







Storm
分布式计算引擎。Jstorm是一个类似于Hadoop MapReduce的系统,用户按照指定的接口实现一个任务,然后这个任务交给JStorm系统,JStorm将这个任务跑起来,并按7 * 24小时运行。如果中间一个worker发生了意外故障,调度器立即分配一个新的worker来替换这个失效的worker。
特性:
- 异常健壮:集群易管理,可轮流重启节点
- 容错性好:消息处理过程出现异常,会进行重试
- 语言无关性:topology可以用多种语言编写
架构类型:- 主从架构:简单,高效,但主节点存在单点问题
- 对称架构:复杂,效率较低,但无单点问题,更加可靠
概念
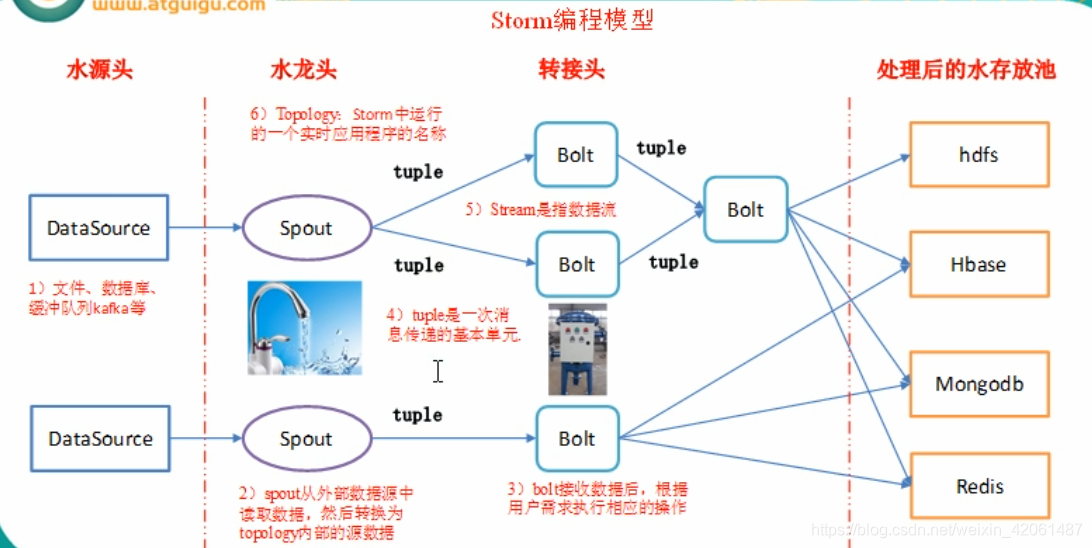
Apache storm从一端读取实时数据的原始流,并将其传递通过一系列小处理单元,并在另一端输出处理/有用的信息。
| 组件 | 描述 |
|---|---|
| Tuple | Tuple是Storm中的主要数据结构。它是有序元素的列表。默认情况下,Tuple支持所有数据类型。通常,它被建模为一组逗号分隔的值,并传递到Storm集群。 |
