







Hadoop 之 Spark 配置与使用
一.Spark 配置
环境说明
| 环境 | 版本 |
|---|---|
| Anolis | Anolis OS release 8.6 |
| Jdk | java version “11.0.19” 2023-04-18 LTS |
| Spark | 3.4.1 |
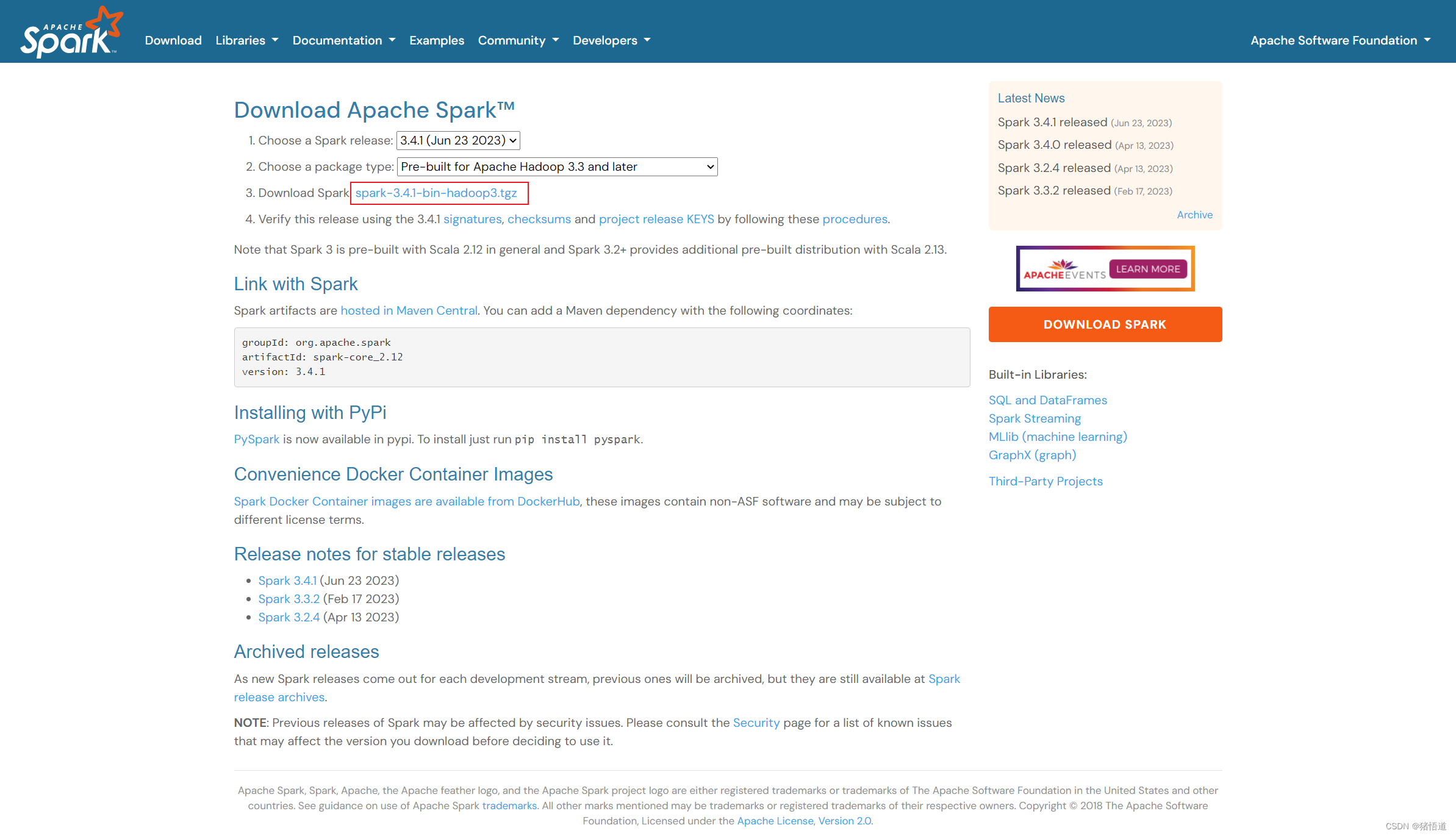
1.Spark 下载
2.单机测试环境配置
## 1.创建目录
mkdir -p /usr/local/spark
## 2.解压 sprak 到指定目录
tar -zxvf spark-3.4.1-bin-hadoop3.tgz -C /usr/local/spark/
