






InnoDB索引
数据存储
当innodb存储数据时,它可以使用不同的行格式进行存储,mysql5.7 版本支持以下格式的行存储方式
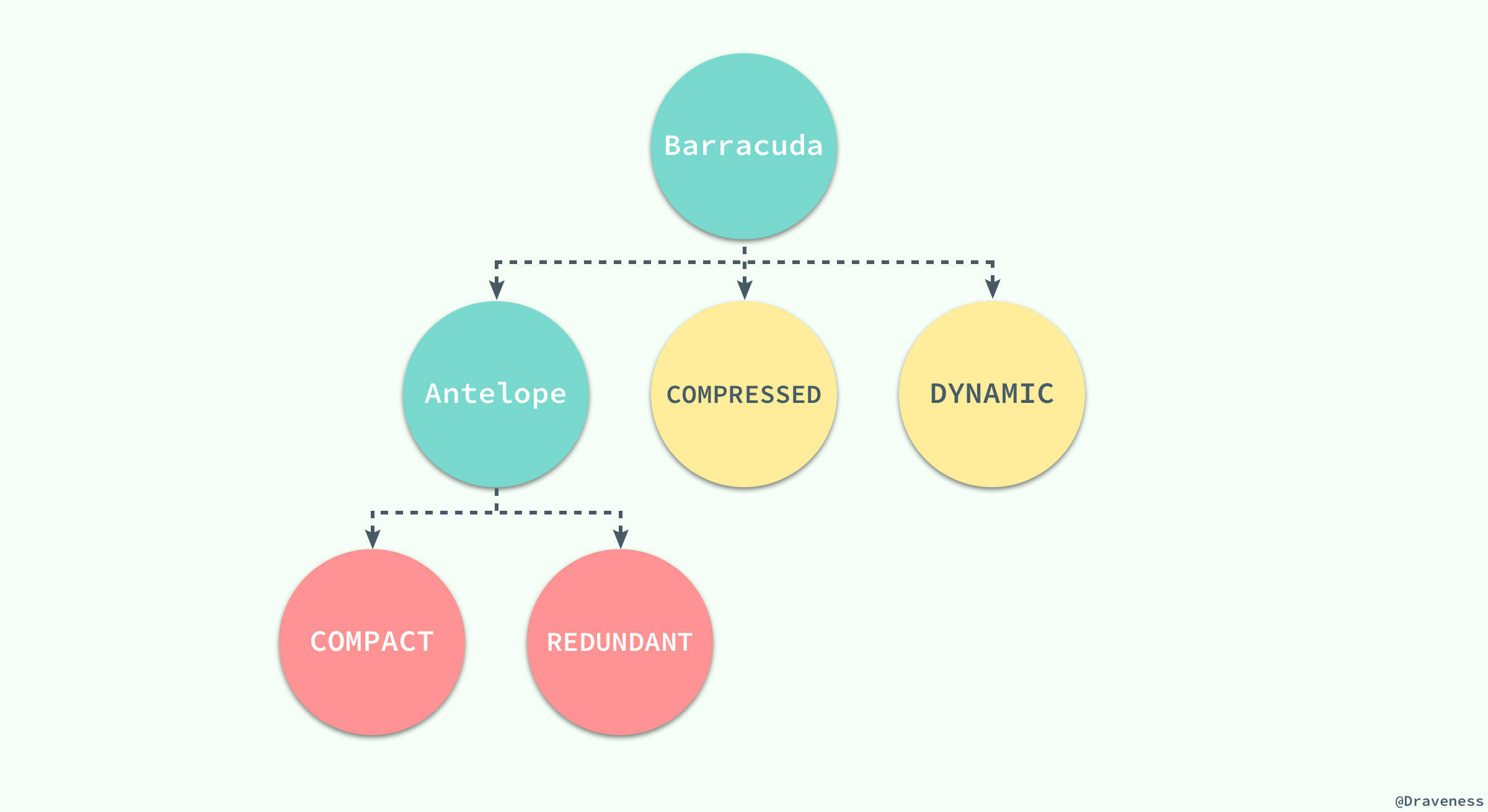
- barracuda
- antelope
-
compact -
redundant - compressed
- dynamic
antelope是innodb最开始支持的文件格式,它包含两个行格式compact和redundant,它最开始并没有名字;antelope的名字是在新的文件格式barracuda出现后才起的,barracuda的出现引入了两种新的行格式compressed和dynamic;innnodb对于文件格式都会向前兼容,而官方文档中也对之后出现的新文件格式预先定义好了名字:Cheetah、Dragon、Elk等等。 两种行记录格式Compact和Redundant在磁盘上按照以下方式存储
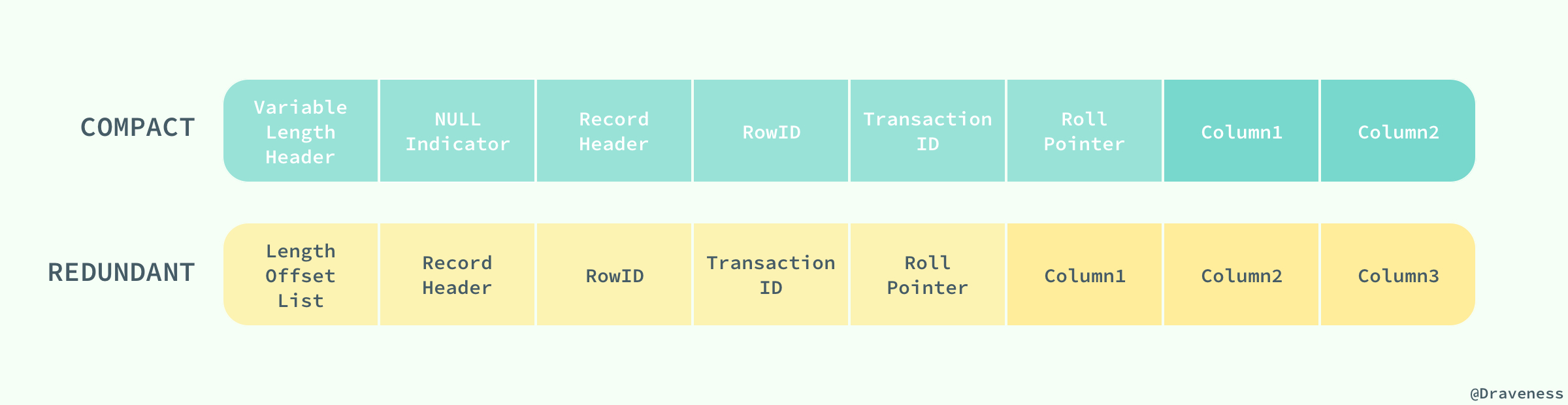
compact和redundant格式的最大的不同就是记录格式的第一部分;在compact中,行记录的第一部分倒序存放了一行数据中列的长度(length),而redundant中存的是每一列的偏移量(offset),从总体上来看,compact行记录格式相比redundant格式能够减少20%的存储空间。
行溢出数据
