






背景与原理
Self-Attention 公式如下
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k} } )V
Attention(Q,K,V)=softmax(dkQKT)V
其中:
Q - Query, 查询张量,Shape是[Batch, Seq_len, Head_num, Hide_dim]
K - Key, 索引张量,Shape是[Batch, Seq_len_kv, Head_num, Hide_dim]
V - Value, 内存张量,Shape是[Batch, Seq_len_kv, Head_num, Hide_dim]
d
k
d_k
dk - 特征维度,主要是为了控制矩阵点乘后的范围,以确保softmax的梯度稳定性,经常取值等于Hide_dim
传统的Self-Attention有三种注意力机制:
- MHA (Multi-head Attention)
MHA(Multi-head Attention)是Google团队在 2017 年在Attention Is All You Need提出的一种NLP经典模型,首次提出并使用了 Self-Attention 机制,也就是 Multi Head Attention,是标准的多头注意力机制,有H个Query、Key 和 Value 矩阵。 - MQA (Multi-Query Attention)
MQA也是Google团队在2019年,在Fast Transformer Decoding: One Write-Head is All You Need提出的,是MHA的一种变体,也是用于自回归解码的一种注意力机制。与MHA不同的是,MQA 让所有的头之间共享同一份 Key 和 Value 矩阵,每个头只单独保留了一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量,以此来达到提升推理速度,但是会带来精度上的损失。 - GQA (Group-Query Attention)
GQA(分组查询注意力)同样,也是Google在2023年,于[GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints]( GQA(分组查询注意力)同样,也是Google在2023年,于GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints提出的一种MHA变体,GQA将查询头分成G组,对于Query是每个头单独保留一份参数,每个组共享一个Key 和 Value 矩阵。GQA-G是指具有G组的grouped-query attention。)提出的一种MHA变体,GQA将查询头分成G组,对于Query是每个头单独保留一份参数,每个组共享一个Key 和 Value 矩阵。GQA-G是指具有G组的grouped-query attention。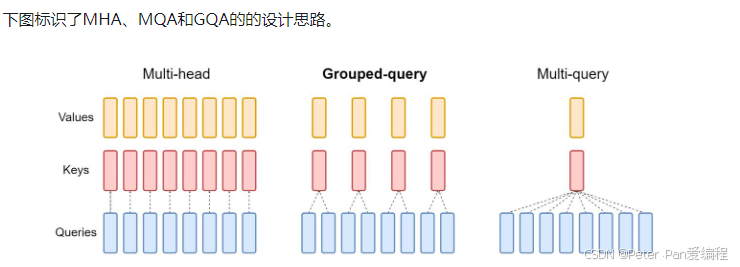
2. Flash Attention公式推导
论文《FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness》
FlashAttention是一种加速注意力计算方法,目前已经应用在:GPT-3、Falcon2(阿联酋大模型)、Llama2、Megatron-LM、GPT-4等知名LLM上。Flash Attention已经集成到了pytorch2.0中,可以很便捷的调用。
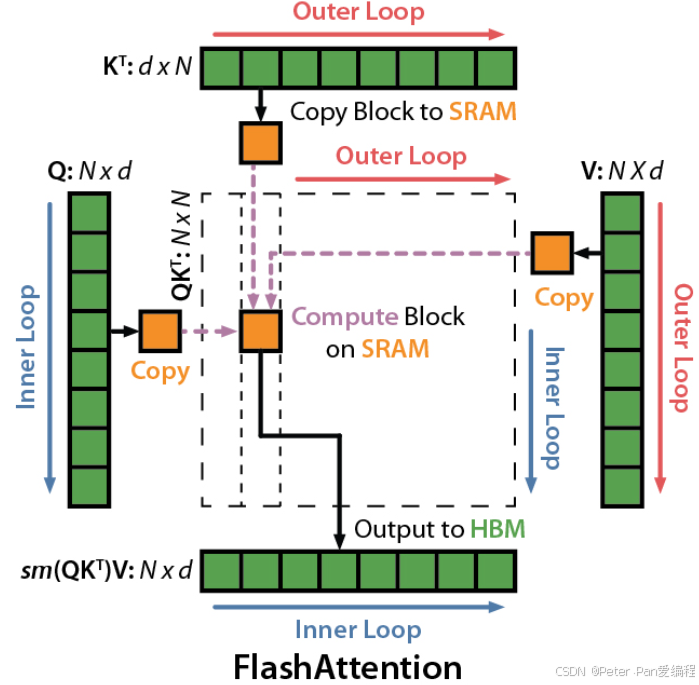
FlashAttention旨在加速注意力计算并减少内存占用。FlashAttention利用底层硬件的内存层次知识,例如GPU的内存层次结构,来提高计算速度和减少内存访问开销。 FlashAttention的核心原理是通过将输入分块并在每个块上执行注意力操作,从而减少对高带宽内存(HBM)的读写操作。具体而言,FlashAttention使用平铺和重计算等经典技术,将输入块从HBM加载到SRAM(快速缓存),在SRAM上执行注意力操作,并将结果更新回HBM。FlashAttention减少了内存读写量,从而实现了2-4倍的时钟时间加速。
原论文中的公式:

下面我们用大白话来重新推导一遍去前向(反向也是一样的方式,不再重复赘叙)
- 首先是对 Q , K , V , l , m Q,K, V,l,m Q,K,V,l,m进行分块
- 在外循环中变量K, V每一块,在内循环中变量Q
- 将分块后的Q, K,V的小块加载的SRAM中
- 计算每一个小块Q, K的矩阵乘 S i j = Q i K j T S_{ij} = Q_i K_j^T Sij=QiKjT
- 计算 M A S K ( S i j ) MASK(S_{ij}) MASK(Sij)
- 使用online softmax进行softmax的计算,减少数据搬移到HBM的成本
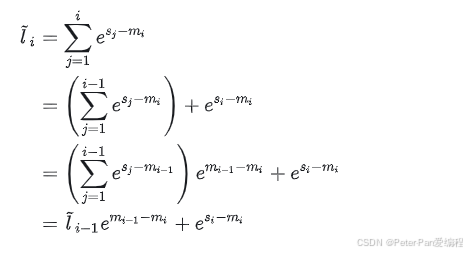
于是 softmax 的计算可以优化成:(这个就 Online Softmax)

- 计算
Q
i
=
(
Q
i
+
P
i
j
~
∗
V
j
)
∗
(
e
(
m
i
j
~
−
m
i
n
e
w
)
)
Q_i = (Q_i + \widetilde{P_{ij}}*V_j)* (e^(\widetilde{m_{ij}} - m_i^{new}))
Qi=(Qi+Pij
∗Vj)∗(e(mij
−minew)),并将结果写回HBM
计算示意图如下:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