## 3.进入安装目录(可将解压后文件夹重命名为 spark 即可)
cd /usr/local/spark/spark-3.4.1-bin-hadoop3/
## 4.修改环境变量并更新
echo 'export SPARK_HOME=/usr/local/spark/spark-3.4.1-bin-hadoop3' >> /etc/profile
echo 'PATH=${SPARK_HOME}/bin:${PATH}' >> /etc/profile
source /etc/profile
## 5.复制 spark 配置
cd $SPARK_HOME/conf
cp spark-env.sh.template spark-env.sh
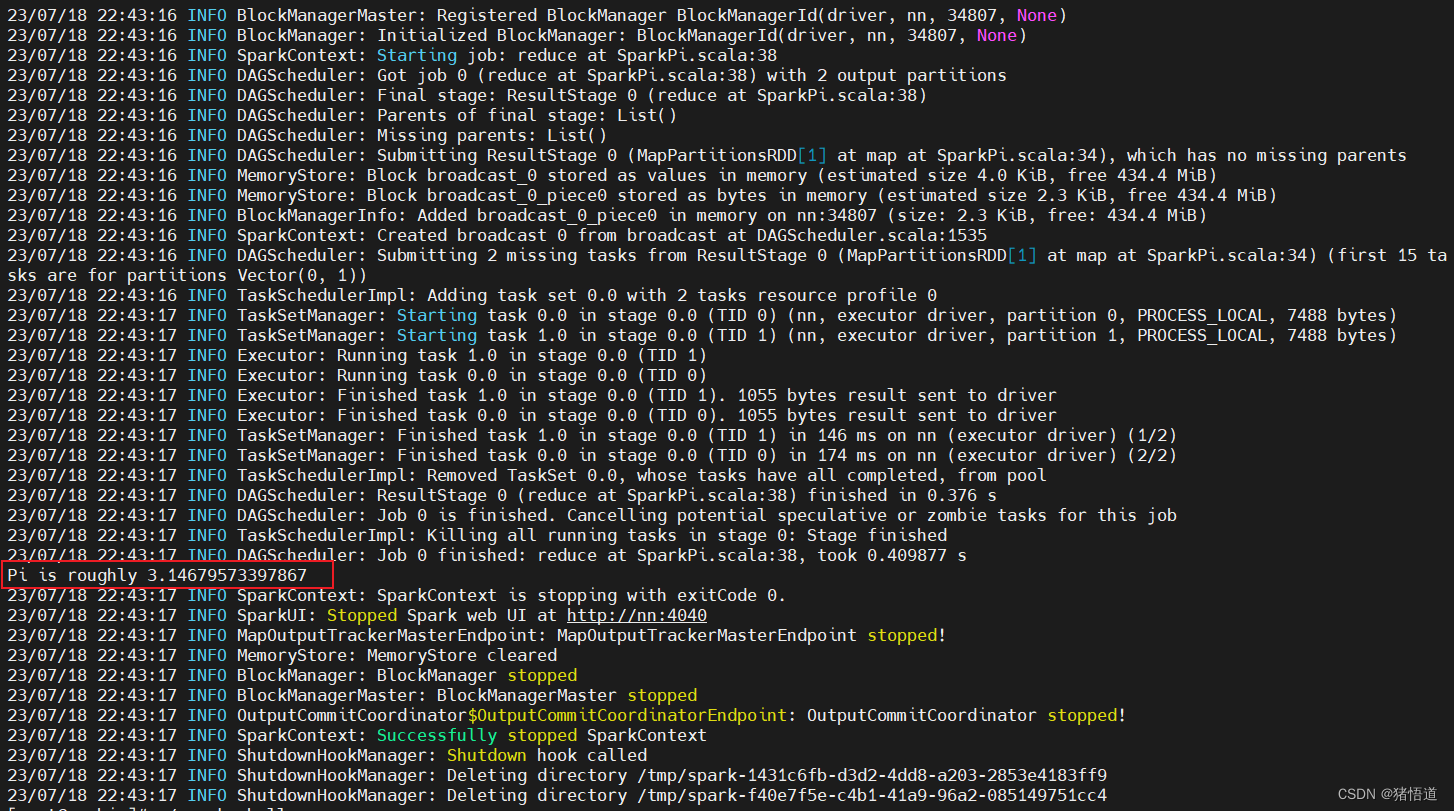
