







一、kNN
本章主要介绍KNN算法,也称为K-近邻算法。简单的说,knn算法采用测量不同特征值间的距离来对数据进行分类,即我们初中时候学过的两点之间的距离公式,有没有想起来,根号下(A-B)**2,这就是欧氏距离,简单吧。
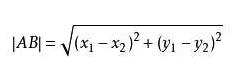
现在来介绍一下KNN的计算的过程,①计算测试集与与训练集数据的距离,用欧式距离计算,②对每个距离进行排序,取K个最近的。(又叫“k邻近”),计算出现频率,取最高的。差不多就是这么回事情了。现在我们通过python的几个小案例来实现一下KNN算法。
对了,还要介绍一下KNN算法的优缺点。就优点来说:精度高,对异常值不敏感,无数据输入假定。缺点的话:计算负责度高,空间负责度高。适用范围:数值型数据。
二、简单介绍一下这个小案例吧
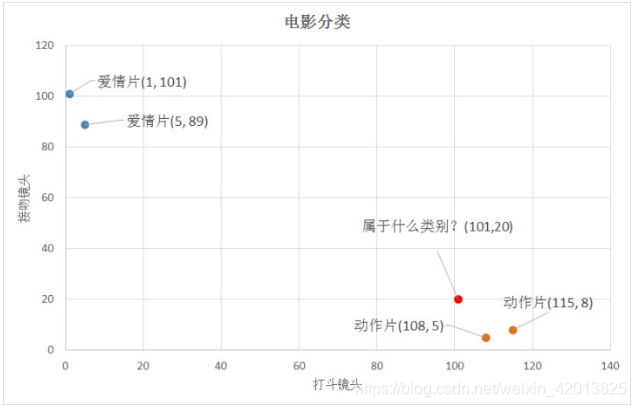
这个小案例是这样的,数据集中有4列数据,包括,电影名、打斗镜头、接吻镜头、电影类型。
即我们不知道在测试集中电影属于哪类电影,需要通过某种方法计算出来。我们用打斗镜头做x轴,接吻镜头做y轴。吧训练样本的数据,这部分训练集数据我们是已经知道,带又标签(电影的类型)。我要要做的,是计算未知类型数据,周围最近K个已知类型数据,然后按照那个类型多,这个未知数据归类为那种。大概就是这样了。数据我保存到云盘了,找不到同学可以自己下载一下,链接:https://pan.baidu.com/s/1sIN0sYyXORGhmO9PoTnsqw
提取码:w065
三、代码实现来了
# -*- coding: UTF-8 -*-
import numpy as np
import operator
"""
函数说明:kNN算法,分类器
Parameters:
inX - 用于分类的数据(测试集)
dataSet - 用于训练的数据(训练集)
labes - 分类标签
k - kNN算法参数,选择距离最小的k个点
Returns:
sortedClassCount[0][0] - 分类结果
"""
def classify0(inX, dataSet, labels, k):
# numpy函数shape[0]返回dataSet的行数
dataSetSize = dataSet.shape[0]
# 在列向量方向上重复inX共1次(横向),行向量方向上重复inX共dataSetSize次(纵向)
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
# 二维特征相减后平方
sqDiffMat = diffMat ** 2
# sum()所有元素相加,sum(0)列相加,sum(1)行相加
sqDistances = sqDiffMat.sum(axis=1)
# 开方,计算出距离
distances = sqDistances ** 0.5
# 返回distances中元素从小到大排序后的索引值
sortedDistIndices = distances.argsort()
# 定一个记录类别次数的字典
classCount = {}
for i in range(k):
# 取出前k个元素的类别
voteIlabel = labels[sortedDistIndices[i]]
# dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值。
# 计算类别次数
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
# python3中用items()替换python2中的iteritems()
# key=operator.itemgetter(1)根据字典的值进行排序
# key=operator.itemgetter(0)根据字典的键进行排序
# reverse降序排序字典
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
# 返回次数最多的类别,即所要分类的类别
return sortedClassCount[0][0]
"""
函数说明:打开并解析文件,对数据进行分类:1代表不喜欢,2代表魅力一般,3代表极具魅力
Parameters:
filename - 文件名
Returns:
returnMat - 特征矩阵
classLabelVector - 分类Label向量
"""
def file2matrix(filename):
# 打开文件
fr = open(filename)
# 读取文件所有内容
arrayOLines = fr.readlines()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









