







 文章讲述了如何使用Navicat创建数据库和mock200万条酒店数据,然后结合Elasticsearch进行索引创建、删除、文档增删改查等操作。还提到了使用Java的RestHighLevelClient进行交互,并展示了批量导入数据的示例。最后提到目前是单线程实现,后续将优化为多线程处理。
文章讲述了如何使用Navicat创建数据库和mock200万条酒店数据,然后结合Elasticsearch进行索引创建、删除、文档增删改查等操作。还提到了使用Java的RestHighLevelClient进行交互,并展示了批量导入数据的示例。最后提到目前是单线程实现,后续将优化为多线程处理。
实现步骤:
一、先mock200万条数据,我这里使用的是navicat16,navicat16本身自带mock数据功能;
1.创建hotel数据库
CREATE database hotel;2.创建表格
DROP TABLE IF EXISTS `tb_hotel`;
CREATE TABLE `tb_hotel` (
`id` bigint NOT NULL COMMENT '酒店id',
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '酒店名称',
`address` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '酒店地址',
`price` int NOT NULL COMMENT '酒店价格',
`score` int NOT NULL COMMENT '酒店评分',
`brand` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '酒店品牌',
`city` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '所在城市',
`star_name` varchar(16) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '酒店星级,1星到5星,1钻到5钻',
`business` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '商圈',
`latitude` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '纬度',
`longitude` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '经度',
`pic` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '酒店图片',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = COMPACT;3.如图所示mock数据
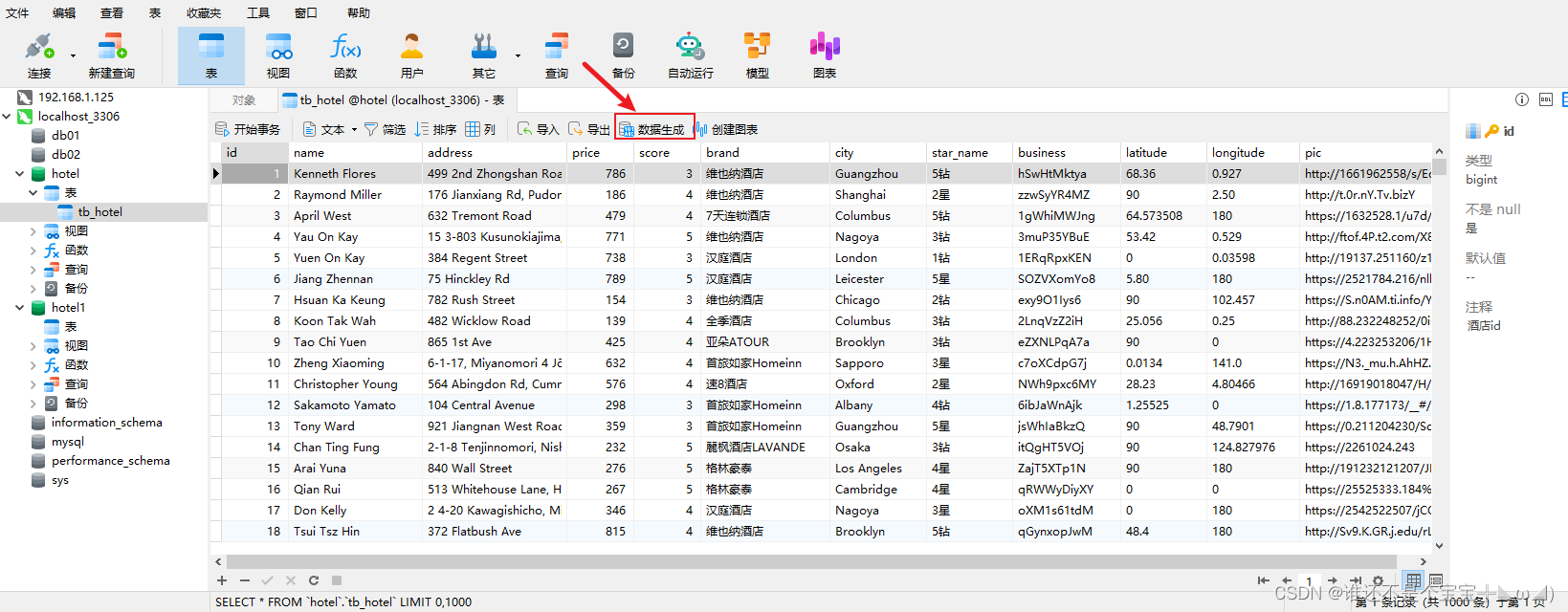
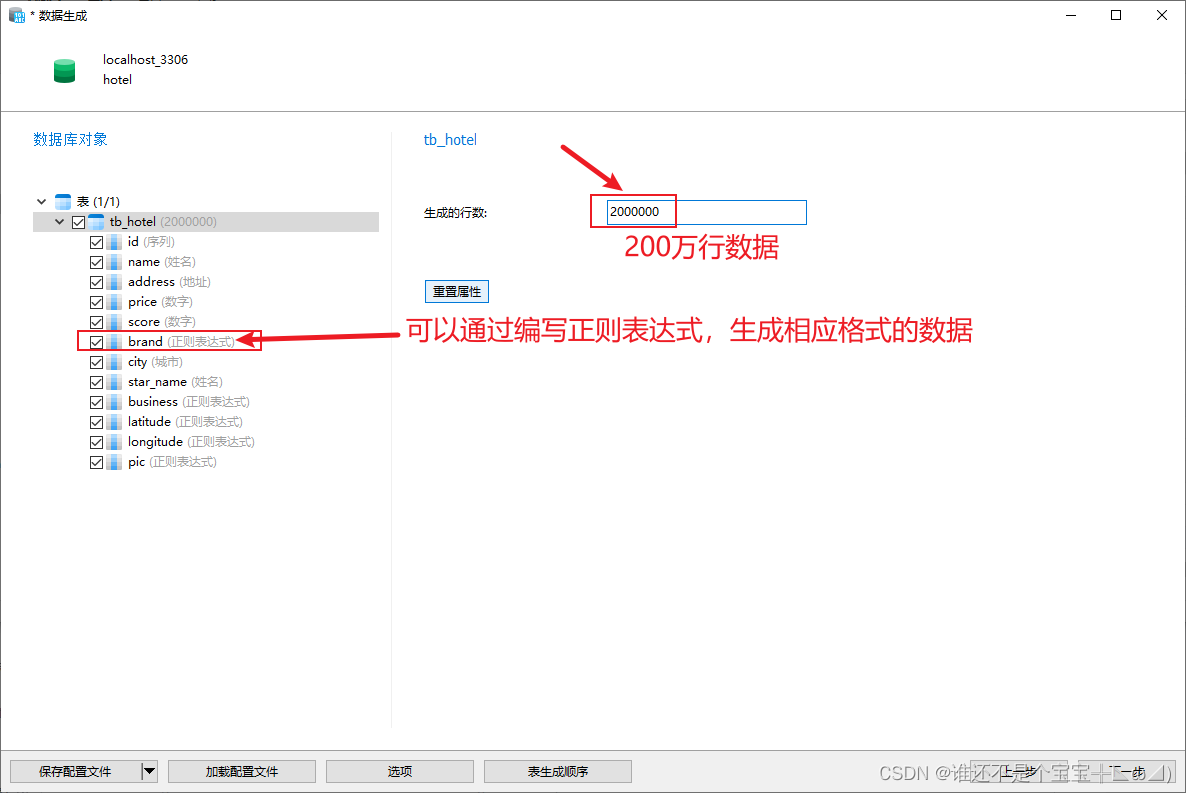
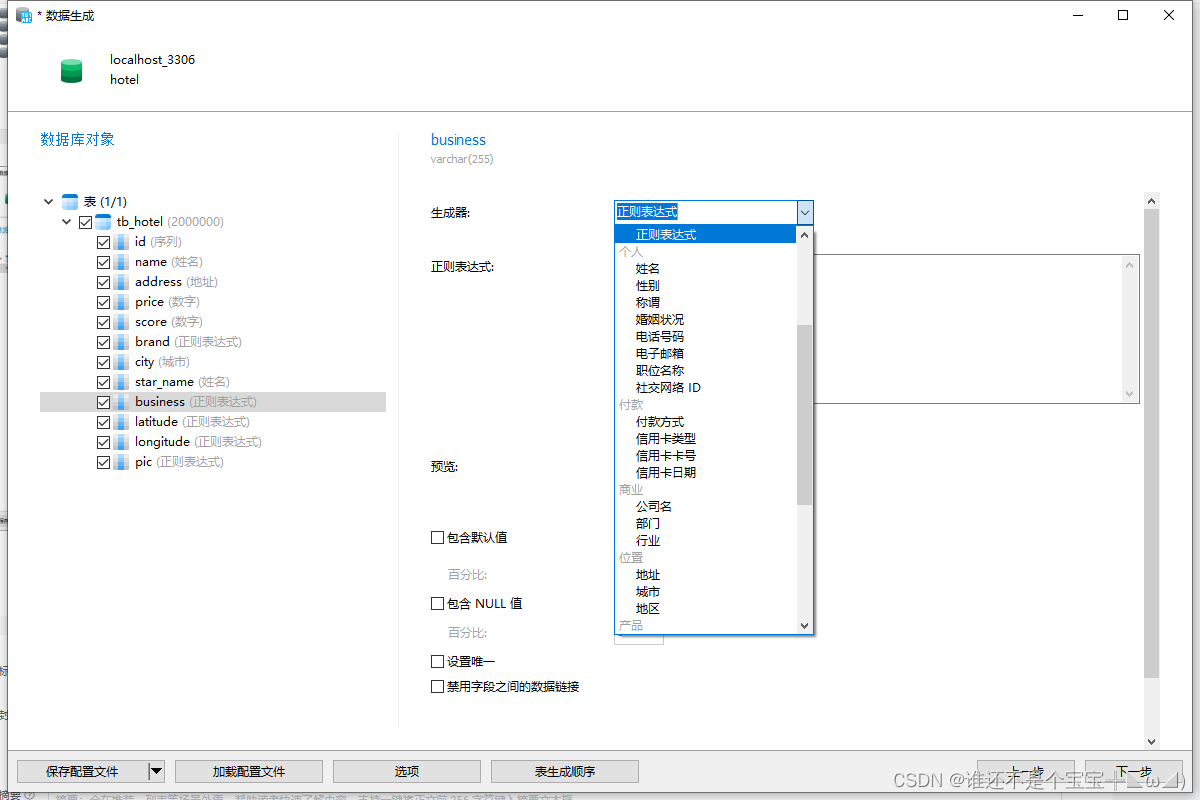
二、运行elasticsearch和kibana
三、编写java代码
@Slf4j
@SpringBootTest
public class HotelIndexTest {
private RestHighLevelClient client;
@Autowired
private HotelService hotelService;
@Autowired
private IHotelService iHotelService;
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://127.0.0.1:9200")
