






数据准备
这个模型主要是针对于录音转成文本,然后对模型进行微调,微调前先准备好录音数据。
租用新实例
登录AutoDL算力云https://www.autodl.com/console/instance/list,这是一个云端服务器,里面有很多便宜的机子可以用于模型训练。所以即使你本地的电脑不支持模型训练也完全没有关系。
登录或者注册后,你会进入这个界面,我们点击这个租用新实例
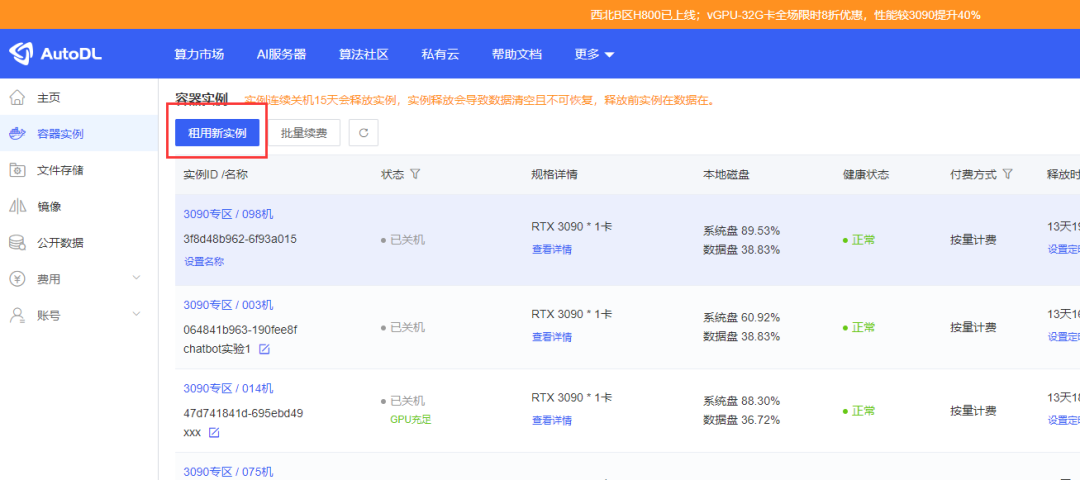