| Stream | 流是元组的无序序列。 |
| Spouts | 流的源。通常,Storm从原始数据源(如Twitter Streaming API,Apache Kafka队列,Kestrel队列等)接受输入数据。否则,您可以编写spouts以从数据源读取数据。“ISpout”是实现spouts的核心接口,一些特定的接口是IRichSpout,BaseRichSpout,KafkaSpout等。 |
| Bolts | Bolts是逻辑处理单元。Spouts将数据传递到Bolts和Bolts过程,并产生新的输出流。Bolts可以执行过滤,聚合,加入,与数据源和数据库交互的操作。Bolts接收数据并发射到一个或多个Bolts。 “IBolt”是实现Bolts的核心接口。一些常见的接口是IRichBolt,IBasicBolt等。 |
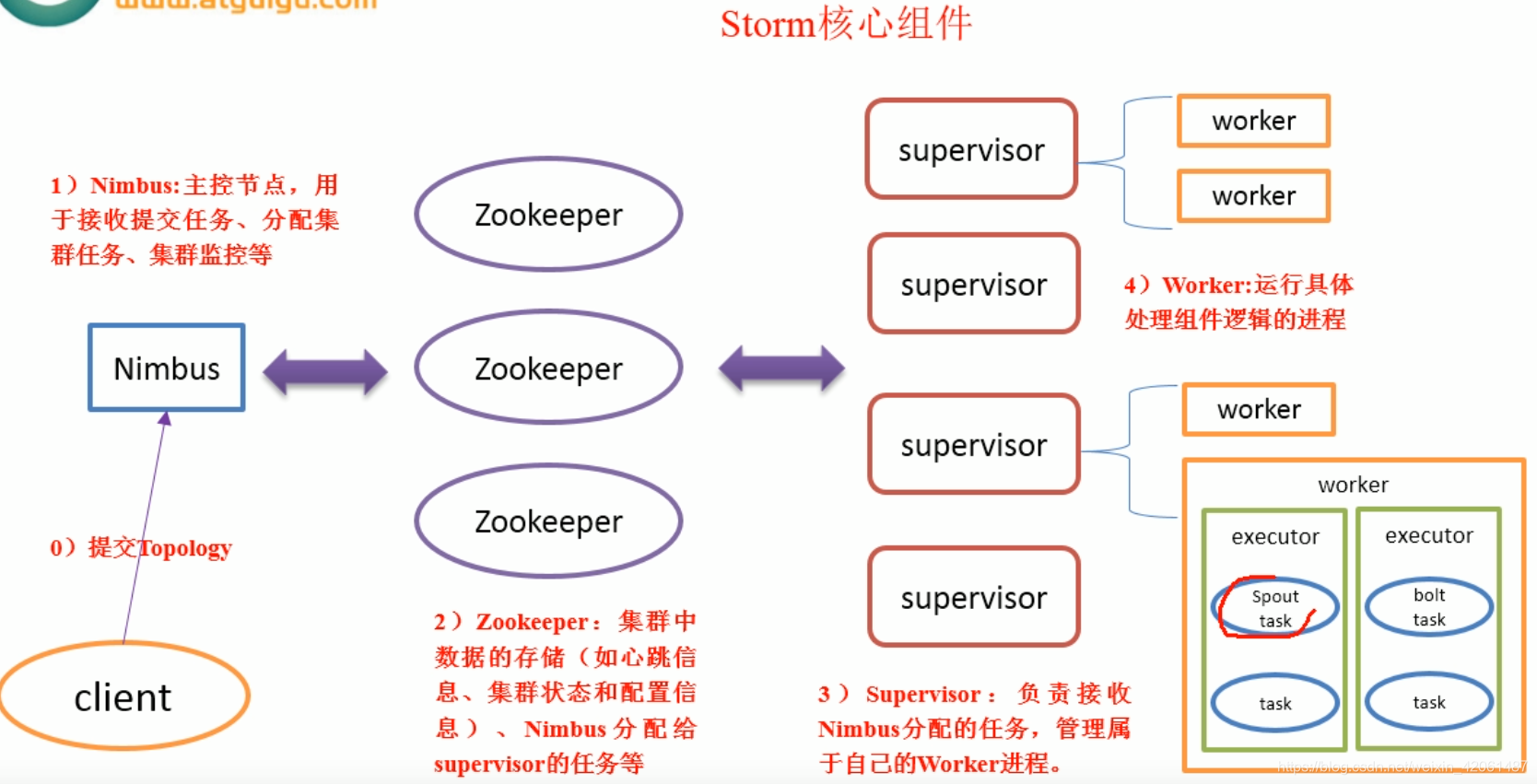
Storm组件:Nimbus
- 接受客户端topo代码,拆分成多个task,将task信息存入zk
- 将task分配给Supervisor,将映射关系存入zk
- 故障检测
Storm组件:Supervisor
