






选择镜像
登录算力云https://www.autodl.com/home,租聘GPU和选择镜像
这里选择ChatGlm3镜像,我们主要测评的是在不同GPU上ChatGlm3并发量测试。
选择3090显卡
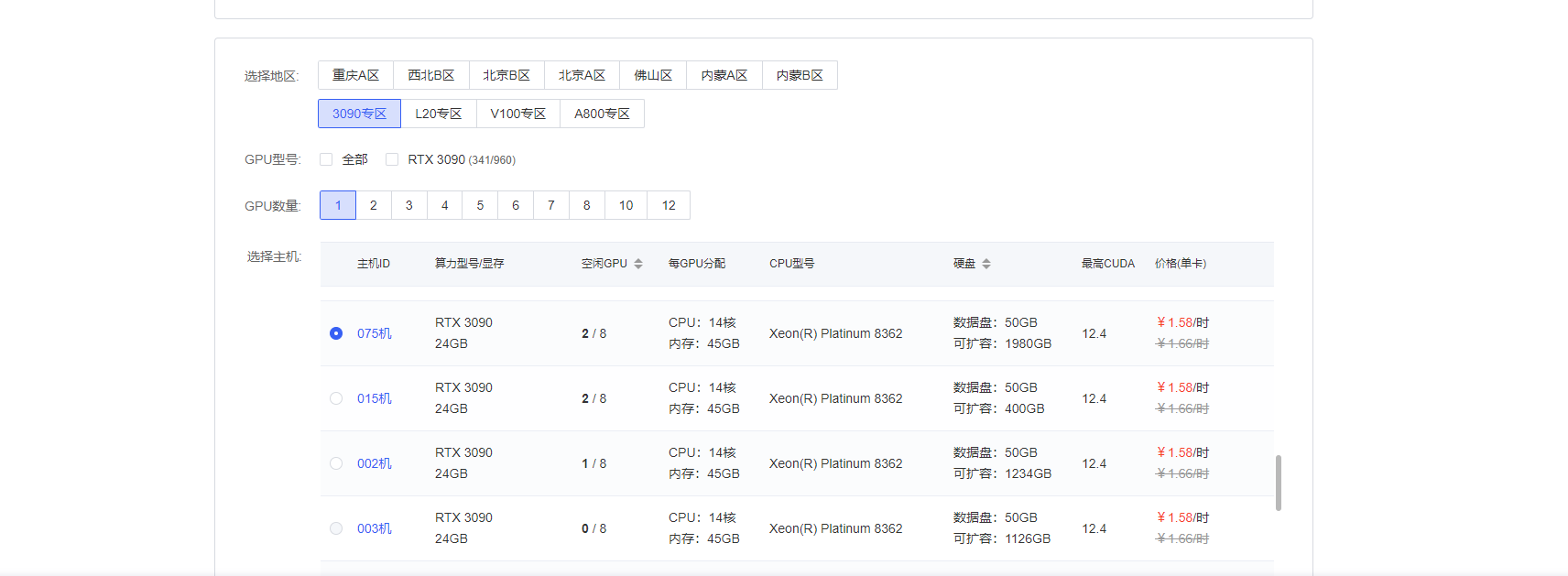
选择镜像
镜像名称:THUDM/ChatGLM3/ChatGLM3__6b
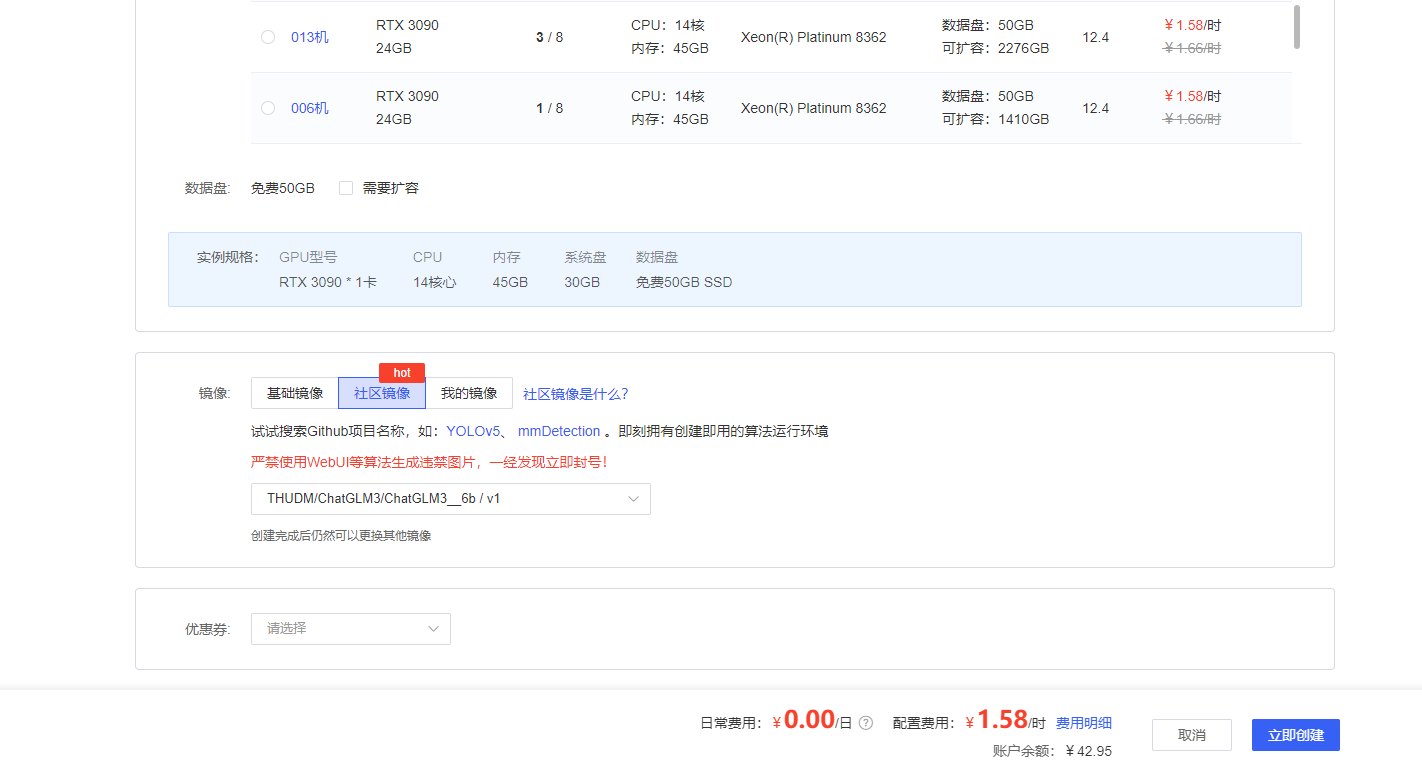