选择一块4090显卡,然后选择社区镜像,此镜像别人已经做好了模型,以及训练模型的相关代码,我们只需要运行相关命令即可。
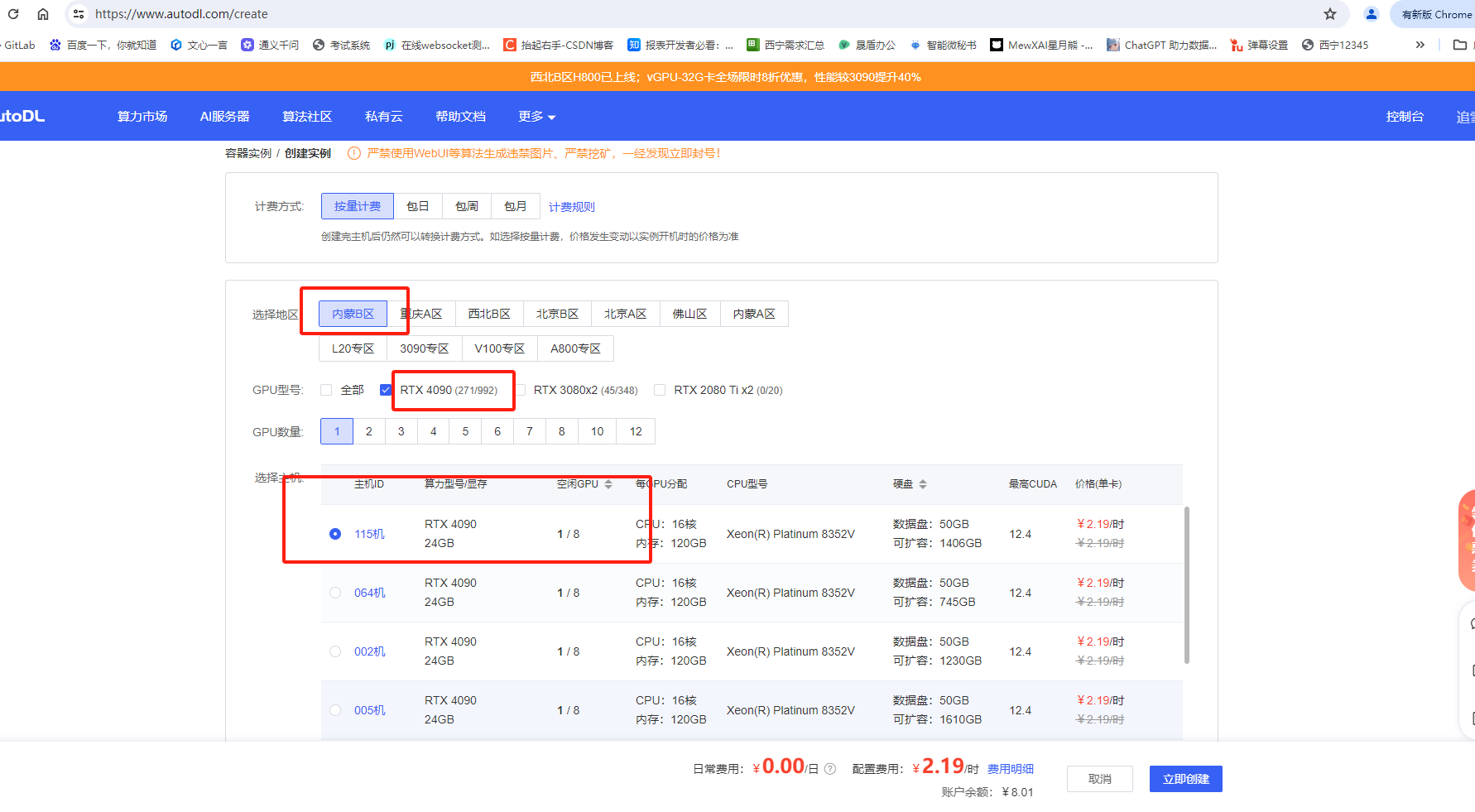
再往下滑,选择相关的社区镜像,具体如下图
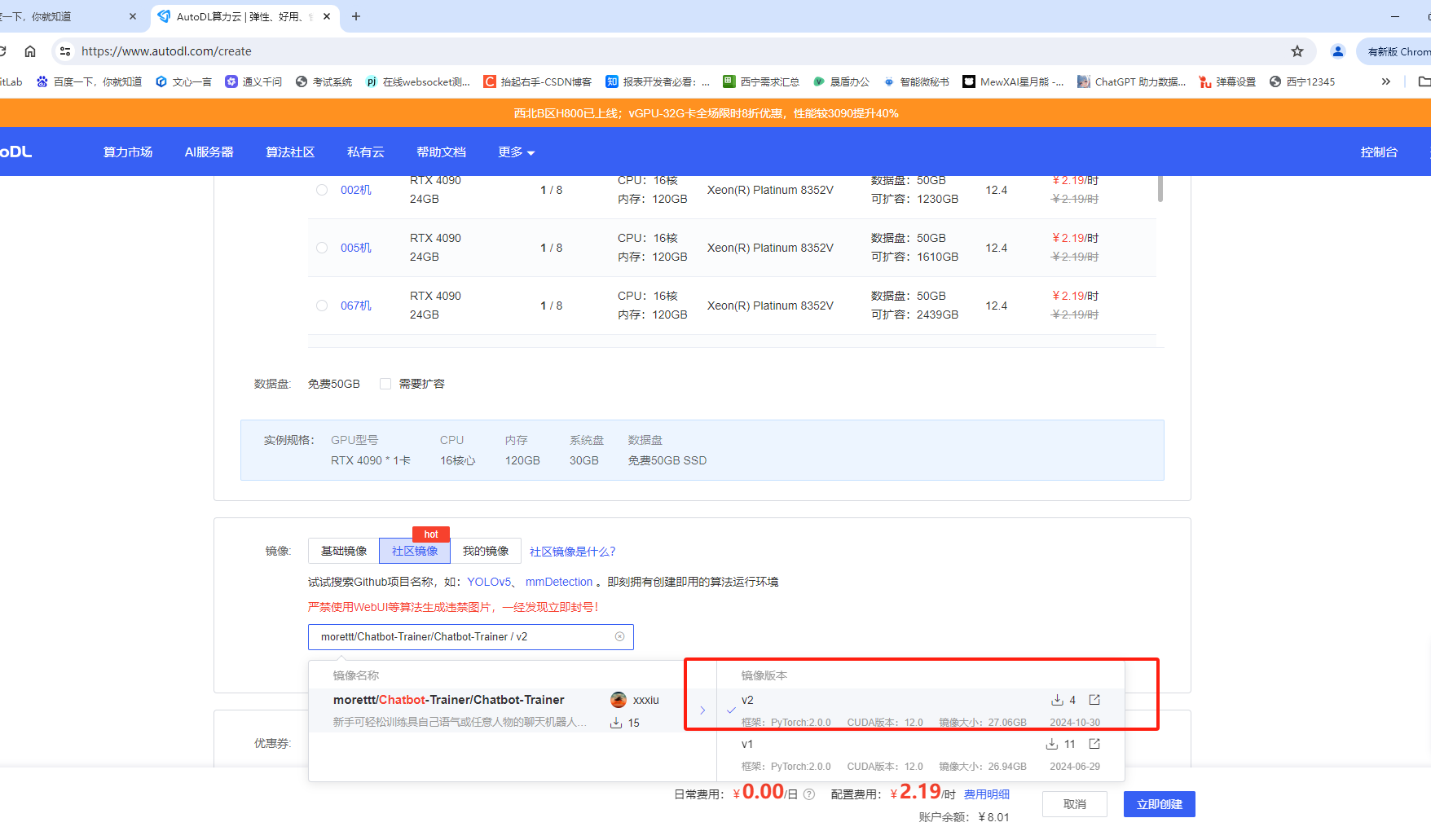
点击创建后,会显示如下状态,等待创建完成
JupyterLab进入服务器
创建成功后,我们直接点击这个JupyterLab
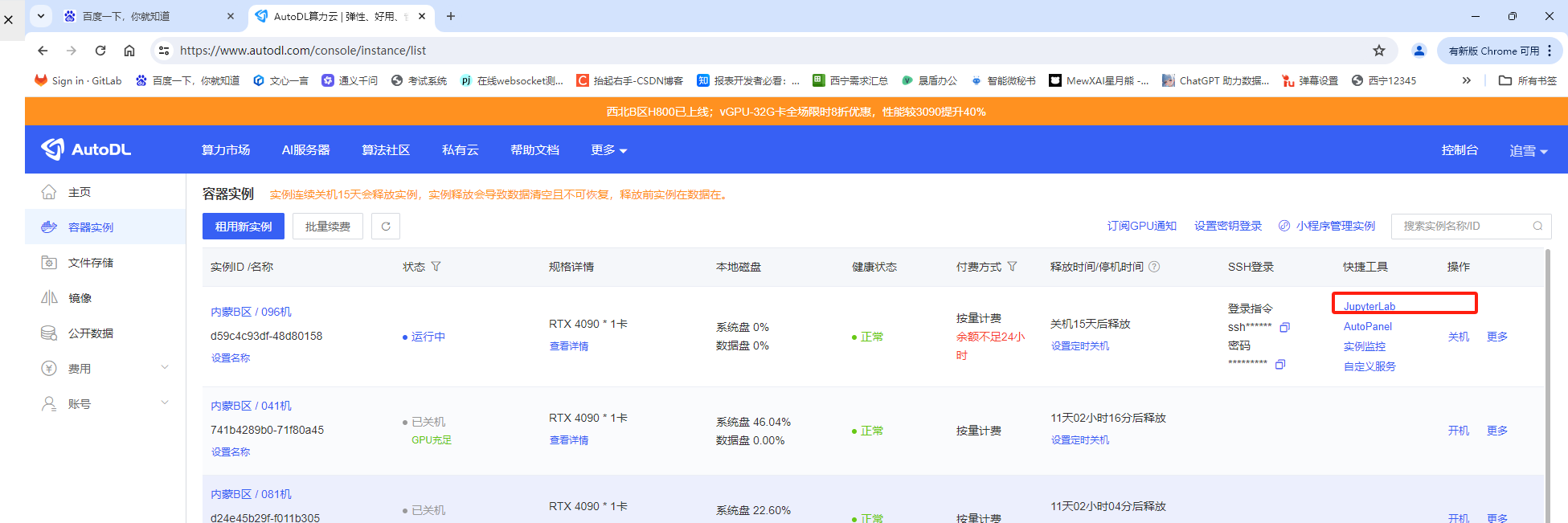
