







目录
1. 引言
1.1 Spark服务
新建Spark服务:
cd /etc/init.d
touch spark
chmod +x spark
用vim spark编辑spark,写入如下内容,然后按ESC输入:wq!保存。
#!/bin/bash
LOG_FILE=/var/log/spark.log
START_FILE=/root/spark-3.4.4/sbin/start-all.sh
STOP_FILE=/root/spark-3.4.4/sbin/stop-all.sh
RED='\033[0;31m'
NC='\033[0m'
check_dependencies() {
if ! hdfs dfsadmin -report &>/dev/null; then
echo -e "${RED}Error: HDFS didn't run!${NC}"
return 1
fi
if ! yarn node -list &>/dev/null; then
echo -e "${RED}Error: YARN didn't run!${NC}"
return 1
fi
}
case "$1" in
start)
if ! check_dependencies; then
exit 1
fi
echo "$(date '+%Y-%m-%d %H:%M:%S') Starting Spark cluster...">>$LOG_FILE
if $START_FILE >>$LOG_FILE 2>&1; then
echo "Spark started successfully."
else
echo -e "${RED}Spark failed to start, Check $LOG_FILE.${NC}"
exit 1
fi
;;
stop)
echo "$(date '+%Y-%m-%d %H:%M:%S') Stopping Spark cluster...">>$LOG_FILE