当innodb使用compact或者redundant格式存储极长的varchar或者blob这类大对象时,我们并不会直接将所有的内容都存放在数据页节点中,而是将数据中的前768个字节存储在数据页中,后面会通过偏移量指向溢出页(off-page),最大768字节的作用是便于创建前缀索引。溢出页(off-page)不存储在B+tree中,使用的是uncompress blob page,并且每个字段的溢出都是存储独享。
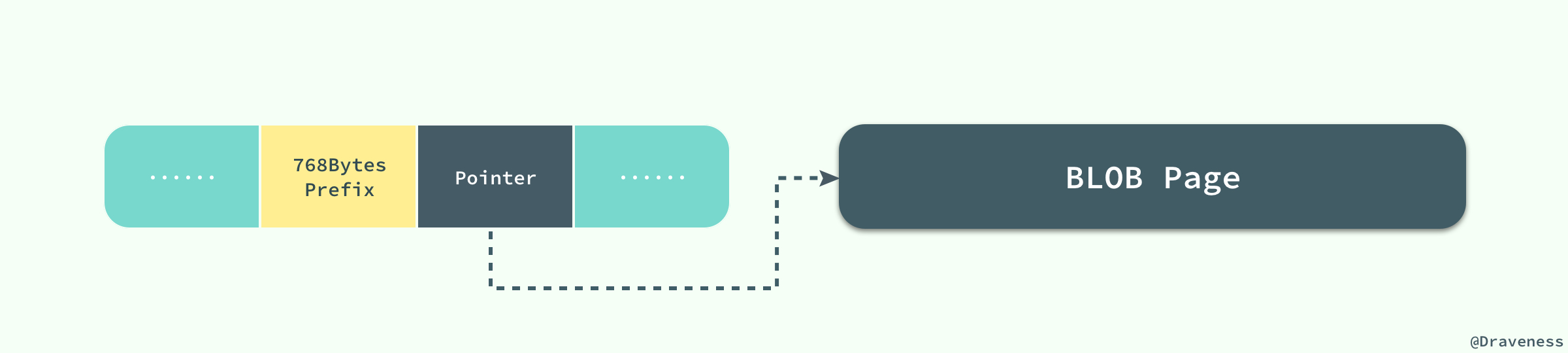
但是我们使用新的行记录格式compressed或者dynamic时都只会在行记录中保存20个字节的指针,实际的数据都会存在溢出页面中。
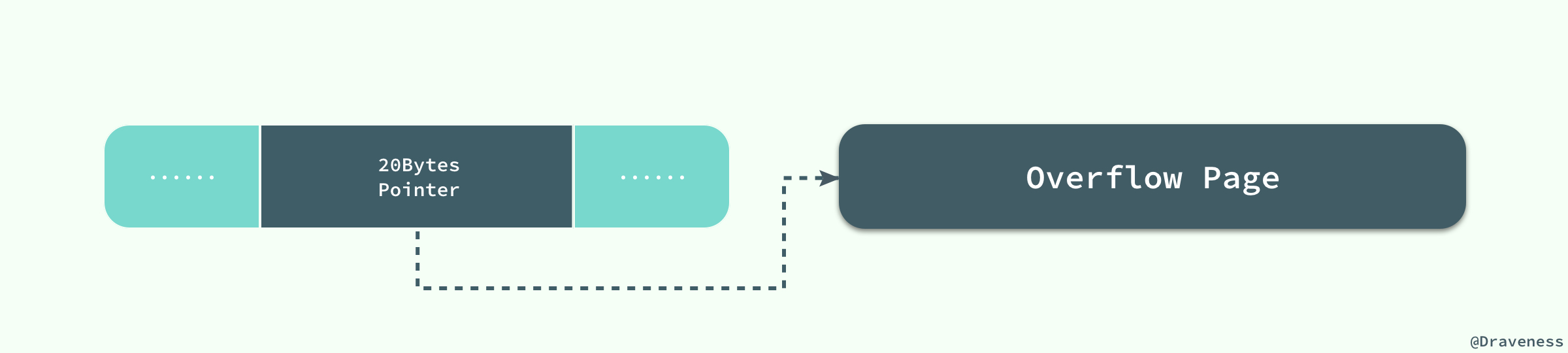
当然在实际存储中,可能会对不同长度的text和blob列进行优化。
想要了解更多与innodb存储引擎中记录的数据格式的相关信息,可以阅读InnoDb Record Structure
数据页结构
与现有的大多数存储引擎一样,Innodb使用页作为磁盘管理的最小单位;数据在Innodb存储引擎中都是按照行存储的。每个16kb大小的页中可以存放2-200行的记录。
页是Innodb存储引擎管理数据的最小磁盘单位,而B-tree节点就是实际存放表中数据的页面,我们在这里将要介绍页是如何组织和存储记录的;首先,一个InnoDB页有以下七个部分:

每一个页中包含了两对header/trailer:内部的page header/page directory关心的是页的状态信息,而fil header/fil trailer关心的是记录页的头信息。 在页的头部和尾部之间就是用户记录和空闲空间了,每一个数据页中都包含infimum和supremum这两个虚拟的记录(可以理解为占位符),infimum记录是比该页中任何主键值都要小的值,Supremum是该页中的最大值:
user records 就是整个页面中真正用于存放行记录的部分,而free space就是空余空间了,它是一个链表的数据结构,为了保证插入和删除的效率,整个页面并不会按照主键顺序对所有记录进行排序,它会自动从左侧向右寻找空白节点进行插入,行记录在物理存储上并不是按照顺序的,它们之间的顺序是由next_record这一指针控制的。
B+树在查找对应的记录时,并不会直接从树中找出对应的行记录,它只能获取记录所在的页,将整个页加载到内存中,再通过Page directory中存储的稀疏索引和n_owned、next_record属性取出对应的记录,不过因为这一操作是在内存操作的,所以通常会忽略这部分查找的耗时。这样就存在一个命中率的问题,如果一个page中能够相对的存放足够的行,那么命中率就会相对高一些,性能就会有所提升。
B+树底层的叶子节点为一双向链表,因此 每个页中至少该有两行记录,这样就决定了Innodb在存储一行数据的时候不能超过8kb,但事实上应该更小,因为还有innodb内部的数据要存储。
通常我们认为blob这类的大对象的存储会把数据存放在off-page,其实不然,关键点还是看一个page中到底能否存放两行数据,blob可以完全存放在数据页中(单行长度没有超过8kb),而varchar类型的也有可能存放在溢出页中(单行长度超过8kb,前768byte存放在数据页中)。