## 6.测试
cd $SPARK_HOME/bin
./run-example SparkPi
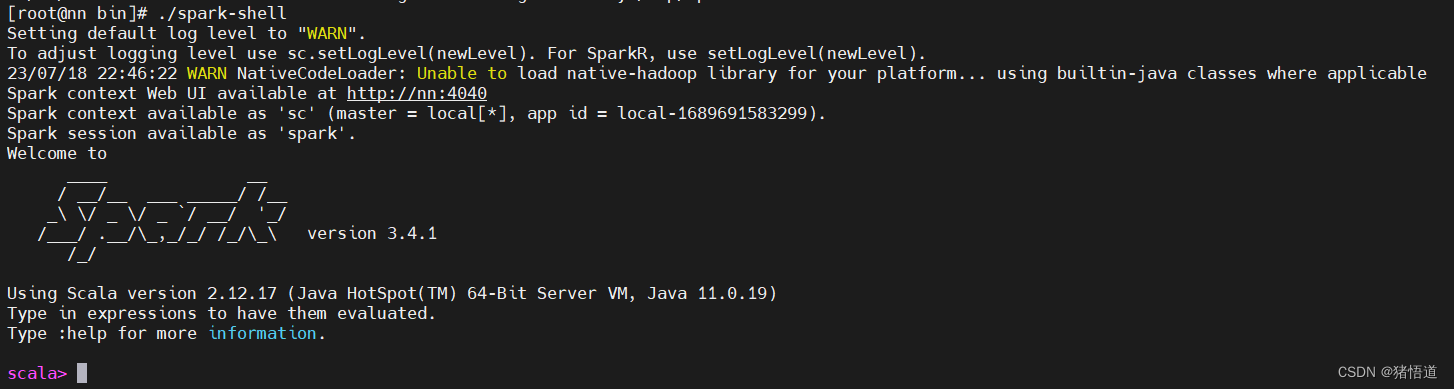
## 1.启动
./spark-shell
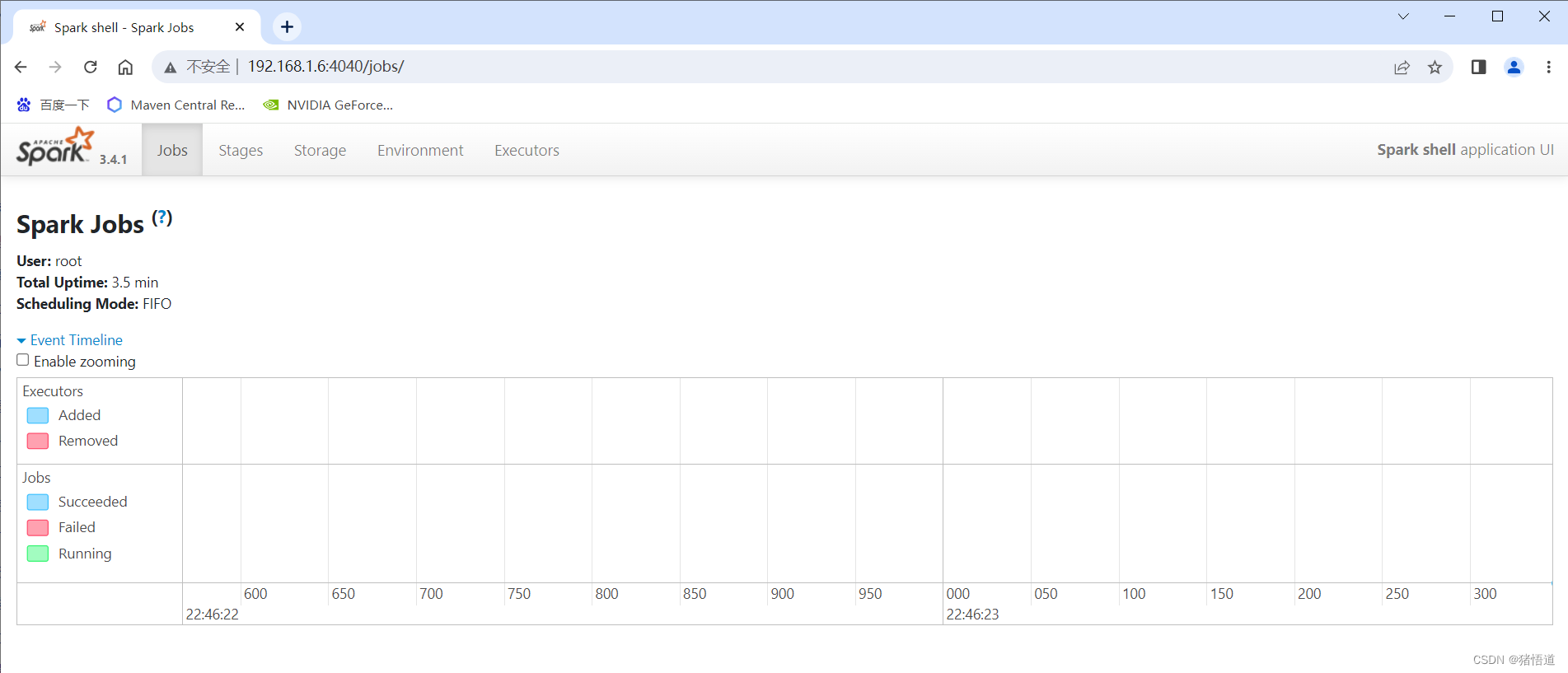
UI访问:控制打印地址为虚拟机域名,Windows 未添加 Host 解析,直接通过IP地址访问
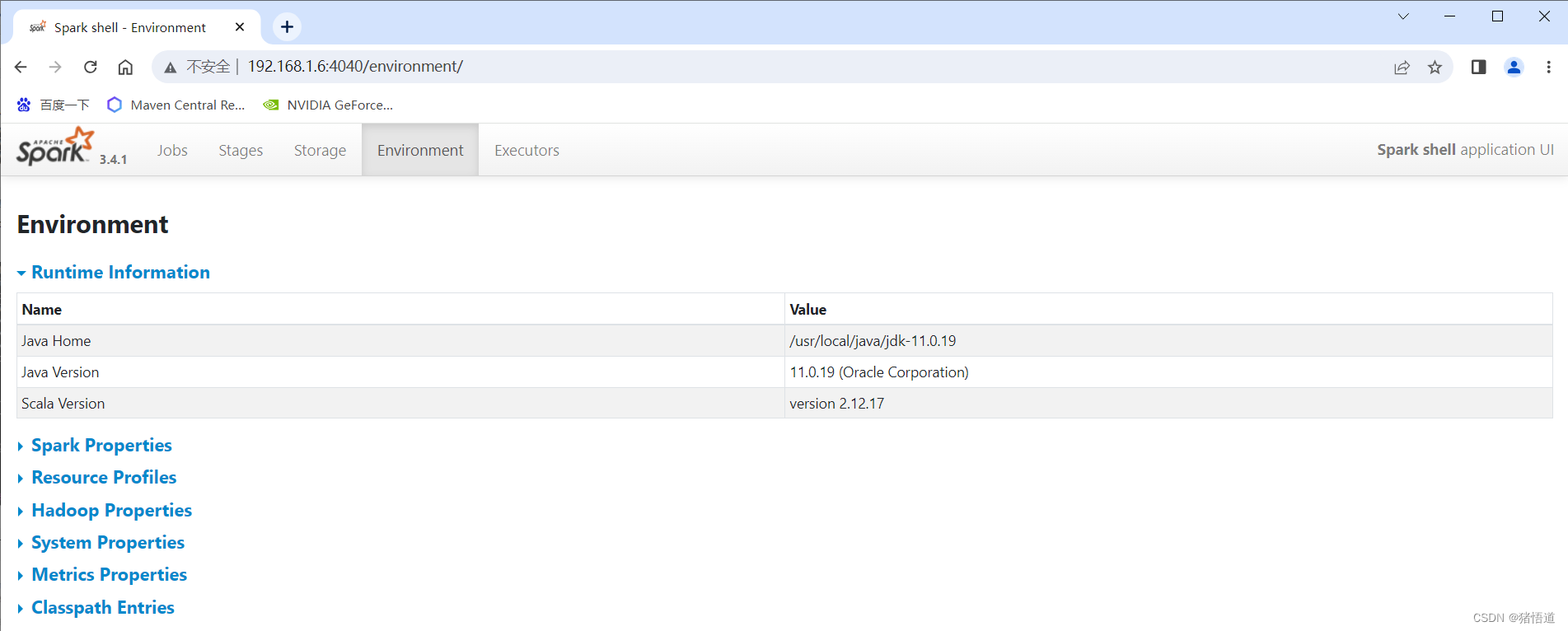
## 1.停止
scala> :quit
## 1.交互分析
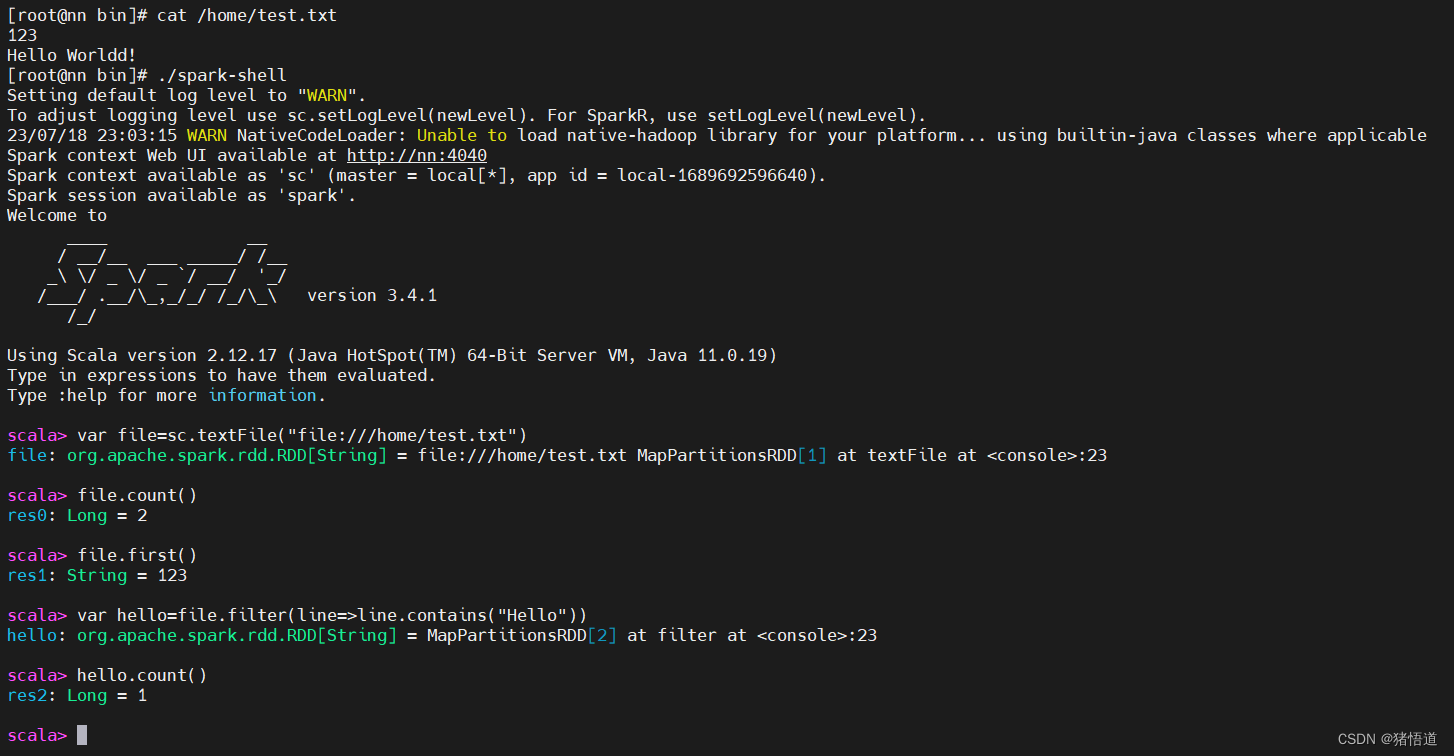
cd $SPARK_HOME/bin
cat /home/test.txt
./spark-shell