));
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
@Test
void contextLoads() {
System.out.println(this.client);
}
/**
* 创建
*/
@Test
void createHotelIndex() throws IOException {
// 1.创建Request对象
CreateIndexRequest request = new CreateIndexRequest("hotel");
// 2.准备请求的参数:DSL语句
request.source(HotelConstants.MAPPING_TEMPLATE, XContentType.JSON);
// 3.发送请求
CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT);
// 4.打印结果
System.out.println(response.isAcknowledged());
}
/**
* 删除
*/
@Test
void testDeleteHotelIndex() throws IOException {
// 1.创建Request对象
DeleteIndexRequest request = new DeleteIndexRequest("hotel");
// 2.发送请求
AcknowledgedResponse response = client.indices().delete(request, RequestOptions.DEFAULT);
//3.打印结果
System.out.println(response.isAcknowledged());
}
/**
* 新增文档
*/
@Test
public void testAddDoc() throws IOException {
// 1.根据id查询酒店数据
Hotel hotel = hotelService.getById("1");
//2、准备Request对象
IndexRequest request = new IndexRequest("hotel").id(hotel.getId().toString());
//3、准备json文档
request.source(JSONObject.toJSONString(hotel), XContentType.JSON);
//4、发送请求
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
}
/**
* 删除文档
*/
@Test
public void testDeleteDoc() throws IOException {
//1、准备Request对象
DeleteRequest request = new DeleteRequest("hotel", "1");
//2、发送请求
client.delete(request, RequestOptions.DEFAULT);
}
/**
* 查询文档
*/
@Test
void testGetDocById() throws IOException {
// 1.准备Request
GetRequest request = new GetRequest("hotel", "1");
// 2.发送请求,得到响应
GetResponse response = client.get(request, RequestOptions.DEFAULT);
// 3.解析响应结果
String json = response.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println(hotelDoc);
}
/**
* 修改文档
*/
@Test