索引
索引是数据库中非常非常重要的概念,它是存储引擎能够快速定位记录的秘密武器,对于提升数据库性能、减轻数据库服务器的负担有着非常重要的作用;索引优化是对查询性能优化的最有效手段,它能够轻松地将查询性能提高几个数量级。
Innodb存储引擎在绝大多数情况下使用B+树建立索引,这是关系型数据库中查找最为常用和有效的索引,但是B+树索引并不能找到一个给定键对应的具体值,它只能找到数据行对应的页,然后正如上一节所提到的,数据库把整个页读入到内存中,并在内存中查找具体的数据行。
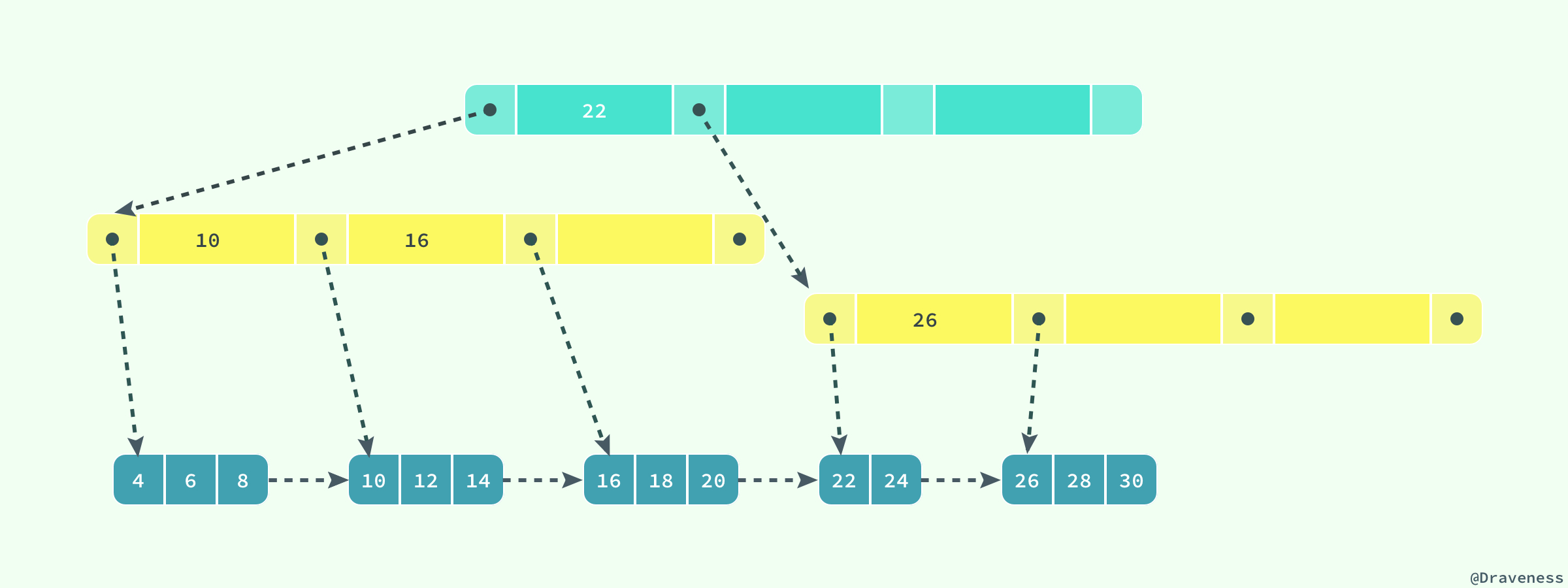
B+树是平衡树,它查找任意节点所耗费的时间都是相同的,比较的次数就是B+树的高度;
B+树的叶子节点存放所有指向关键字的指针,节点内部关键字记录和节点之间都根据关键字的大小排列。当顺序递增插入的时候,只有最后一个节点会在满掉的时候引起索引分裂,此时无需移动记录,只需创建一个新的节点即可。而当非递增插入的时候,会使得旧的节点分裂,还可能伴随移动记录,以便使得新数据能够插入其中。一般建议使用一列顺序递增的id来作为主键,但不必是数据库中autoincrement字段,只要满足顺序增加即可,如twitter的snowflake即为顺序递增的Id生成器。
B+树的高度