## 2.取文件
var file=sc.textFile("file:///home/test.txt")
## 3.打印行数和第一行信息
file.count()
file.first()
## 4.过滤
var hello=file.filter(line=>line.contains("Hello"))
hello.count()
3.集群配置
| 域名 | 地址 | 类别 |
|---|---|---|
| nn | 192.168.1.6 | master |
| nd1 | 192.168.1.7 | slave |
| nd2 | 192.168.1.8 | slave |
同单机配置,在 nd1 、nd2 部署 spark,并设置环境变量(也可利用 scp 命令将住节点下配置好的文件拷贝到从节点)
## 1.修改 nn 配置(此处旧版本为 slave)
cd $SPARK_HOME/conf
cp workers.template workers
vim workers
## 2.添加主从节点域名
echo 'nn' >> workers
echo 'nd1' >> workers
echo 'nd2' >> workers
## 3.保存并将配置文件分发到 nd1、nd2
scp workers root@nd1:$SPARK_HOME/conf/
scp workers root@nd2:$SPARK_HOME/conf/
## 4.增加 spark 配置
echo 'export JAVA_HOME=/usr/local/java/jdk-11.0.19/' >> spark-env.sh
echo 'export SPARK_MASTER_HOST=nn' >> spark-env.sh
echo 'export SPARK_MASTER_PORT=7077' >> spark-env.sh
## 5.将配置分发到 nd1、nd2
scp spark-env.sh root@nd1:$SPARK_HOME/conf/
scp spark-env.sh root@nd2:$SPARK_HOME/conf/
workers 文件配置内容如下
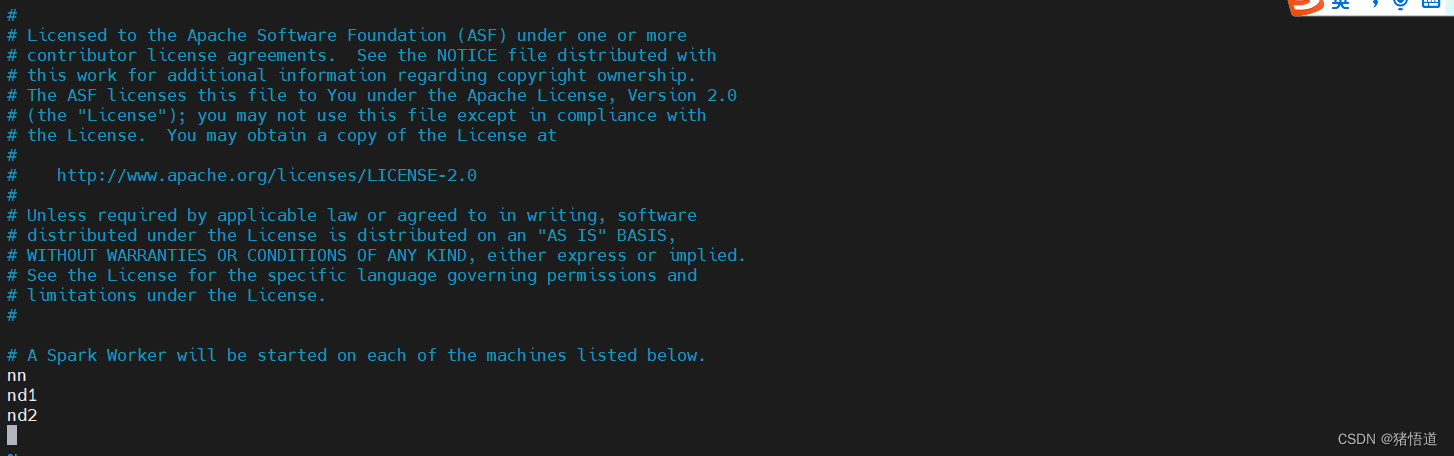
## 1.修改 host 将本机域名与IP地址绑定
vim /etc/hosts
## 2.启动
cd $SPARK_HOME/sbin/
./start-all.sh