镜像加载成功
点击立即创建之后等一会可以看到示例状态为运行中
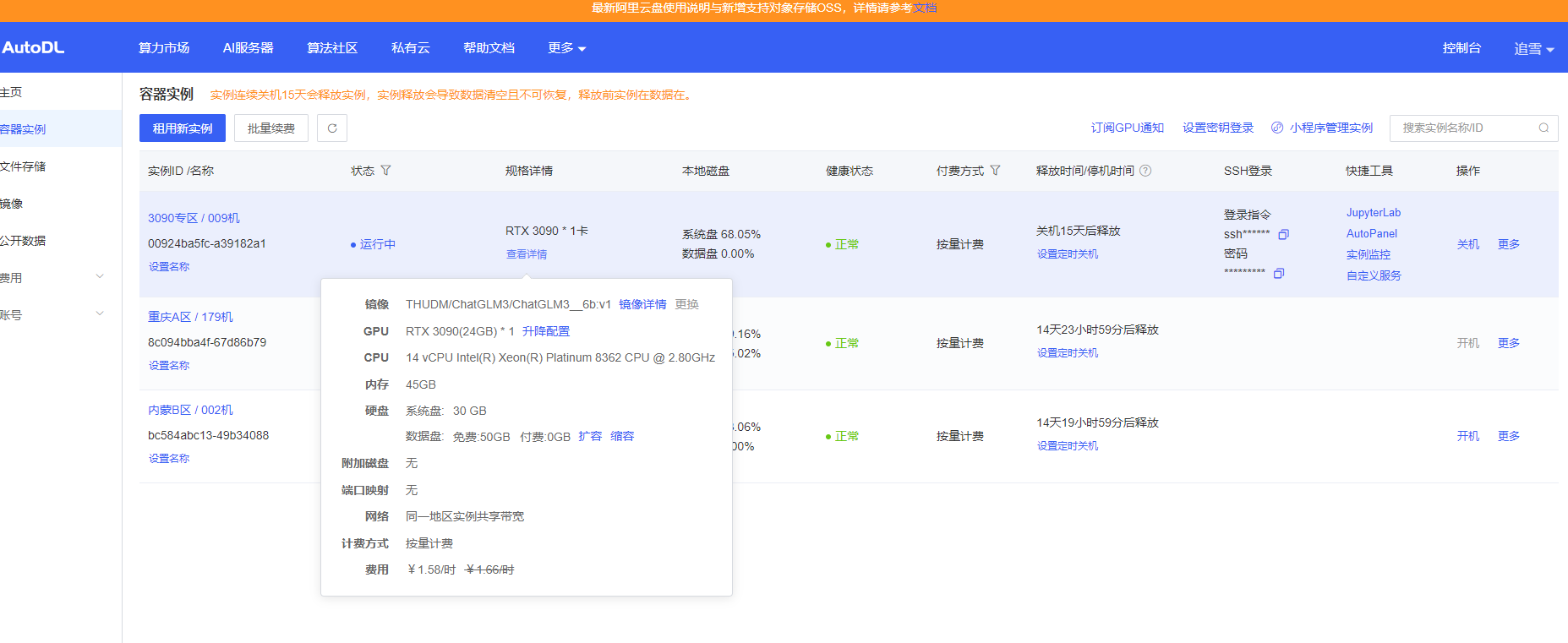
点击JuputerLab进入系统进行操作
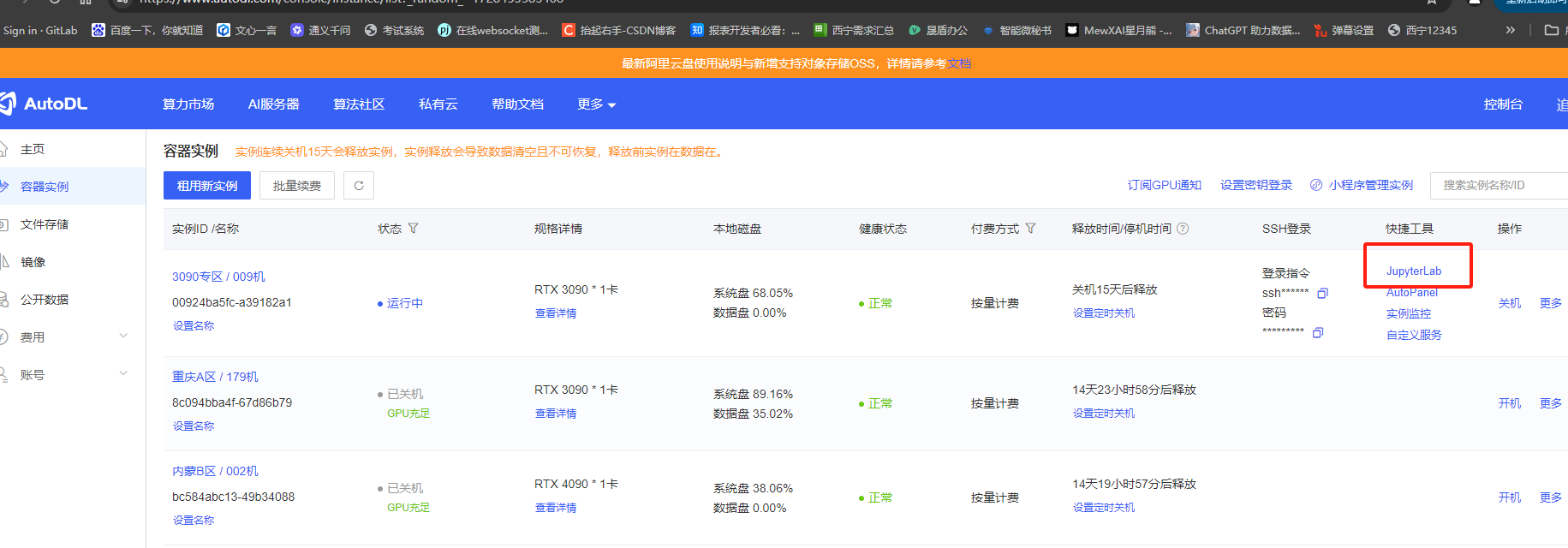
启动服务
#运行命令启动模型,可以直接聊天,
bash /root/miscellany/tnt.sh