稍等片刻,即可看见如下操作界面:
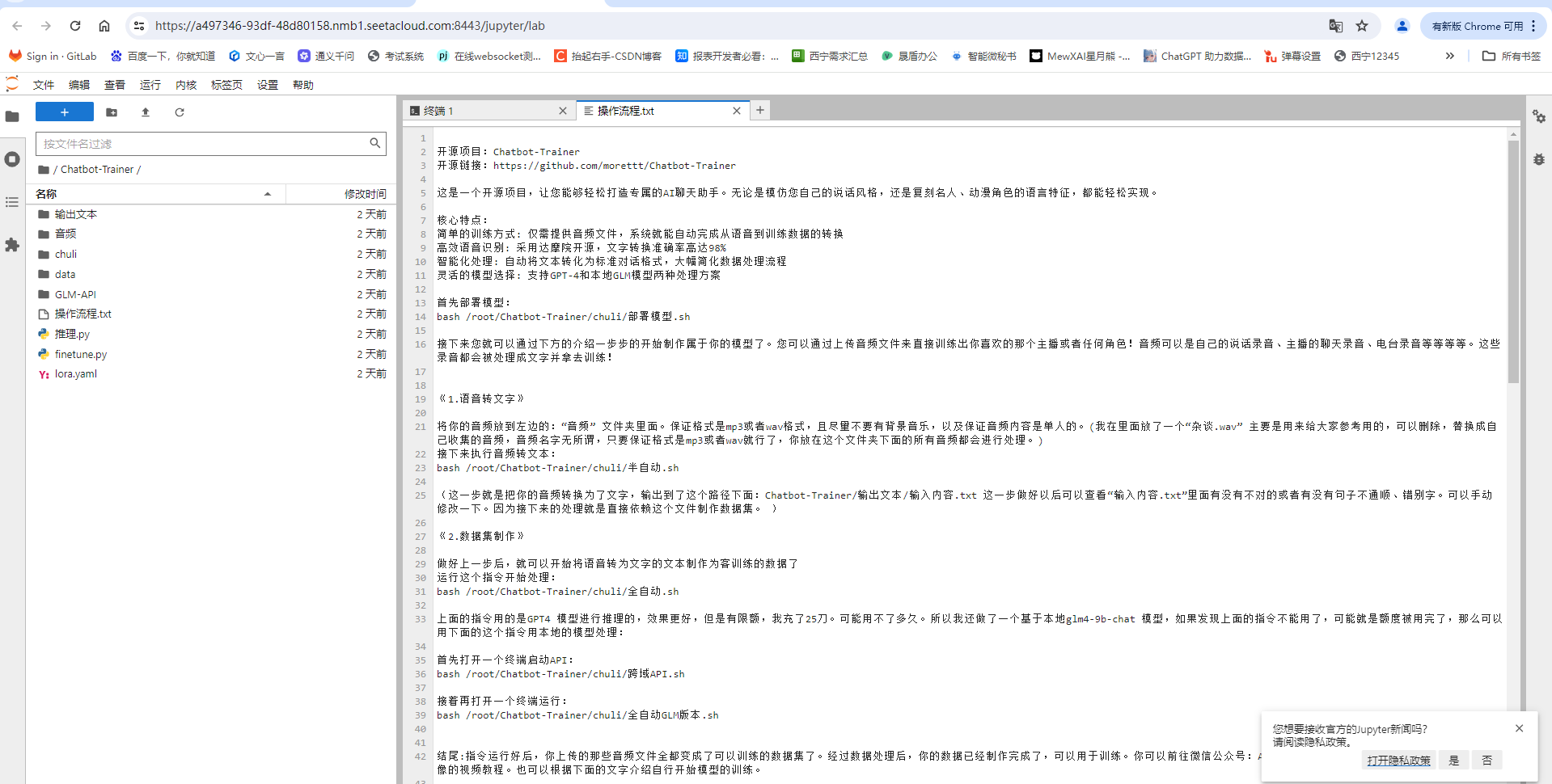
模型部署
第一步,我们复制这个指令:
bash /root/Chatbot-Trainer/chuli/部署模型.sh然后点击那个终端图标,然后将其输入到终端并运行
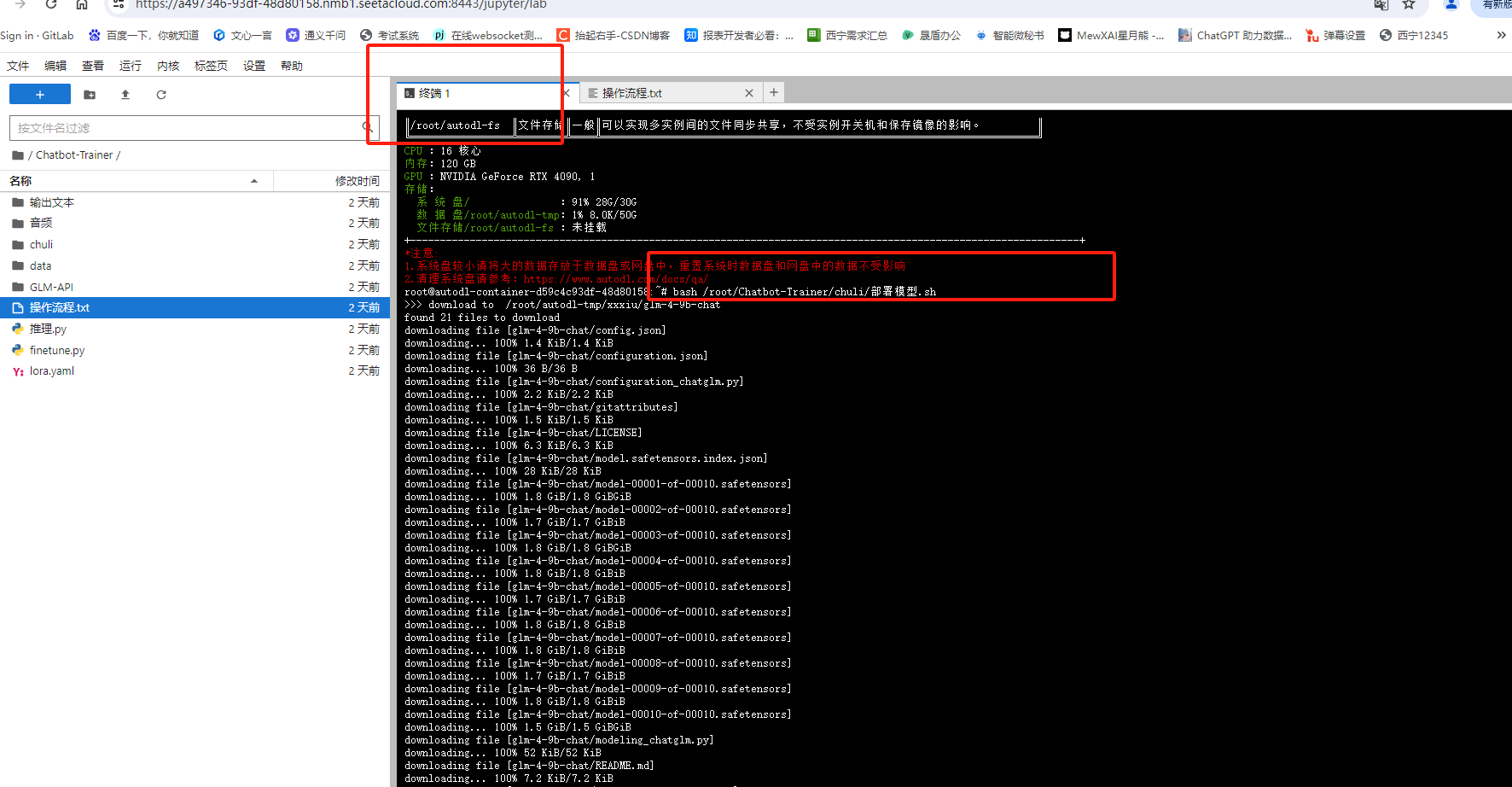
上传训练数据
将你准备好的录音上传到这个音频的文件夹
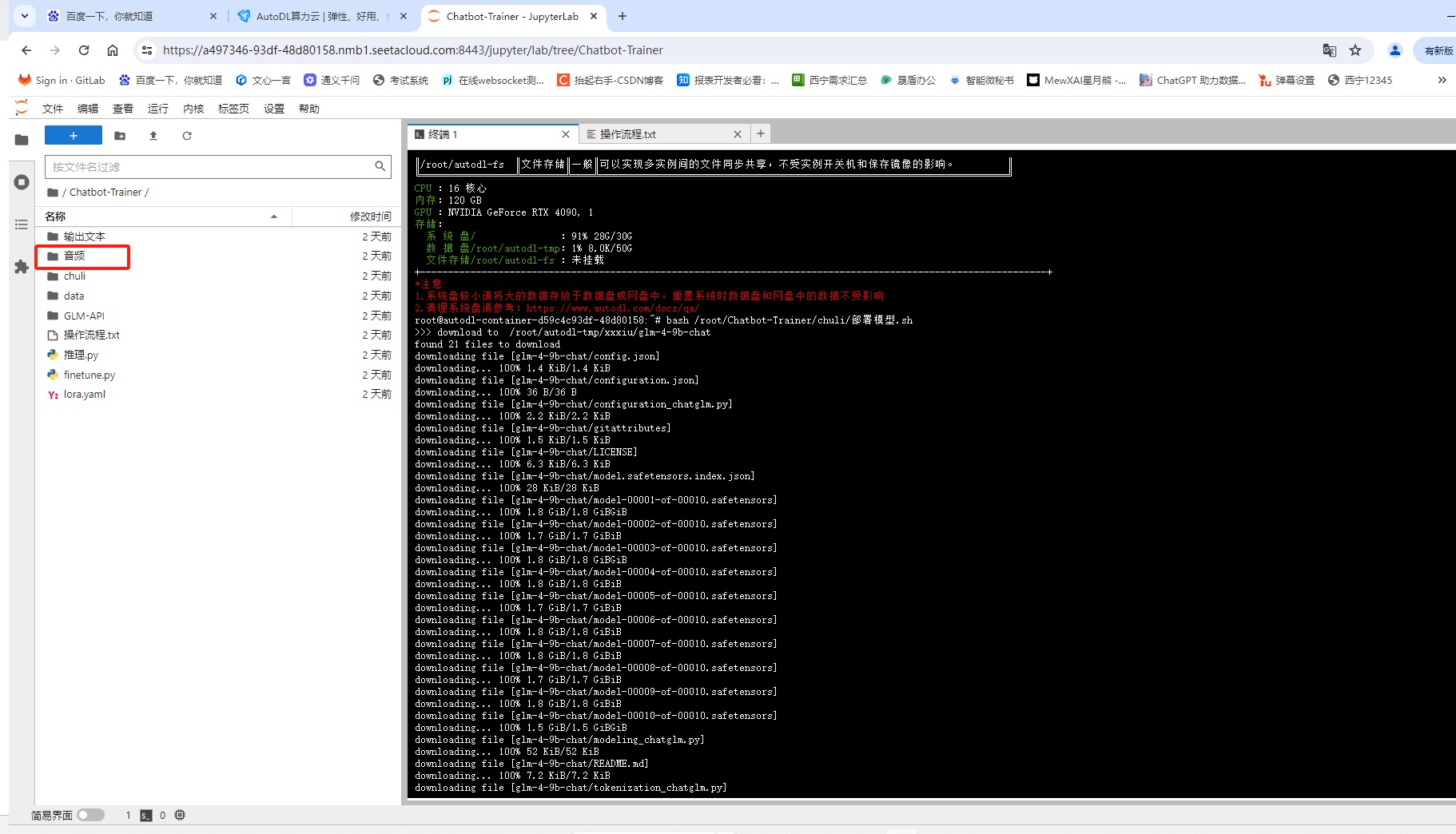
