




 本文详细解释了PyTorch中`torch.nn.Conv2d`函数的各个参数含义,包括输入通道数、输出通道数、卷积核大小、步长、填充、膨胀卷积等,以及它们如何影响卷积操作的结果。
本文详细解释了PyTorch中`torch.nn.Conv2d`函数的各个参数含义,包括输入通道数、输出通道数、卷积核大小、步长、填充、膨胀卷积等,以及它们如何影响卷积操作的结果。
不仔细看代码是真不知道以前的代码都是白跑了,里面的东西根本就没搞懂。
self.conv1 = nn.Conv2d(
in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
# 我们常用的这句代码,里面的参数到底都代表什么意思呢?Args:
in_channels (int): Number of channels in the input image
out_channels (int): Number of channels produced by the convolution # 卷积产生的通道数
kernel_size (int or tuple): Size of the convolving kernel
stride (int or tuple, optional): Stride of the convolution. Default: 1
# 整数型 or 元组,可选 :
padding (int, tuple or str, optional): Padding added to all four sides of
the input. Default: 0
padding_mode (string, optional): ``'zeros'``, ``'reflect'``,
``'replicate'`` or ``'circular'``. Default: ``'zeros'``
# 填充模式:默认以0填充
dilation (int or tuple, optional): Spacing between kernel elements. Default: 1
# 控制膨胀卷积 内核元素之间的间距
groups (int, optional): Number of blocked connections from input
channels to output channels. Default: 1
# 控制分组卷积 默认不分组,groups=1
bias (bool, optional): If ``True``, adds a learnable bias to the
output. Default: ``True``参数 kernel_size,stride,padding,dilation 都可以是一个整数或者是一个元组,一个值的情况将会同时作用于高和宽 两个维度,两个值的元组情况代表分别作用于高或宽维度。
dilation:控制卷积核选的元素之间的间距【可选】默认为1,好像叫膨胀卷积?
1.dilation=1的话(默认情况),效果如图:
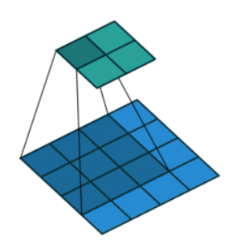
2.dilation=2,那么效果如图:
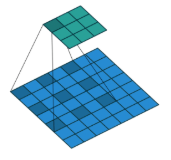
输入是蓝色,绿色是输出,可以看到dilation=1时输入间隔着一个格子。
另外,比如3*3卷积核里面那9个数,一开始是随机初始化后,后面根据loss,不断更新。


















 2248
2248



 到【灌水乐园】发言
到【灌水乐园】发言