$STOP_FILE >>$LOG_FILE 2>&1
echo "Spark stopped."
;;
*)
echo "Usage: $0 {start|stop}"
exit 1
;;
esac
exit 0
1.2 docker-compose.yml
在这里,我提到了如何使用我配置的镜像。如果想使用Spark,只需要把Hadoop服务中的image值改为hadoop3.3.6_ubuntu24.04:1.2即可。此外,前面几篇博客包括本篇中提到的Hadoop、HBase、Hive和Spark服务均已配置。还有就是关于网页UI的验证,由于我是在docker容器中配置并且网络是bridge模式,因此可以通过将容器的端口映射到本地来访问容器端的网页。
2. 安装Spark3.4.4
2.1 下载并解压Spark
命令:
cd ~
wget https://dlcdn.apache.org/spark/spark-3.4.4/spark-3.4.4-bin-without-hadoop.tgz
tar -zxvf spark-3.4.4-bin-without-hadoop.tgz -C .‘
mv spark-3.4.4-bin-without-hadoop spark-3.4.4
2.2 配置环境变量
用vim /etc/profile编辑环境变量,按i输入如下内容,然后按ESC输入:wq!保存,最后用source /etc/profile使环境变量生效。
export SPARK_HOME=/root/spark-3.4.4
export PATH=$PATH:$SPARK_HOME/bin
2.3 配置Spark
创建配置文件:
cd ~/spark-3.4.4/conf
cp spark-env.sh.template spark-env.sh