#跑完上一个命令再按ctrl+c退出,然后运行以下命令启动模型,并使用oneapi代理
bash /root/ChatGLM3/openai_api_demo/one.sh
运行之后如下所示

测试是否成功
保留前面一个终端,并新开启一个终端输入一下命令
bash /root/ChatGLM3/openai_api_demo/three.sh对话测试
文字输入,看是否能够正常对话
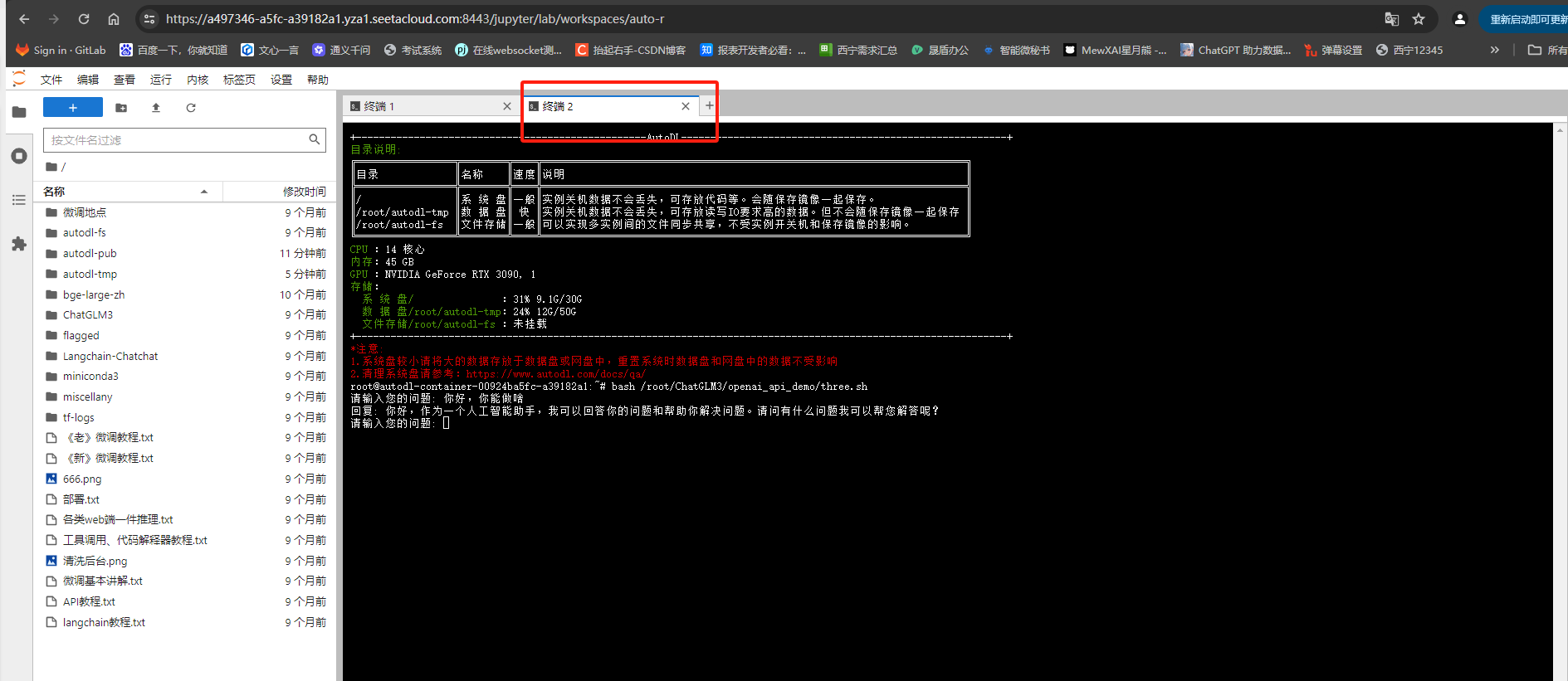