这里我们先假设B+树高为2,即存在一个根节点和若干个叶子节点,那么这棵B+树的存放总记录树为:根节点指针数*单个叶子节点记录行数。这里假设一行记录的大小为1K,那么一个页上的能放16行数据。假设主键id为bigint类型,长度为8字节,而指针大小在Innodb源码中设置为6字节,这样一共14个字节,那么可以算出一颗高度为2的B+树,能存放16x1024/14x16=18720条这样的数据记录。
根据同样的原理我们可以算出一个高度为3的B+树可以存放:1170x1170x16=21902400条这样的记录。所以在Innodb中B+树高度一般为1到3层,它就能满足千万级别的数据存储。
聚集索引
innodb存储引擎中的表都是使用索引组织的,也就是按照键的顺序存放;聚集索引就是按照表中主键的顺序构建一颗B+树,并在叶节点中存放表中的行记录数据。
如果没有主键,则会用非空的unique键做主键;如果没有非空的unique键,则系统生成一个6字节的rowid做主键;
CREATE TABLE users( id INT NOT NULL, first_name VARCHAR(20) NOT NULL, last_name VARCHAR(20) NOT NULL, age INT NOT NULL, PRIMARY KEY(id), KEY(last_name, first_name, age) KEY(first_name) );如果使用上面的sql在数据库中创建一张表,B+树就会使用id作为索引的键,并在叶子节点中存储一条记录中的所有信息
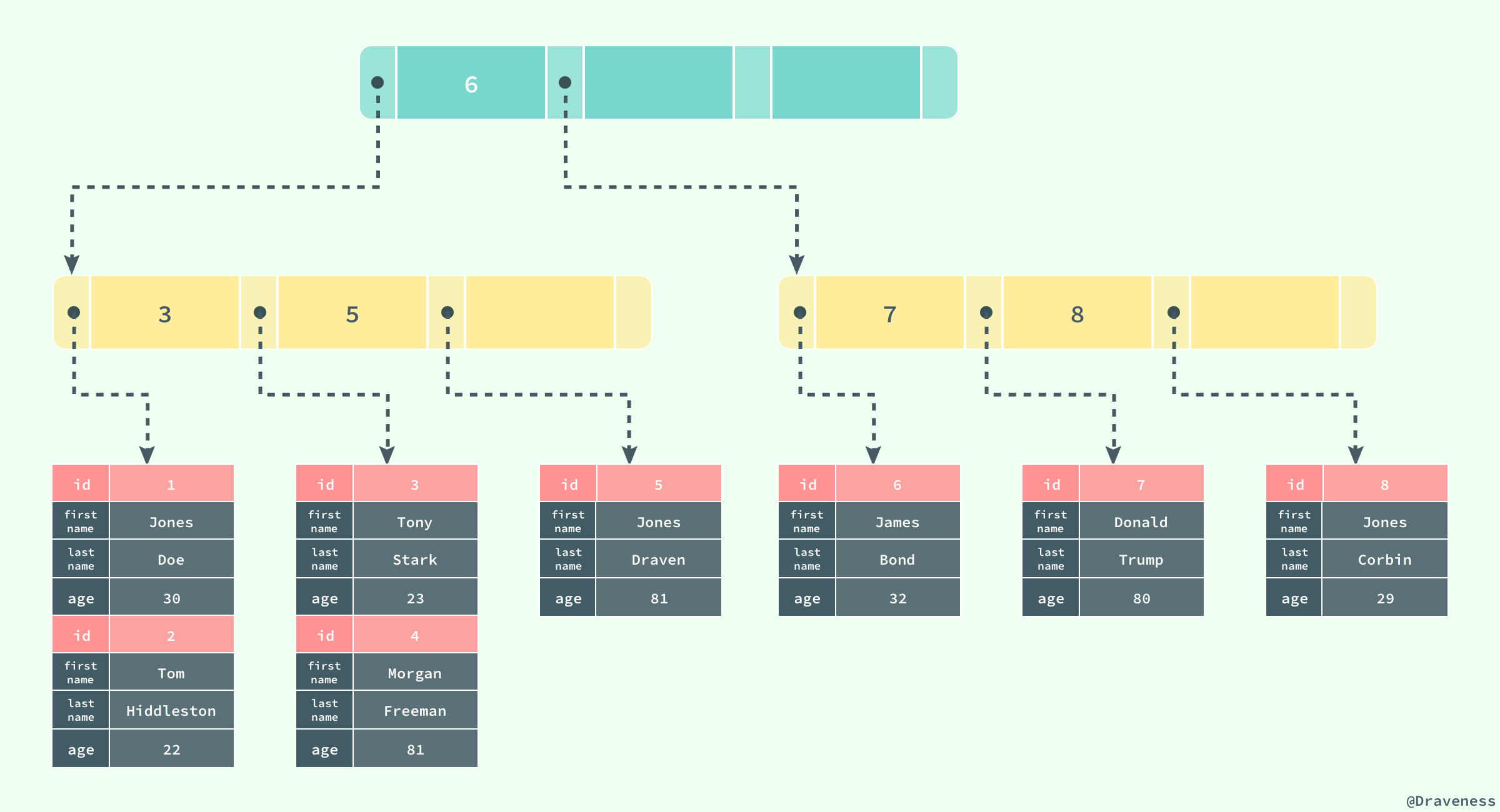