需要注意的是要等待下面的这个进度条加载完了才是音频上传成功了
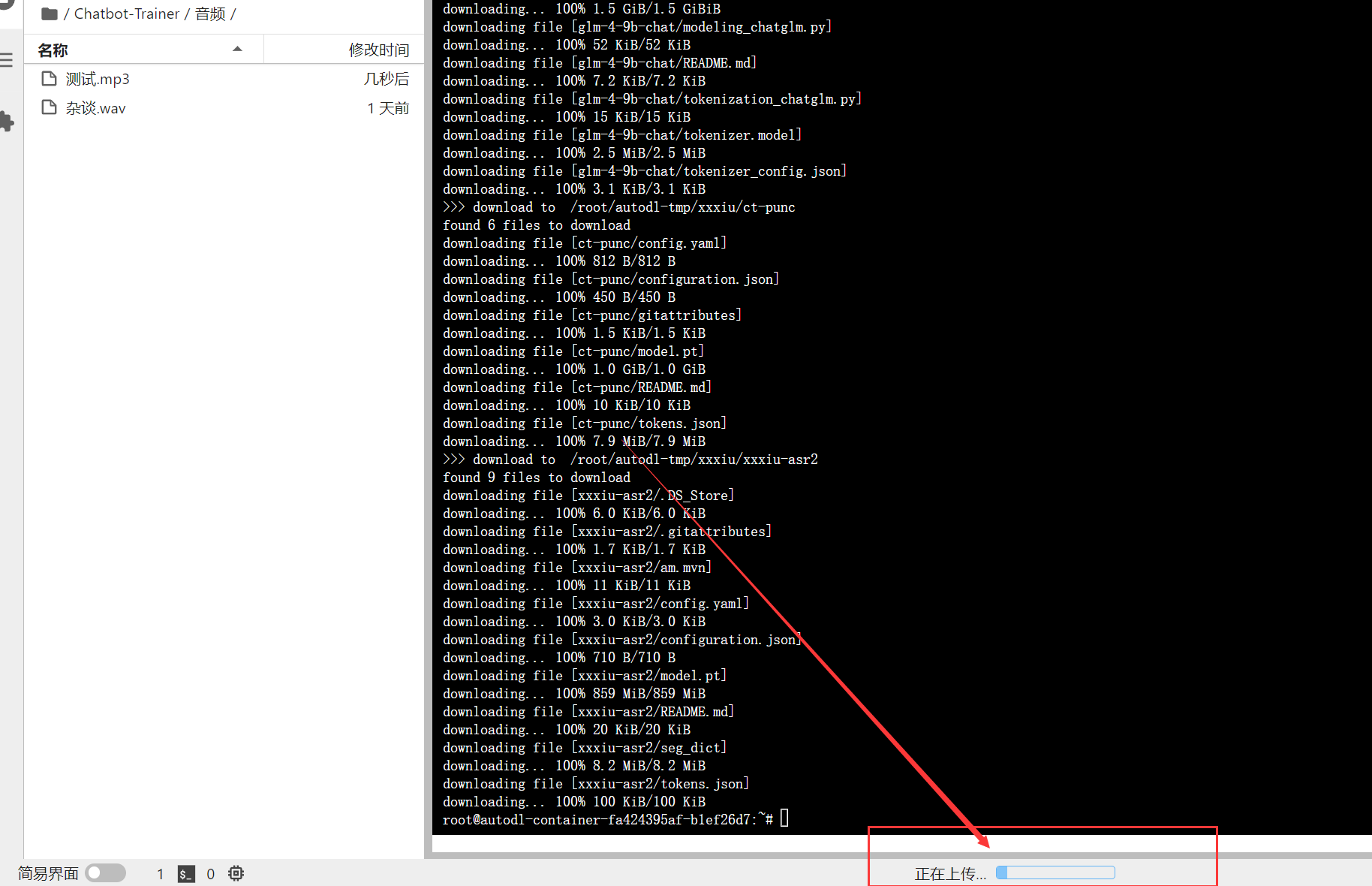
处理音频数据
需要等模型和部署完成再运行,这个部署是比较慢的,主要是模型比较大,大家多等一会
音频上传好了之后,我们在终端运行这个指令开始处理数据:
bash /root/Chatbot-Trainer/chuli/半自动.sh 运行后,系统就会开始为你处理数据了,就像这样:
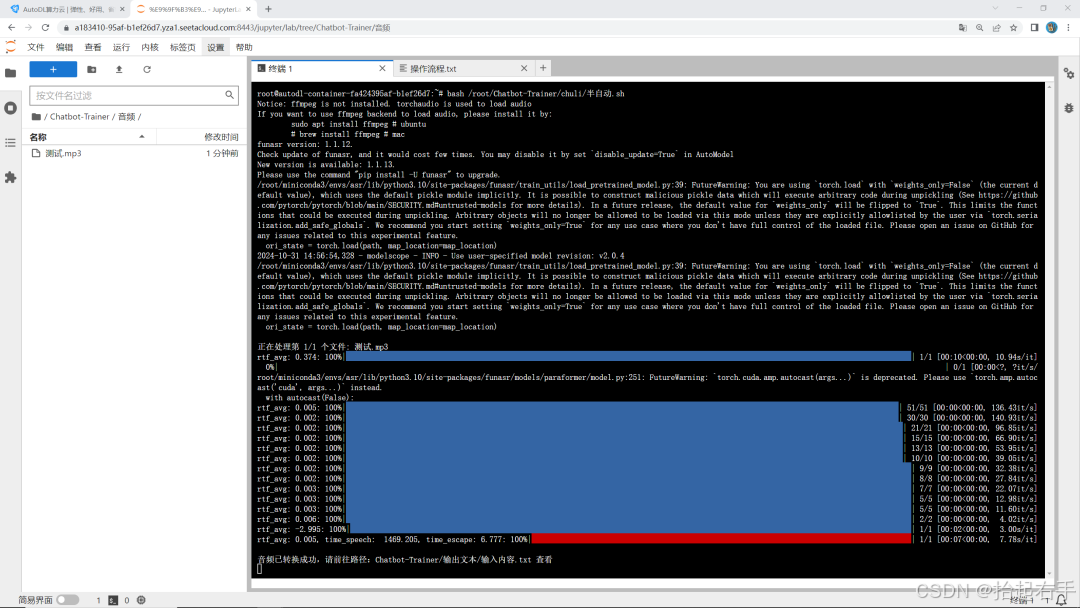