代理服务
(1)Windows
点击自定义服务
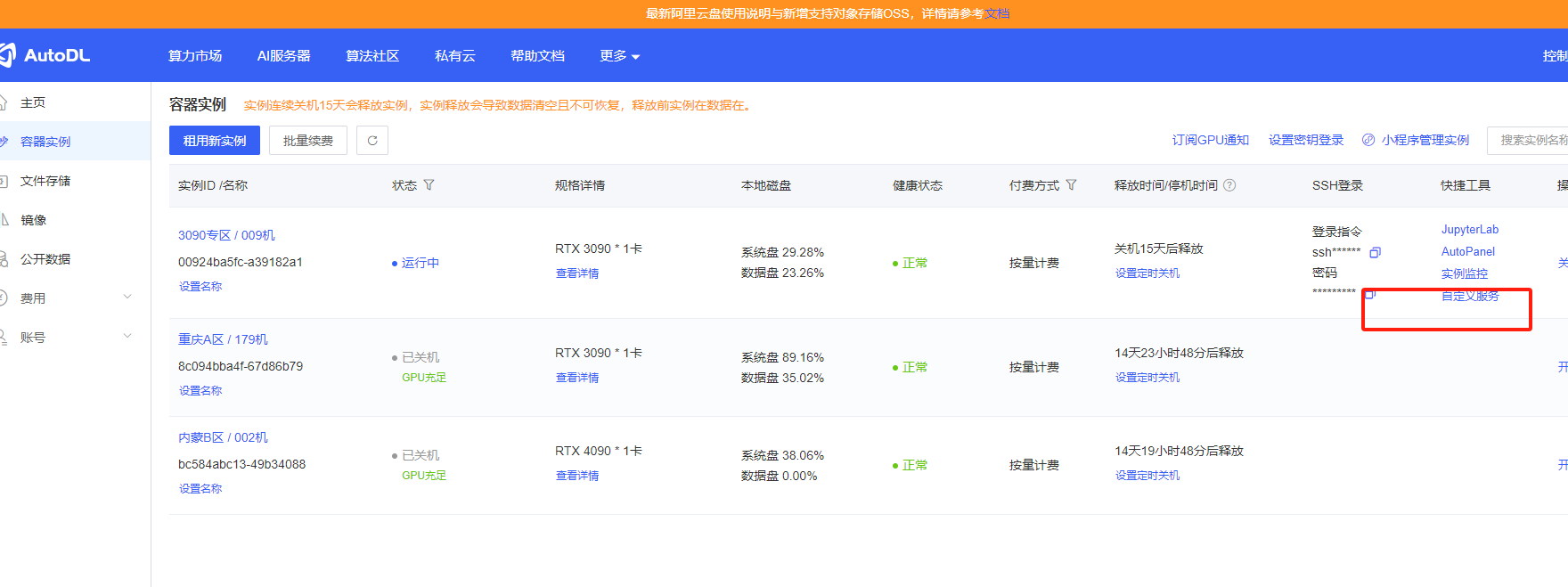
下载工具包
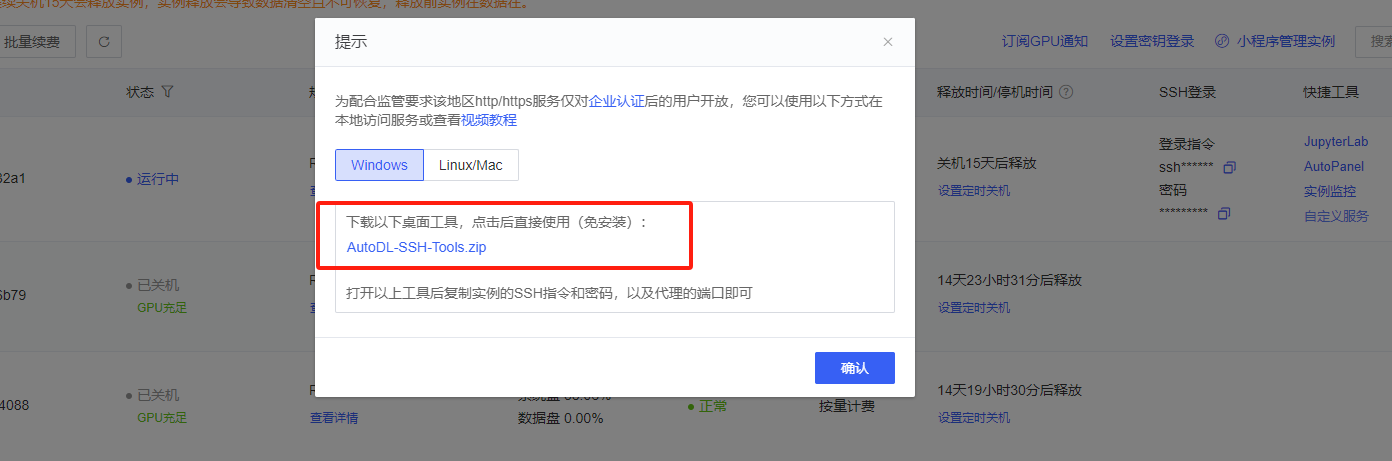
解压并启动工具
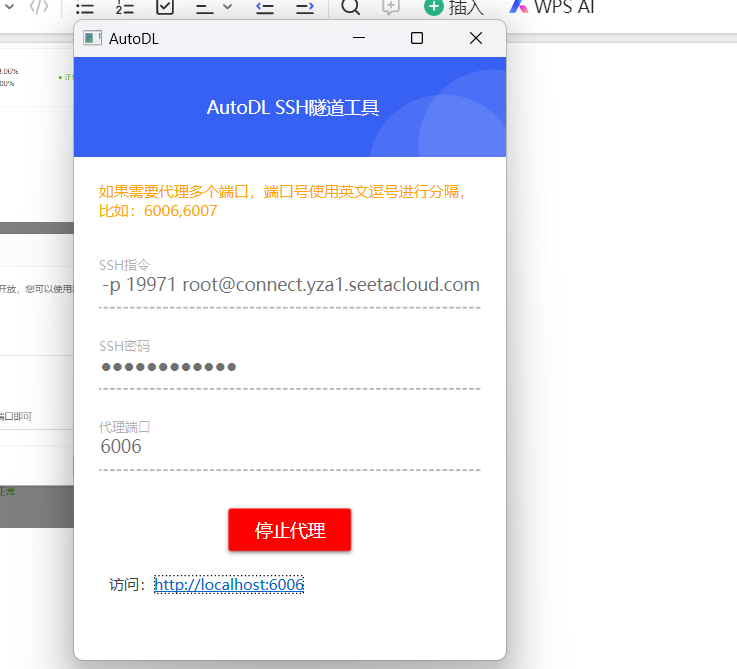
复制SSH指令和密码,并代理端口6006
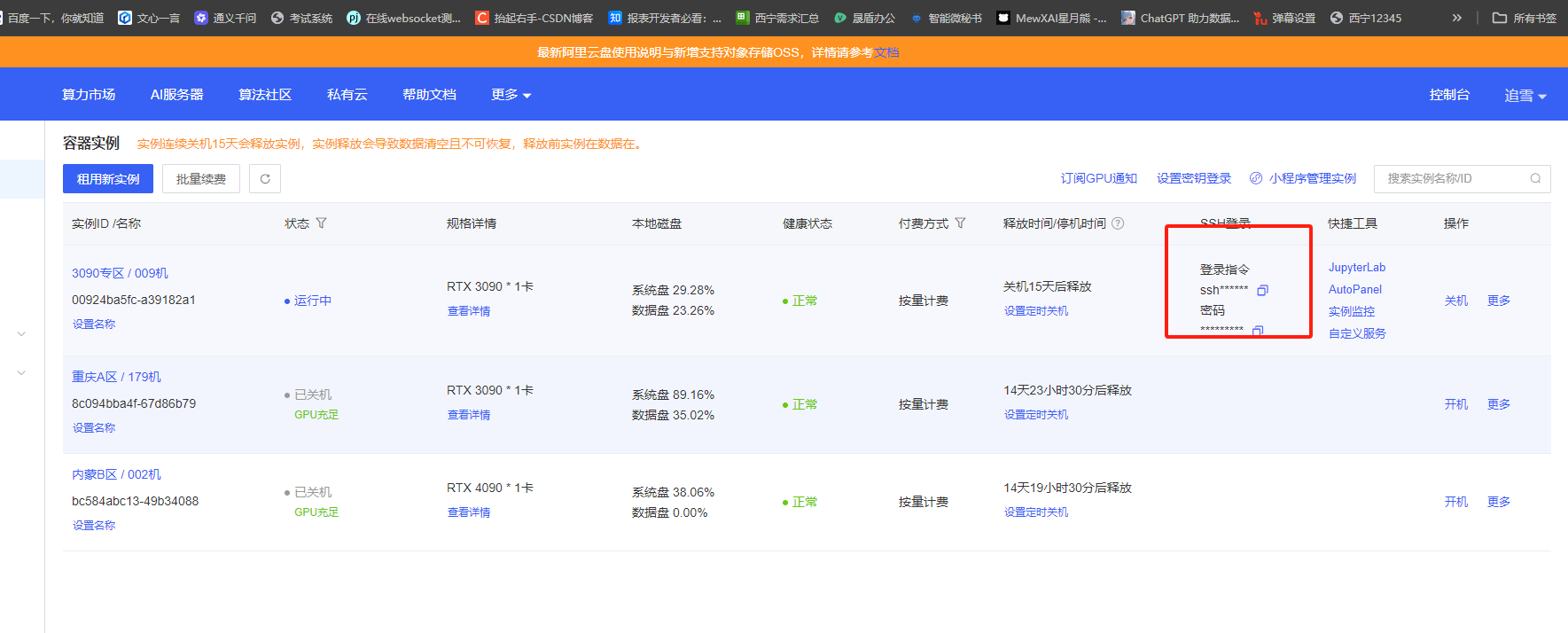
