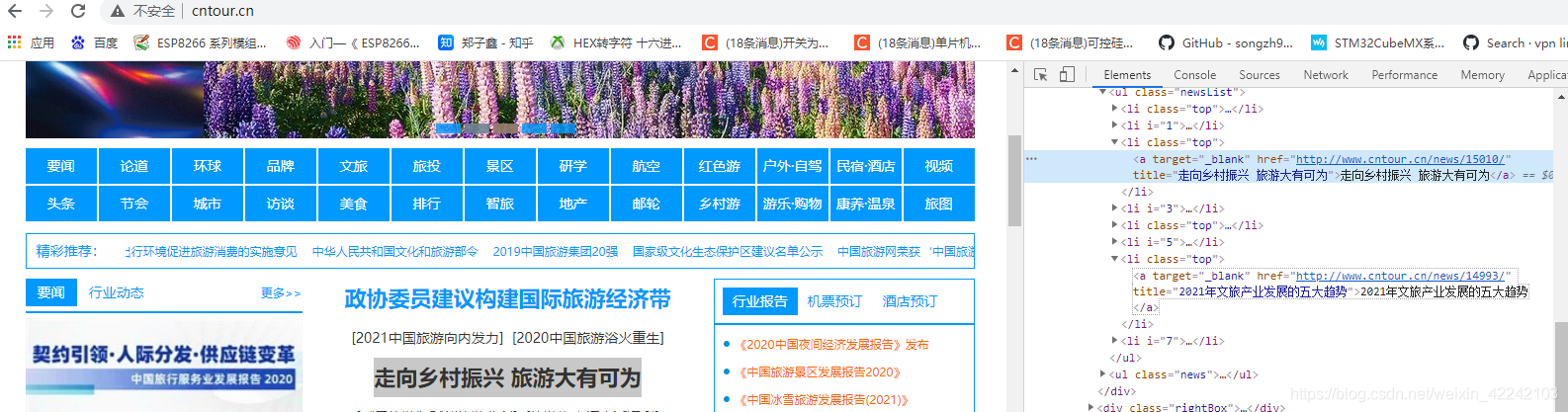
跳转到相应的位置,右键点击copy->copy selector, 粘贴就可得到
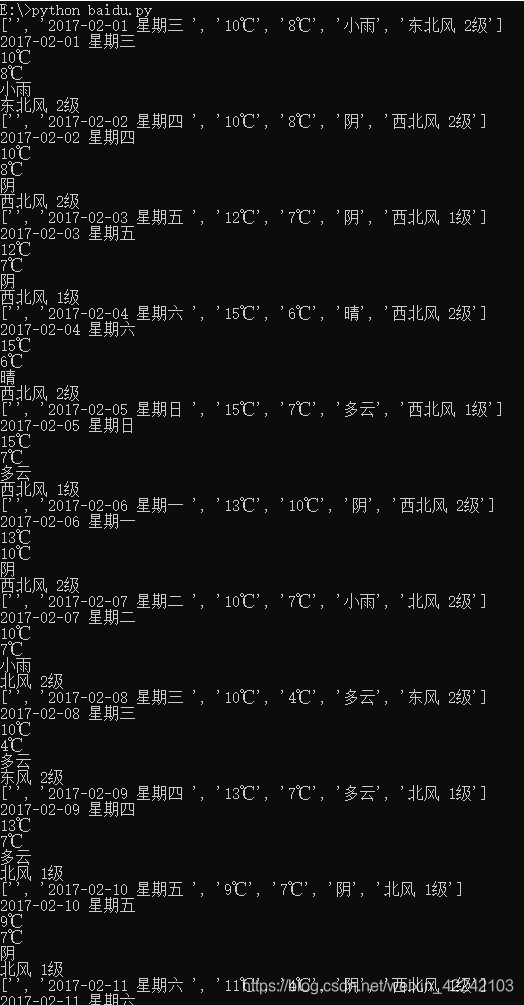
获取历史天气信息
# -*- coding: utf-8 -*-
import requests #导入requests包
from bs4 import BeautifulSoup
url='http://lishi.tianqi.com/chongqing/201702.html'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'}
strhtml=response = requests.get(url,headers=headers)
soup=BeautifulSoup(strhtml.text,'html.parser') #解析
temp = soup.find_all('ul', class_="thrui")
temp1 = temp[0].find_all('li')#获取li的内容
#print(temp1)
#print(temp)
for item1 in temp1:
str = item1.get_text().splitlines()#按行分割,放在一个list里
print(str)
for i in range(1, len(str)):
if len(str[i]) != 0:
print(str[i])



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