图中对于B+树的描述与真实情况下B+树中的数据结构有一些差别,不过这里想表达的主要意思是:聚集索引叶节点中保存的事整条记录,而不是其中一部分
聚集索引与表的物理存储方式有着非常密切的关系,所有正常的表应该有且仅有一个聚集索引(绝大多数情况下都是主键),表中的所有行记录数据都是按照聚集索引的顺序存放的。
当我们使用聚集索引对表中的数据进行检索时,可以直接获得聚集索引所对应的整条记录数据所在的页,不需要进行第二次操作。
辅助索引
数据库将所有的非聚集索引都划分为辅助索引,但是这个概念对我们理解辅助索引并没有什么帮助;辅助索引也是通过B+树实现的,但是它的叶节点并不包含行记录的全部数据,仅包含索引中的所有键和一个用于查找对应行记录的“书签”,在innodb中这个书签就是当前记录的主键。
辅助索引的存在并不会影响聚集索引,因为主机索引构成的B+树是数据实际存储的形式,而辅助索引只用于加速数据的查找,所以一张表上往往有多个辅助索引以此来提升数据库的性能。
一张表一定包含一个聚集索引构成的B+树以及若干辅助索引构成的B+树。
如果在表users中存在一个辅助索引(first_name,age),那么它构成的B+树大致就是上图这样,按照(first_name,age)的字母顺序对表中的数据进行排序,当查找主键时,再通过聚集索引获取到整条行记录(回表)
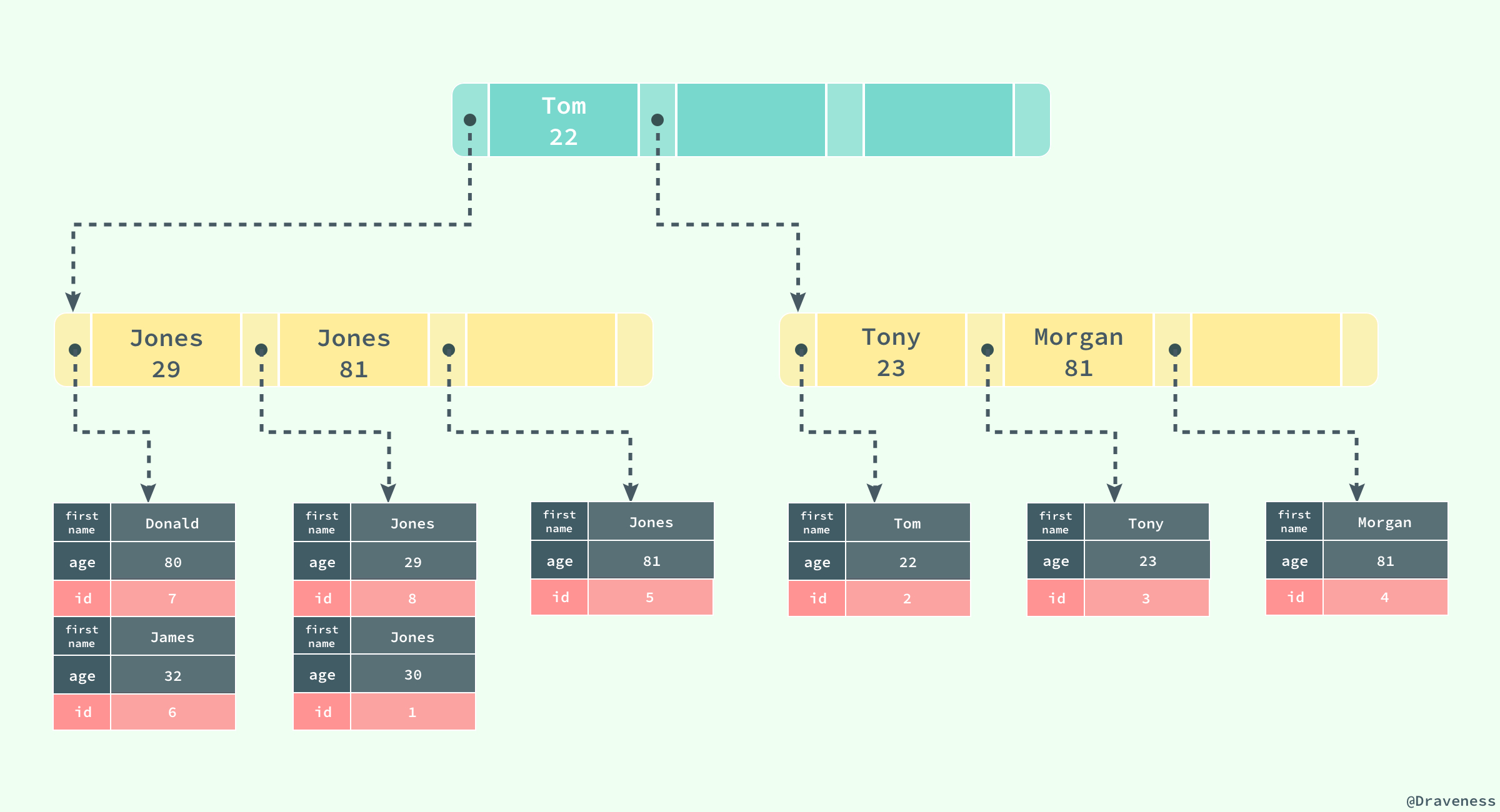
覆盖索引
