







 本文探讨了数据预处理中的抽样、异常值处理及特征工程的重要性,包括特征选择、特征变换与降维等关键步骤,旨在提升机器学习模型的性能。
本文探讨了数据预处理中的抽样、异常值处理及特征工程的重要性,包括特征选择、特征变换与降维等关键步骤,旨在提升机器学习模型的性能。
数据样本抽样
样本具有代表性(比例保持一致)
样本比例平衡以及样本不平衡时如何处理
尽量使用全量数据Hadoop spark
1.异常值(空值)处理
1.识别异常值和重复值
Pandas:isnull()/duplicated
2.直接丢弃
Pandas:drop()/dropna()/drop_duplicated()
3.异常值(空值)处理
当是否有异常当作一个新的属性,代替原值
Pandas:fillna()
4.集中值指代
Pandas:fillna()
5.边界值指代
Pandas:fillna()
6.差值
Pandas:interpolate()–Series
2.特征与处理–标注(Label)
反应目的的,不容易获得的,我们关注的,和其他数据相关的属性。
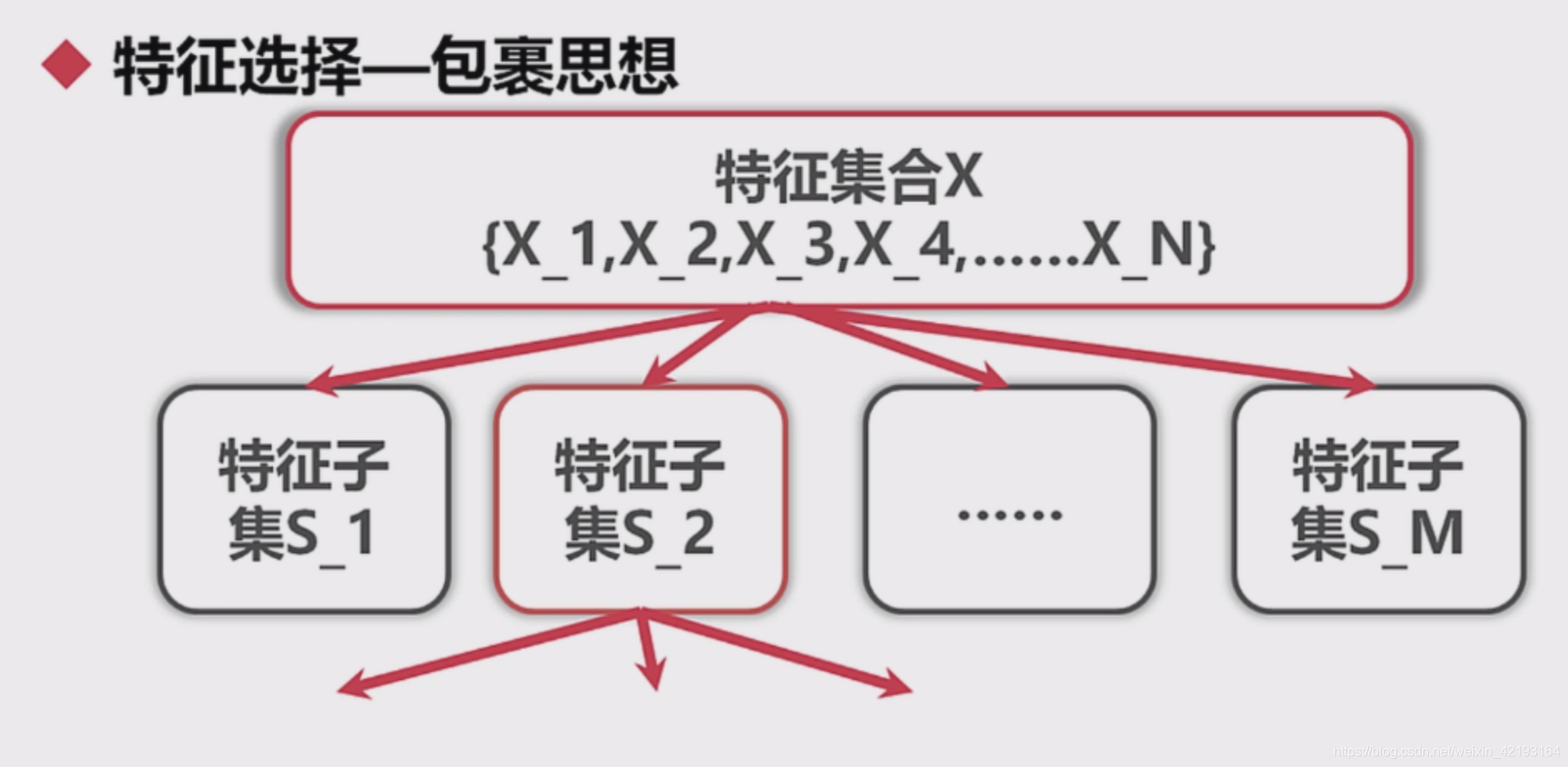
特征选择