cp spark-defaults.conf.template spark-defaults.conf
cp workers.template workers
cp log4j2.properties.template log4j2.properties
2.3.1 workers
用vim workers编辑workers,将${MY_HOST}替换为echo $MY_HOST打印出来的值,然后按ESC输入:wq!保存。

2.3.2 spark-env.sh
用vim spark-env.sh编辑spark-env.sh,在文件末尾写入如下内容,然后按ESC输入:wq!保存。
export SCALA_HOME=/root/scala-2.13.16
export JAVA_HOME=/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/root/hadoop-3.3.6
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_DIST_CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath)
export SPARK_MASTER_HOST=172.18.0.2
export SPARK_PID_DIR=/root/spark-3.4.4/data/pid
export SPARK_LOCAL_DIRS=/root/spark-3.4.4/data/spark_shuffle
2.3.3 spark-defaults.conf
用vim spark-defaults.conf编辑spark-defaults.conf,在文件末尾写入如下内容,然后按ESC输入:wq!保存。
spark.master yarn
spark.submit.deployMode cluster
spark.eventLog.enabled true
spark.eventLog.dir hdfs://172.18.0.2:9000/user/spark
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 1g
用service hadoop start启动Hadoop,然后hadoop fs -mkdir /user/spark。
3. 验证Spark
配置上面1.1中的Spark服务,通过service spark start启动Spark,然后输入jps,验证Master和Worker是否启动。

输入spark-shell --deploy-mode client。
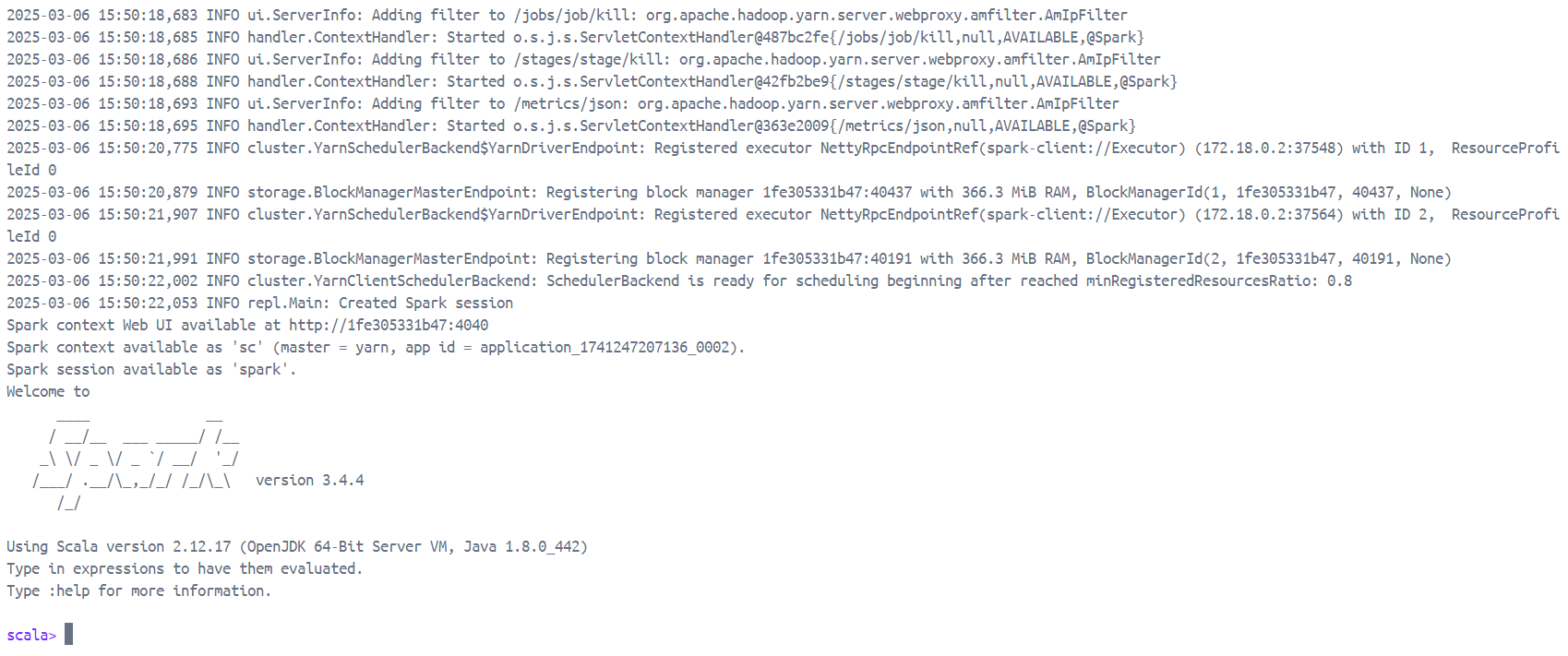
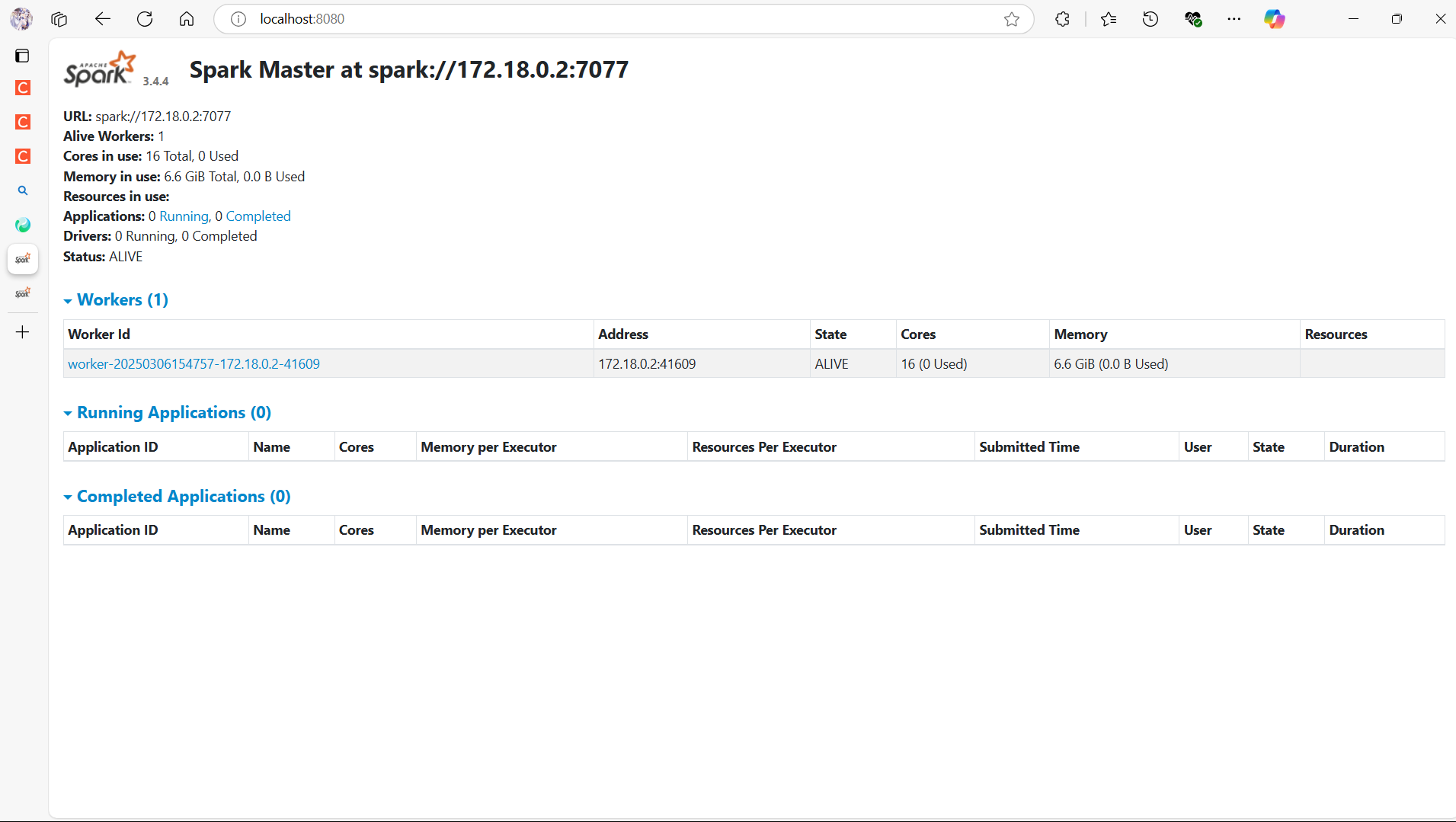
验证localhost:8080和http://localhost:8088/proxy/application_1741247207136_0004/jobs/能否打开,其中application_1741247207136_0004是spark-shell --deploy-mode client运行产生的Spark应用id(在该命令运行后终端的输出)。
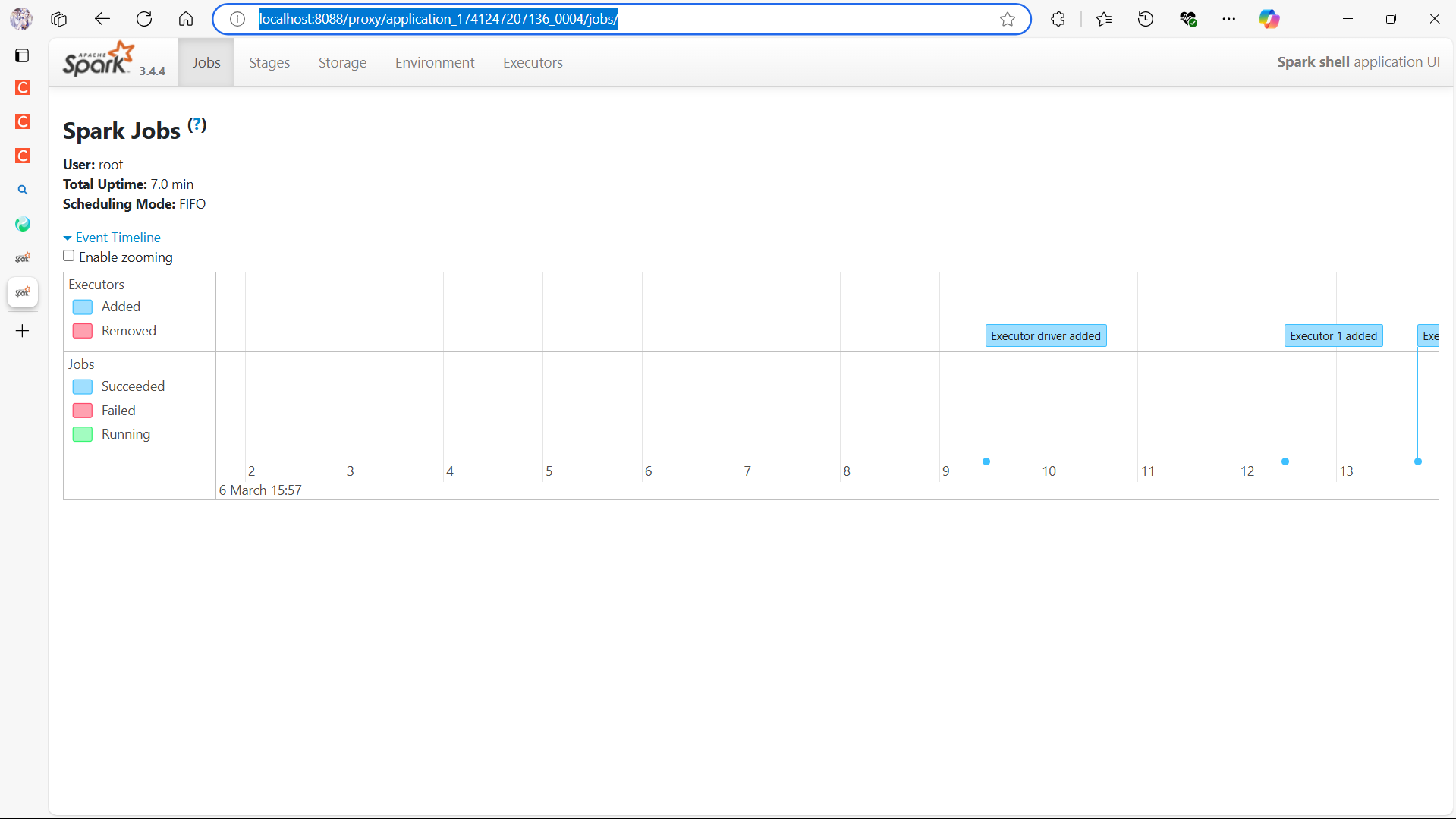
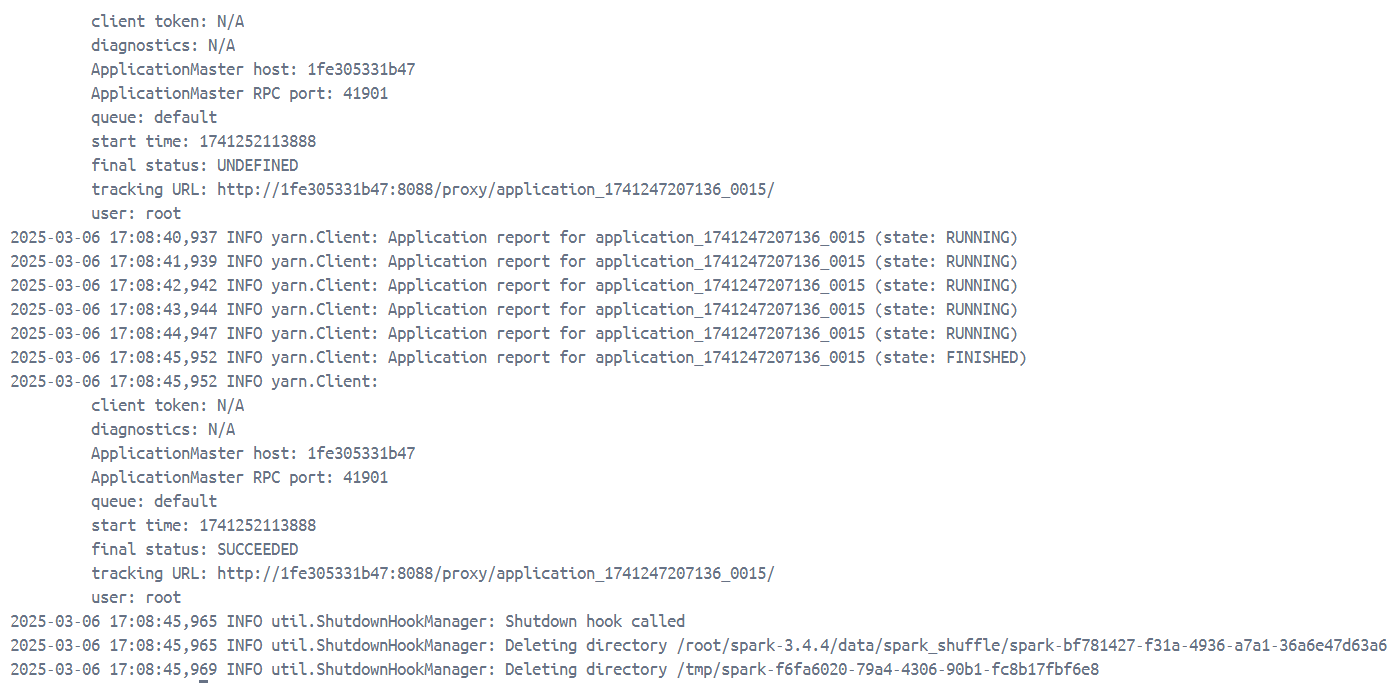
输入:quit退出Spark Shell。运行简单的Spark作业:run-example SparkPi。
参考
吴章勇 杨强著 大数据Hadoop3.X分布式处理实战

















 3637
3637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