处理好的数据会被保存到这个路径下面:Chatbot-Trainer/输出文本/输入内容.txt
bash /root/Chatbot-Trainer/chuli/全自动.sh模型会将你音频转换为文字的内容进一步处理成这种对话的数据,我们需要的就是,耐心等待模型将你的数据全部制作完成。
全部处理好以后,会输出这样的内容就代表全部处理完了:

模型训练
到了这一步,我们的数据就全部处理好了,你现在可以直接开始模型的训练了!我们运行这个指令:
bash /root/Chatbot-Trainer/chuli/lora微调/lora训练.sh你可以看见模型现在就开始训练了:
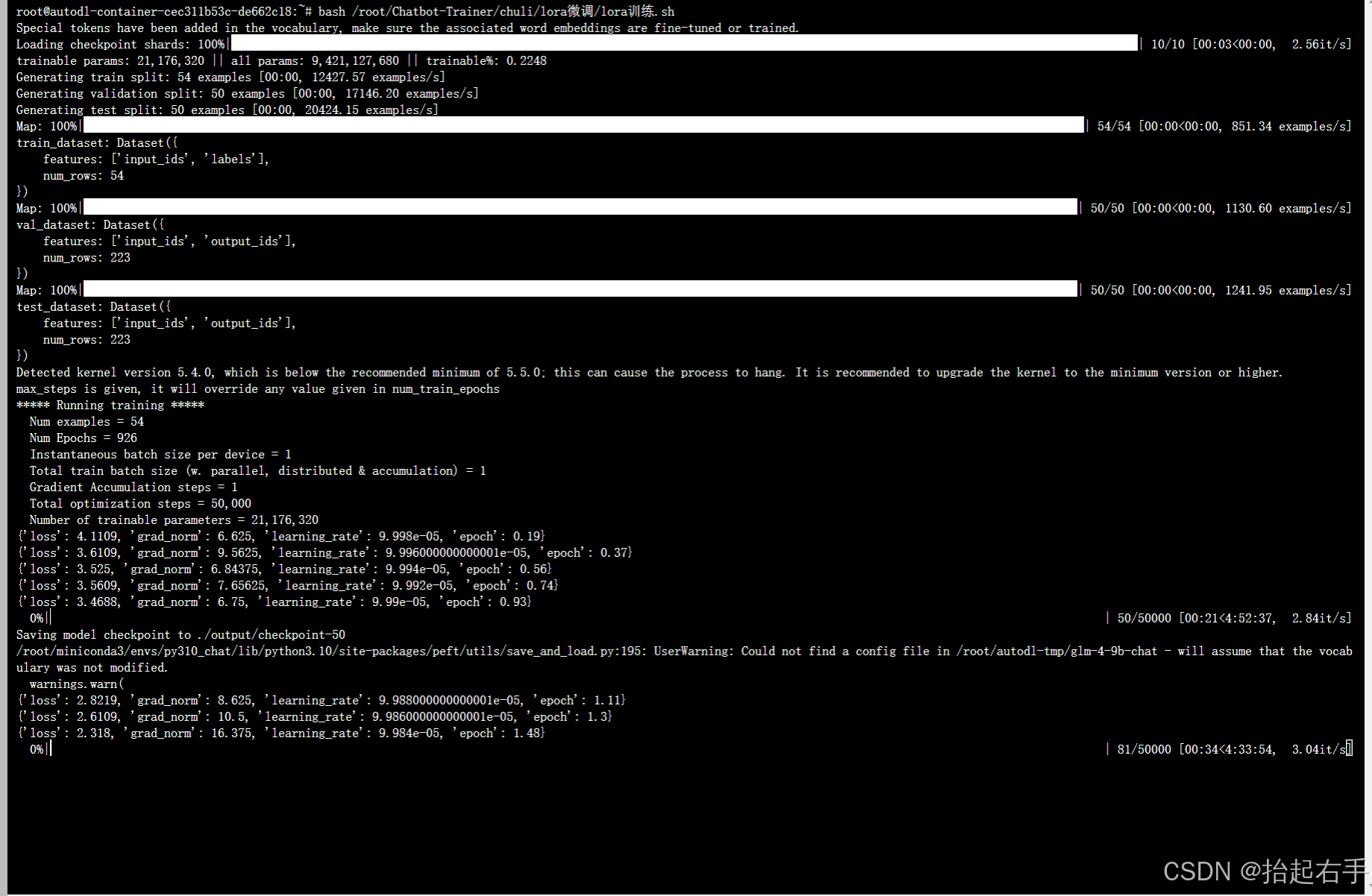
默认设置是每50步保存一次模型。其中你可以观察左边的这个loss
loss会一直下降。我们不用等进度条跑完,只要看见loss已经下降到了0.5~0.9这个范围,就可以手动按住键盘的ctrl+c 键直接停止训练。
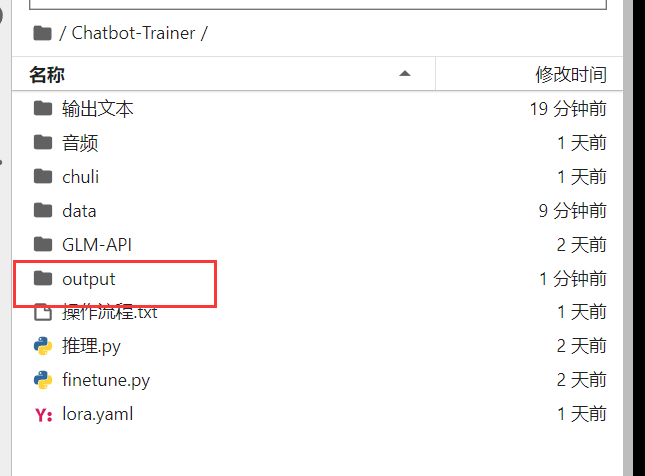
保存好的模型会生成到这个路径下面