- 从Nimbus目录读取代码,从zk上读取Nimbus分配的task
- 启动工作进程Worker执行任务
- 检测运行的工作进程Worker
Storm组件: Worker
- 从zk上读取分配的task,并计算出task需要给哪些task发消息
- 启动一个或多个Executor线程执行任务Task
Storm组件:Zookeeper
- Numbus于Supervisor进行通信(分配任务和心跳)
- Supervisor与Worker进行通信(分配任务和心跳)
- Nimbus高可用(HA机制)
Strom作业提交流程
- 用户编写Strom Topolgy
- 使用Client提交Topology给Nimbus
- Nimbus指派Task给Supervisor
- Supervisor为Task启动Worker
- Worker执行Task
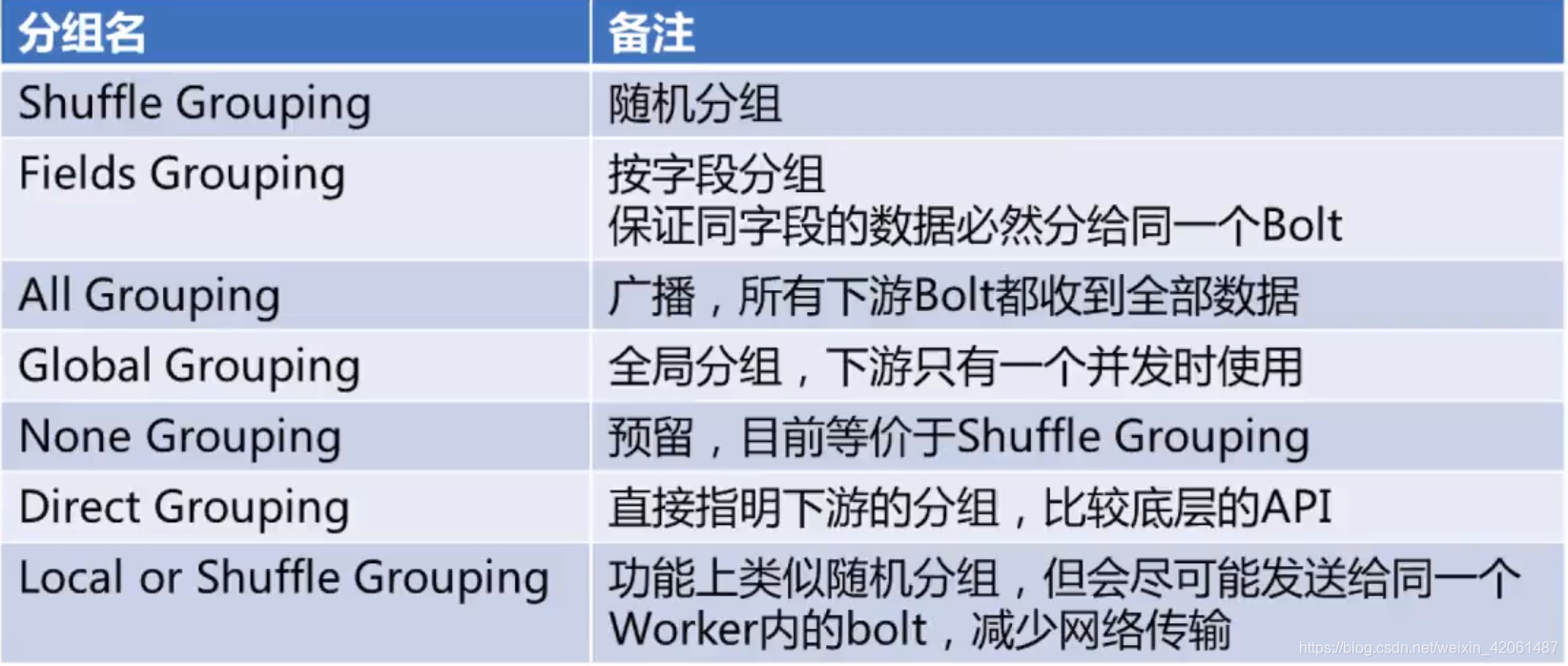
Grouping方式
Storm如何保证数据有效性
- Nimubs故障,换台机器重启即可
- Supervisor挂掉,迁移其上的Worker即可
- Worker挂掉,迁移走数据能正确处理吗?
