







 博客介绍了初学Python爬虫图片的方法,以懒人图库为例,实现一个简单的爬虫。通过发送请求获取界面,再用正则表达式解析界面,还附上了全部代码和效果图,无需手动查找模块。
博客介绍了初学Python爬虫图片的方法,以懒人图库为例,实现一个简单的爬虫。通过发送请求获取界面,再用正则表达式解析界面,还附上了全部代码和效果图,无需手动查找模块。
初学python爬虫图片,先实现一个简单的(不用自己去一步一步的看在哪个模块,直接使用正则表达式查询所有的图片格式)
以懒人图库为例
(1)发送请求,得到界面
#打开网页,下载器
def open_html ( url):
#发送请求
req=urllib.request.Request(url)
#得到响应
reponse=urllib.request.urlopen(req)
#得到HTML
html=reponse.read()
return html
(2)正则表达式解析界面
#下载图片
def load_image(html):
#正则表达式——寻找jpg
regx='http://[\S]*jpg'
#生成一个pattern
pattern=re.compile(regx)
#得到所有图片
get_image=re.findall(pattern,repr(html))
num=1
for img in get_image:
photo=open_html(img)
with open(r'D:\Python\Spider\picture\%s.jpg'%num,'wb') as f:
print('开始下载图片')
f.write(photo)
print('正在下载第%s张图片'%num)
f.close()
num=num+1
if num>1:
print('下载成功!!!')
else:
print('下载失败!!!')
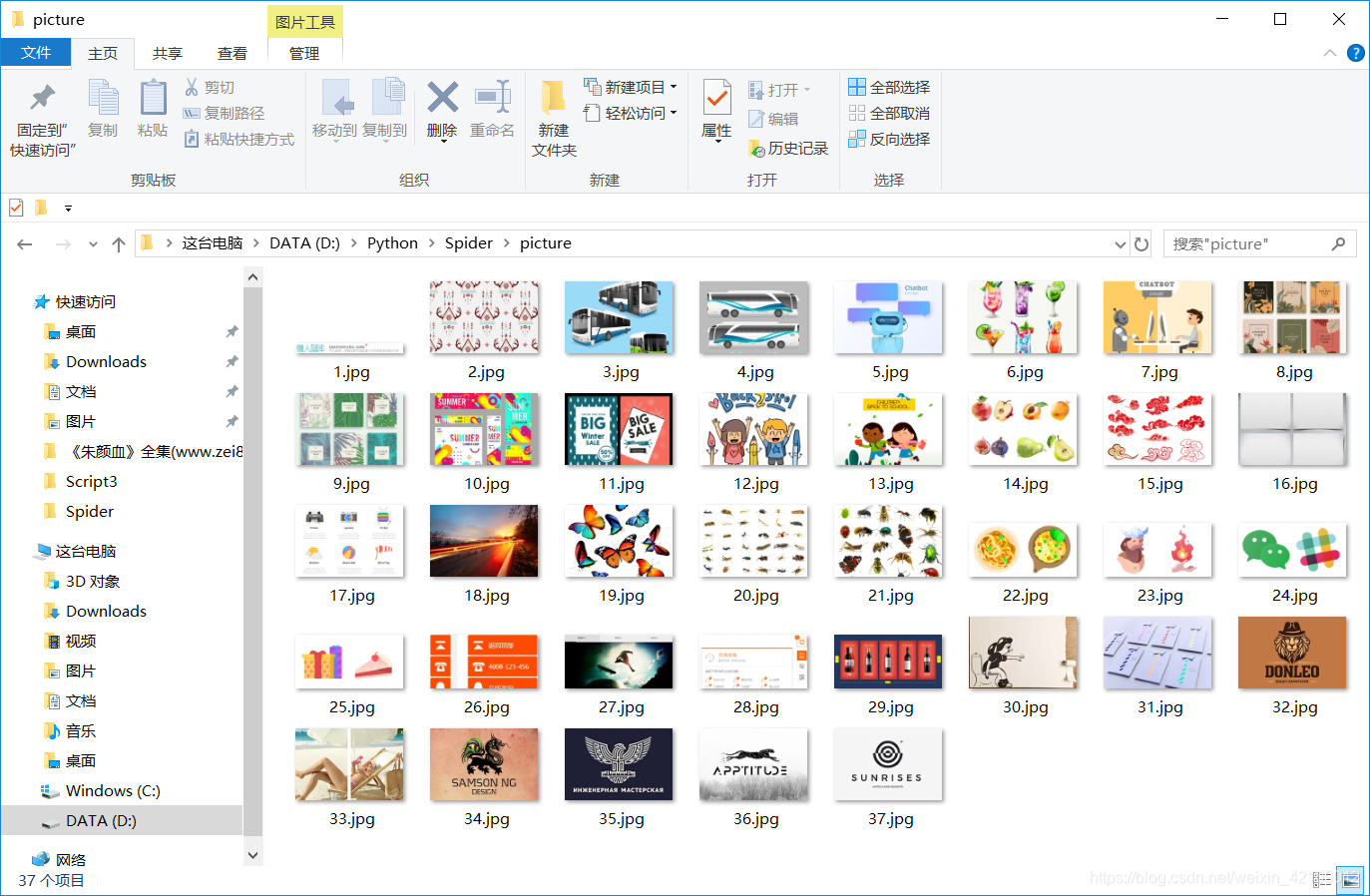
以下附上全部代码和效果图
# -*- coding: cp936 -*-
#导入库函数
import urllib
import urllib.request
import re
#打开网页,下载器
def open_html ( url):
#发送请求
req=urllib.request.Request(url)
#得到响应
reponse=urllib.request.urlopen(req)
#得到HTML
html=reponse.read()
return html
#下载图片
def load_image(html):
#正则表达式——寻找jpg
regx='http://[\S]*jpg'
#生成一个pattern
pattern=re.compile(regx)
#得到所有图片
get_image=re.findall(pattern,repr(html))
num=1
for img in get_image:
photo=open_html(img)
with open(r'D:\Python\Spider\picture\%s.jpg'%num,'wb') as f:
print('开始下载图片')
f.write(photo)
print('正在下载第%s张图片'%num)
f.close()
num=num+1
if num>1:
print('下载成功!!!')
else:
print('下载失败!!!')
#定义url
url='http://www.lanrentuku.com/'
html=open_html(url)
load_image(html)

















 429
429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