剔除与标注不相关或者冗余的特征
1.数据规约的思路之一(另一个思路为抽样)
特征选择(之前有讲过)
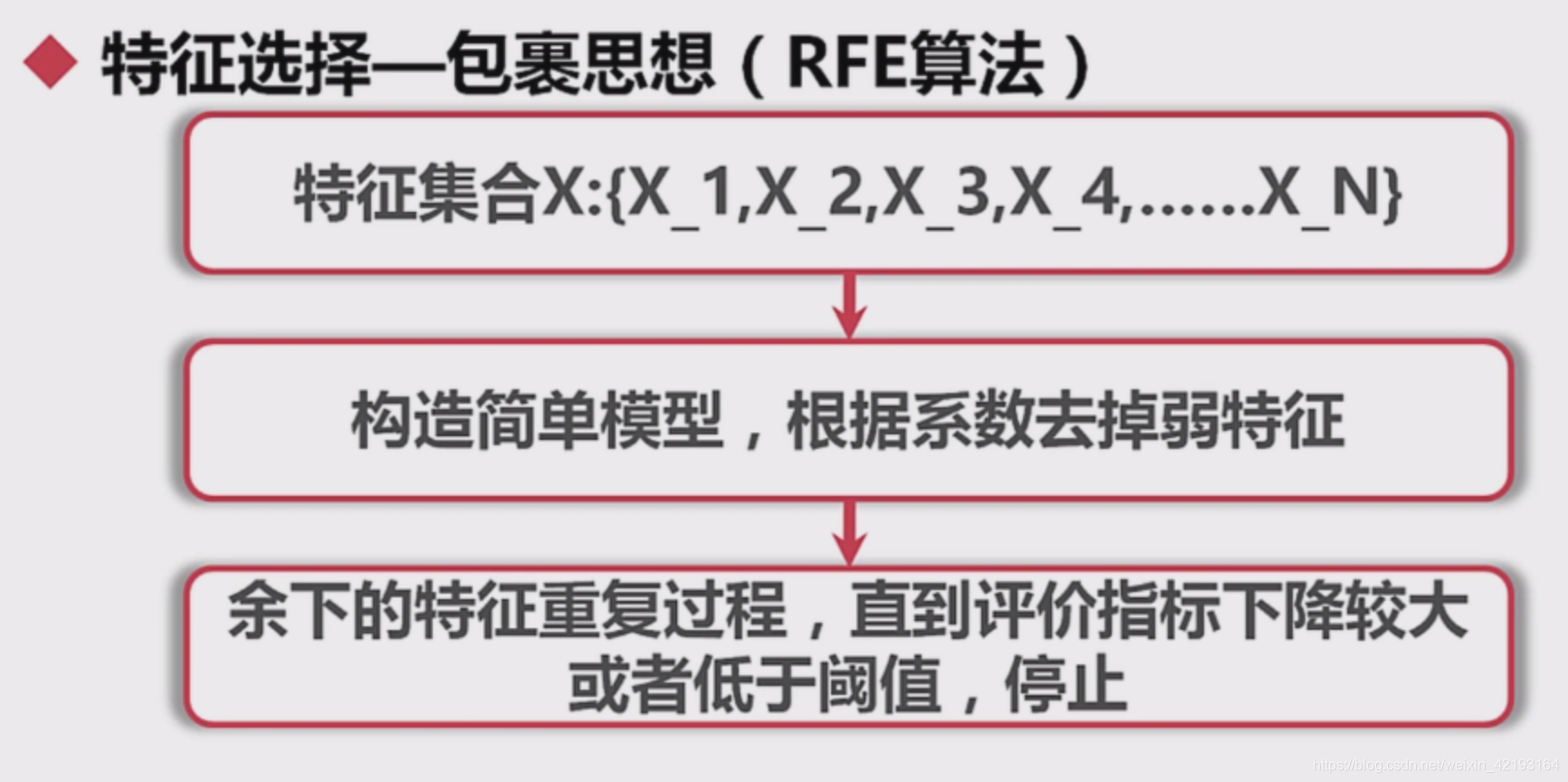
2.包裹思想(RFE算法)
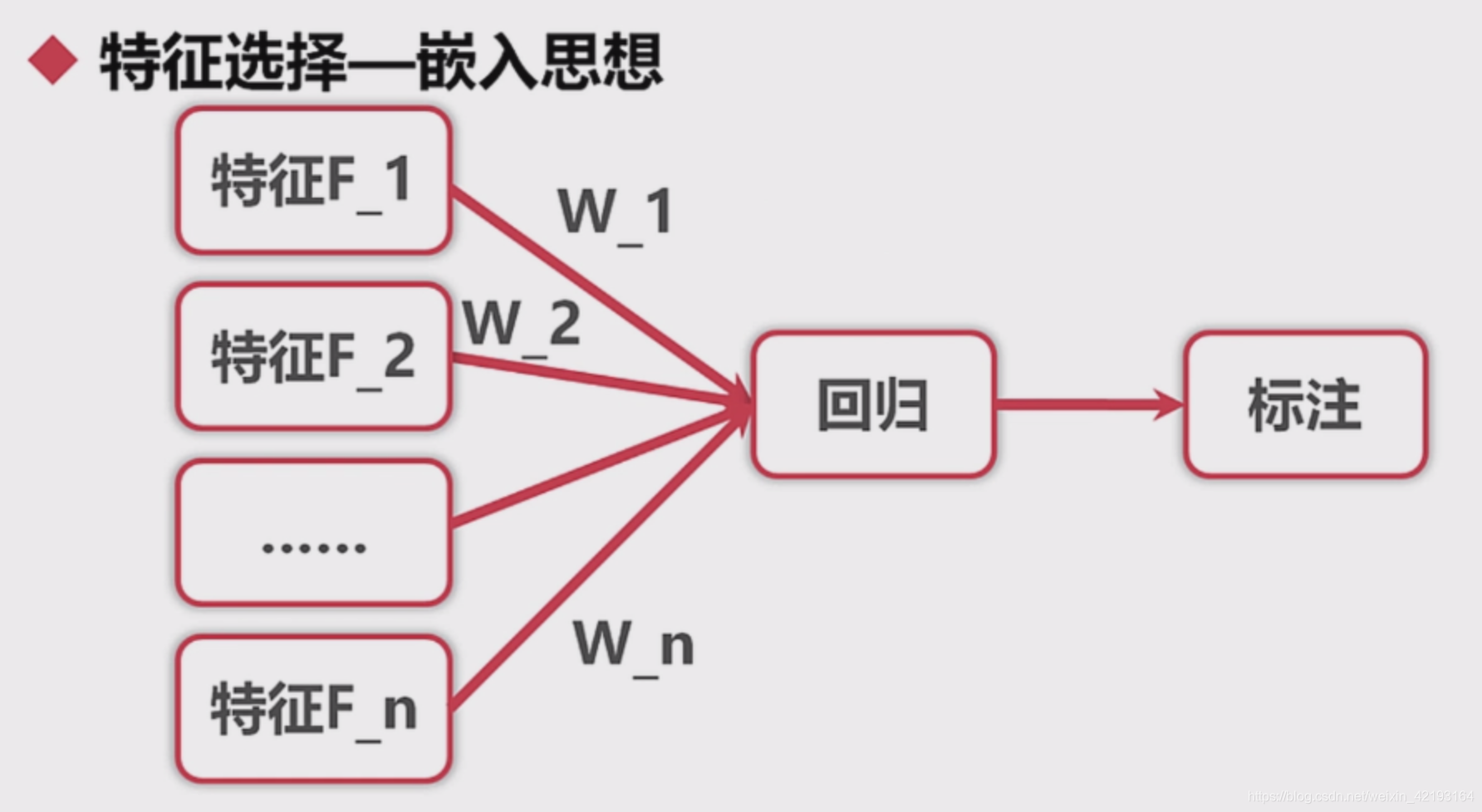
嵌入思想
特征变换
对值化,离散化,数据平滑,归一化(标准化),数值化,正规化

















 755
755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