## 3.停止
./stop-all.sh
Host 配置

启动日志
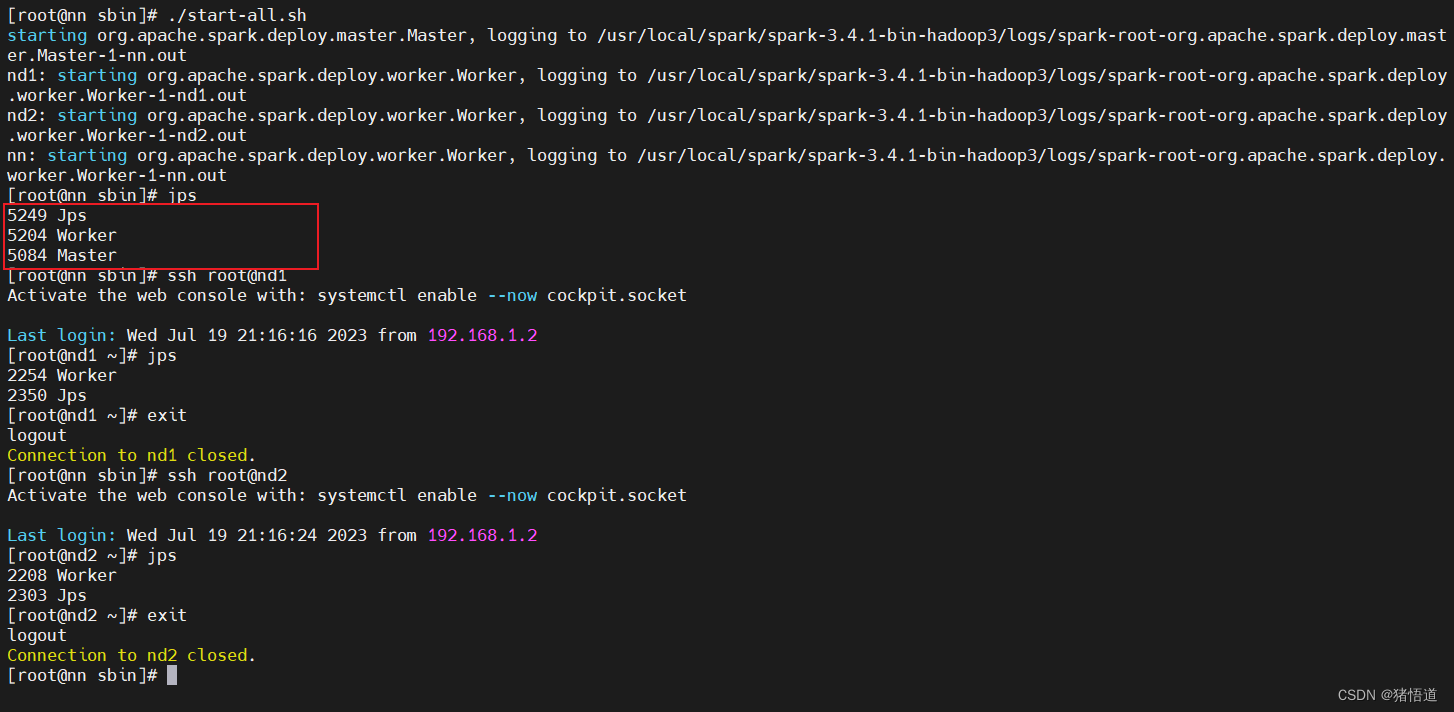
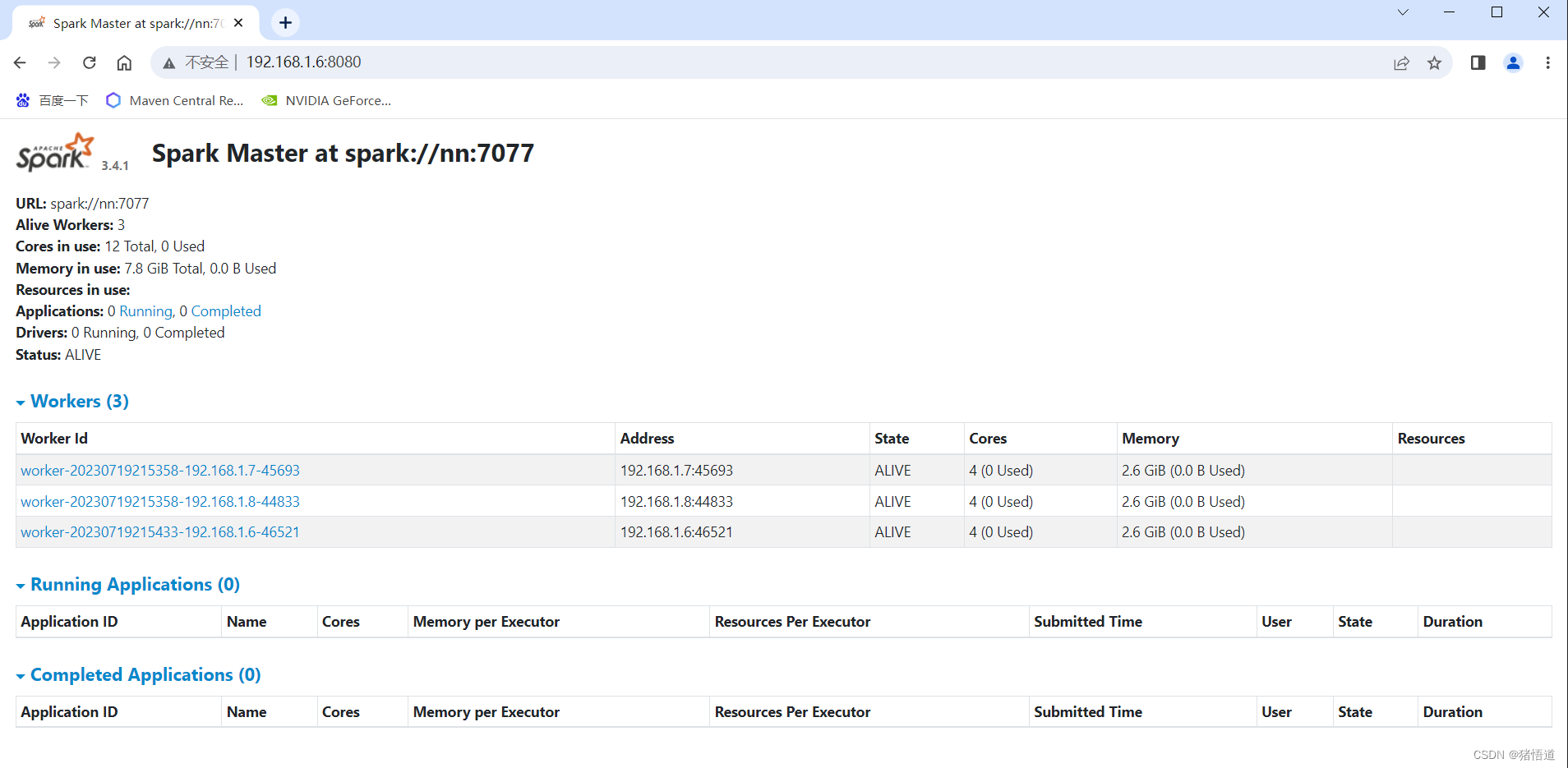
查看集群 UI:http://192.168.1.6:8080/
二.Java 访问 Spark
当前测试环境为 VM Ware 虚拟机,本地为 WIN 10 IDEA
调试问题记录:
- Spark 回调本机超时,Win 防火墙未关闭,端口不通
- Lamdba 语法 cannot assign instance of java.lang.invoke.SerializedLambda,本地 Jdk 版本和 Spark 集群环境 Jdk 版本要一致
- String Serialized 序列化问题,Java 依赖包和 Spark Jar 包版本要一致
- Jdk 版本过高,某些类解析提示 unnamed,可以在 IDEA 启动命令配置上:–add-exports java.base/sun.nio.ch=ALL-UNNAMED
- 域名 由于虚拟机原因,本机存在虚拟网卡,虚拟机内访问本地会通过域名(默认本地主机名)访问,要注意服务回调端口绑定的地址是虚拟网卡地址还是真实网卡地址,并将该地址配置配置到虚拟机的 Hosts | Linu
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 5597
5597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











