







 本文详细介绍了HBase的存储原理,包括读写流程、数据刷写过程(flush)、数据compaction合并以及region的拆分策略。在读写过程中,HBase通过Memstore和HLog保证数据一致性,flush和compaction则是为了管理和优化磁盘文件。region拆分是HBase扩展性的重要保证,有多种触发策略。整个流程涉及元数据管理、内存与磁盘的交互,以及事务性保证。
本文详细介绍了HBase的存储原理,包括读写流程、数据刷写过程(flush)、数据compaction合并以及region的拆分策略。在读写过程中,HBase通过Memstore和HLog保证数据一致性,flush和compaction则是为了管理和优化磁盘文件。region拆分是HBase扩展性的重要保证,有多种触发策略。整个流程涉及元数据管理、内存与磁盘的交互,以及事务性保证。
HBase存储原理(架构)
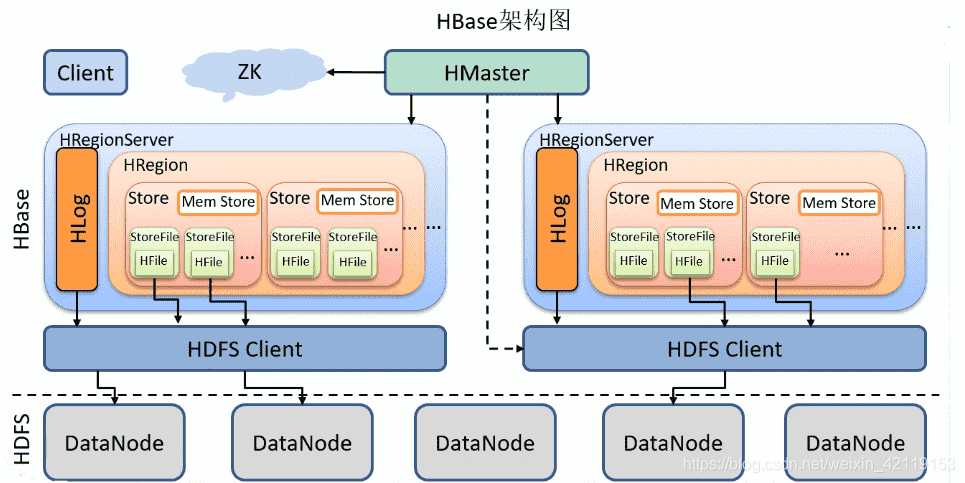
HBase依赖于Zookeeper和Hadoop的,所以在启动HBase前需要启动Zookeeper和Hadoop。
HMaster用于管理整个HBase集群,即管理每个HRegionServer,它掌握着整个集群的元数据信息,同时会将相应的数据存储到Zookeeper(元数据信息、高可用信息等)。
HMaster的职责:
1)管理用户对Table的增、删、改、查操作;
2)记录region在哪台 Hregion server上;
3)在Region Split 后,负责新Region的分配;
4)新机器加入时,管理 HRegion Server的负载均衡,调整Region分布;
5)在 HRegion Server 宕机后,负责失效 HRegion Server 上的Regions 迁移。
HRegionServer是每台机器上的一个Java进程(一台机器只有一个HRegionServer进程),用来处理客户端的读写请求(和Hadoop的DataNode类似),并维护着元数据信息。
HRegionServer的职责:
1) HRegion Server 主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是 HBASE中最核心的模块。
2) HRegion Server 管理了很多 table 的分区,也就是region。
每个HRegionServer有一个HLog(有且仅有一个)。HLog是操作日志,用来做灾难恢复的,当客户端发起一个写请求时,会先往HLog中写再往Memory Store中写。假设没有HLog,我们进行一个写请求,会首先写到Memory Store上,等到Memory Store到达一定容量后,才会flush到StoreFile中。但是如果在这之前主机断电了呢?那这部分操作的数据全丢失了。这显然不是我们想到的结果,于是就有了HLog。
每个HRegionServer里面有多个HRegion,一个HRegion对应于HBase的一张表(也可能是表的一部分,因为表太大了会切分,表和HRegion的对应关系是一对多),当这张表到一定大小的时候会进行切分,切分成两个HRegion,切分出来的新的HRegion会保存到另一台机器上。每个HRegionServer里面有多个HRegion,可以理解为有多张表。
每个HRegion里面有多个Store(一张表中有多个列族),一个Store对应于HBase一张表的一个列族,。按照这个原理,我们在设计列族的时候,可以把经常查询的列放在同一个列族,这样可以提高效率,因为同一个列族在同一个文件里面(不考虑切分)。
每个Store有一个内存级别的存储Memory Store(有且仅有一个)。当Memory Store达到一定大小或一定时间后会进行数据刷写(flush),写到磁盘中(即HFile)。
每个Store有多个磁盘级别的存储StoreFile,Memory Store每刷写一次就形成一个StoreFile,HFile是StoreFile在HDFS上的存储格式。
HBase读原理
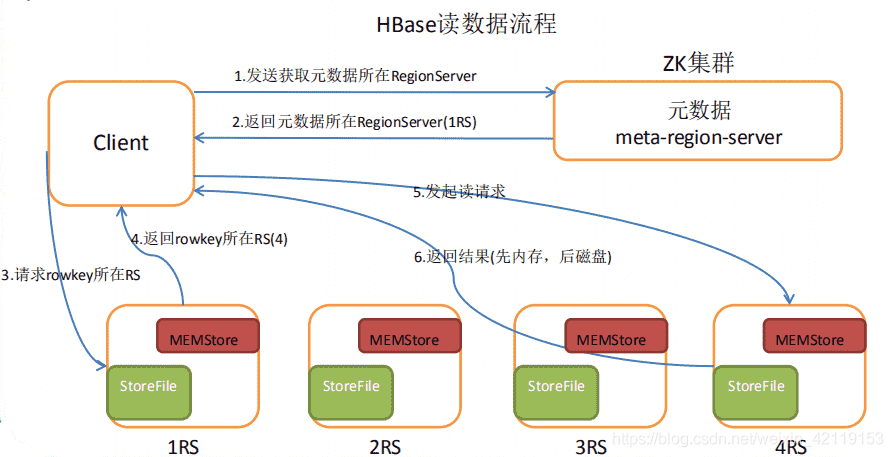
在上图中,我们模拟一下客户端读取数据过程,假设Zookeeper存放的meta表在RS1机器上,meta表存放的内容如下,Student表行键范围在1-100的存放在RS4上,在101~200的存放在RS3上,等等。
meta表:
_________________________________________________
| 表名 | rowkey范围 | 所在位置 |
|____________|________________|_________________|
| Student | 1 ~ 100 | RS4 |
|____________|________________|_________________|
| Student | 101 ~ 200 | RS3 |
|____________|________________|_________________|
| Teacher | 1 ~ 500 | RS1 |
|____________|________________|_________________|
| ···  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 533
533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