聚簇索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录,这种行为称之为回表。回表会导致查询时多次读取磁盘,为减少IO mysql在辅助索引上进行了优化,将辅助索引作为覆盖索引(covering index)。在查询的时候,如果select 子句中的字段为主键,辅助索引的键则不进行回表。
索引失效
索引并不是时时都会生效的,比如以下几种情况,将会导致索引失效:
- 如果条件中有or,即使其中有条件带索引也不会使用。要想实验or,又想要索引生效,只能将or条件的每个列都加上索引
- 对于多列索引,不是使用的最左匹配,则不会使用索引。
- 如果mysql估计使用全表扫描要比使用索引快,则不使用索引。例如,使用<>、not in、not exist,对于这三种情况大多数情况下认为结果集很大,mysql就有可能不使用索引。
索引使用
- select
- distinct<select_list>
- from<left_table>
- <join_type>JOIN <right_table>
- ON<join_condition>
- where<where_condition>
- group by<group_by_list>
- having<having_condition>
- order by<order_by_condition>
- limit<limit_number>
关于sql语句的执行,有三个值得我们注意的地方:
- from才是sql语句执行的第一步,并非select。数据库在执行sql语句的第一步是将数据从硬盘加载到数据缓存区中,以便对这些数据进行操作。
- select 是在大部分语句执行了之后才执行的,严格的说是在from和group by之后执行。理解这一点事非常重要的,这就是你不能在where中使用在select 中设定别名的字段作为判断条件的原因。
- 无论在语法上还是在执行顺序上,union总是排在order by之前。很多人认为每个union段都能使用order by排序,但是根据sql语言标准和各个数据库sql的执行差异来看,这并不是真的。尽管某些数据库允许sql语句对子查询(subqueries)或者派生表(derived tables)进行排序,但是这并不说明这个排序在union操作过后仍保持排序后的顺序。
虽然sql的逻辑查询是根据上述进行查询,但是数据库也许并不会完全按照逻辑查询处理的方式来进行查询。mysql数据库有两个组件parser(分析sql语句)和Optimizer(优化)。
从官方手册上看,可以理解为,mysql采用了基于开销的优化器,以确定处理查询的最解方式,也就是说执行查询之前,都会先选择一条自以为最优的方案,然后执行这个方案来获取结果。在很多情况下,mysql能够计算最佳的可能查询计划,但是在某些情况下,mysql没有关于数据的足够信息,或者是提供太多的相关数据信息,估测就没那么友好了。
存在索引的情况下,优化器优先使用条件用到索引且最优的方案。当sql条件有多个所以可以选择,mysql优化器将直接使用效率最高的索引执行。


















 2522
2522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