void testUpdateDoc() throws IOException {
// 1.准备Request
UpdateRequest request = new UpdateRequest("hotel", "36934");
// 2.准备请求参数
request.doc(
"price", "952",
"starName", "四钻"
);
// 3.发送请求
client.update(request, RequestOptions.DEFAULT);
}
/**
* 批量导入
*/
@Test
void testBulkDoc() throws IOException {
log.info("==================数据导入开始=================");
long start = System.currentTimeMillis();
for (int i = 1;; i++) {
long first = System.currentTimeMillis();
BulkRequest request = new BulkRequest();
IPage<Hotel> page = new Page<>(i, 10000);
iHotelService.page(page);
List<Hotel> list = page.getRecords();
if (list.isEmpty()) {
long end = System.currentTimeMillis();
long l = end - start;
log.info("==================数据导入结束=================");
log.error("导入200万条数据耗时(ms)"+l);
break;
}
list.stream().forEach(item -> {
HotelDoc hotelDoc = new HotelDoc(item);
request.add(new IndexRequest("hotel").id(item.getId().toString()).source(JSONObject.toJSONString(hotelDoc), XContentType.JSON));
});
client.bulk(request, RequestOptions.DEFAULT);
long second = System.currentTimeMillis();
long everycount = second - first;
log.error("导入第"+i+"次万条数据耗时(ms)"+everycount);
}
}
}批量删除这里使用了分页查询,需要编写配置类。
@Configuration
public class PageConfig {
/**
* 新的分页插件,一缓和二缓遵循mybatis的规则,需要设置 MybatisConfiguration#useDeprecatedExecutor = false 避免缓存出现问题(该属性会在旧插件移除后一同移除)
*/
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.H2));
return interceptor;
}
@Bean
public ConfigurationCustomizer configurationCustomizer() {
return configuration -> configuration.setUseDeprecatedExecutor(false);
}
}类似的方法还有很多,可以试着尝试一下:MyBatis Plus 解决大数据量查询慢问题
三、现阶段这里只是实现了单线程的数据转移,多线程代码正在写,等我写好了就传上来!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