运行训练好的模型
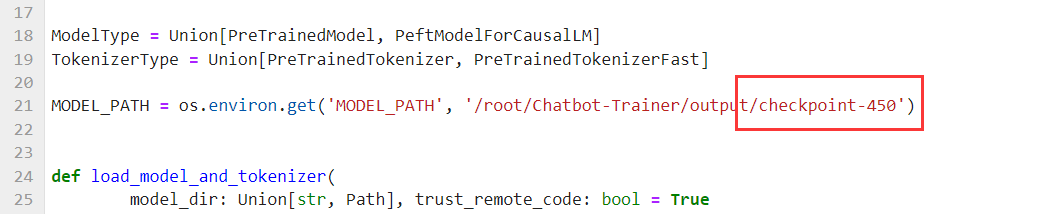
output下面是每50步保存的模型,我们选择结尾数字最大的一个,例如:checkpoint-450
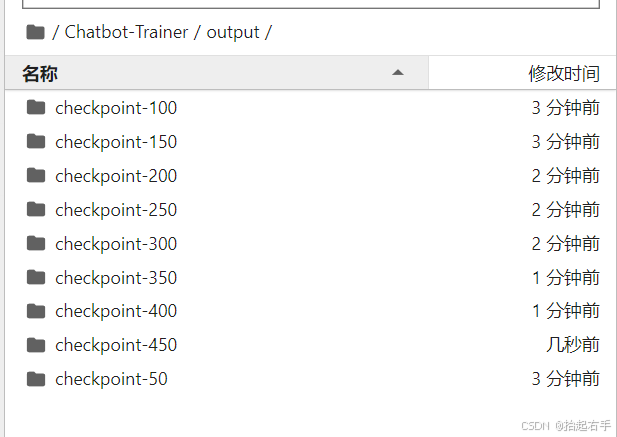
然后我们回到这里,打开这个推理.py文件
这个代码其余的都不用管,直接看红框标注的地方
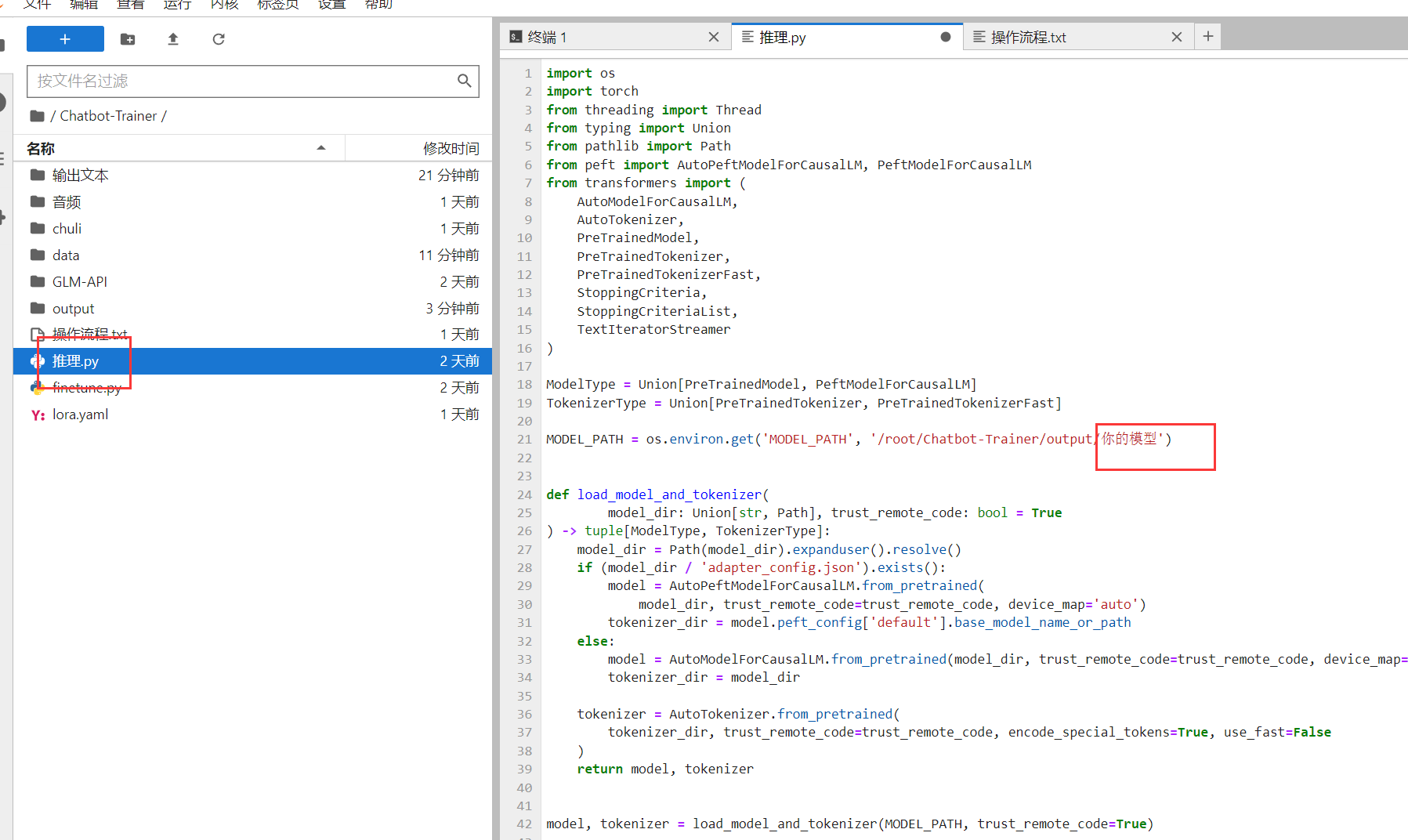
我们把刚刚复制的模型名字粘贴,记得保存。
