







解决问题
1)不规则采样
2)不同的测量步长
模型
概念
1、Time series,我们定义时间序列为一个集合 S i S_i Si,集合长度为M。即: S i : = { s 1 , . . . , s M } S_i:=\{s_1,...,s_M\} Si:={s1,...,sM}。
其中每一个观测点 s i s_i si定义为如下三元组 ( t j , z j , m j ) (t_j,z_j,m_j) (tj,zj,mj),三元组中 t j t_j tj代表时间; z j z_j zj为观测值; m j ∈ { 1... D } m_j \in \{1...D\} mj∈{1...D}为模态指示,D代表时间序列的维度(个人理解:类似于同一个时间点可以观测到多个信息,例如病人在5点的血压和脉搏,这是两个维度的值)。
完整的时间序列定义为 S i = { ( t 1 , z q , m 1 ) , . . . , ( t M , z M , m M ) } S_i=\{(t_1,z_q,m_1),...,(t_M,z_M,m_M)\} Si={(t1,zq,m1),...,(tM,zM,mM)}
2、数据集,数据集 D D D中包含n条Time series。 D : = { ( S 1 , y 1 ) , . . . , ( S N , y N ) } D:=\{(S_1,y_1),...,(S_N,y_N)\} D:={(S1,y1),...,(SN,yN)},其中 S i S_i Si表示第i条时间序列,而 y i ∈ { 1 , . . . , C } y_i \in \{1,...,C\} yi∈{1,...,C}是其标签。
3、Non-synchronized time series, ∣ { ( t k , z k , m k ) ∣ t k = t j } ∣ ≠ D |\{(t_k,z_k,m_k)|t_k=t_j\}| \neq D ∣{(tk,zk,mk)∣tk=tj}∣=D,某一个(或多个)时间点的某一个(或多个)维度的值不存在。
提出模型
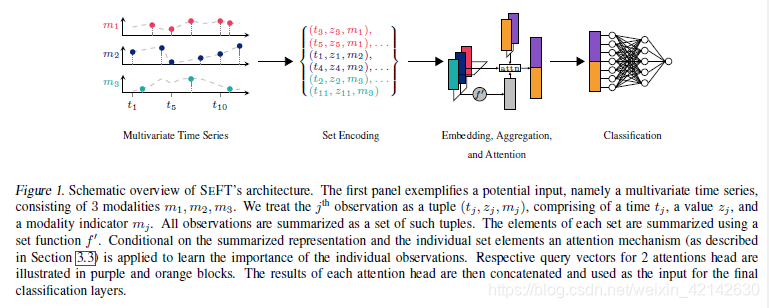
平均聚集函数为:
f ( S ) = g ( 1 ∣ S ∣ ∑ s j ∈ S h ( s j ) ) f(S)=g(\frac{1}{|S|}\sum_{s_j \in S}h(s_j)) f(S)=g(∣S∣1∑sj∈Sh(sj))
其中 h : Ω → R d h: \Omega \rightarrow R^d h:Ω→Rd, g : R d → R C g:R^d \rightarrow R^C g:Rd→RC是神经网络。该函数主要是得到一系列时间点(时间序列)的平均表征。
time encoding
时间编码通过将每个观测值的时间t传递给频率变化的多个三角函数,将一维时间轴转换为多维输入。
x 2 k ( t ) : = s i n ( t t 2 k / τ ) x_{2k}(t):=sin(\frac{t}{t^{2k/\tau }}) x2k(t):=sin(t2k/τt)
x 2 k + 1 ( t ) : = c o s ( t t 2 k / τ ) x_{2k+1}(t):=cos(\frac{t}{t^{2k/\tau }}) x2k+1(t):=cos(t2k/τt)
τ \tau τ表示高维的时间编码( τ ∈ N + \tau \in N^+ τ∈N+),编码位置为 x ∈ R τ x \in R^\tau x∈Rτ, k ∈ { 0 , . . . , τ / 2 } k \in \{0,...,\tau/2\} k∈{0,...,τ/2},t表示数据中预期的最大时间标度。
通过time encoding,所有观测值 s j s_j sj变为 s j = ( x ( t j ) , z j , m j ) s_j=(x(t_j),z_j,m_j) sj=(x(tj),zj,mj)
Attention-based Aggregation
通过Time encoding可以将任意大小的Time series编码为固定大小的表示形式。但是对于越来越大的集合大小,许多不相关的观察结果可能会影响平均聚集函数的结果。
(本部分类似于Transformer中的Attention机制,具体细节留个坑,日后来填)。
作者提出,他们的Attention机制与Transformer中的是有区别的。Transformer中使用来自所有集合元素的信息来计算单个集合元素的嵌入,从而导致运行时间和空间复杂度为 O ( n 2 ) O(n^2) O(n2)。 相比之下,我们的方法独立地计算集合元素的嵌入,从而降低了 O ( n ) O(n) O(n)的运行时和内存复杂性。
Online monitoring scenario
由于用于在当前时间点进行预测的一组观测值是在进行预测的时间点可用的全部观测值的子集。
个人理解:仅仅计算时间j之前的时间点的相互权重。
f
(
S
i
)
=
∑
j
≤
i
e
x
p
(
e
j
)
∑
k
≤
i
e
x
p
(
e
k
)
h
(
s
j
)
=
∑
j
≤
i
e
x
p
(
e
j
)
h
(
s
j
)
∑
k
≤
i
e
x
p
(
e
k
)
f(S_i)=\sum_{j\leq i} \frac{exp(e_j)}{\sum_{k \leq i}exp(e_k)}h(s_j) =\frac{\sum_{j\leq i}exp(e_j)h(s_j)}{\sum_{k \leq i}exp(e_k)}
f(Si)=j≤i∑∑k≤iexp(ek)exp(ej)h(sj)=∑k≤iexp(ek)∑j≤iexp(ej)h(sj)
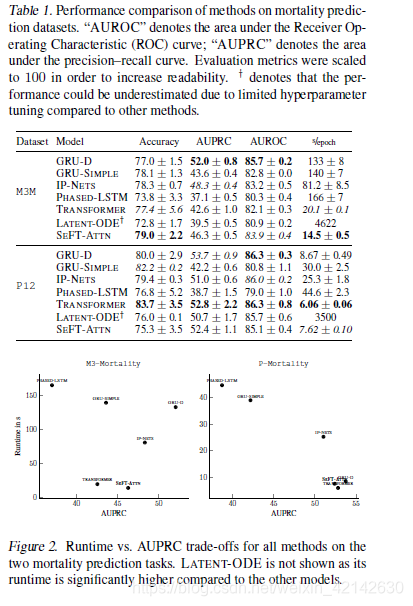
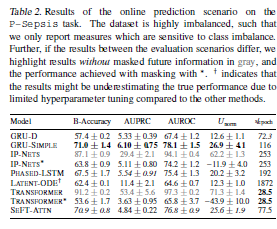
实验
任务
- 预测患者死亡率
- 预测患者败血症
数据集
- Physionet 2012 Mortality Prediction Challenge
- Physionet 2019 Sepsis Early Prediction Challenge
对比方法
- GRU-simple(2018)
- GRU-Decay(2018)
- Phased-LSTM(2016)
- Interpolation Prediction Networks(2019)
- Transformer(2017)
- Latent-ODE(2019)
实验结果

















 919
919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