如何保证worker数据正确的恢复?不会被重复计算?
Spout数据保障
- 不丢:Acker机制保证数据如果未处理成功,可以即使发现,并通知Spout重发
- 不重:使用msgID去重
API参数介绍
Spout创建
Spout是用于数据生产的组件。基本上,一个spout将实现一个IRichSpout接口。“IRichSpout”接口有以下重要方法
- open 为Spout提供执行环境。执行器将运行此方法来初始化喷头
- nextTuple 通过收集器发出生成的数据
- close 当spout要关闭时调用此方法
- declareOutFields 声明元组的输出模式
- activate 当Spout已经失效时被调用。该Spout的nextTuple方法很快就会被调用
- ack 确认处理了特定元组
- fail 指定不处理和不重新处理特定元组
open
open(Map conf, TopologyContext context, SpoutOutputCollector collector)
- conf - 为此spout提供storm配置
- context - 提供有关拓扑中的spout位置,其任务ID,输入和输出信息的完整信息
- collector - 使我们能够发出将由bolts处理的元组
nextTuple
nextTuple()
nextTuple()从与ack()和fail()方法相同的循环中定期调用。它必须释放线程的控制,当没有工作要做,以便其他方法有机会被调用。因此,nextTuple的第一行检查处理是否已完成。如果是这样,它应该休眠至少一毫秒,以减少处理器在返回之前的负载。
close
close()
关闭资源的方法
declareOutFields
declareOutputFields(OutputFieldsDeclarer declarer)
declarer - 用于声明输出流id,输出字段等
此方法用于指定元组的输出模式
ack
ack(Object msgId)
该方法确认已经处理了特定元组。
nextTuple
nextTuple()
此方法通知特定元组尚未完全处理,Storm将重新处理特定的元组
Bolt创建
Bolt是一个使用元组作为输入,处理元组,并产生新的元组作为输出的组件。Bolts将实现IRichBolt接口。在此程序中,使用两个Bolts类CallLogCreatorBolt和CallLogCounterBolt来执行操作
IRichBolt接口有以下方法
- prepare - 为bolt提供要执行的环境。执行器将运行此方法来初始化spout
- excute - 处理单个元组的输入
- cleanup - 当spout要关闭时调用
- declareOutputFields - 声明元组的输出模式
prepare
prepare(Map conf, TopologyContext context, OutputCollector collector)
- conf - 为此bolt提供Storm配置
- context - 提供有关拓扑中的bolt位置,其任务ID,输入和输出信息等的完整信息
- collector - 使我们能够发出处理的元组
execute
execute(Tuple tuple)
这里的元组是要处理的输入元组
execute方法一次处理单个元组。元组数据可以通过Tuple类的getValue方法访问。不必立即处理输入元组。多元组可以被处理和输出为单个输出元组。处理的元组可以通过使用OutputCollector类发出。
cleanup
cleanup()
declareOutputFields
declareOutputFields(OutputFieldsDeclarer declarer)
这里的参数declarer用于声明输出流id,输出字段等
此方法用于指定元组的输出模式
分组策略
-
Shuffle Grouping 随机分组:轮询,平均分配
-
Fields Grouping 按字段分组:比如按照userid分组,具有相同的userid的tuple会被分到同一组
-
All Grouping 广播发送:对于每个tuple,所有的bolts都会收到
-
Global Grouping 全局分组:这个tuple被分配到storm中的一个bolt的其中一个task
-
Non Grouping 不分组:stream不关心到底谁会收到他的tuple
-
Direct Grouping 直接分组:消息的发送者指定由消息接收者的哪个task处理这个消息
-
Local or shuffle grouping :如果目标bolt有一个或多个task在同一个工作进程中,tuple将会被随机发送给这些tasks。否则,和普通的shuffle Grouping行为一致。

















 4395
4395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









