







摘录自《Elasticsearch 权威指南(中文版)》
地址:https://es.xiaoleilu.com/index.html
目的:方便以后使用es
先介绍下ES一些基础概念,后面才是spring整合
ES集群:
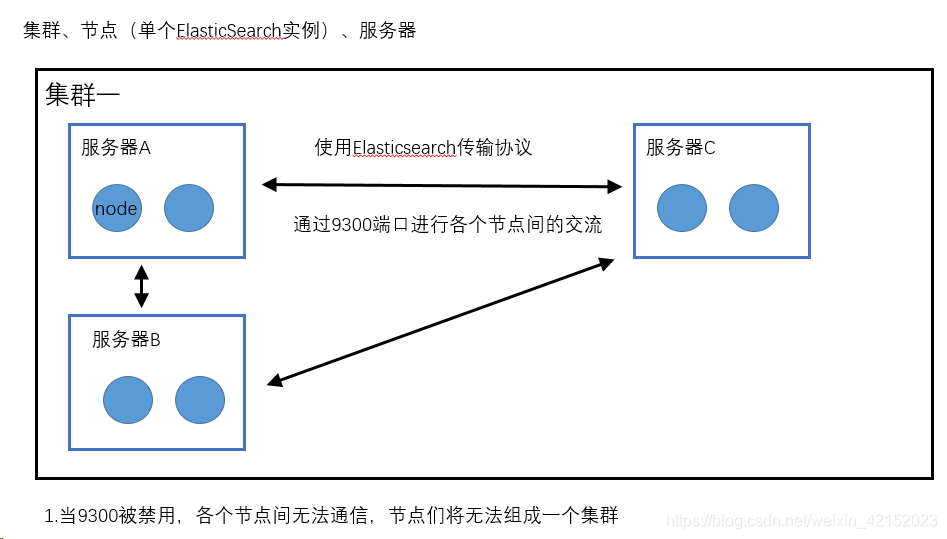
ES为Java内置了两套客户端(通过9300端口通信)
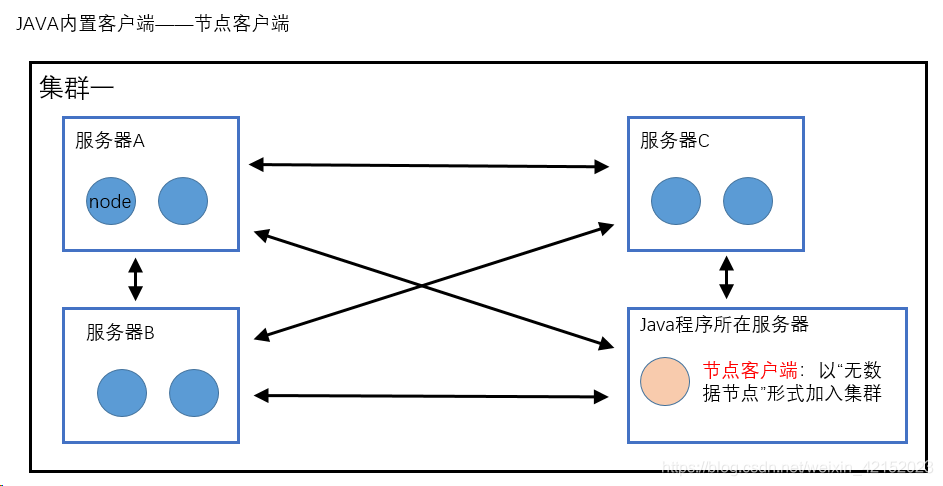
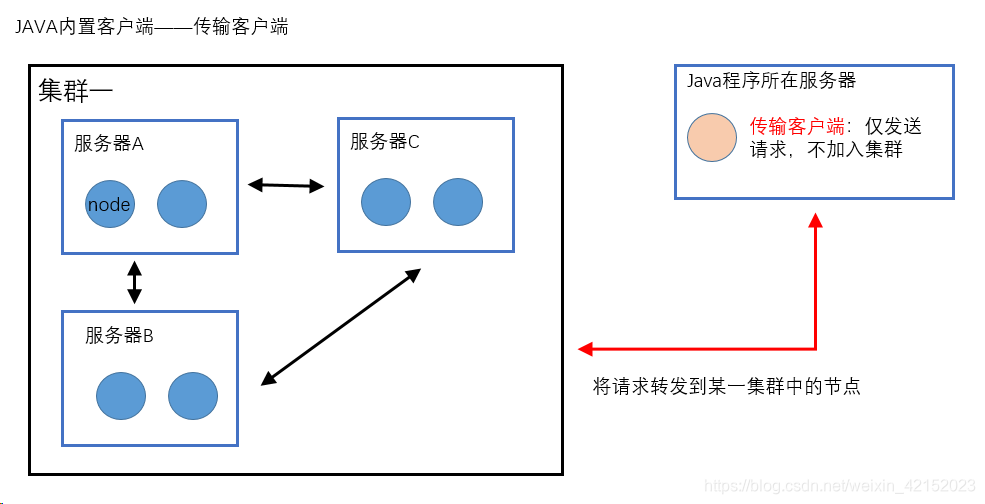
ps:其他语言使用9200端口与ES通信
基础使用
设置分片(在添加索引时)
PUT /blogs
{
"settings" : {
"number_of_shards" : 3, 主分片数量,一旦设置不可变更
"number_of_replicas" : 1 几份复制分片(1份即3主3副,2份即3主6副)
}
}
索引(index)仅是用来指向一个或多个分片的“逻辑命名空间(logical namespace)”
分片(shard)是最小的工作单元(worker unit),是实际存储数据的地方
动态设置复制分片
PUT /blogs/_settings
{
"number_of_replicas" : 2
}
启动多个节点
1.同一台服务器(测试的时候使用)
/config/elasticsearch.yml中添加node.max_local_storage_nodes: 3
然后多次启动即可,es会自动将新节点加入集群
ps:同一台机器启动多个节点,实际上,硬件资源并没有增加,且服务器挂了以后,所有的分片都在同一服务器,也失去了集群的意义
2.不同服务器
/config/elasticsearch.yml使用相同的集群名称,即“cluster.name”的值一致
???ip设置???
文档(Document)
- ES作为一个分布式文档搜索引擎,每个字段都默认被索引
- ES文档不可修改,只能覆盖
映射及分析
重要参数
1.type(除了String类型,其他的很少做映射)
2.index
| 值 | 解释 |
|---|---|
| analyzed | 首先分析这个字符串,然后索引。换言之,以全文形式索引此字段。 |
| not_analyzed | 索引这个字段,使之可以被搜索,但是索引内容和指定值一样。不分析此字段。 |
| no | 不索引这个字段。这个字段不能为搜索到。 |
结构化语句:
| 项目 | 结构化查询(Query DSL) | 结构化过滤(Filter DSL) |
|---|---|---|
| 目的 | 询问每个文档目标字段的值与目标值的匹配程度如何 | 检查是否包含特定值 |
| 适用范围 | 全文本搜索,相关性评分 | 剩下的所有 |
| 性能 | 因为需要计算相关性,耗时,且不可缓存 | 结果集是一个简单的文档列表,方便缓存 |
| 备注 | 查询语句会计算每个文档与查询语句的相关性,最后给出一个综合评分_score,并按相关性进行排序 | 不包含的直接过滤掉 |
结构化查询/_search,body需要传参query{…}
{
"query":{
"match_all":{
}  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 978
978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