启动SSH隧道代理
(2)MAC/Linux
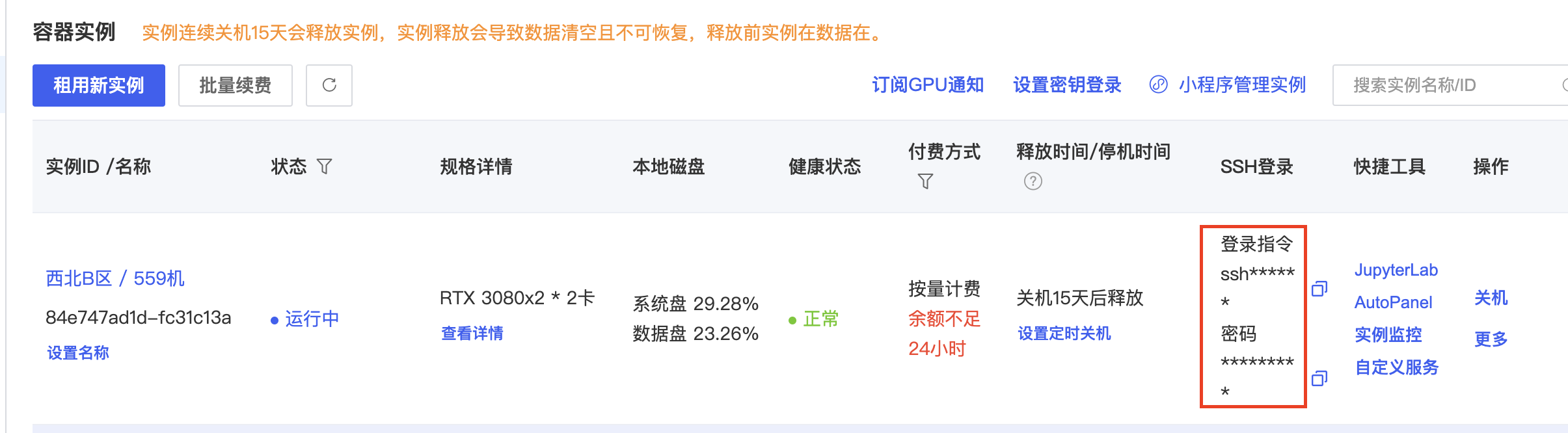
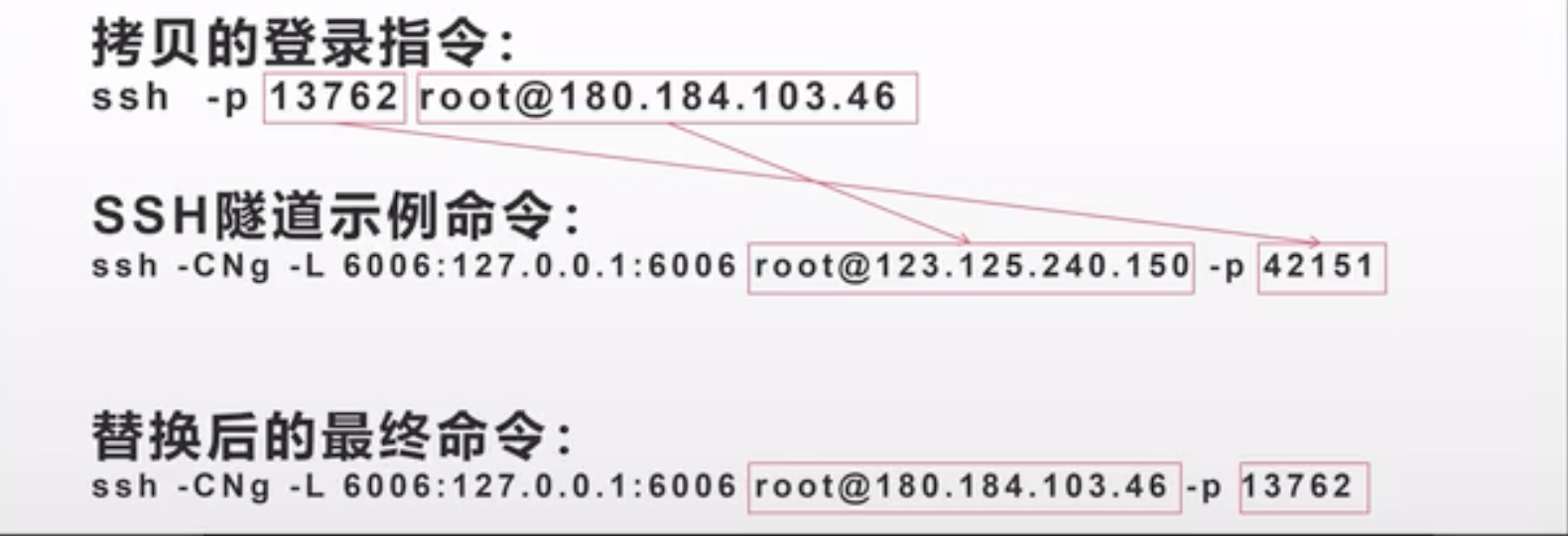
复制上图SSH的登录指令到终端,按照下图进行指令修改后回车,要求输入密码输入上图中的密码即可
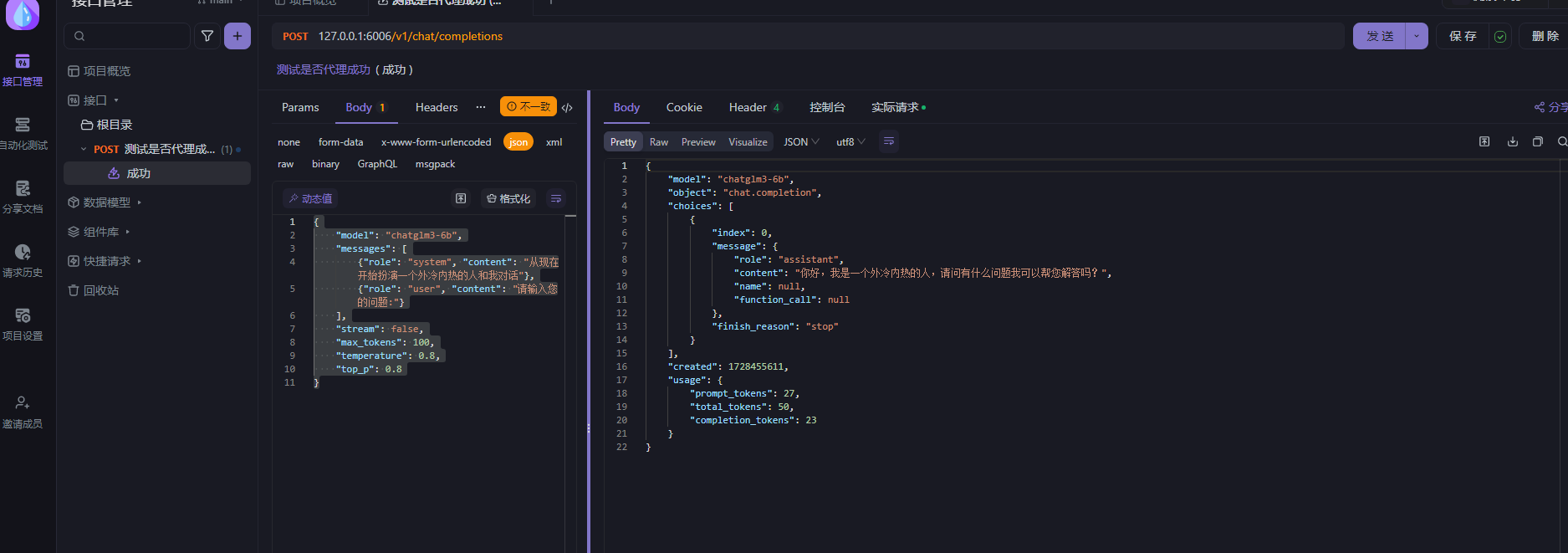
APIFOX测试