最后,我们就可以推理你训练好的模型了:
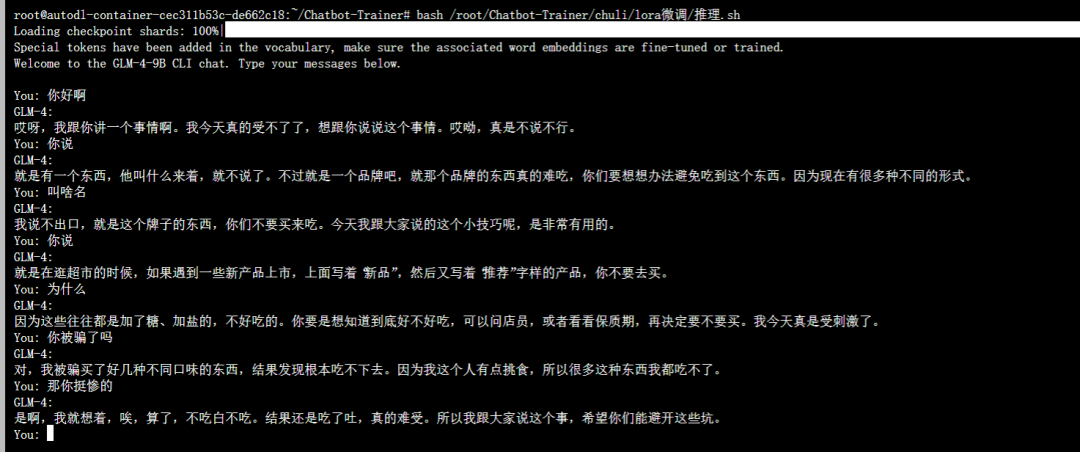
bash /root/Chatbot-Trainer/chuli/lora微调/推理.sh测试
将上面的指令输入到终端,代码会加载你训练好的模型,你可以直接和训练好的模型对话测试,就像这样。

















 970
970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