新增一个post请求
url 127.0.0.1:6006/v1/chat/completions
json参数
{
"model": "chatglm3-6b",
"messages": [
{"role": "system", "content": "从现在开始扮演一个外冷内热的人和我对话"},
{"role": "user", "content": "请输入您的问题:"}
],
"stream": false,
"max_tokens": 100,
"temperature": 0.8,
"top_p": 0.8
}请求测试
或者直接加入研发中心的团队
李亮 在 Apifox 邀请你
点击GPU测试项目
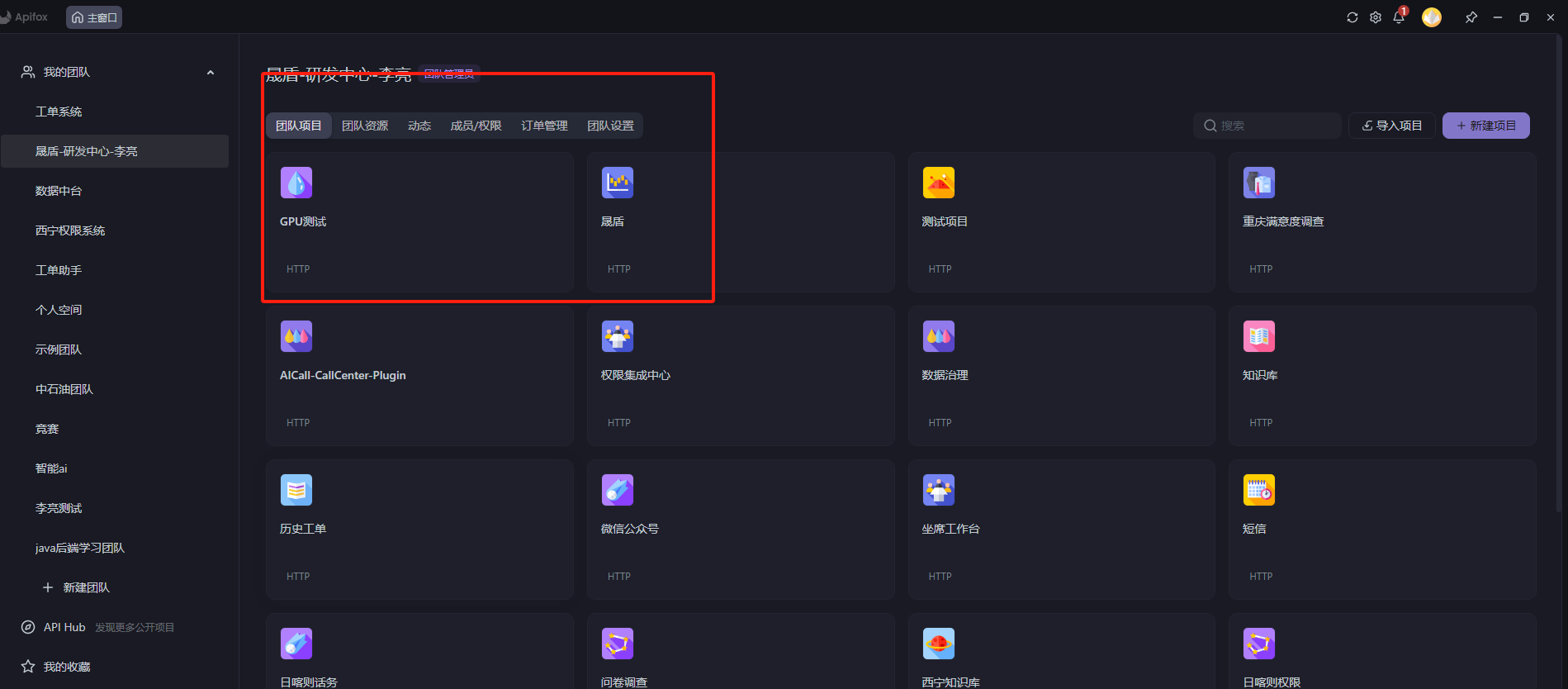
调用成功案例测试
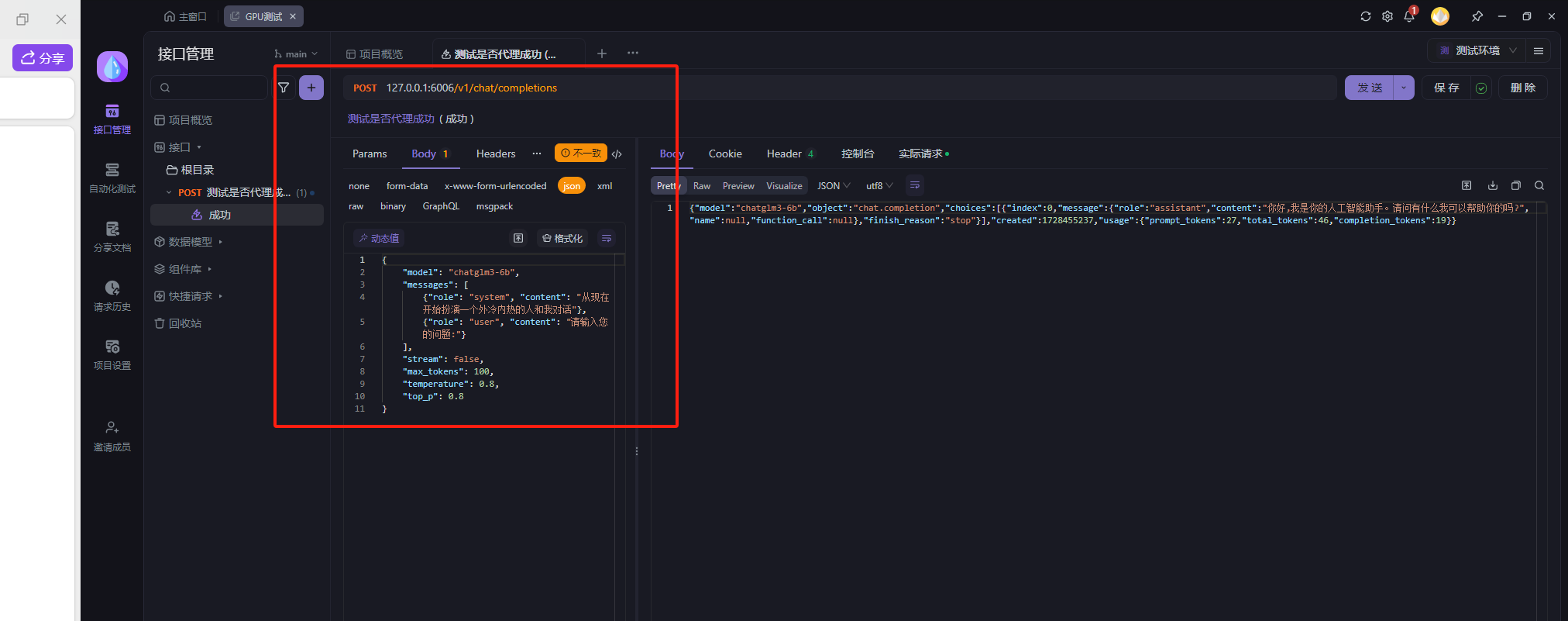
测试成功
并发测试
点开自动化
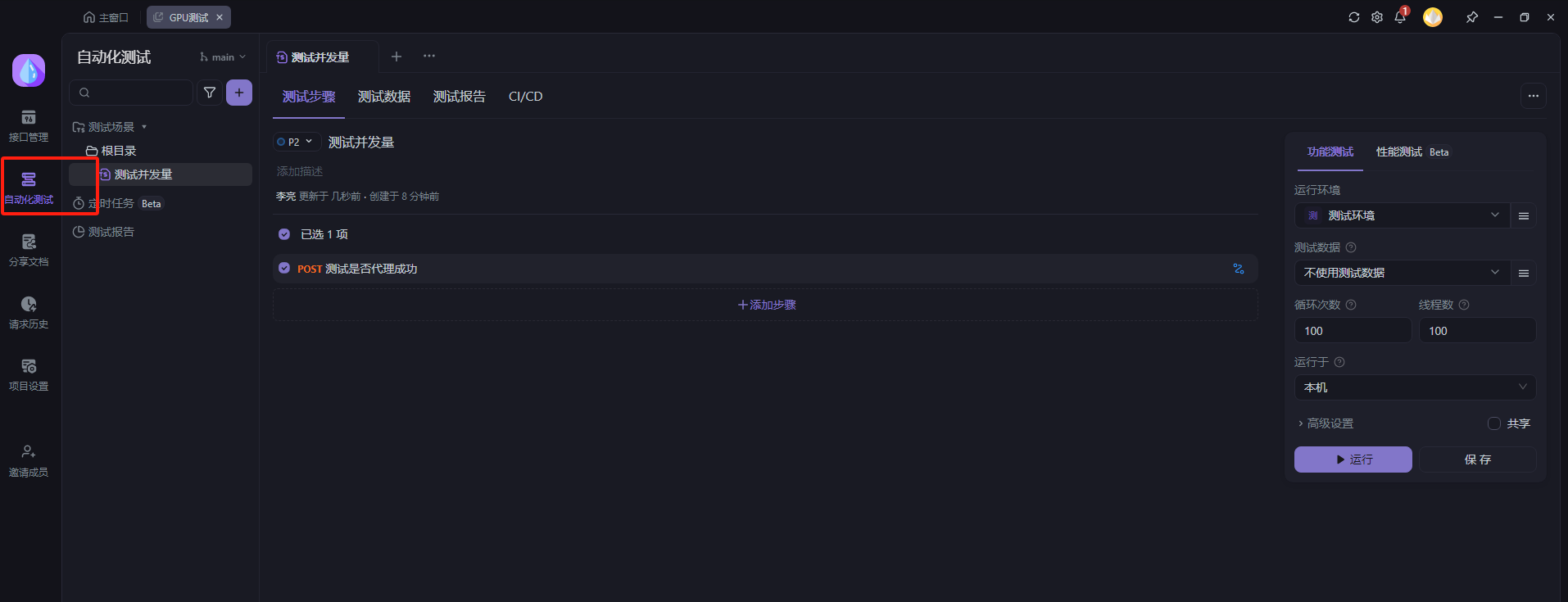
选择线程数
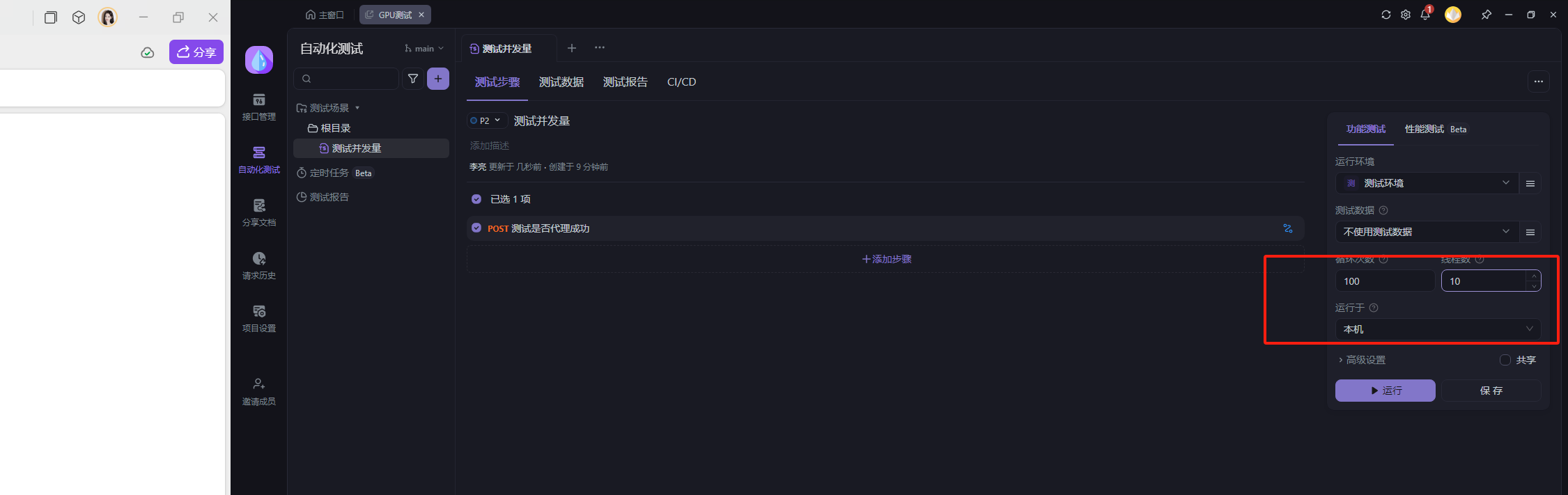
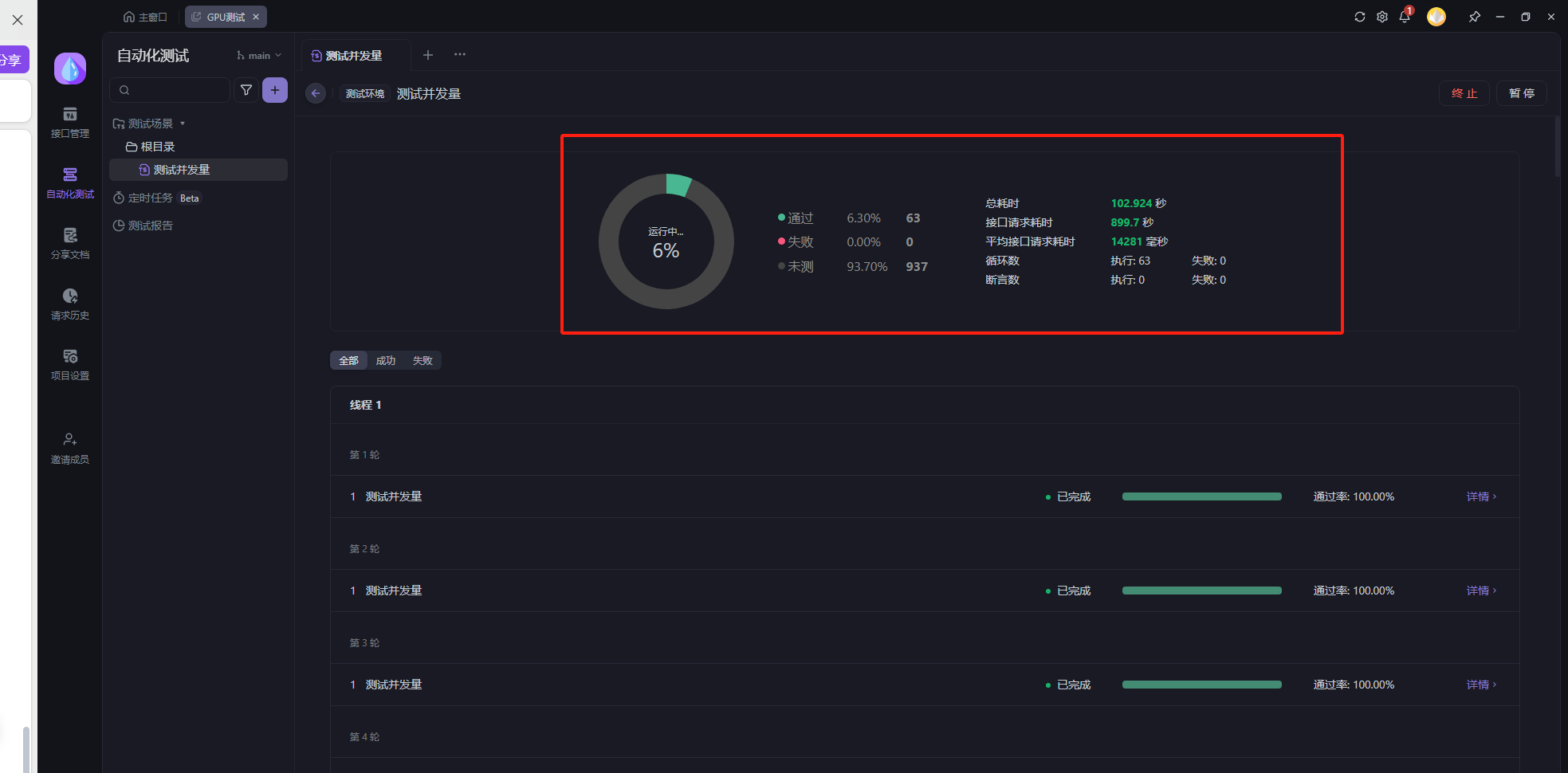
运行程序
如图请求完成之后得出结果

















 314
314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









